Elastic:使用 Docker 安装 Elastic Stack 8.0 并开始使用
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elastic:使用 Docker 安装 Elastic Stack 8.0 并开始使用相关的知识,希望对你有一定的参考价值。
Elastic Stack 8.0 终于于最近发布了。在我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单” 我已经详细地描述了如何在本地部署 Elasticsearch 及 Kibana。设置 Elasticsearch 的最简单方法是使用 Elastic Cloud 上的 Elasticsearch Service 创建托管部署。 如果你更喜欢管理自己的测试环境,可以使用 Docker 安装和运行 Elasticsearch。在今天的演示中,我将使用 Docker 来安装 Elastic Stack 8.0,并对它的使用进行展示。
运行 Elasticsearch
我们需要在自己的电脑上安装好 Docker Desktop。接着我们运行如下的命令:
docker network create elastic
docker pull docker.elastic.co/elasticsearch/elasticsearch:8.0.0
docker run --name es-node01 --net elastic -p 9200:9200 -p 9300:9300 -it docker.elastic.co/elasticsearch/elasticsearch:8.0.0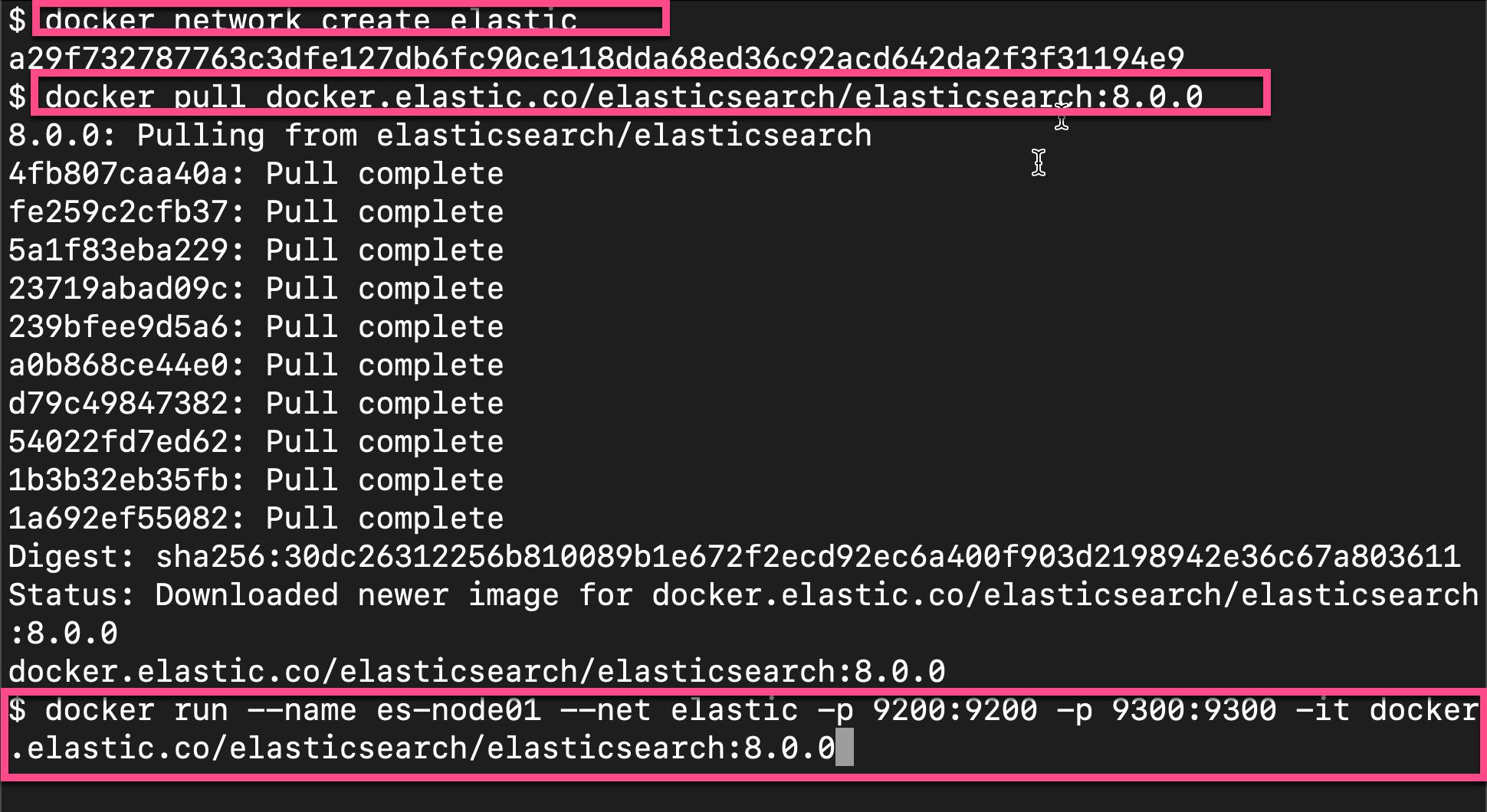
当我们第一次启动 Elasticsearch 时,以下安全配置会自动发生:
- 为传输层和 HTTP 层生成证书和密钥。
- 传输层安全 (TLS) 配置设置写入 elasticsearch.yml。
- 为弹性用户生成密码。
- 为 Kibana 生成一个注册令牌。
--------------------------------------------------------------------------------
-> Elasticsearch security features have been automatically configured!
-> Authentication is enabled and cluster connections are encrypted.
-> Password for the elastic user (reset with `bin/elasticsearch-reset-password -u elastic`):
21=0VbI9nz+kjR69l1WT
-> HTTP CA certificate SHA-256 fingerprint:
05661cff7bef5f59ae84442e25d9f1821662f82ed958b1b1da6147950943ecc3
-> Configure Kibana to use this cluster:
* Run Kibana and click the configuration link in the terminal when Kibana starts.
