ctr预估中,可以有哪些深度模型,深度方法?
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ctr预估中,可以有哪些深度模型,深度方法?相关的知识,希望对你有一定的参考价值。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
随着深度学习模型尺寸逐渐扩大、训练数据量显著上升,目前工业界的大多数场景都需要使用分布式的方式进行模型训练。今天来跟大家聊聊Tensorflow、Pytorch分布式训练的底层实现逻辑。有的算法同学可能会想,我只要深入研究模型就可以了,为什么还要了解这些工程上的东西,有专门的人搭好架子直接用不就行了?正是因为要用这些架子,才更应该了解这些架子的底层逻辑,这样才能在实验中快速排查运行效率低、数据读取错误、效果不符合预期等问题,上述问题和分布式的工程实现逻辑是息息相关的。
本文将对分布式训练原理,以及常见的Parameter Server分布式架构和Ring Allreduce分布式架构进行简单介绍。
1. 分布式训练原理
当我们模型尺寸及训练数据量大幅增加时,如果还有一个GPU跑速度会非常慢,因此分布式训练被越来越多的应用。分布式训练,即在多个机器上一起训练模型,提高训练效率。主要有两种思路,一种思路是模型并行,即将一个模型分拆成多个小模型,分别放在不同的设备上,每个设备跑模型的一部分。由于模型各个部分关系很大,这种方式效率很低,需要不同设备模型之间的频繁通信,一般不会使用这种方法。另一种思路是数据并行,完整的模型在每个机器上都有,但是把数据分成多份给每个模型,每个模型输入不同的数据进行训练。数据并行是目前最常用的分布式实现方法。
下面我们介绍两种分布式框架,分别是Tensorflow中采用的Parameter Server架构和Pytorch中采用的Ring AllReduce架构。
