58集团处罚数据中心的设计与实践
Posted 过往记忆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了58集团处罚数据中心的设计与实践相关的知识,希望对你有一定的参考价值。
01
导读
58集团作为国内领先的生活服务及分类信息平台,业务覆盖招聘、房产、汽车、二手、本地生活服务及金融等领域,各业务每天生成海量信息,对内容安全、业务违规的高效治理和处罚的需求亟需解决,本文站在中心化建设视角,阐述58集团处罚数据中心的设计与实践。
02
背景与目标
目前有各业务自建的治理系统和集团主风控系统两条路径来治理内容安全和业务违规问题。上游治理层系统针对用户和信息进行处理后,产生的处罚类数据由各业务自行存储和使用,虽然相对简单和快速地解决了当下面临的治理问题,但对于用户而言需要面对不同形态的处罚数据和繁杂多样的系统操作规则,同时对于下游用户申诉中心无法做到统一高效地处理户申诉诉求。
基于上述背景,处罚数据中心旨在建立集团统一的处罚平台,满足各业务方治理层处罚业务留证和回溯操作诉求,建立标准化处罚信息。

03
业务现状与决策
3.1 业务现状
上游治理系统多
主要包括各业务治理(招聘、房产、微聊等)的处罚和风控治理的处罚,且其中涉及多个系统,采集处罚数据需要适配各系统的接入。
海量数据接入
各业务每天生产海量的数据,需要快速、准确、高效的接入实时处罚数据和存量数据。
处罚方式多样
集团涉及业务广泛,处罚方式多样,例如加黑名单、部落帖子禁止分享、房产信息降权等,需要将所有处罚方式统一归纳、梳理,并对处罚方式进行字典管理。
处罚上下文格式不统一
涉及的多个处罚系统、风控平台都无法抽出数据模型来覆盖所有内容,需要制定标准化处罚业务数据模型来描述所有处罚信息。
处罚数据归属
在数据非标准化、集团风控治理情况下,处罚数据大多无法区分业务归属,针对这种情况下的数据归属也是解决重点。
3.2 解决方案
针对上游各治理系统数据不规范,下游处罚中心也无分类的功能,当各业务治理、风控治理产生的处罚数据,用户无法对当前处罚进行分类申诉。
我们提出两种解决方案:
方案一:由上游所有业务提供标准化数据,比如上下文信息,最后将数据推送到处罚中心进行留存。
优点:处罚数据中心只做数据分类留存。
缺点:推动所有上游业务改动困难,让各业务统一使用风控平台进行治理也不现实
方案二:处罚中心作为基础平台统一处理异构数据,进行数据ETL后进行留存。
优点:不需要上游业务改动,项目成本可控。
缺点:在分类治理数据中有技术挑战。
综上,我们采用方案二由处罚中心作为集团处罚链路基础层,统一处理异构数据。同时,基于规则对海量存量异构数据进行清洗,过程中在保证业务正确性的前提下,还需要保证服务清洗效率以及服务的稳定性。
数据ETL(Extract-Transform-Load)的关键点
数据粒度
58集团作为国内知名信息分类平台之一,其信息数据增长迅速,需要根据业务场景对数据进行聚合,如何定义处罚粒度,以什么样的维度聚合来描述当前处罚信息,对后面标准化建设以及应用有重要意义,例如针对同一批次或者同一类型的处罚信息进行聚合可以更准确记录处罚现场。
数据标准化
在接收各数据源数据时,数据里缺失关键信息问题,需要借助数据里的特征,对处罚数据进行补全,再构建处罚中心标准数据。
04
设计方案
处罚中心整体架构,如下图所示:

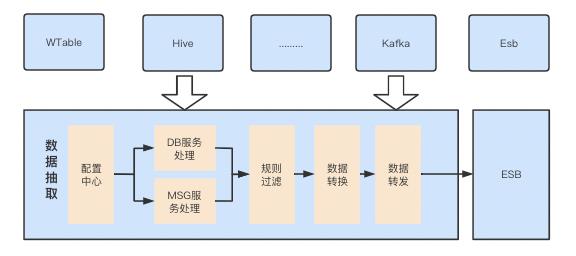
数据层:58集团业务产生的治理数据、集团处理中心产生的业务数据、以及业务线下同步的数据,都会成为我们的数据源。