* Copy the following enrollment token and paste it into Kibana in your browser (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjAuMCIsImFkciI6WyIxNzIuMjQuMC4yOjkyMDAiXSwiZmdyIjoiMDU2NjFjZmY3YmVmNWY1OWFlODQ0NDJlMjVkOWYxODIxNjYyZjgyZWQ5NThiMWIxZGE2MTQ3OTUwOTQzZWNjMyIsImtleSI6Ilc5TWktMzRCTVZaSFJZRHZXc3piOmk5b1RXWkdFUV95VVoxeUFtU0N0bFEifQ==
-> Configure other nodes to join this cluster:
* Copy the following enrollment token and start new Elasticsearch nodes with `bin/elasticsearch --enrollment-token <token>` (valid for the next 30 minutes):
eyJ2ZXIiOiI4LjAuMCIsImFkciI6WyIxNzIuMjQuMC4yOjkyMDAiXSwiZmdyIjoiMDU2NjFjZmY3YmVmNWY1OWFlODQ0NDJlMjVkOWYxODIxNjYyZjgyZWQ5NThiMWIxZGE2MTQ3OTUwOTQzZWNjMyIsImtleSI6IlhkTWktMzRCTVZaSFJZRHZXc3pvOnRoQWxhcmxYU3Myb0ZHX2g5czA1Z1EifQ==
If you're running in Docker, copy the enrollment token and run:
`docker run -e "ENROLLMENT_TOKEN=<token>" docker.elastic.co/elasticsearch/elasticsearch:8.0.0`
--------------------------------------------------------------------------------你可能需要向上翻滚才能在 terminal 中看到 password 及 enrollment token(注册令牌)。
