Elasticsearch:运用 doc-value-only 字段来实现更快的索引速度并节省空间 - Elastic Stack 8.1
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:运用 doc-value-only 字段来实现更快的索引速度并节省空间 - Elastic Stack 8.1相关的知识,希望对你有一定的参考价值。
在 8.1 中,我们引入了 doc-value-only 字段,让你可以灵活地更快地索引和更有效地存储。通过禁用字段上的倒排结构(如倒排索引)和点(BKD 树),你可以将数据索引速度提高 20%,同时将磁盘存储减少约 20%!在 template 级别和 rollover 时进行此更改,在搜索性能方面存在折衷。使用 doc-value-only 字段,你可以根据数据类型和用例在成本和性能之间进行选择。很少查询且查询性能不那么重要的字段将非常适合利用更快的索引和更小的磁盘大小。
你可以使用 field usage 和 disk usage API 来确定适用的字段和潜在的存储节省。这是广泛适用的,并且可能应该用于你主要运行聚合的所有数据,例如指标。如果你的组织在一天内摄取了数 TB 的数据,此选项将对你的整体数据管理产生巨大影响,并且可以大大降低你的总拥有成本。
Elasticsearch:运用 doc-value-only 字段来实现更快的索引速度并节省空间 - Elastic Stack 8.1
Elasticsearch:运用 doc-value-only 字段来实现更快的索引速度并节省空间 - Elastic Stack 8.1_哔哩哔哩_bilibili
doc_values
默认情况下,大多数字段都已编入索引,这使得它们可搜索。 倒排索引允许查询在唯一排序的术语列表中查找搜索术语,并从中立即访问包含该术语的文档列表。