服务层:服务层的核心功能为对所有数据源进行数据采集数据抽取模块、对采集的数据进行规则特征匹配的数据清洗模块、以及对数据应用展示查询、反向恢复的数 据应用模块
存储层:作为集团处罚数据中心,处罚数据的增量写入与查询需求很高,使用公司自研数据库wlist、wtable,wlist为<k,list>结构,用来存储当前key的索引集合,wtable为<k,v>结构,用来存储数据实体。
05
数据ETL
5.1 数据采集
数据采集包括对线上实时数据、离线数据、业务同步数据、存量数据的采集。对于不同上游的数据接入,数据采集需要适配各系统接入差异,同时海量数据的采集在保证对数据采集渠道的扩展支持上,还要关注采集效率。
5.2 抽取框架选择
大数据实时计算框架的选型,调研业内主流的Spark、Flink大数据处理框架以及部门内自研数据处理系统大禹平台。详细选型对比如下:
Spark | Flink | 大禹平台 | |
功能特性 | 基于内存计算、支持批处理和流处理、支持SQL编程接口 | 基于内存计算、支持批处理和流处理、支持SQL编程接口 | 多数据源流量调度、支持流处理,处理计算需定制开发工具 |
延迟 | 秒级 | 毫秒级 | 秒级 |
故障恢复机制 | 完善 | 完善 | - |
Exactly once | 支持 | 支持 | 支持 |
窗口计算 | 支持基于时间的窗口计算 | 拥有灵活的窗口计算特性,用户可自定义窗口操作 | 不支持 |
Spark和Flink在功能特性上都可以满足业务场景诉求,在延迟方面Flink有更明显的优势,同时在窗口计算上的灵活性给后续数据处理工作预留较多的操作空间,因此,我们选择Flink作为数据抽取框架,利用其强大的流式计算能力,能够快速处理数据密集型任务,在采集数据时更加高效。
5.3 数据转换
采集的数据是多源、异构的,需要将其进行字段的转换、数据补全转换成统一的格式数据。这里采用自定义的DSL(Domain-Specific Language,领域专用语言)来描述对数据转换配置信息,统一数据处理领域模型。

处理流程上,首先获取配置的source调起内部采集数据框架,例如当前source为ESB(消息中间件),我们即可消费当前消息,将当前消息作为整体数据源,根据“do”中配置信息,将数据转换配置信息拿到;再根据“_#TF”Transform转换语法,将数据在数据源中通过JsonPath的方式获取赋值,并生成转换后的对象,转换后的对象将作为统一格式数据传输到下游处理。
5.4 数据聚合
针对数据粒度的把控,需要对数据进行聚合,通过配置不同的聚合维度,更准确的描述当前处罚现场。
本项目使用LRU聚合的方式进行处理,对抽取下发的数据进行聚合,将聚合后的数据根据数据特征规则进行匹配,识别出特征数据补全到原始数据中,构建出标准数据进行存储应用。
LRU聚合逻辑如图所示,需将多个详情信息,根据业务规则把多条数据聚合成一个罚单。一个黑产用户可能存在大量违规信息,需要将多个规则一致、业务判定一致的数据聚合成一个罚单来管理当前批次处理。同时处罚中心是一个分布式系统,如果处罚明细分散在多个节点,到达节点时间不一致,不同的节点根据单个详情信息生成的罚单信息有可能出现数据一致性和性能问题,单纯靠数据库锁对性能和数据库压力来说不可能完成,为了保证数据一致性和清洗效率,使用数据聚合来尽可能减少数据库压力。
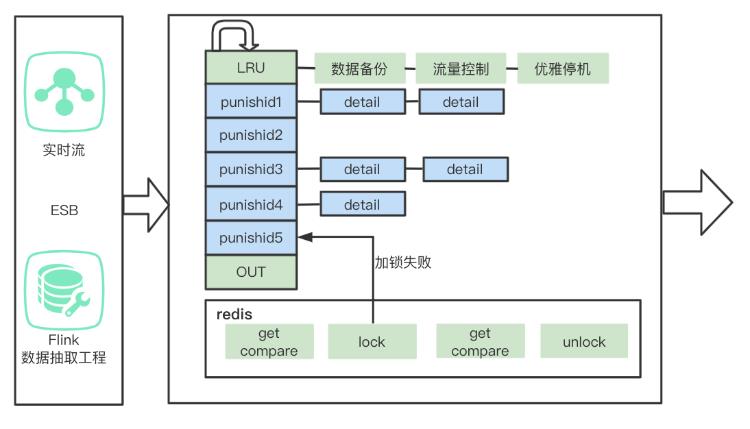
LRU负责聚合,那么数据聚合到什么程度?