复制生成的密码和注册令牌并将其保存在安全位置。 这些值仅在你第一次启动 Elasticsearch 时显示。 你将使用这些将 Kibana 注册到你的 Elasticsearch 集群并登录。
注意:如果需要重置 elastic 用户或其他内置用户的密码,请运行 elasticsearch-reset-password 工具。 要为 Kibana 或 Elasticsearch 节点生成新的注册令牌,请运行 elasticsearch-create-enrollment-token 工具。 这些工具在 Elasticsearch bin 目录中可以找到。
如果我们需要访问 Elasticsearch,请参阅我之前的文章 “Elastic Stack 8.0 安装 - 保护你的 Elastic Stack 现在比以往任何时候都简单”。
安装及运行 Kibana
要使用直观的 UI 分析、可视化和管理 Elasticsearch 数据,请安装 Kibana。
在新的终端会话中,运行:
docker pull docker.elastic.co/kibana/kibana:8.0.0
docker run --name kib-01 --net elastic -p 5601:5601 docker.elastic.co/kibana/kibana:8.0.0请注意在上面,我们使用了 --net 来定义 network。请使用和上面在 Elasticsearch 安装中一样的 network。
当我们上面的命令成功运行后,我们可以看到如下的输出:
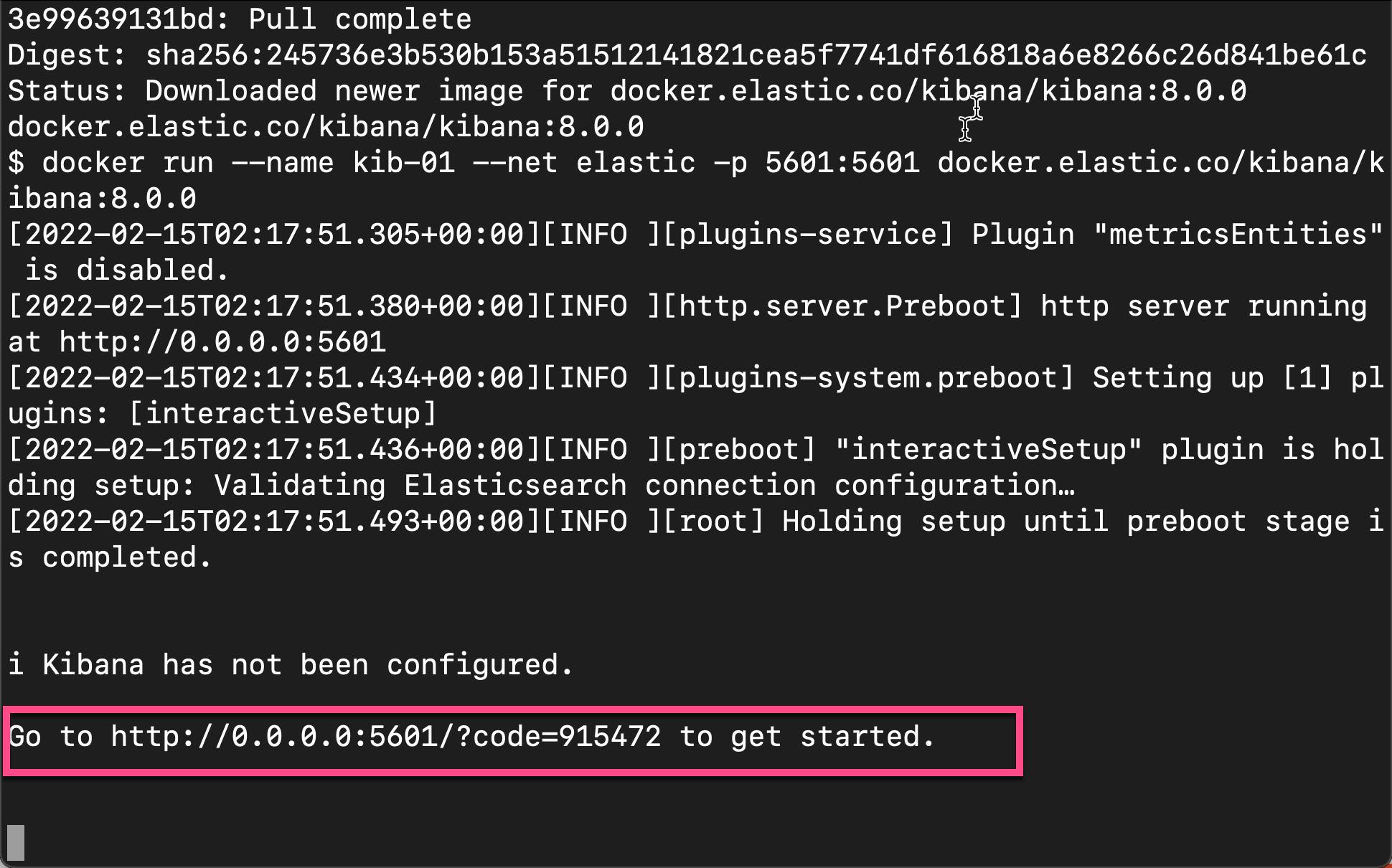
在上面,它让我到地址 http://0.0.0.0:5601/?code=915472 去配置 Kibana。在浏览器中打开上面的地址:
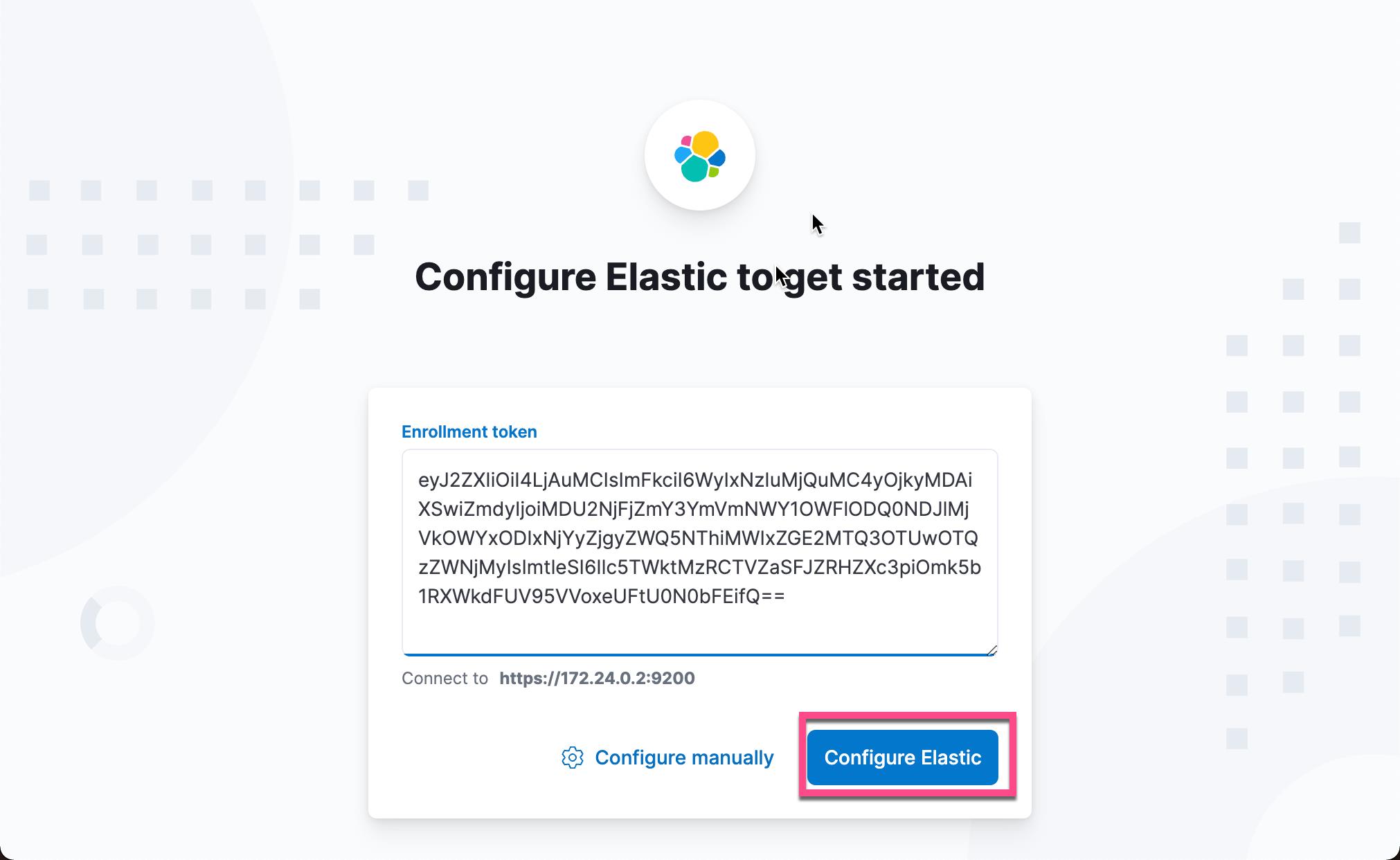
我们把在 Elasticsearch 启动时的 Kibana enrollment token 拷贝进上面的输入框,并点击 Configure Elastic:
等配置完毕后,我们把之前生成的 elastic 超级用户的密码输入进如下的登录页面:

点击 Log in,这样我们就进行入到 Kibana 的界面:
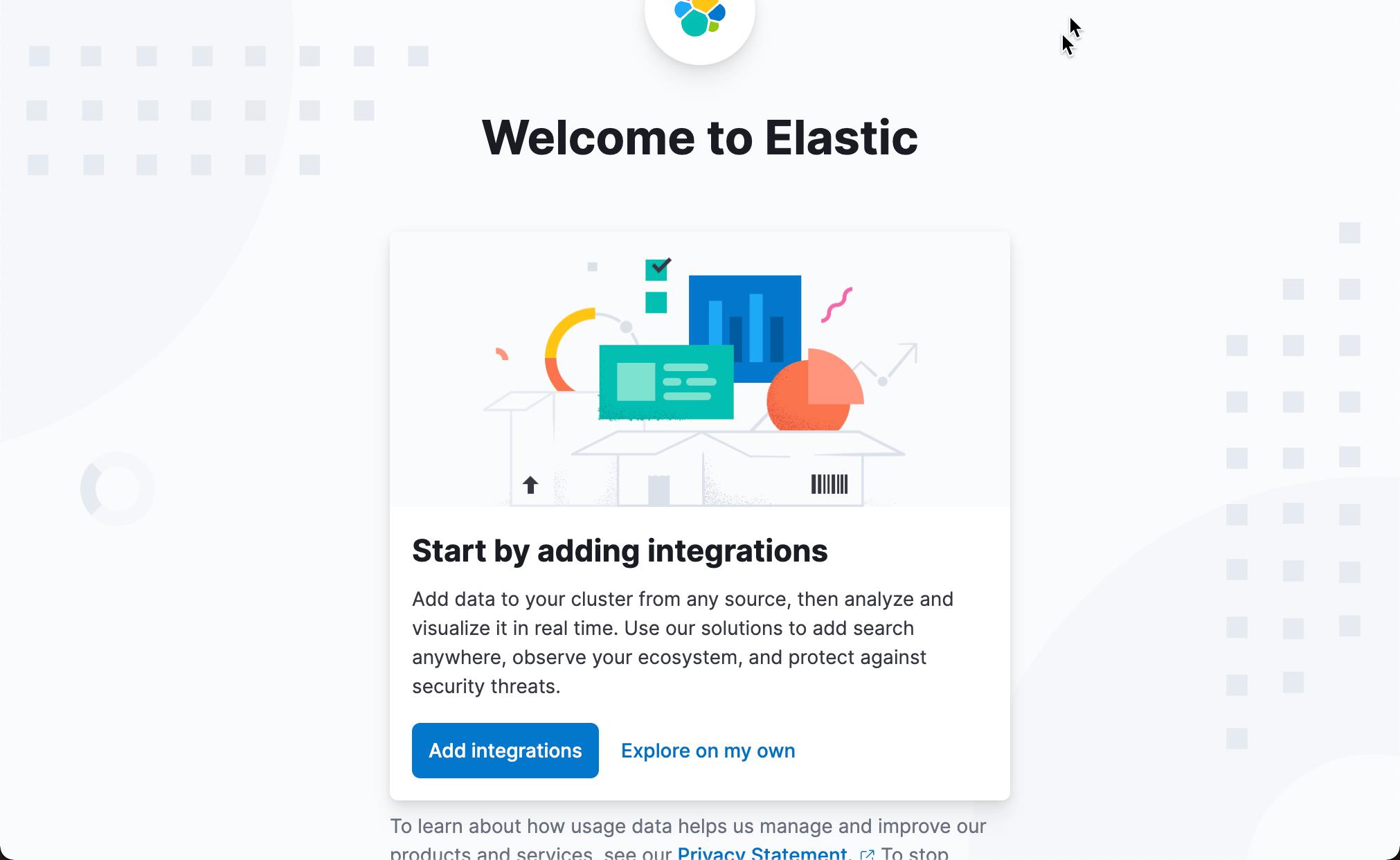
