Spark框架—RDD分区和缓存
Posted 那人独钓寒江雪.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark框架—RDD分区和缓存相关的知识,希望对你有一定的参考价值。
Spark框架—RDD分区和缓存
AccessLogAgg.scala
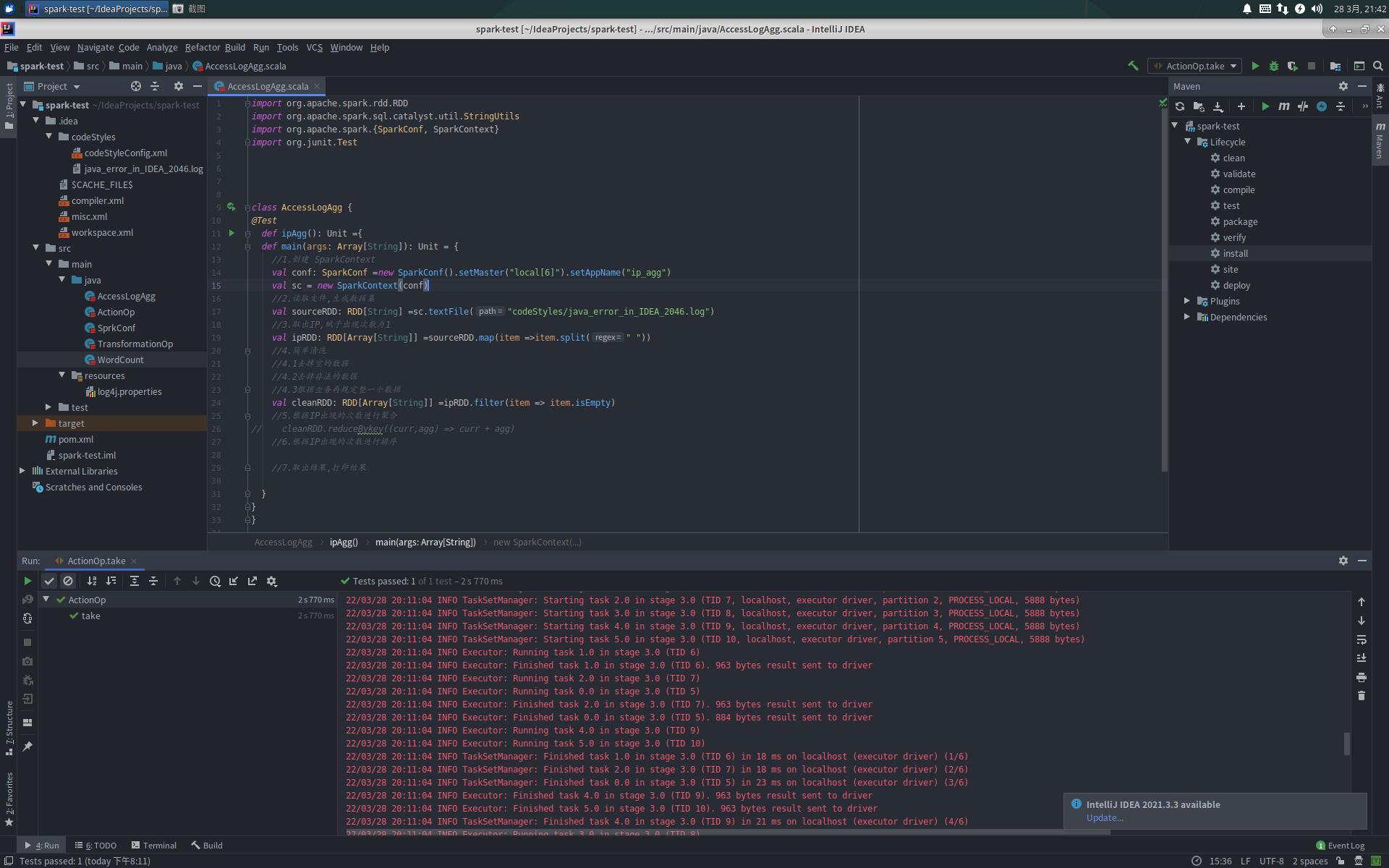
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.catalyst.util.StringUtils
import org.apache.spark.SparkConf, SparkContext
import org.junit.Test
class AccessLogAgg
@Test
def ipAgg(): Unit =
def main(args: Array[String]): Unit =
//1.创建 SparkContext
val conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("ip_agg")
val sc = new SparkContext(conf)
//2.读取文件,生成数据集
val sourceRDD: RDD[String] =sc.textFile("codeStyles/java_error_in_IDEA_2046.log")
//3.取出IP,赋予出现次数为1
val ipRDD: RDD[Array[String]] =sourceRDD.map(item =>item.split(" "))
//4.简单清洗
//4.1去掉空的数据
//4.2去掉非法的数据
//4.3根据业务再规定整一个数据
val cleanRDD: RDD[Array[String]] =ipRDD.filter(item => item.isEmpty)
//5.根据IP出现的次数进行聚合
// cleanRDD.reduceBykey((curr,agg) => curr + agg)
//6.根据IP出现的次数进行排序
//7.取出结果,打印结果
ActionOp.scala
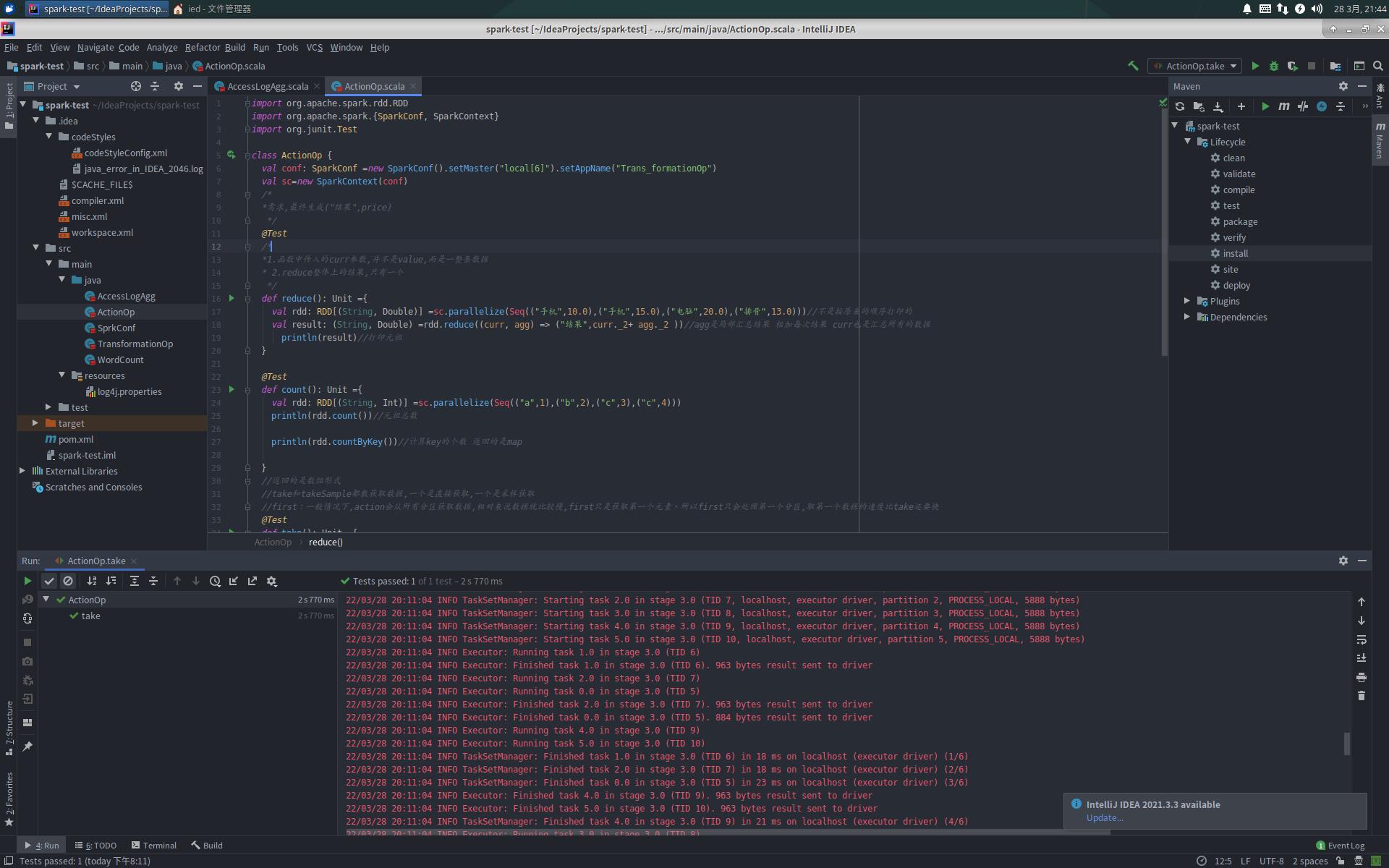
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf, SparkContext
import org.junit.Test
class ActionOp
val conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("Trans_formationOp")
val sc=new SparkContext(conf)
/*
*需求,最终生成("结果",price)
*/
@Test
/*
*1.函数中传入的curr参数,并不是value,而是一整条数据
* 2.reduce整体上的结果,只有一个
*/
def reduce(): Unit =