2. Tensorflow——Parameter Server架构
Tensorflow采用的是Parameter Sever架构。Parameter Sever架构主要包括1到多个server节点和多个worker节点。其中server节点保存模型参数,如果有多个server节点会把模型参数保存多份到多个server上。而worker负责使用server上的参数以及本worker上的数据计算梯度。Parameter Sever架构在每个step的训练过程中主要分为3个步骤。首先每个worker从server上拷贝下来完整的模型参数;接下来用每个worker上的数据在这份参数上计算梯度;最后,每个worker将计算得到的梯度传回给server,server端进行参数的更新。
Parameter Sever有两种实现方法,一种是异步更新,一种是同步更新。异步更新中,每个设备上自己进行训练,不用等其他设备,自己训练完一个step得到梯度,传回给server后,server就直接用这个梯度更新模型参数。异步的方式效率很高,运行效率随着设备数量够增加线性提升。但是异步训练的缺点在于,很可能出现无效梯度导致模型效果不好。假设t时刻a和b两个设备都拿到相同的参数,a运行的快,得到梯度更新了共享模型参数,b运行慢,在a更新后又一次更新了共享模型参数,但是b基于的并不是a已经更新过的参数得到的梯度,因此此时b得到的梯度是失效的。在同步更新中,ps需要等到所有worker都回传了梯度后,才进行参数更新,强保障了各个worker计算梯度时参数的一致性,不会出现无效梯度问题。但是同步更新会出现同步阻塞问题,即只要有一个worker没有回传梯度,那么当前step就需要一直等着。
同步方式和异步方式是一种运行效率和模型精度之间的取舍。如果模型对于一致性的敏感度高,那么异步更新会严重影响效果,否则就可以用异步更新提升运行效率。也有一些折中的办法,比如在同步更新中设定最大等待步数,几个step内server上的参数必须更新一次。