在上面,默认的情况是添加 integrations。这个是用来摄入数据到 Elasticsearch 中的。在今天的展示中,我就先不进行展示了。我们点击 Explore on my own:
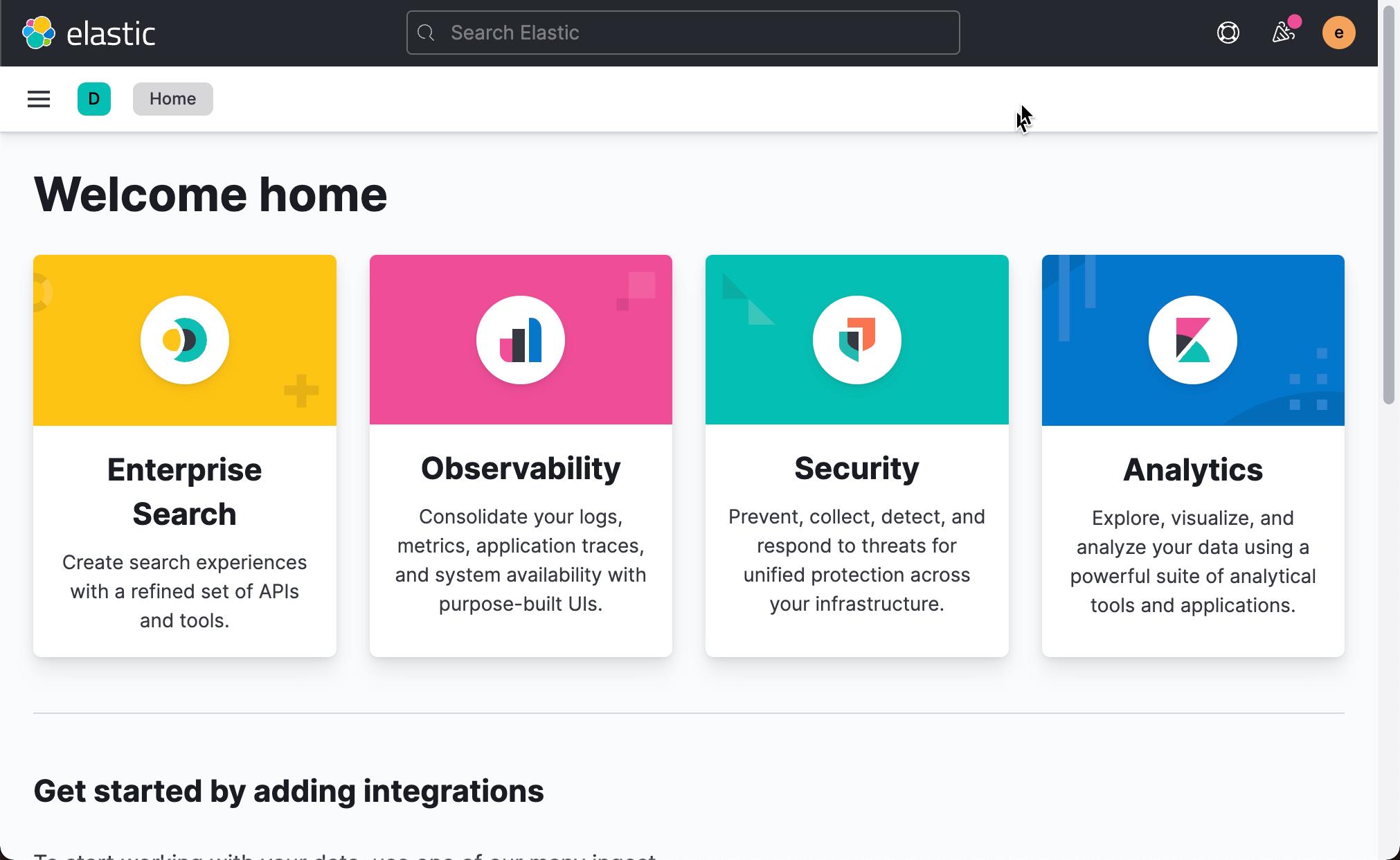
这样我们就成功地进入到 Kibana 界面了。
至此,我们已经成功地通过 docker 启动了 Elasticsearch 及 Kibana。我们可以通过如下的命令来进行查看:
docker ps$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
7ad78365a6a4 docker.elastic.co/kibana/kibana:8.0.0 "/bin/tini -- /usr/l…" 13 minutes ago Up 13 minutes 0.0.0.0:5601->5601/tcp kib-01
438986615af6 docker.elastic.co/elasticsearch/elasticsearch:8.0.0 "/bin/tini -- /usr/l…" 24 minutes ago Up 24 minutes 0.0.0.0:9200->9200/tcp, 0.0.0.0:9300->9300/tcp es-node01我们可以看到名叫 kib-01 及 es-node01 的两个容器已经在成功运行。
发送请求到 Elasticsearch
你使用 REST API 向 Elasticsearch 发送数据和其他请求。 这使你可以使用任何发送 HTTP 请求的客户端(例如 curl)与 Elasticsearch 交互。 你还可以使用 Kibana 的控制台向 Elasticsearch 发送请求。

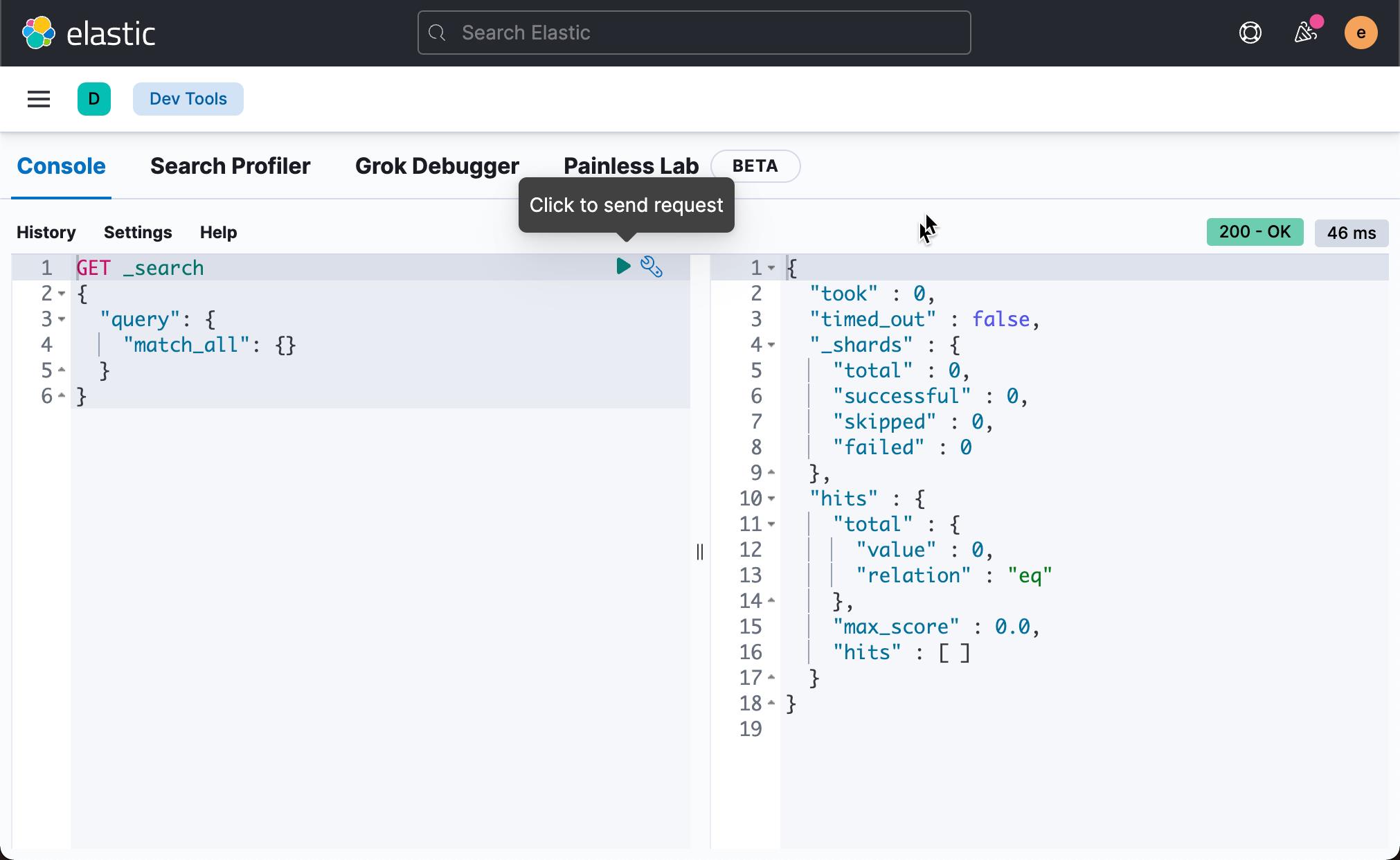
比如,我们可以尝试如下的命令来查看请求的结果:
也许很多开发者想知道如何使用 curl 来得到请求的数据。我们不能像之前的这种方法来获取数据:
curl -X GET http://localhost:9200/这其中的原因是 Elasticsearch 由于启动了 https 连接,我们必须使用证书来访问 Elasticsearch。Elasticsearch 的访问地址为 https://localhost:9200,而不是 http://localhost:9200。那么我们该如何获取这个证书呢?