val rdd: RDD[(String, Double)] =sc.parallelize(Seq(("手机",10.0),("手机",15.0),("电脑",20.0),("排骨",13.0)))//不是按原来的顺序打印的
val result: (String, Double) =rdd.reduce((curr, agg) => ("结果",curr._2+ agg._2 ))//agg是局部汇总结果 相加每次结果 curr也是汇总所有的数据
println(result)//打印元祖
@Test
def count(): Unit =
val rdd: RDD[(String, Int)] =sc.parallelize(Seq(("a",1),("b",2),("c",3),("c",4)))
println(rdd.count())//元祖总数
println(rdd.countByKey())//计算key的个数 返回的是map
//返回的是数组形式
//take和takeSample都散获取数据,一个是直接获取,一个是采样获取
//first:一般情况下,action会从所有分区获取数据,相对来说数据就比较慢,first只是获取第一个元素,所以first只会处理第一个分区,取第一个数据的速度比take还要快
@Test
def take(): Unit =
val rdd: RDD[Int] =sc.parallelize(Seq(1,2,3,4,5,6))
rdd.take(3).foreach(item => println(item))//因为返回的是数组形式 所以用foreach
println(rdd.first())
rdd.takeSample(withReplacement = false,num = 3).foreach(println(_))//取三个数,没有重复值
//数学计算
//除了这四个支持意外,还有其他很多的支持,这些对于数字类型的支持都是Action
@Test
def numberic(): Unit =
val rdd: RDD[Int] =sc.parallelize(Seq(1,2,3,4,10,20,30,50,100))
println(rdd.max())
println(rdd.min())
println(rdd.mean())//求均值
println(rdd.sum())
TransformationOp.scala
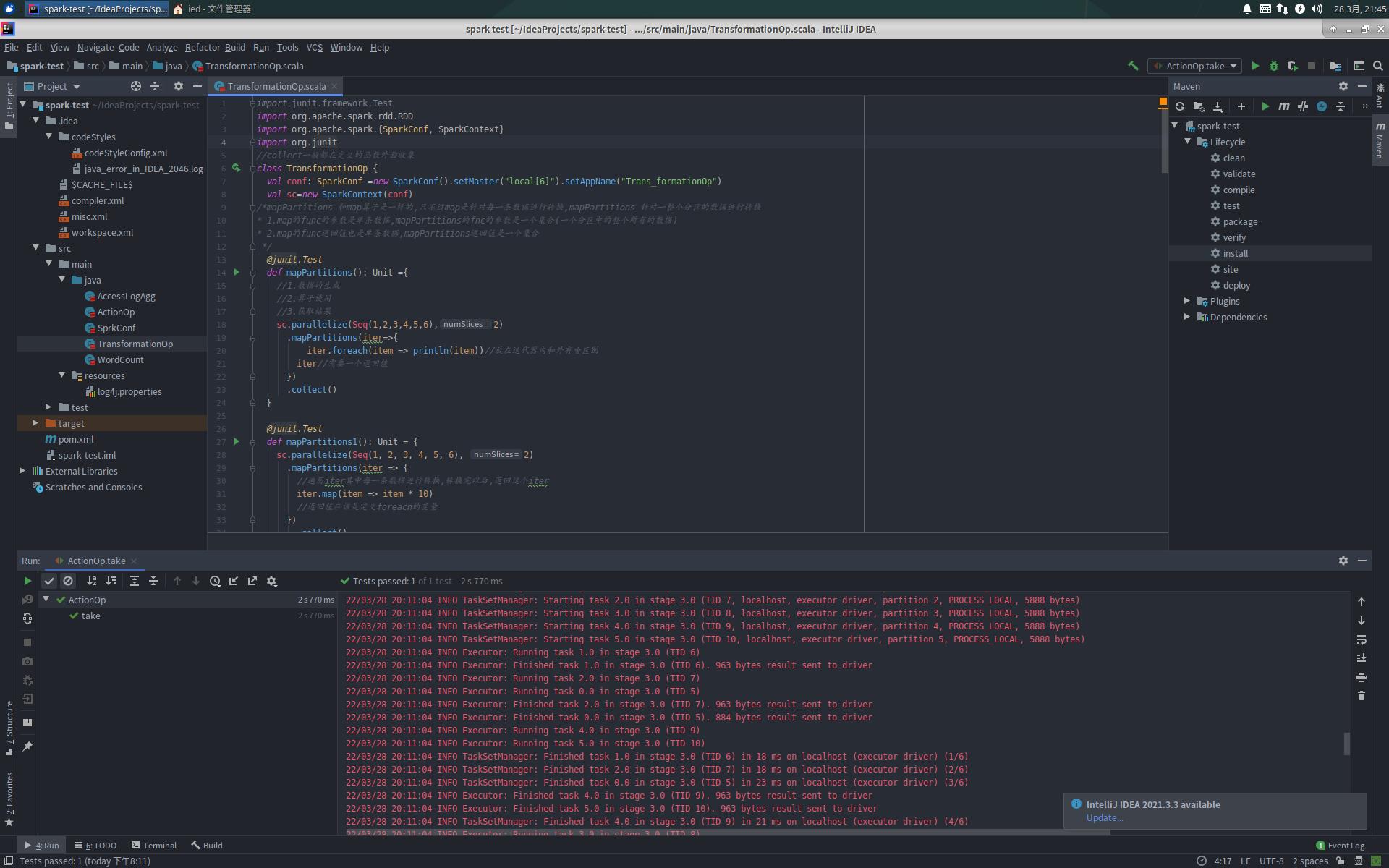
import junit.framework.Test
import org.apache.spark.rdd.RDD
import org.apache.spark.SparkConf, SparkContext
import org.junit
//collect一般都在定义的函数外面收集
class TransformationOp
val conf: SparkConf =new SparkConf().setMaster("local[6]").setAppName("Trans_formationOp")
val sc=new SparkContext(conf)
/*mapPartitions 和map算子是一样的,只不过map是针对每一条数据进行转换,mapPartitions 针对一整个分区的数据进行转换
