Zookeeper
Posted 技术很low的瓜贼
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper相关的知识,希望对你有一定的参考价值。
文章目录
分布式
分布式技术-Zookeeper
1.Zookeeper概述
1.1概述
Zookeeper是一个开源的分布式的,为分布式应用提供协调服务的Apache项目
1.2 工作机制
- Zookeeper从设计模式角度来理解,是一个基于观察者模式设计的分布式服务管理框架
- 它负责 存储 和 管理 大家都关心的数据
- 然后接受观察者的注册,一旦这些数据发生变化
- Zookeeper就将负责通知已经注册的那些观察者做出相应的反应
- 从而实现集群中类似Master/Slave管理模式
- Zookeeper = 文件系统 + 通知机制
1.3 Zookeeper特点
- 是一个leader和多个follower来组成的集群
- 集群中只要有半数以上的节点存活,Zookeeper就能正常工作
- 全局一致性,每台服务器都保存一份相同的数据副本,无论client连接到哪台server,数据都是一致的
- 数据更新原子性,一次数据要么成功,要么失败
- 实时性,在一定时间范围内,client能读取到最新数据
- 更新的请求按照顺序执行,会按照发过来的顺序逐一执行
1.4 Zookeeper数据结构
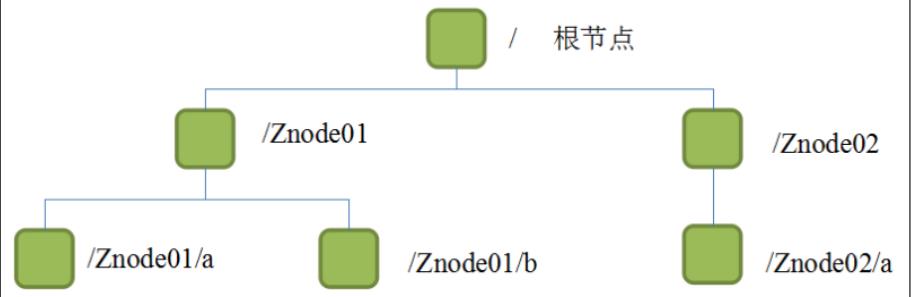
- Zookeeper数据模型的结构与linux文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode(ZookeeperNode)。
- 每一个ZNode默认能够存储1MB的数据(元数据),每个ZNode的路径都是唯一的
- 元数据(Metadata),又称中介数据,中继数据,为描述数据的数据,主要是描述数据属性的信息,用来支持如只是存储位置,历史数据,资源查找,文件记录等功能
1.5 应用场景
- 提供的服务包括:统一命名服务,统一配置管理,统一集群管理,服务器节点动态上下线,软负载均衡等
1.5.1 统一命名服务
- 在分布式环境下,通常需要对应用或服务进行统一的命名,便于识别
- 例如:服务器的IP地址不容易记,但域名相比之下却是很容易记住

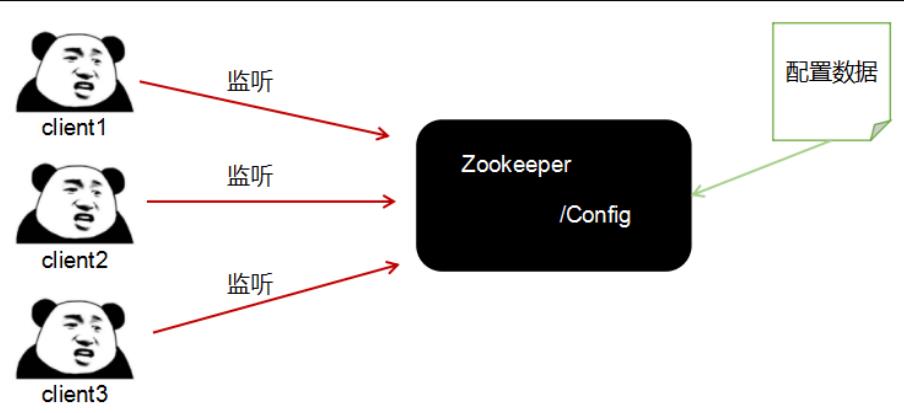
1.5.2 统一配置管理
- 分布式环境下,配置文件做同步是必经之路
- 1000台服务器,如果配置文件作出修改,那一台一台的修改,运维人员肯定会疯,Zookeeper可以做到修改一处就快速同步到每台服务器上
- 将配置管理交给Zookeeper
- 将配置信息写入到Zookeeper的某个节点上
- 每个客户端都监听这个节点
- 一旦节点中的数据文件被修改,Zookeeper就会通知每台客户端服务器
1.5.3 服务器节点动态上下线
- 客户端能实时获取服务器上下线的变化
- 例如:美团上可以看到商家营业或者打烊的状态
1.5.4 软负载均衡
- Zookeeper会记录每台服务器的访问次数,让访问数最少的服务器去处理最新的客户请求
- 如果每台服务器的访问次数都达到一样,则采取轮循

1.6下载地址
-
apache-zookeeper-3.6.0.tar.gz需要安装maven,然后再运行mvn clean install 和mvn
javadoc:aggregate,前一个命令会下载安装好多jar包,不知道要花多长时间
-
apache-zookeeper-3.6.0-bin.tar.gz已经自带所需要的各种jar包
2.Zookeeper本地模式安装
2.1本地模式安装
2.1.1 安装前准备
-
安装好JDK
-
拷贝apache-zookeeper-3.6.0-bin.tar.gz到usr目录
-
解压安装包
[root@localhost usr]# tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz -
重命名
[root@localhost usr]# mv apache-zookeeper-3.6.0-bin zookeeper
2.1.2 配置修改
-
在/usr/zookeeper/这个目录上创建zkData和zkLog目录