我们可以通过如下的命令来获取 Elasticsearch 容器的名称:
docker ps
我们可以通过如下的命令来登录容器:
docker exec -it es-node01 /bin/bash我们可以通过如下的方式来找到 Elasticsearch 在启动时生成的证书位置:
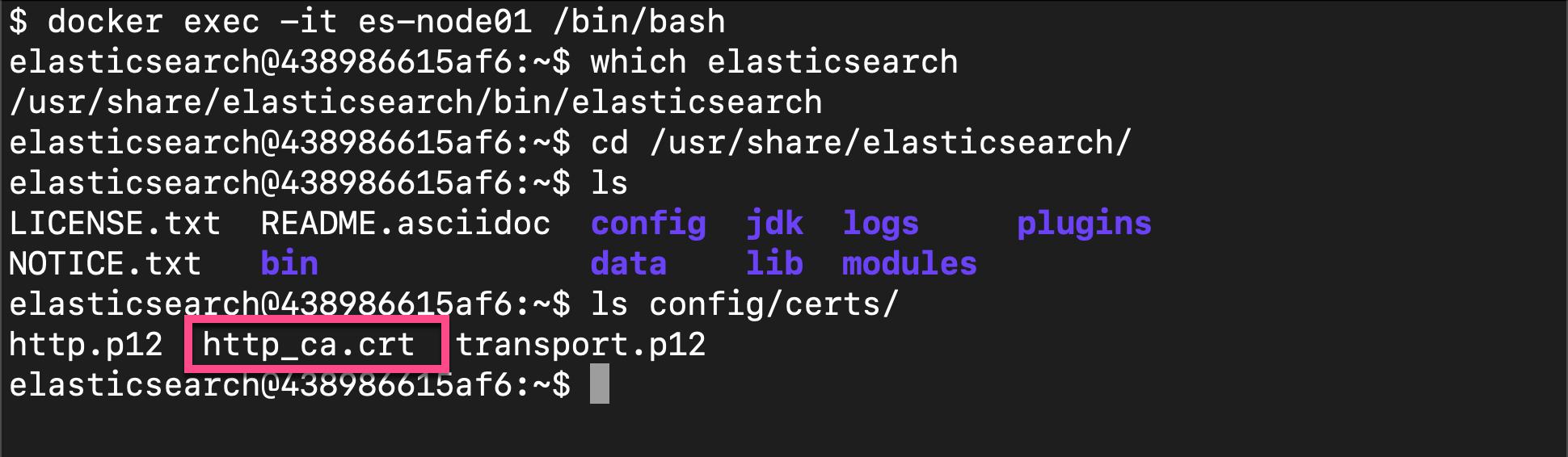
在上面,我们可以看到 Elasticsearch 所生成的证书。这个证书的名称叫做 http_ca.crt。我们可以通过如下的方式来把这个证书拷贝出来:
docker cp es-node01:/usr/share/elasticsearch/config/certs/http_ca.crt .$ pwd
/Users/liuxg/data/elastic8
$ docker cp es-node01:/usr/share/elasticsearch/config/certs/http_ca.crt .
$ ls
http_ca.crt有了这个证书,我们可以使用如下的命令通过 curl 来访问 Elasticsearch:
curl -X GET --cacert ./http_ca.crt -u elastic:21=0VbI9nz+kjR69l1WT https://localhost:9200/在上面的命令中,请记住需要替换上面的 -u 中的用户名及密码。另外注意的是我们访问的地址是 https://localhost:9200/ 而不是以前的 http://localhost:9200。
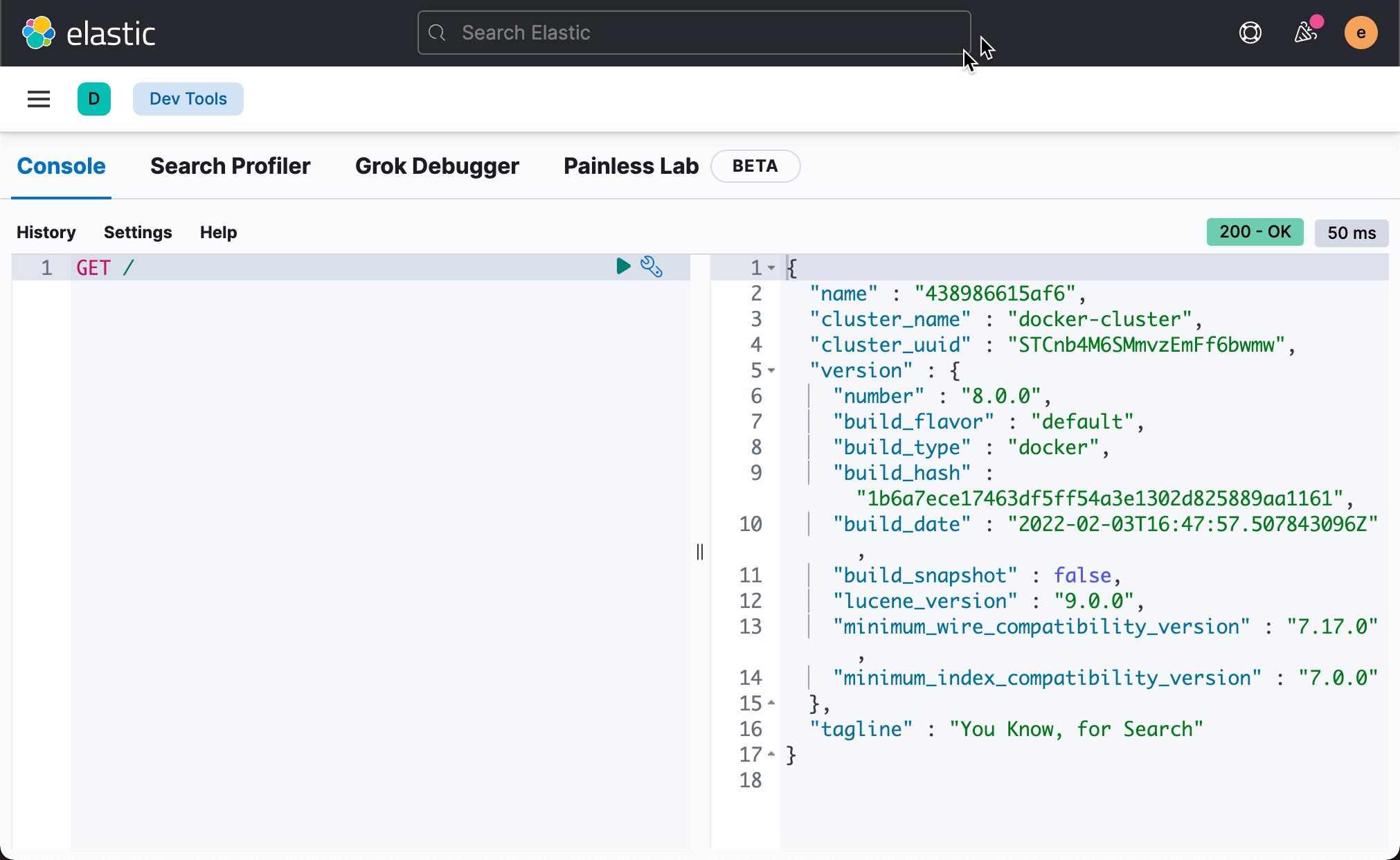
上面的命令执行的结果为:
$ curl -X GET --cacert ./http_ca.crt -u elastic:21=0VbI9nz+kjR69l1WT https://localhost:9200/
"name" : "438986615af6",
"cluster_name" : "docker-cluster",
"cluster_uuid" : "STCnb4M6SMmvzEmFf6bwmw",
"version" :
"number" : "8.0.0",
"build_flavor" : "default",
"build_type" : "docker",
"build_hash" : "1b6a7ece17463df5ff54a3e1302d825889aa1161",
"build_date" : "2022-02-03T16:47:57.507843096Z",
"build_snapshot" : false,
"lucene_version" : "9.0.0",
"minimum_wire_compatibility_version" : "7.17.0",
"minimum_index_compatibility_version" : "7.0.0"
,
"tagline" : "You Know, for Search"
添加数据
你将数据作为称为文档的 JSON 对象添加到 Elasticsearch。 Elasticsearch 将这些文档存储在可搜索的索引中。
对于时间序列数据,例如日志和指标,你通常将文档添加到由多个自动生成的支持索引组成的数据流中。
数据流需要与其名称匹配的索引模板。 Elasticsearch 使用这个模板来配置流的后备索引。 发送到数据流的文档必须具有 @timestamp 字段。
添加单个文档
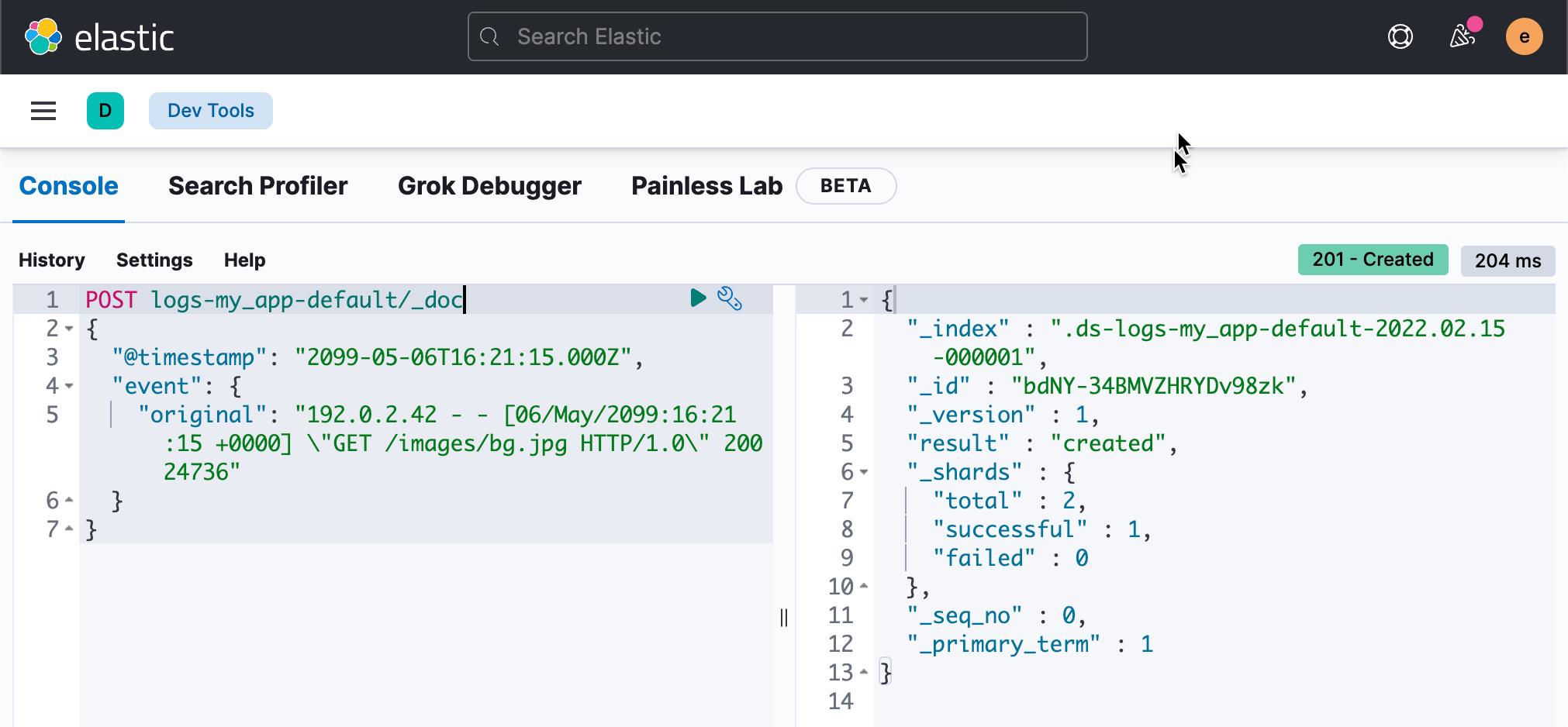
提交以下索引请求以将单个日志条目添加到 logs-my_app-default 数据流。 由于 logs-my_app-default 不存在,请求会使用内置的 logs-*-* 索引模板自动创建它。
POST logs-my_app-default/_doc
"@timestamp": "2099-05-06T16:21:15.000Z",
"event":
"original": "192.0.2.42 - - [06/May/2099:16:21:15 +0000] \\"GET /images/bg.jpg HTTP/1.0\\" 200 24736"
响应包括 Elasticsearch 为文档生成的元数据:
- 包含文档的支持 _index。 Elasticsearch 会自动生成支持索引的名称。
- 索引中文档的唯一 _id。
添加多个文档
使用 _bulk 端点在一个请求中添加多个文档。 批量数据必须是换行符分隔的 JSON (NDJSON)。 每行必须以换行符 (\\n) 结尾,包括最后一行。
PUT logs-my_app-default/_bulk
"create":
"@timestamp": "2099-05-07T16:24:32.000Z", "event": "original": "192.0.2.242 - - [07/May/2020:16:24:32 -0500] \\"GET /images/hm_nbg.jpg HTTP/1.0\\" 304 0"
"create":
"@timestamp": "2099-05-08T16:25:42.000Z", "event": "original": "192.0.2.255 - - [08/May/2099:16:25:42 +0000] \\"GET /favicon.ico HTTP/1.0\\" 200 3638" 如果这个时候我们使用如下的命令来查看当前的索引:
GET _cat/indices我们会发现:
yellow open .ds-logs-my_app-default-2022.02.15-000001 a4I6Rzj_S6yPC0Dww6OzTg 1 1 3 0 8.3kb 8.3kb我们可以看到没有我们之前的那种我们想要的 logs-my_app-default 索引名,这是因为我们的索引名匹配内置的索引模板 logs-*-*:
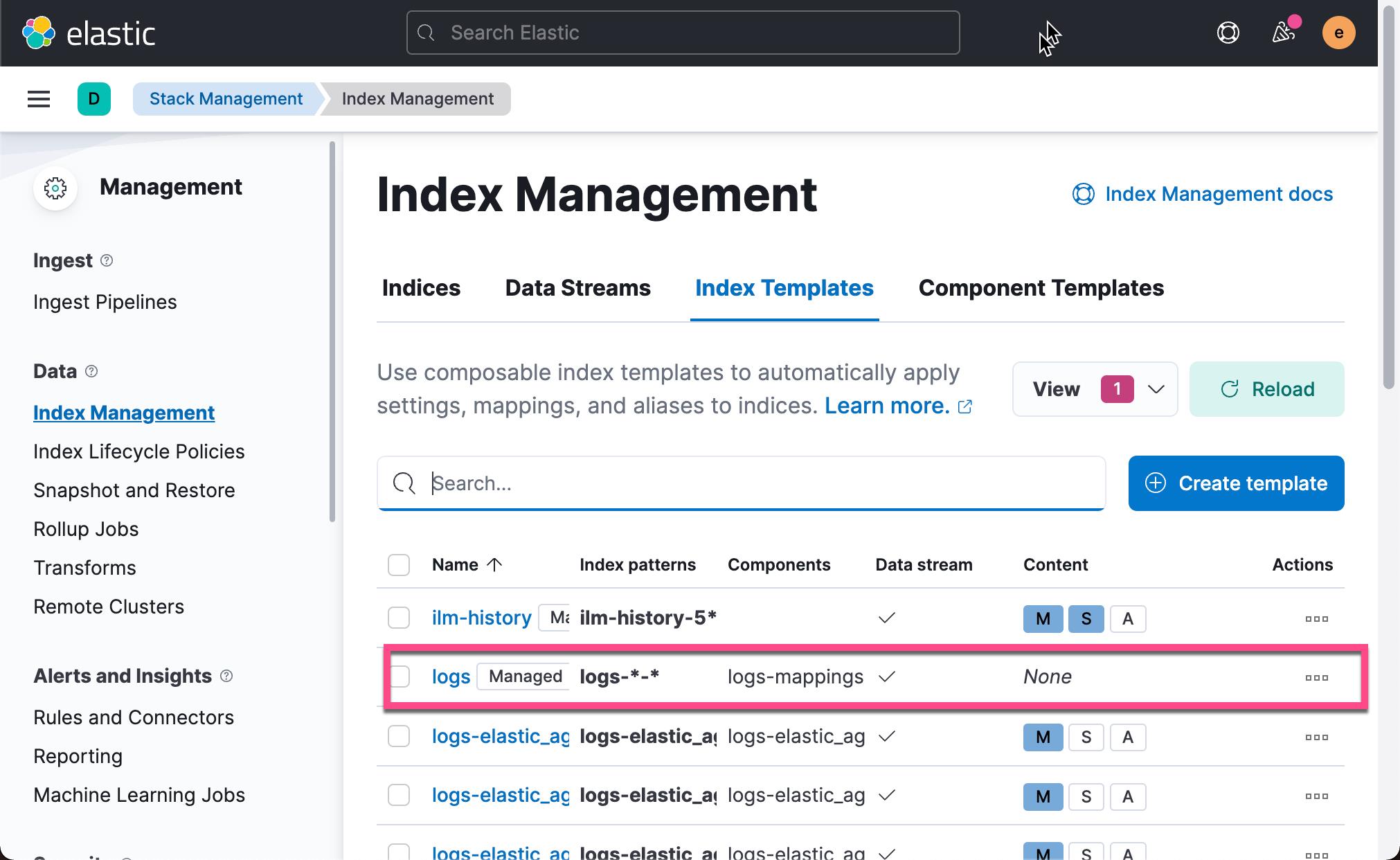
有关索引模板的内容,请参阅我之前的另外一篇文章 “Elastic:Data stream 在索引生命周期管理中的应用”。
搜索数据
索引文档可用于近乎实时的搜索。 以下搜索匹配 logs-my_app-default 中的所有日志条目,并按 @timestamp 降序对它们进行排序。
GET logs-my_app-default/_search
"query":
"match_all":
,
"sort": [
"@timestamp": "desc"
]
默认情况下,响应的 hits 部分最多包含与搜索匹配的前 10 个文档。 每个命中的 _source 包含索引期间提交的原始 JSON 对象。
"took" : 2,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 3,
"relation" : "eq"
,
"max_score" : null,
"hits" : [
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "ctNa-34BMVZHRYDvfszg",
"_score" : null,
"_source" :
"@timestamp" : "2099-05-08T16:25:42.000Z",
"event" :
"original" : """192.0.2.255 - - [08/May/2099:16:25:42 +0000] "GET /favicon.ico HTTP/1.0" 200 3638"""
,
"sort" : [
4081940742000
]
,
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "cdNa-34BMVZHRYDvfszg",
"_score" : null,
"_source" :
"@timestamp" : "2099-05-07T16:24:32.000Z",
"event" :
"original" : """192.0.2.242 - - [07/May/2020:16:24:32 -0500] "GET /images/hm_nbg.jpg HTTP/1.0" 304 0"""
,
"sort" : [
4081854272000
]
,
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "bdNY-34BMVZHRYDv98zk",
"_score" : null,
"_source" :
"@timestamp" : "2099-05-06T16:21:15.000Z",
"event" :
"original" : """192.0.2.42 - - [06/May/2099:16:21:15 +0000] "GET /images/bg.jpg HTTP/1.0" 200 24736"""
,
"sort" : [
4081767675000
]
]
获得特定的字段
对于大型文档,解析整个 _source 很麻烦。 要将其从响应中排除,请将 _source 参数设置为 false。 相反,请使用 fields 参数来检索你想要的字段。
GET logs-my_app-default/_search
"query":
"match_all":
,
"fields": [
"@timestamp"
],
"_source": false,
"sort": [
"@timestamp": "desc"
]
响应包含每个命中的字段值作为数组。
"took" : 4,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 3,
"relation" : "eq"
,
"max_score" : null,
"hits" : [
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "ctNa-34BMVZHRYDvfszg",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-08T16:25:42.000Z"
]
,
"sort" : [
4081940742000
]
,
...搜索 date range
要在特定时间或 IP 范围内进行搜索,请使用范围查询。
GET logs-my_app-default/_search
"query":
"range":
"@timestamp":
"gte": "2099-05-05",
"lt": "2099-05-08"
,
"fields": [
"@timestamp"
],