排序、聚合和访问脚本中的字段值需要不同的数据访问模式。 我们需要能够查找文档并找到它在字段中的术语,而不是查找术语和查找文档。
Doc values 是在文档索引时构建的磁盘数据结构,这使得这种数据访问模式成为可能。 它们存储与 _source 相同的值,但以面向列的方式存储,这对于排序和聚合更有效。 几乎所有字段类型都支持 Doc 值,但 text 和 annotated_text 字段除外。
如果你想对 doc_values 有更多的认识,请参阅我之前的文章 “Elasticsearch:inverted index,doc_values 及 source”。
Doc-value-only 字段
数值类型、日期类型、布尔类型、ip 类型、geo_point 类型和关键字类型在没有被索引但只启用 doc 值时也可以查询。 doc 值的查询性能比索引结构的查询性能要慢得多,但在磁盘使用率和查询性能之间提供了一个有趣的折衷,因为这些字段很少被查询并且查询性能不那么重要。 这使得 doc-value-only 字段非常适合通常不用于过滤的字段,例如度量数据上的仪表或计数器。
Doc-value-only 字段可以配置如下:
PUT my-index-000001
"mappings":
"properties":
"status_code":
"type": "long"
,
"session_id":
"type": "long",
"index": false
注意:
- 上面的 status_code 是一个正常的 long 类型的字段
- 而 session_id 里的 index 属性被定义为 false,那么它表示这个是一个 doc-value-only 字段,这是因为 doc values 在默认的情况下是启动的
如何禁止 doc values