[root@localhost zookeeper]# mkdir zkData [root@localhost zookeeper]# mkdir zkLog -
进入/usr/zookeeper/conf这个路径,复制一份 zoo_sample.cfg 文件并命名为 zoo.cfg
[root@localhost conf]# cp zoo_sample.cfg zoo.cfg -
编辑zoo.cfg文件
-
修改dataDir路径:
dataDir=/usr/zookeeper/zkData -
添加dataLogDir路径:
dataLogDir=/usr/zookeeper/zkLog
-
2.1.3 操作Zookeeper
注:启动Zookeeper前需要先关闭防火墙
[root@localhost bin]# systemctl stop firewalld.service
-
启动Zookeeper
[root@localhost bin]# ./zkServer.sh start -
查看进程是否启动
[root@localhost bin]# jps 注意:若此处显示数据为两条,则启动正常 QuorumPeerMain:是zookeeper集群的启动入口类,是用来加载配置启动QuorumPeer线程的 -
查看状态
[root@localhost bin]# ./zkServer.sh status -
启动客户端
[root@localhost bin]# ./zkCli.sh -
退出客户端
[zk: localhost:2181(CONNECTED) 0] quit
2.2 配置参数解读
-
tickTime=2000:通信心跳数,Zookeeper服务器与客户端心跳时间,单位/毫秒
- Zookeeper使用的基本时间,服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是米格tickTime时间会发送一个心跳,时间单位/毫秒
-
initLimit=10:LF初始通信时限
-
集群中的Follower跟随者服务器与Leader领导者服务器之间,启动时能容忍的最多心跳数
-
10*2000(10个心跳时间)如果领导和跟随者没有发出心跳通信,就视为失效的连接,领导
和跟随者彻底断开
-
-
syncLimit =5:LF同步通信时限
-
集群启动后,Leader与Follower之间的最大响应时间单位,假如响应超过syncLimit *
tickTime->10秒,Leader就认为Follwer已经死掉,会将Follwer从服务器列表中删除
-
-
dataDir:数据文件目录+数据持久化路径
- 主要用于保存Zookeeper中的数据
-
dataLogDir:日志文件目录
-
clientPort =2181:客户端连接端口
- 监听客户端连接的端口
3. Zookeeper内部原理
3.1 选举机制
-
半数机制:集群中半数以上机器存活,集群可用。所以Zookeeper适合安装奇数台服务器
-
虽然在配置文件中并没有指定Master和Slave。但是,Zookeeper工作时,是有一个节点为
Leader,其他则为Follower,Leader是通过内部的选举机制临时产生的
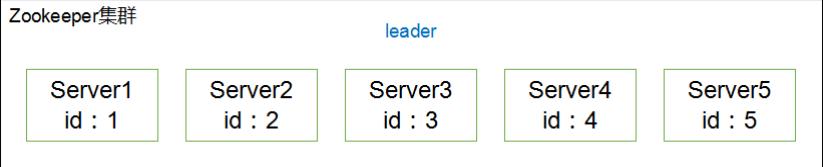
- Server1先投票,投给自己,自己为1票,没有超过半数,根本无法成为leader,顺水推舟将票数投给了id比自己大的Server2
- Server2也把自己的票数投给了自己,再加上Server1给的票数,总票数为2票,没有超过半数,也无法成为leader,也学习Server1,顺水推舟,将自己所有的票数给了id比自己大的Server3
- Server3得到了Server1和Server2的两票,再加上自己投给自己的一票。3票超过半数,顺利成为leader
- Server4和Server5都投给自己,但是无法改变Server3的票数,只好听天由命,承认Server3是leader
3.2 节点类型
- 持久型(persistent)
- 持久化目录节点:客户端与Zookeeper断开连接后,该节点依旧存在
- 持久化顺序编号目录节点:客户端与Zookeeper断开连接后,该节点依旧存在,创建ZNode时设置顺序标识,ZNode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护,如:ZNode0001,ZNode0002…