"_source": false,
"sort": [
"@timestamp": "desc"
]
上面的命令执行的结果为:
"took" : 2,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 2,
"relation" : "eq"
,
"max_score" : null,
"hits" : [
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "cdNa-34BMVZHRYDvfszg",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-07T16:24:32.000Z"
]
,
"sort" : [
4081854272000
]
,
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "bdNY-34BMVZHRYDv98zk",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-06T16:21:15.000Z"
]
,
"sort" : [
4081767675000
]
]
你可以使用日期数学来定义相对时间范围。 以下查询搜索过去一天的数据,这些数据不会匹配 logs-my_app-default 中的任何日志条目。
GET logs-my_app-default/_search
"query":
"range":
"@timestamp":
"gte": "now-1d/d",
"lt": "now/d"
,
"fields": [
"@timestamp"
],
"_source": false,
"sort": [
"@timestamp": "desc"
]
从非结构化内容中提取字段
你可以在搜索期间从非结构化内容(例如日志消息)中提取运行时字段。
使用以下搜索从 event.original 中提取 source.ip 运行时字段。 要将其包含在响应中,请将 source.ip 添加到 fields 参数。
GET logs-my_app-default/_search
"runtime_mappings":
"source.ip":
"type": "ip",
"script": """
String sourceip=grok('%IPORHOST:sourceip .*').extract(doc[ "event.original" ].value)?.sourceip;
if (sourceip != null) emit(sourceip);
"""
,
"query":
"range":
"@timestamp":
"gte": "2099-05-05",
"lt": "2099-05-08"
,
"fields": [
"@timestamp",
"source.ip"
],
"_source": false,
"sort": [
"@timestamp": "desc"
]
上面命令运行的结果为:
"took" : 1,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 2,
"relation" : "eq"
,
"max_score" : null,
"hits" : [
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "cdNa-34BMVZHRYDvfszg",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-07T16:24:32.000Z"
],
"source.ip" : [
"192.0.2.242"
]
,
"sort" : [
4081854272000
]
,
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "bdNY-34BMVZHRYDv98zk",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-06T16:21:15.000Z"
],
"source.ip" : [
"192.0.2.42"
]
,
"sort" : [
4081767675000
]
]
在上面的命令中,它是用来 runtime fields 来提前我们需要的字段。有关 runtime fields 的更多知识请阅读文章 “Elastic:开发者上手指南” 里的 runtime fields 文章。
Combine queries
你可以使用 bool 查询来组合多个查询。 以下搜索结合了两个范围查询:一个在 @timestamp 上,一个在 source.ip 运行时字段上。
GET logs-my_app-default/_search
"runtime_mappings":
"source.ip":
"type": "ip",
"script": """
String sourceip=grok('%IPORHOST:sourceip .*').extract(doc[ "event.original" ].value)?.sourceip;
if (sourceip != null) emit(sourceip);
"""
,
"query":
"bool":
"filter": [