Parameter Sever的主要问题在于,随着worker数量(GPU、CPU)的增加,模型的运行效率并不是线性提升的。这是因为在server带宽一定的前提下,worker数量的增加,增加了worker与server的通信时长。因此worker数量增加的越多,带来的效率提升边际收益递减。解决这个问题的方法之一为,增加server的数量,提升server带宽,进而减少worker与server通信时常。
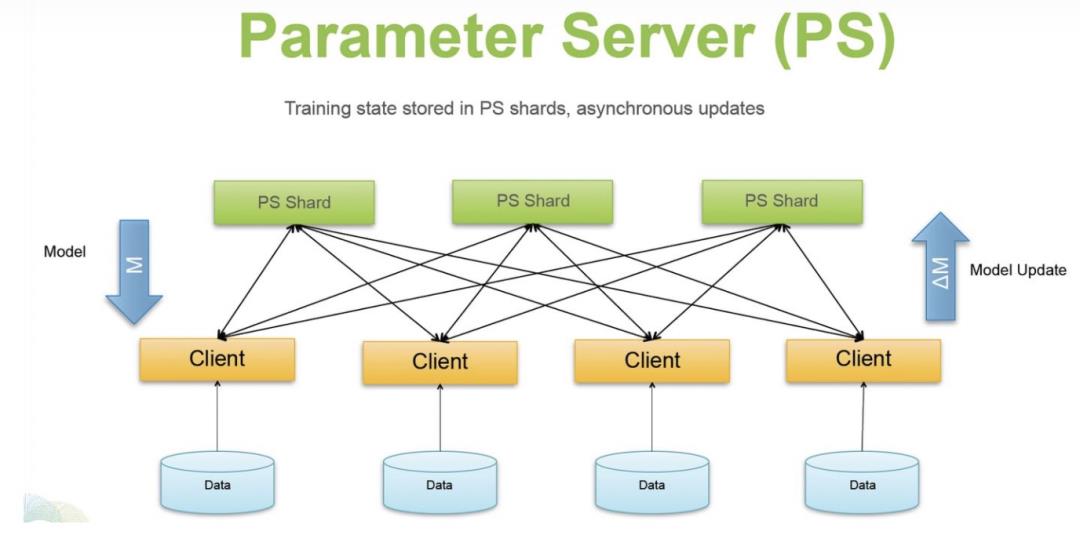
3. Pytorch——Ring AllReduce架构
Pytorch采用了另一种Ring AllReduce架构,这种架构的特点是运行效率随着worker数量的增加是线性增加的。Ring AllReduce架构不像Parameter Server架构有一个中央的server连接各个worker,所有worker都和server交互,而是采用了一种环形的结构。Ring AllReduce架构中没有server,都是worker,所有worker组成一个环形,每个worker和另外两个worker相连。每个worker都只和相邻的两个worker进行信息传递。每个worker上都有一份完整的模型参数,并进行梯度计算和更新。
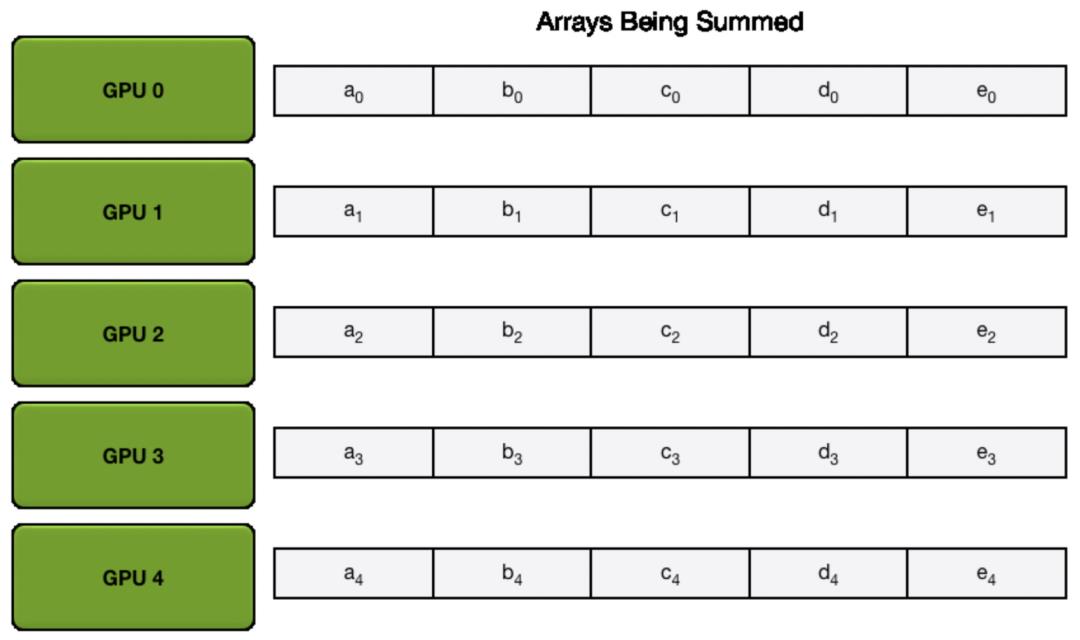
在实现同步更新的时候,Ring AllReduce架构主要分为scatter reduce和allgather两个步骤。假设一共使用了5个worker,那么在scatter reduce步骤中,将每个设备上计算出来的梯度分割成5等份,即网络参数的梯度分成5份,每个worker都使用相同的分割方法。然后通过worker之间的5次通信,让每个worker上都有一部分参数的梯度是完整的,如下图的过程。这个过程是为了让每个worker上都有一部分网络参数,能够融合所有其他worker上的梯度,得到一份完整的梯度。