我们约定可以将一批处罚数据都涵盖,然后作为冷数据释放掉,需要结合线上数据调整。
LRU的数据释放OUT阶段是数据处理阶段,可以最大化的保证分布式的数据标记冲突次数,为了解决一致性,采用redis加锁的方式
1、通过get - compare来确定本服务是否需要更新业务线标记和处罚类型
2、如果需要获取锁
3、如果获取锁失败,那么将数据按照随机值退回到LRU队列
4、如果成功那么再次get - compare 获取最新值 ,如果需要更新
5、执行更新
6、释放锁
注意:对于第一步是否需要的问题 ,要看实际锁竞争的程度,因为LRU已经将冲突进行合并并且分散化,如果冲突不多可以省去第一步,直接加锁。
5.5 数据特征识别
数据被抽取系统采集后形成统一格式数据,再经过聚合,就形成了我们的一个罚单。再对数据进行分析,获取我们需要数据特征。
将数据进一步分析是构建处罚业务数据模型重要一环,为处罚数据标准化提供数据特征。例如上面提到的处罚数据归属问题,可以在这里将数据归属通过数据特征识别将业务分类识别出来。
数据特征识别如图所示:
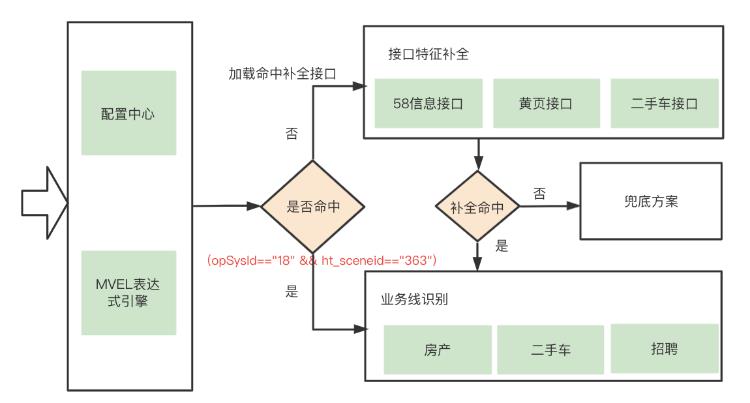
特征识别引擎
先了解下为什么要使用引擎框架
1.传统的编码需要太过精巧复杂的结构
2.逻辑经常变化
3.业务专家没有技术背景也可以支持
以上的条件完美契合我们使用场景,接下来就是选择合适我们的引擎。在设计特征识别引擎前,我们对业内常见的引擎框架Drools、Aviator、Mvel进行了调研
Drools:
优点:功能完善
缺点:配置复杂,学习成本高,使用编程语言业务专家无法独立完成规则配置
Aviator:
优点:性能优秀
缺点:没有if else、do while等语句,没有赋值语句,仅支持逻辑表达式、算术表达式、三元表达式和正则匹配。无法自定义运算符,自定义函数有局限性
Mvel:
优点:功能强大、扩展性高、支持对象属性方法、支持if else流程,语言简单
缺点:缺少可选类型安全
综上引擎框架的优缺点,Mvel的优点更适合项目的要求,因此我们选择了表达式引擎Mvel作为特征识别引擎的基础框架。
特征识别流程