"range":
"@timestamp":
"gte": "2099-05-05",
"lt": "2099-05-08"
,
"range":
"source.ip":
"gte": "192.0.2.0",
"lte": "192.0.2.240"
]
,
"fields": [
"@timestamp",
"source.ip"
],
"_source": false,
"sort": [
"@timestamp": "desc"
]
上面的命令执行的结果为:
"took" : 2,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 1,
"relation" : "eq"
,
"max_score" : null,
"hits" : [
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "bdNY-34BMVZHRYDv98zk",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-06T16:21:15.000Z"
],
"source.ip" : [
"192.0.2.42"
]
,
"sort" : [
4081767675000
]
]
聚合数据
使用聚合将数据汇总为指标、统计数据或其他分析。
以下搜索使用聚合来使用 http.response.body.bytes 运行时字段计算 average_response_size。 聚合仅在与查询匹配的文档上运行。
GET logs-my_app-default/_search
"runtime_mappings":
"http.response.body.bytes":
"type": "long",
"script": """
String bytes=grok('%COMMONAPACHELOG').extract(doc[ "event.original" ].value)?.bytes;
if (bytes != null) emit(Integer.parseInt(bytes));
"""
,
"aggs":
"average_response_size":
"avg":
"field": "http.response.body.bytes"
,
"query":
"bool":
"filter": [
"range":
"@timestamp":
"gte": "2099-05-05",
"lt": "2099-05-08"
]
,
"fields": [
"@timestamp",
"http.response.body.bytes"
],
"_source": false,
"sort": [
"@timestamp": "desc"
]
上面的命令运行的结果为:
"took" : 1,
"timed_out" : false,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
,
"hits" :
"total" :
"value" : 2,
"relation" : "eq"
,
"max_score" : null,
"hits" : [
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "cdNa-34BMVZHRYDvfszg",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-07T16:24:32.000Z"
],
"http.response.body.bytes" : [
0
]
,
"sort" : [
4081854272000
]
,
"_index" : ".ds-logs-my_app-default-2022.02.15-000001",
"_id" : "bdNY-34BMVZHRYDv98zk",
"_score" : null,
"fields" :
"@timestamp" : [
"2099-05-06T16:21:15.000Z"
],
"http.response.body.bytes" : [
24736
]
,
"sort" : [
4081767675000
]
]
,
"aggregations" :
"average_response_size" :
"value" : 12368.0
了解更多的搜索选项
要继续探索,请将更多数据索引到你的数据流并查看常用搜索选项。
清理
当我们已经完成了我们的练习后,我们可以使用如下的命令来进行清理:
DELETE _data_stream/logs-my_app-default上述命令将删除你的测试 data stream 及相关的支撑索引。
当然我们甚至可以使用如下的命令来彻底地删除你的测试环境以节省存储空间:
docker stop es-node01
docker stop kib-01上述两个命令将停止 Elasticsearch 及 Kibana 容器。我们可以使用如下的命令来彻底删除容器及网络:
docker network rm elastic
docker rm es-node01
docker rm kib-01以上是关于Elastic:使用 Docker 安装 Elastic Stack 8.0 并开始使用的主要内容,如果未能解决你的问题,请参考以下文章