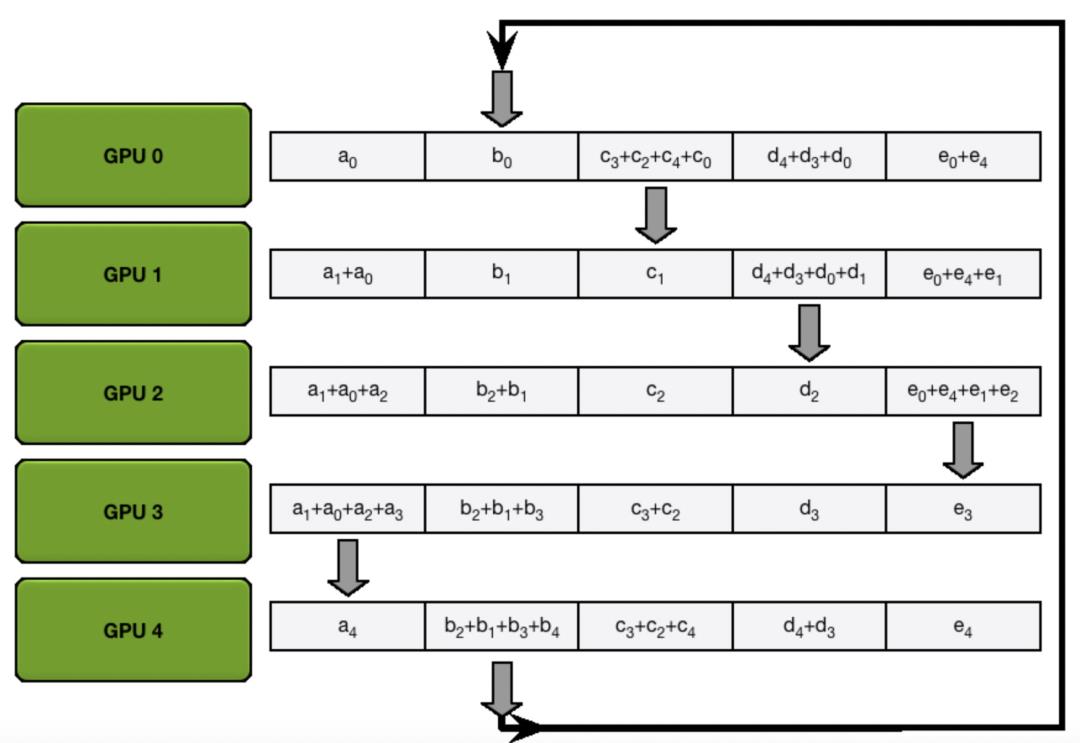
编辑切换为居中
添加图片注释,不超过 140 字(可选)
接下来,在allgather过程中,需要让所有worker上的所有网络参数的梯度都是上一步中某个worker上完整的梯度。这里需要再次进行4次信息传递,把每个worker上各自梯度完整的部分传播到其他worker上,如下图所示。
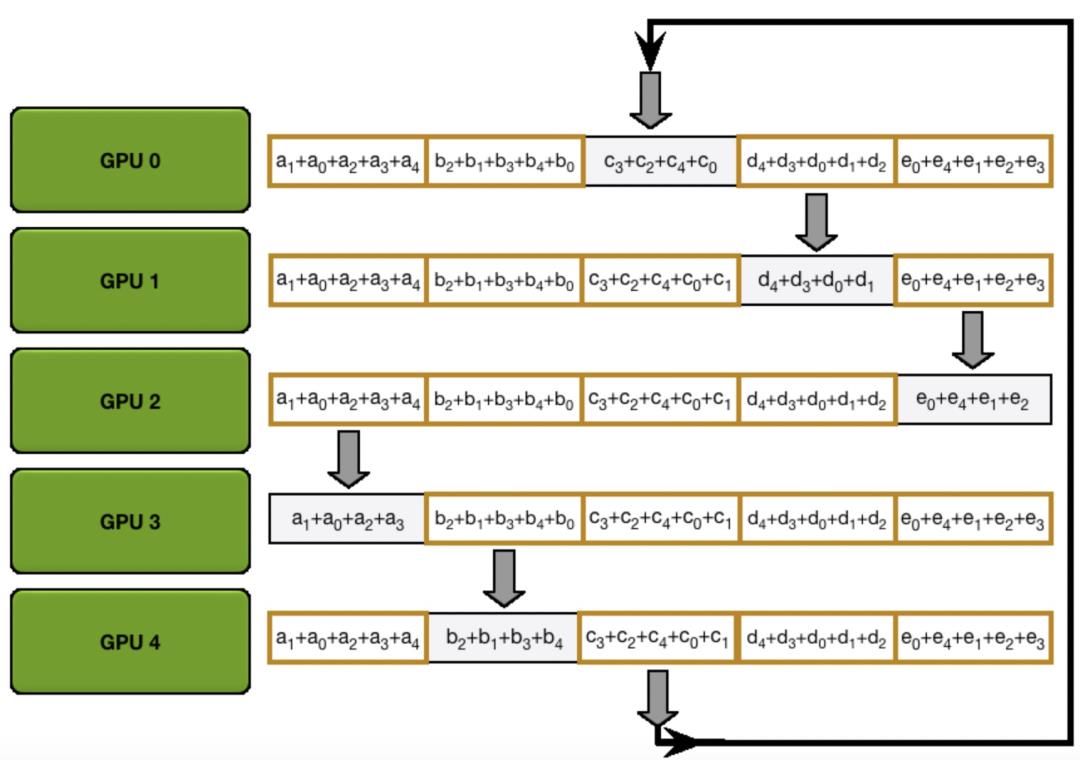
经过scatter reduce和all gather两个过程之后,所有worker上的所有参数对应的梯度都是融合了所有worker计算的梯度的结果。下面我们来看看为什么这种方式的运行效率会随着worker数量的增加线性提升。
通过上面的过程我们发现,一次Ring AllReduce过程总共需要进行2 * (worker_num -1)次信息交互,并且每个worker进行信息交互的次数是相同的,因此平均到每个worker的通信量为2*(worker_num - 1) / worker_num。通过上面公式可以看出,Ring AllReduce的通信时间并不会随着worker数量的增加而增加,因此其运行效率会随着worker数量增加线性增加。
4. 总结
本文我们简单介绍了典型的分布式训练框架的实现逻辑,包括Parameter Server架构和Ring AllReduce架构。掌握基本的分布式框架实现逻辑,可以帮助我们进行更好的技术选型,以及当运行效率低时排查可能出现问题的点,是使用深度学习进行模型训练的基本功。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,查看更多干货算法笔记~
以上是关于ctr预估中,可以有哪些深度模型,深度方法?的主要内容,如果未能解决你的问题,请参考以下文章