所有支持 doc values 的字段都默认启用它们。 如果你确定不需要对字段进行排序或聚合,或从脚本访问字段值,则可以禁用 doc values 以节省磁盘空间:
PUT my-index-000001
"mappings":
"properties":
"status_code":
"type": "keyword"
,
"session_id":
"type": "keyword",
"doc_values": false
注意:
- 上面的 status_code 被定义为 keyword 类型的字段。在默认的情况下它含有 doc values
- 而上面的 session_id 很清楚地表明 doc_values 被禁止,也就是说我们不能对这个字段进行聚合分析,但是由于它没有明确地定义 index 是 false,也就是说它还可以被搜索
示例展示
在一下的展示中,我们将使用两个不同版本的 Elastic Stack 的安装来进行展示,以显示它们的区别。
Elastic Stack 7.17
我们首先安装好 Elastic Stack 7.17 版本的 Elasticsearch 及 Kibana,并在 Kibana 的 Dev Tools 中打入如下的命令:
PUT my-index-000001
"mappings":
"properties":
"status_code":
"type": "long"
,
"session_id":
"type": "long",
"index": false
在上面,我们定义了两个字段:status_code 及 session_id。如上所示,我们的 session_id 的 index 属性被设置为 false。假如我们写入如下的数据:
PUT my-index-000001/_doc/1
"status_code": 404,
"session_id": 10
我们接着做如下的搜索:
GET my-index-000001/_search
