终于有人把辛普森悖论讲明白了
Posted 大数据v
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了终于有人把辛普森悖论讲明白了相关的知识,希望对你有一定的参考价值。
导读:困扰统计学家60多年的魔咒,时至今日也没有得到彻底解决。
作者:徐晟
来源:大数据DT(ID:hzdashuju)

在做重大决策时,我们总会参考一些统计数据,比如高考前关注学校的录取率,择业时参考各个行业的就业率等。统计数字可以帮助我们比较这些对象的优劣,做出更加合理的决定。但有时,统计数字并不靠谱,基于统计数据的因果推断甚至会出错。
举例来说,假设张三想去医院看病。他收集到了附近两家医院的医疗数据,如表2-1所示。
根据数据,医院A最近治疗了1000个病人,有900人存活,100人死亡,存活率为90%。医院B最近也治疗了1000个病人,有800人存活,200人死亡,存活率为80%。从统计数据来看,似乎医院A比医院B更好一点。
现在我们把收集到的样本数据做一些细分,按照重症病人和非重症病人进行统计,如表2-2所示。
▼表2-2 重症和非重症病人统计
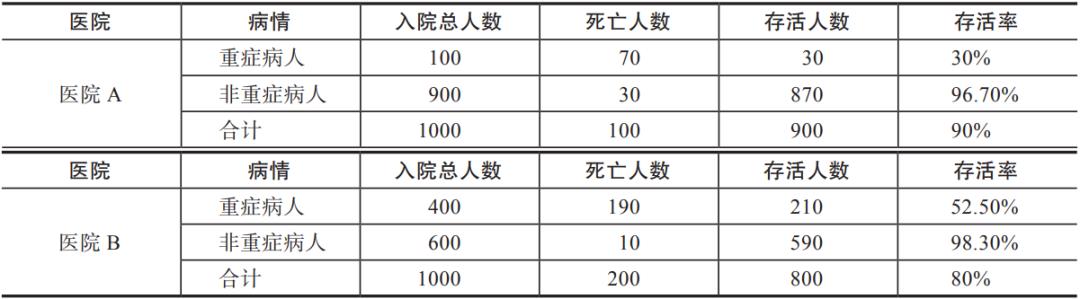
我们只是进一步区分了病人病情的严重程度,结论就被变魔术般改变了。从表2-2中可以看出,无论是重症病人还是非重症病人,不管怎么看,最好的选择都是医院B,这与之前的情况大相径庭。一开始我们只关注整体的存活率,医院A明明是更好的选择,但是如果关心更细的病例存活率,医院B就变成了更好的选择。为何会出现这种情况?
这是因为数据中存在潜在变量(比如病情严重程度不同的病人占比),按照潜在变量分组后的数据是不均匀的。在上面的例子中,医院A和医院B对于不同分组病人的救治成功率差别很大。对于重症病人,存活率只有30%~50%,而对于非重症的病人,存活率超过了95%。
同时,两种病人去医院A和医院B就医的数据分布正好相反,大多数重症病人都去了医院B,大部分的非重症病人去了医院A就诊。这就导致医院B的总体救治率数据反而被拉低了,而医院A的统计数据反而更占优势。
在分组比较中占据优势的一方,在综合评估中却成为失势的一方,该现象被称为辛普森悖论。辛普森悖论最初是英国数学家辛普森(Edward Huge Simpson)于1951年发现并提出的。此悖论如同魔咒般,已困扰统计学家60多年,时至今日也没有得到彻底解决。它的出现揭示出一个令人震惊的事实——同一组数据的整体趋势和分组趋势有可能完全不同。
若使用数学语言,辛普森悖论可以表示为如下的关系式:
当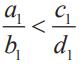 ,
,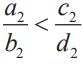 时,我们不能得出
时,我们不能得出 的结论。反过来也一样,有兴趣的读者可以自行证明。
的结论。反过来也一样,有兴趣的读者可以自行证明。
不少统计学家认为,由于辛普森悖论的存在,因此仅仅通过有限个统计数字,无法直接推导和还原事实真相。这是统计数据的致命缺陷。因为数据可以按照各种形式分类和比较,潜在变量无穷无尽,理论上总是可以用某个潜在变量得到某种结论。
对于那些不怀好意的人,他们很容易对数据进行拆分或归总,得到一个对自己有利的统计数据,从而误导甚至操纵别人。所以,为了避免辛普森悖论,我们应该仔细分析各种影响因素,不要笼统概括,更不能浅尝辄止地看问题。
关于作者:徐晟,某商业银行IT技术主管,毕业于上海交通大学,从事IT技术领域工作十余年,对科技发展、人工智能有自己独到的见解,专注于智能运维(AIOps)、数据可视化、容量管理等方面工作。
本文摘编自《大话机器智能:一书看透AI的底层运行逻辑》,经出版方授权发布。(ISBN:9787111696193)

《大话机器智能:一书看透AI的底层运行逻辑》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:AI是什么?机器如何拥有“智能”?“智能”如何起作用?本书以通俗易懂的方式,勾勒人工智能的全貌,展现AI的底层运行逻辑,即AI是如何工作的。

划重点👇
干货直达👇
更多精彩👇
在公众号对话框输入以下关键词
查看更多优质内容!
读书 | 书单 | 干货 | 讲明白 | 神操作 | 手把手
大数据 | 云计算 | 数据库 | Python | 爬虫 | 可视化
AI | 人工智能 | 机器学习 | 深度学习 | NLP
5G | 中台 | 用户画像 | 数学 | 算法 | 数字孪生
据统计,99%的大咖都关注了这个公众号
👇
以上是关于终于有人把辛普森悖论讲明白了的主要内容,如果未能解决你的问题,请参考以下文章