Spark优化,多线程提交任务,提升效率
Posted 大数据男
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark优化,多线程提交任务,提升效率相关的知识,希望对你有一定的参考价值。
优化背景:
for循环提交4次任务,会触发4个Job,由于Driver的单线程运行及Spark的任务调度决定了4个Job是串行执行,但这个4个任务是无关的,可以并行执行。
优化思路
通过线程池并行提交Job,Driver端不卡顿。
具体实现
val listBuffer = new ListBuffer[Future[String]]
val service: ExecutorService = Executors.newFixedThreadPool(4)
for (i <- 0 to 3)
val task: Future[String] = service.submit(new Callable[String]
override def call(): String =
println(s"第$i个任务。。。。。。。。。。。。。。。。")
val k = i
reRunDF
.withColumn(fieldStockAttributeId, lit(k))
.createOrReplaceTempView(s"$OverseasDetailQuantityReport.tblWwarehouseStorageRecord_$k")
val resFrame = spark.sql(OverseasDetailQuantityReport.sqlMain(k))
resFrame.show()
writeStarRocks(resFrame, OverseasDetailQuantityReport.tblDetailQuantity, dbInfo)
writeToKafka(resFrame, OverseasDetailQuantityReport.tblDetailQuantity)
println(s"第$i个任务。。。。。。。。。。。。。。。。结束")
"success"
)
listBuffer.append(task)
//遍历获取结果
listBuffer.foreach(result=>
println(result.get())
)
service.shutdown()
效果
优化前 : 5分钟
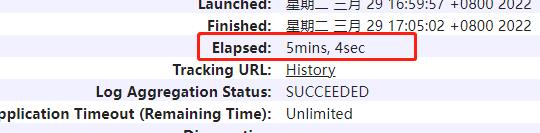
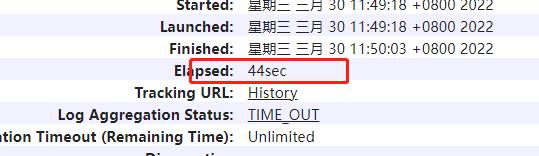
优化后:44秒
关键点
1,要用callable,不能用runnable,runnable没有返回值,无法阻塞driver,不阻塞driver导致driver线程马上结束,应用终止。callable有返回值,可以通过获取返回值阻塞Driver,应用能正常运行。阻塞代码如下:
//遍历获取结果
listBuffer.foreach(result=>
println(result.get())
)
2,使用了for循环,createOrReplaceTempView时临时表名必须是动态的,否则循环注册的临时表名相同,导致后续计算从同一张表中获取。
.createOrReplaceTempView(s"$OverseasDetailQuantityReport.tblWwarehouseStorageRecord")
需改为动态临时表名:
.createOrReplaceTempView(s"$OverseasDetailQuantityReport.tblWwarehouseStorageRecord_$k")
3,集群必须要有足够的资源,且提交任务时要申请足够的资源,否则调度系统仍然会让Job排队执行
/usr/local/service/spark/bin/spark-submit --master yarn --jars ./jars/guava-29.0-jre.jar --conf "spark.executor.extraClassPath=guava-29.0-jre.jar" --num-executors 6 --executor-cores 2 --executor-memory 4g --class com.quantity.OverseasDentityReportApp /home/hadoop/cter/finbatch-1.0.jar daily
以上是关于Spark优化,多线程提交任务,提升效率的主要内容,如果未能解决你的问题,请参考以下文章