首先将已知的数据特征比如:场景、数据源、处理类型、参数等作为特征,利用这个特征集,结合配置中心和MVEL表达式引擎做特征提取,如果当前特征不足以为我们提取特征,那么进入补全接口工厂中,根据数据标识命中对应的补全接口,然后在进行规则池命中(当前规则可与第一次命中一致,也可使补全专用规则)。
06
历程回顾
在处罚中心标准化建设过程中,遇到的一些问题回顾。
6.1 程序员“喜闻乐见”的FullGC
调试过程中的部分GC日志

可以发现 FullGC频繁发生,在1次/min。
初步定位存在可能存在大对象在老年代分配,开始dump内存快照分析。
1、dump内存快照
jmap -dump:format=b,file=heap.bin <pid>
2、将内存快照下载到本地使用MAT工具分析

3、发现日志类对象和esb的channel连接占用将多内存。
4、分析代码
在数据清洗中,记录了全量数据流水的日志类,一直再append对象进去,经过分析,这块记录流水可以去掉。
另外一个esb客户端连接占用内存过多问题,与esb同事沟通后,在升级esbClient最新版本之后解决。
6.2 日志引起的性能问题
在上面排查GC时发现内存快照中日志占用很大,根据快照使用Arthas观察大对象所在的方法,查看耗时情况。

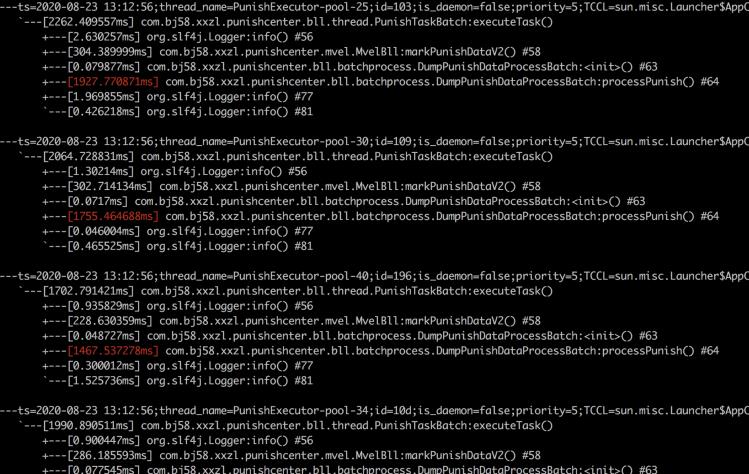
发现为了调试方便,循环打印大量日志导致,因为同步日志慢是因为大量线程阻塞等待获取锁,再去写日志。当前项目使用的log4j,写日之前会进行加锁,在高并发情况下就会出现性能问题,因此要按需进行日志打印。
最终通过断优化代码逻辑,在有限的服务器资源、数据库资源、以及可以保证正常线上读写的情况下成功达成项目目标。
07
总结
目前处罚数据标准化已经建设完成,覆盖集团已知全部数据源36个,支撑集团日均300万处罚数据流入,新业务接入成本由原来8人日降低到1h,并且支持实时数据清洗;构建的特征规则覆盖了集团所有业务,聚合后的标准数据也可以让业务为用户提供入口,用户可以看到当前被处罚的信息,用户也可操作恢复给业务带来流量,同时可对后续业务反哺提供标准数据。
作者简介
王 涛:58同城-信息安全部-后端工程师
李刚强:58同城-信息安全部-后端工程师
邢而康:58同城-信息安全部-后端工程师
以上是关于58集团处罚数据中心的设计与实践的主要内容,如果未能解决你的问题,请参考以下文章