- 短暂型(ephemeral)
- 临时目录节点:客户端和服务器断开连接后,创建的节点自动删除
- 临时顺序编号目录节点:客户端与Zookeeper断开连接后,该节点被删除,创建ZNode时设置顺序标识,ZNode名称后会附加一个值,顺序号是一个单调递增的计数器,由父节点维护,如:ZNode0001,ZNode0002…
注意:注意:序号是相当于i++,和数据库中的自增长类似
3.3 监听器原理

- 在main方法中创建Zookeeper客户端的同时就会创建两个线程,一个负责网络连接通信,一个负责监听
- 监听事件就会通过网络通信发送给Zookeeper
- Zookeeper获得注册的监听事件后,立即将监听事件添加到监听列表里
- Zookeeper监听到数据变化或路径变化,就会将这个消息发送给监听线程
- 常见的监听:
- 监听节点数据的变化:get path
- 监听子节点增减的变化:Is path
- 常见的监听:
- 监听线程就会在内部调用process方法(process内容由我们实现)
3.4 写数据流程
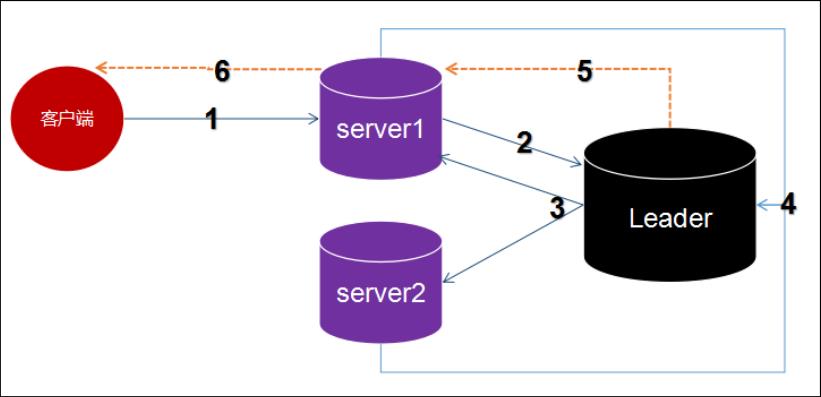
- Client 想向 ZooKeeper 的 Server1 上写数据,必须的先发送一个写的请求
- 如果Server1不是Leader,那么Server1 会把接收到的请求进一步转发给Leader。
- 这个Leader 会将写请求广播给各个Server,各个Server写成功后就会通知Leader。
- 当Leader收到半数以上的 Server 数据写成功了,那么就说明数据写成功了。
- 随后,Leader会告诉Server1数据写成功了。
- Server1会反馈通知 Client 数据写成功了,整个流程结束
Zookeeper实战知识点
4.1 分布式安装部署
集群思路:先搞定一台服务器,然后再克隆出需要的服务器数量,形成集群(注意:通常Zookeeper中服务器的数量正常为奇数台)
4.1.1 安装Zookeeper
4.1.2 配置服务器编号
-
再/usr/zookeeper/zkData中创建myid文件
[root@localhost zkData]# vi myid -
在文件中添加与server对应的编号:1
-
为其他服务其配置编号:依次递增,不能重复
4.1.3 配置zoo.cfg文件
-
打开zoo.cfg文件,添加配置
#######################cluster########################## server.1=192.168.204.141:2888:3888 server.2=192.168.204.142:2888:3888 server.3=192.168.204.143:2888:3888 -
配置参数解读 server.A=B:C:D
-
A:一个数字,表示第几号服务器
集群模式下配置的/usr/zookeeper/zkData/myid文件里面的数据就是A的值
-
B:服务器的ip地址
-
C:与集群中Leader服务器交换信息的端口
-
D:选举时专用端口,万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选
出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
-
4.1.4 配置其他服务器
-
在虚拟机数据目录下创建zk02
-
将本台服务器数据目录下的**.vmx文件和所有的.vmdk**文件拷贝到zk02下
-
虚拟机->文件->打开(选择zk02下的**.vmx**文件)
注意:如果.vmx文件打不开,可以先扫描虚拟机,扫描到以后就可以直接开启
-
开启复制好的虚拟机,弹出对话框,选择“我已复制该虚拟机”
-
进入系统后,修改linux中的ip(打开**/etc/sysconfig/network-scripts/ifcfg-eno16777736后修改IPADDR**),然后修改/usr/zookeeper/zkData/myid的数值
4.1.5 集群操作
-
每台服务器防火墙必须关闭
[root@localhost bin]# systemctl stop firewalld.service -
启动第1台
[root@localhost bin]# ./zkServer.sh start -