* 1.map的func的参数是单条数据,mapPartitions的fnc的参数是一个集合(一个分区中的整个所有的数据)
* 2.map的func返回值也是单条数据,mapPartitions返回值是一个集合
*/
@junit.Test
def mapPartitions(): Unit =
//1.数据的生成
//2.算子使用
//3.获取结果
sc.parallelize(Seq(1,2,3,4,5,6),2)
.mapPartitions(iter=>
iter.foreach(item => println(item))//放在迭代器内和外有啥区别
iter//需要一个返回值
)
.collect()
@junit.Test
def mapPartitions1(): Unit =
sc.parallelize(Seq(1, 2, 3, 4, 5, 6), 2)
.mapPartitions(iter =>
//遍历iter其中每一条数据进行转换,转换完以后,返回这个iter
iter.map(item => item * 10)
//返回值应该是定义foreach的变量
)
.collect()
.foreach(item => println(item))//没有返回值
@junit.Test
def mapPartitionsWithIndex(): Unit =
sc.parallelize(Seq(1,2,3,4,5,6),2)
.mapPartitionsWithIndex((index,iter) =>
println("index:"+index)
iter.foreach(item=>println(item))
iter
)
.collect()
@junit.Test
def map1(): Unit =
sc.parallelize(Seq(1,2,3,4,5,6),2)
.mapPartitionsWithIndex((index,iter)=>
println("index:"+index)
iter.map(item=> item *10)
iter.foreach(item => println(item))
iter
)
.collect()
@junit.Test
//1.定义集合
//2.过滤数据
//3.收集结果
def filter(): Unit = //filter相当于if结构
sc.parallelize(Seq(1, 2, 3, 4, 5, 6, 7, 8, 9, 10))
.filter(item => item % 2 == 0)
.collect()
.foreach(item => println(item))
//sample 算子可以从一个数据集中抽样出来一部分,常用于减小数据集以保证运行速度,并且尽可能少规律的损失
//1.第一个参数值为投入哦,则抽样出来的数据集中可能会有重复,2.sample接受第二个参数意为抽样的比例,3.seed随机数种子,用于sample内部随即生成
//1.为true是有放回的,2.为false是无放回的
@junit.Test
//1.定义集合
//2.过滤数据
//3.收集结果
def sample(): Unit =