"query":
"match":
"session_id": 10
我们可以看到如下的错误信息:
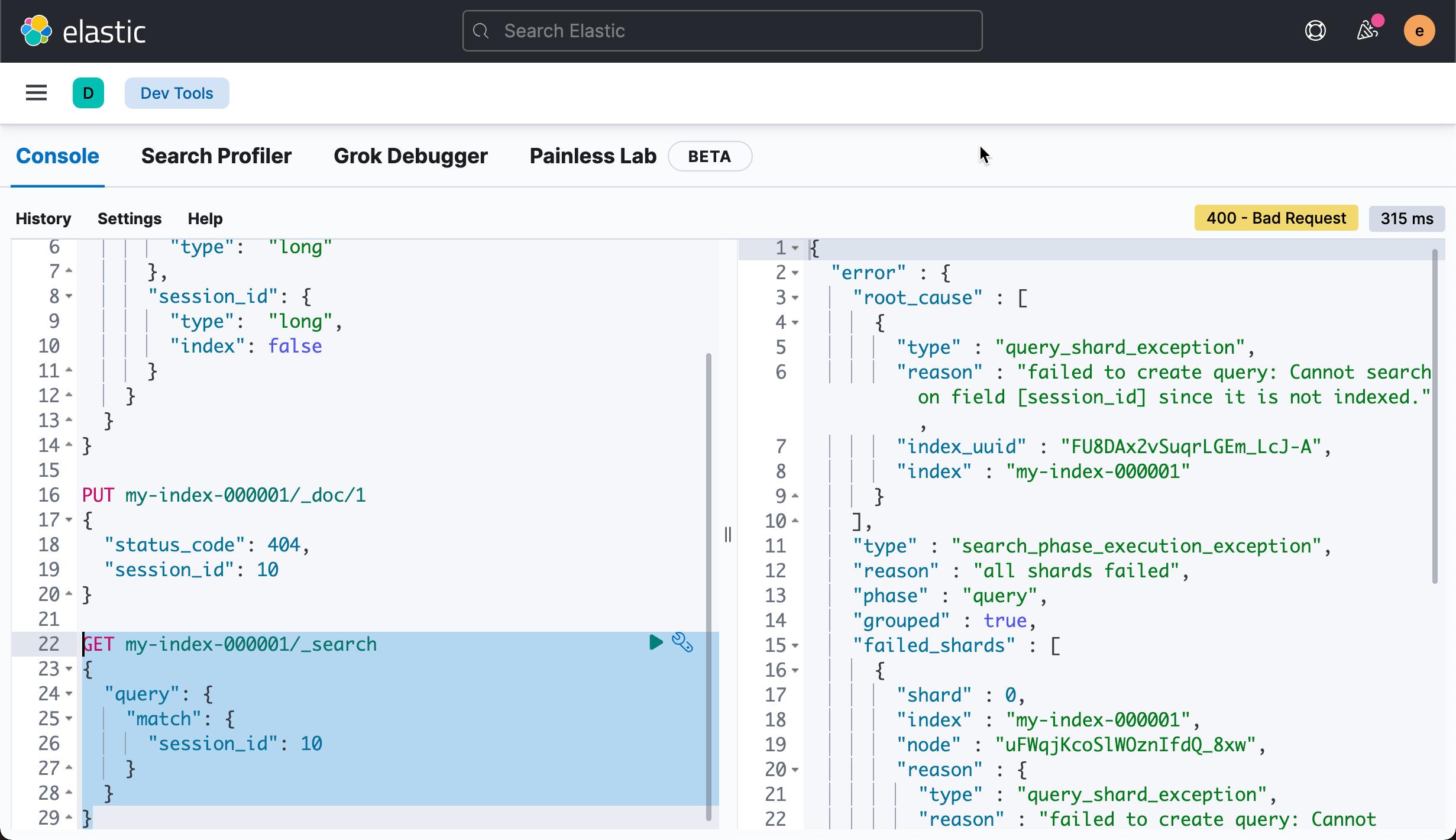
上面的原因显而可见,这是由于 session_id 的属性 index 为 false。它没有被做倒排索引。
Elastic Stack 8.1
我们接下来看看 Elastic Stack 8.1 的情况。我们安装好 Elasticsearch 及 Kibana,并打入和上面一样的命令:
PUT my-index-000001
"mappings":
"properties":
"status_code":
"type": "long"
,
"session_id":
"type": "long",
"index": false
在上面的两个字段定义中,session_id 现在是一个 doc-value-only 字段。尽管 index 为 false,但是我们还是可以对它进行搜索。我们写入如下的文档:
PUT my-index-000001/_doc/1
"status_code": 404,
"session_id": 10
我们按照上面的方法来进行搜索:
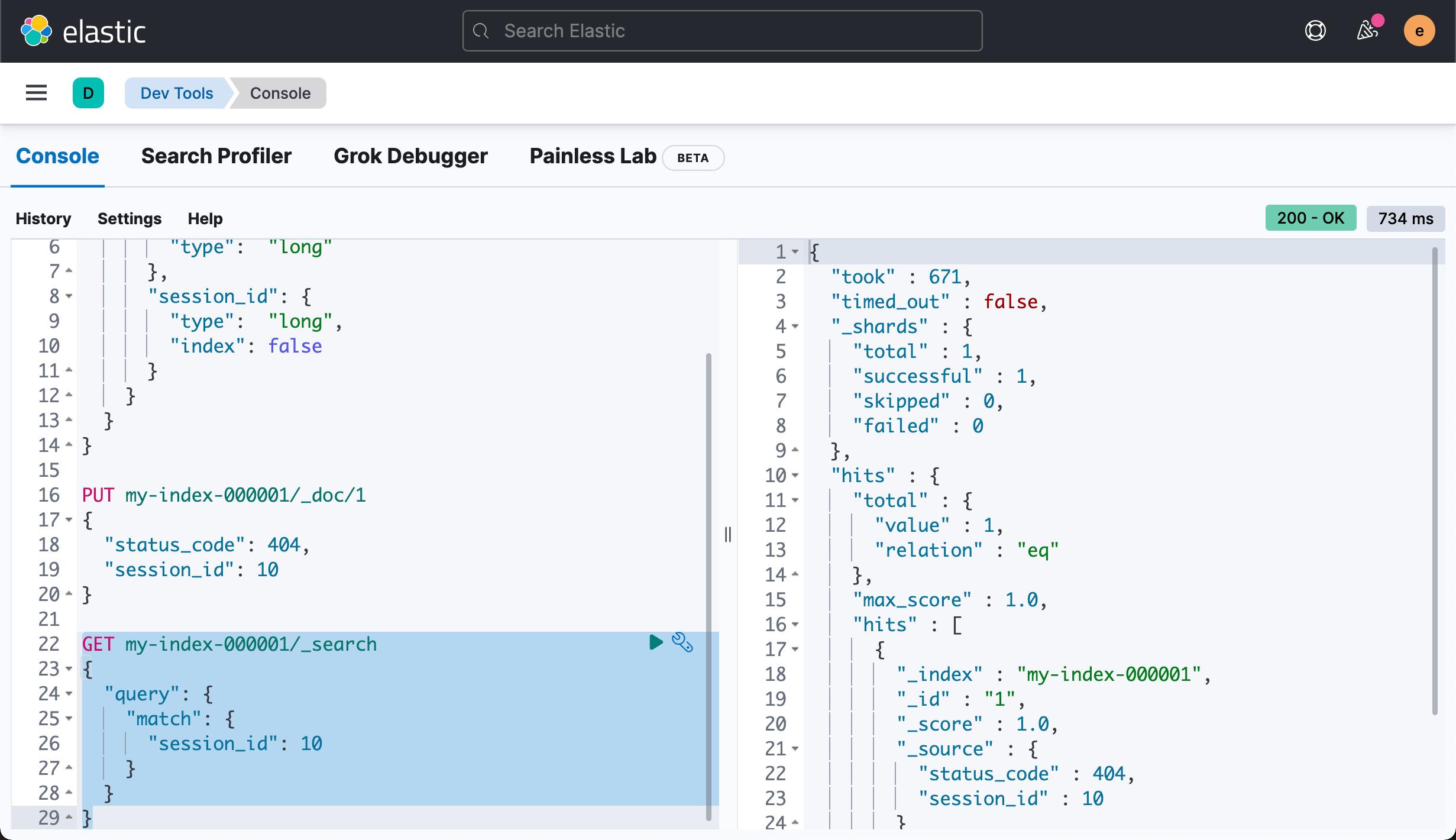
从上面的图中,我们可以看出来,尽管 index 属性被设置为 false,我们也可以对它进行搜索。当然我们也可以对它进行统计:
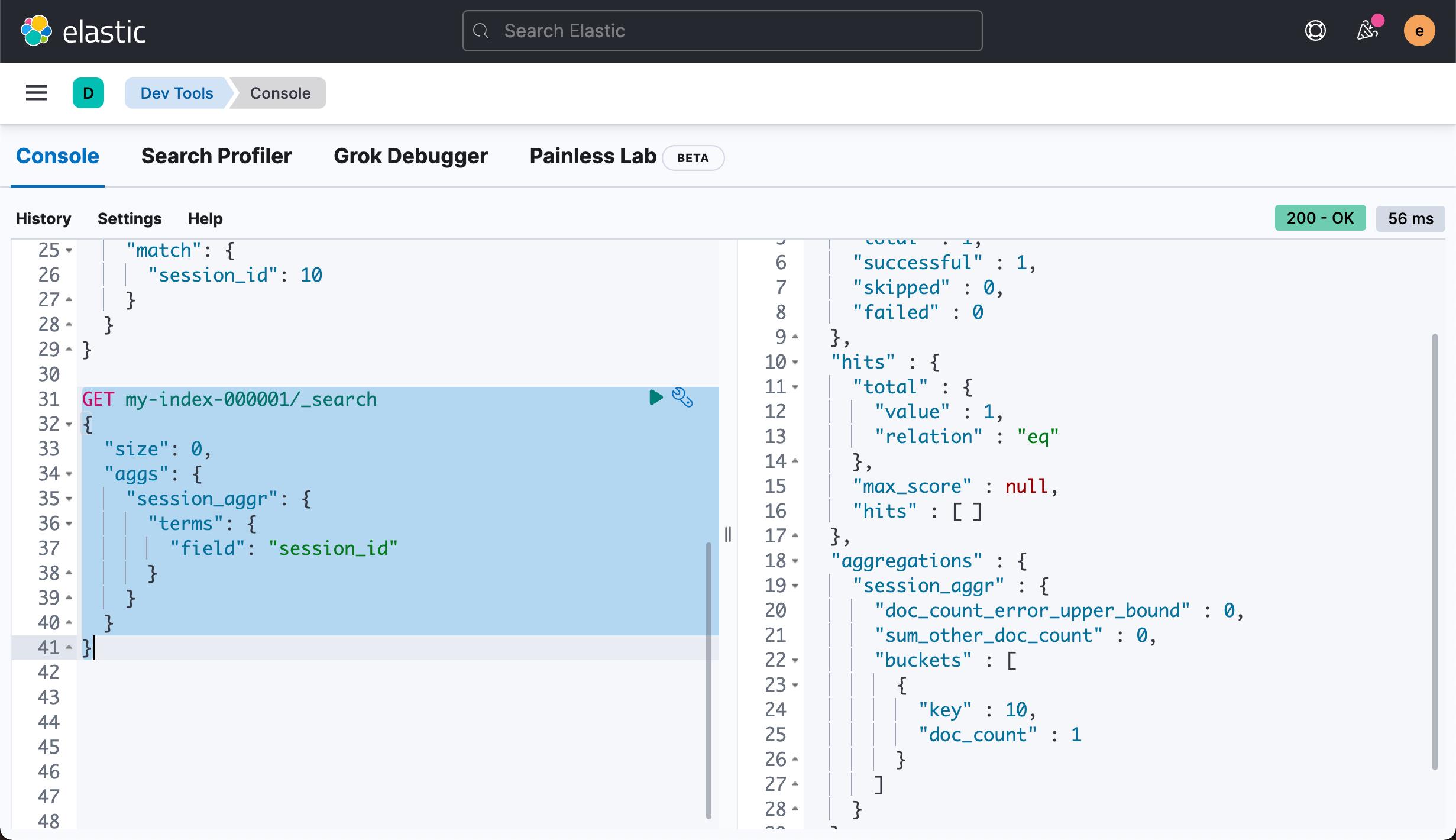
由于我们使用了 index 为 false,它可以极大地提高我们的数据摄入速度并有效地节省磁盘的空间。
以上是关于Elasticsearch:运用 doc-value-only 字段来实现更快的索引速度并节省空间 - Elastic Stack 8.1的主要内容,如果未能解决你的问题,请参考以下文章