查看状态
[root@localhost bin]# ./zkServer.sh statusZooKeeper JMX enabled by default Using config: /opt/zookeeper/bin/../conf/zoo.cfg Client port found: 2181. Client address: localhost. 注:此处显示失败的原因是因为没有超过半数以上的服务器,所以集群失败 (防火墙没有关闭也会导致失败) Error contacting service. It is probably not running. -
若有三台服务器时显示如下(Zookeeper的选举机制)
- 查看第一台的状态:Mode: follower
- 查看第2台的状态:Mode: leader
4.2 客户端命令行操作
-
启动客户端
[root@localhost bin]# ./zkCli.sh注意:都是在/usr/zookeeper/bin/目录下
-
显示所有操作命令
help -
查看当前ZNode中所包含的内容
ls / -
查看当前节点详细数据
ls -s /-
cZxid:创建节点的事务
-
每次修改ZooKeeper状态都会收到一个zxid形式的时间戳,也就是ZooKeeper事务ID。
-
事务ID是ZooKeeper中所有修改总的次序。
-
每个修改都有唯一的zxid,如果zxid1小于zxid2,那么zxid1在zxid2之前发生。
-
-
ctime:被创建的毫秒数(从1970年开始)
-
mZxid:最后更新的事务zxid
-
mtime:最后修改的毫秒数(从1970年开始)
-
pZxid:最后更新的子节点zxid
-
cversion:创建版本号,子节点修改次数
-
dataVersion:数据变化版本号
-
aclVersion:权限版本号
-
ephemeralOwner:如果是临时节点,这个是znode拥有者的session id。如果不是临时节点
则是0。
-
dataLength:数据长度
-
numChildren:子节点数
-
-
创建节点
-
在根目录下,创建中国和美国两个节点
create /china create /usa -
在根目录下,创建俄罗斯节点,并保存“fighting”数据到节点上
create /russia "fighting" -
多级创建节点
- 在china节点下,创建shanxi“beautiful”
- china节点必须提前创建好,否则将报错节点不存在
create /china/shanxi "beautiful"
-
-
获得节点的值
get /china/shanxi -
修改节点的值
set /china/shanxi "cool" -
创建短暂节点:创建成功之后,quit退出客户端,重新连接,短暂的节点消失
create -e /usa ls / quit ls / -
创建带序号的节点
-
在俄罗斯russia下,创建3个city
create -s /russia/city # 执行三次 ls /russia [city0000000000, city0000000001, city0000000002]-
如果原来没有序号节点,序号从0开始递增。
-
如果原节点下已有2个节点,则再排序时从2开始,以此类推
-
-
-
监听节点的值变化或子节点变化(路径变化)
-
在server3主机上注册监听/usa节点的数据变化
addWatch /usa -
在Server1主机上修改/usa的数据
set /usa "telangpu" -
Server3会立刻响应
WatchedEvent state:SyncConnected type:NodeDataChanged path:/usa
-
如果在Server1的/usa下面创建子节点NewYork
create /usa/NewYork -
Server3会立刻响应
WatchedEventstate:SyncConnectedtype:NodeCreatedpath:/usa/NewYork -
删除节点
delete /usa/NewYork -
递归删除节点(非空节点,不仅删除/ru,而且/ru下的所有子节点也随之删除)
deleteall /ru
-
4.3 分布式锁
-
锁:我们在多线程中接触过,作用就是让当前的资源不会被其他线程访问!