//sample作用:把大数据集变小,尽可能的减少数据集规律的损失
val rdd1: RDD[Int] =sc.parallelize(Seq(1,2,3,4,5,6,7,8,9,10),2)
val rdd2: RDD[Int] =rdd1.sample(withReplacement = true,0.6)//第二个参数表示从10份里面抽取6份,true表示有返回值
val result: Array[Int] =rdd2.collect()
result.foreach(item => println(item))
@junit.Test
def mapValues(): Unit =
sc.parallelize(Seq(("a",1),("b",2),("c",3),("d",4)))
.mapValues(item => item * 10)
.collect()
.foreach(println(_))
@junit.Test
def intersection(): Unit =
val rdd1: RDD[Int] =sc.parallelize(Seq(1,2,3,4,5))
val rdd2: RDD[Int] =sc.parallelize(Seq(2,5,3,6))
rdd1.intersection(rdd2)//交集
.collect()
.foreach(println(_))
@junit.Test
def union(): Unit =//并集
val rdd1: RDD[Int] =sc.parallelize(Seq(1,2,3,4,5,6))
val rdd2: RDD[Int] =sc.parallelize(Seq(3,7,8))
rdd1.union(rdd2)
.collect()
.foreach(println(_))
@junit.Test//差集
def subtract(): Unit =
val rdd1: RDD[Int] =sc.parallelize(Seq(1,2,3,4))
val rdd2: RDD[Int] =sc.parallelize(Seq(1,3,4))
rdd1.subtract(rdd2)
.collect()
.foreach(println(_))
//groupByKey 能不能在map端做Combiner有没有意义?没有的 取出key值,按照Key分组,和ReduceByKey有点类似
@junit.Test
def groupByKey(): Unit =
sc.parallelize(Seq(("a",1),("a",2),("b",1)))
.groupByKey()
.collect()
.foreach(println(_))
@junit.Test
//计算集合内的平均值
def combineByKey(): Unit =
//1.准备集合
val rdd: RDD[(String, Double)] =sc.parallelize(Seq(("zhangsan",99.0),("zhangsan",96.0),("lisi",97.0),("lisi",98.0),("zhangsan",97.0)))
//2.算子操作