-
我的日记本,不可以被别人看到。所以要锁在保险柜中
-
当我打开锁,将日记本拿走了,别人才能使用这个保险柜
-
-
在zookeeper中使用传统的锁引发的 “羊群效应” :1000个人创建节点,只有一个人能成功,999
人需要等待!
-
羊群是一种很散乱的组织,平时在一起也是盲目地左冲右撞,但一旦有一只头羊动起来,其他的羊
也会不假思索地一哄而上,全然不顾旁边可能有的狼和不远处更好的草。羊群效应就是比喻人都有
一种从众心理,从众心理很容易导致盲从,而盲从往往会陷入骗局或遭到失败。
-
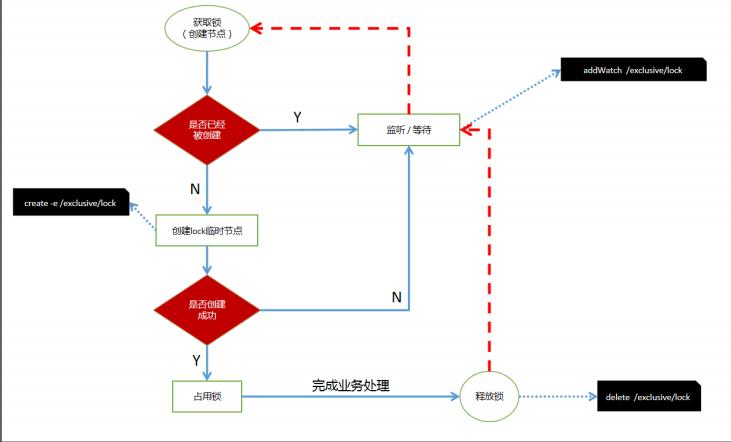
避免“羊群效应”,zookeeper采用分布式锁
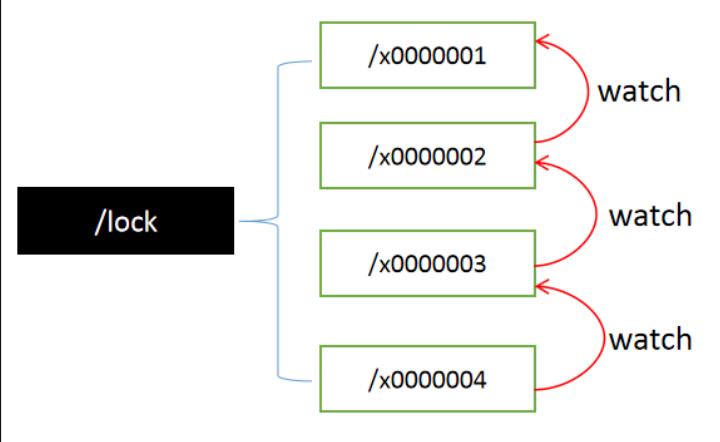
- 所有请求进来,在/lock下创建 临时顺序节点 ,放心,zookeeper会帮 你编号排序
- 判断自己是不是/lock下最小的节点
- 是,获得锁(创建节点)
- 否,对前面小我一级的节点进行监听
- 获得锁请求,处理完业务逻辑,释放锁(删除节点),后一个节点得到通 知(比你年轻的死了,你成为最嫩的了)
- 重复步骤2
以上是关于Zookeeper的主要内容,如果未能解决你的问题,请参考以下文章