//2.1createCombiner转换数据
//2.2mergeValue分区上的聚合
//2.3mergeCombiners把所有分区上的结果再次聚合,生成最终结果
val combineResult: RDD[(String, (Double, Int))] =rdd.combineByKey(
createCombiner = (curr:Double)=>(curr,1),
mergeValue=(curr:(Double,Int),nextValue:Double) =>(curr._1+nextValue,curr._2+1),
mergeCombiners = (curr:(Double,Int),agg:(Double,Int)) =>(curr._1+agg._1,curr._2+agg._2)
)
//("zhangsan",(99+96+97,3))
val resultRDD: RDD[(String, Double)] =combineResult.map(item=>(item._1,item._2._1/item._2._2))
//3.获取结果,打印结果
resultRDD.collect().foreach(println(_))
//foldByKey和spark中的reduceByKey的区别是可以指定初始值
//foldByKey和scala中的foldLeft或者foldRight区别是,这个初始值作用于每一个数据,而foldLeft只作用一次
@junit.Test
def foldByKey(): Unit =
sc.parallelize(Seq(("a",1),("a",1),("b",1)))
.foldByKey(10)((curr,agg) => curr + agg)//agg是局部变量 10是单次增加不是全体增加
.foreach(println(_))
//zeroValue:指定初始值
//seqOp:作用于每一个元素,根据初始值,进行计算
//combOp:将seqOp处理过的结果进行聚合
//aggregateByKey
@junit.Test
def aggregateByKey(): Unit =
val rdd: RDD[(String, Double)] = sc.parallelize(Seq(("手机", 10.0), ("手机", 15.0), ("电脑", 20.0)))
rdd.aggregateByKey(0.8)((zeroValue, item) => item * zeroValue, (curr, agg) => curr + agg)
.collect()
.foreach(println(_))
@junit.Test
def join(): Unit =
val rdd1: RDD[(String, Int)] =sc.parallelize(Seq(("a",1),("a",2),("b",1)))
val rdd2: RDD[(String, Int)] =sc.parallelize(Seq(("a",10),("a",11),("b",12)))
rdd1.join以上是关于Spark框架—RDD分区和缓存的主要内容,如果未能解决你的问题,请参考以下文章