对Nuscenes数据集一无所知,手把手带你玩转Nusences数据集
Posted 秃头小苏
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对Nuscenes数据集一无所知,手把手带你玩转Nusences数据集相关的知识,希望对你有一定的参考价值。
文章目录
嗯,实话实说,标题可能写的有点夸张🎃🎃🎃怎么说是夸张呢,因为玩转Nuscenes数据集也是我的目标🎯🎯🎯本文将从一个初学者的角度来认识Nuscenes数据集,首先会对Nuscenes数据集的结构进行分析,然后会通过代码教大家如何获取Nuscenes数据集中的各种数据 【由于自己也是刚刚接触,可能有的地方描述的不够完整不够准确,但是我会对我学习中的一些比较迷惑的地方重点讲解,可能会和开始学习Nuscenes的读者产生共鸣,当然随着我的后续学习,我也会不断的更新内容,让我们一起真正的玩转Nusences数据集🚀🚀🚀】
Nuscenes数据集简介
先来简单的介绍一下Nuscenes数据集,相信大家对Nuscenes数据集应该是有一些了解的,至少应该知道这是和自动驾驶相关的,知道这些就足够了,下面再来补充一些知识📩📩📩Nuscenes数据的采集来自不同城市的1000个场景中,采集车上配备了完善的传感器,包括6个相机(CAM)、1个激光雷达(LIDAR)、5个毫米波雷达(RADAR)、IMU和GPS。传感器在采集车上的布置如下图所示:
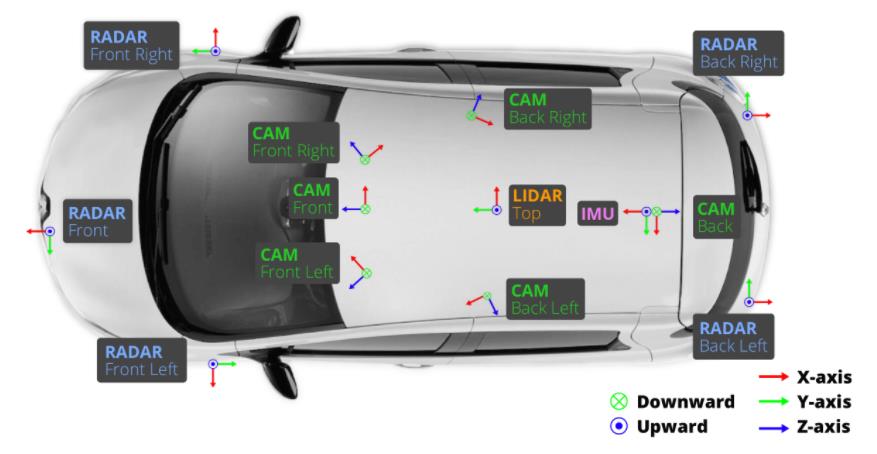
可以看出,相机(CAM)有六个,分别分布在前方(Front)、右前方(Front Right)、左前方(Front Left)、后方(Back)、右后方(Back Right)、左后方(Back Left);激光雷达(LIDAR)有1个,放置在车顶(TOP);毫米波雷达有五个,分别放置在前方(Front)、右前方(Front Right)、左前方(Front Left)、右后方(Back Right)、左后方(Back Left)。
准备工作✨✨✨
数据才是王道,第一步我们当然是需要下载数据了。Nuscenes的官网下载链接如下:https://www.nuscenes.org/download。第一次下载应该是需要进行登录的,登录完成就可以进行下载啦!!!登录完成你可能会发现有太多可下载的资源了,我该下载哪一个呢,这里我们用做实验,故不需要下载完整的数据集,下载mini版本即可【完整的太大了,mini大约4个G】。
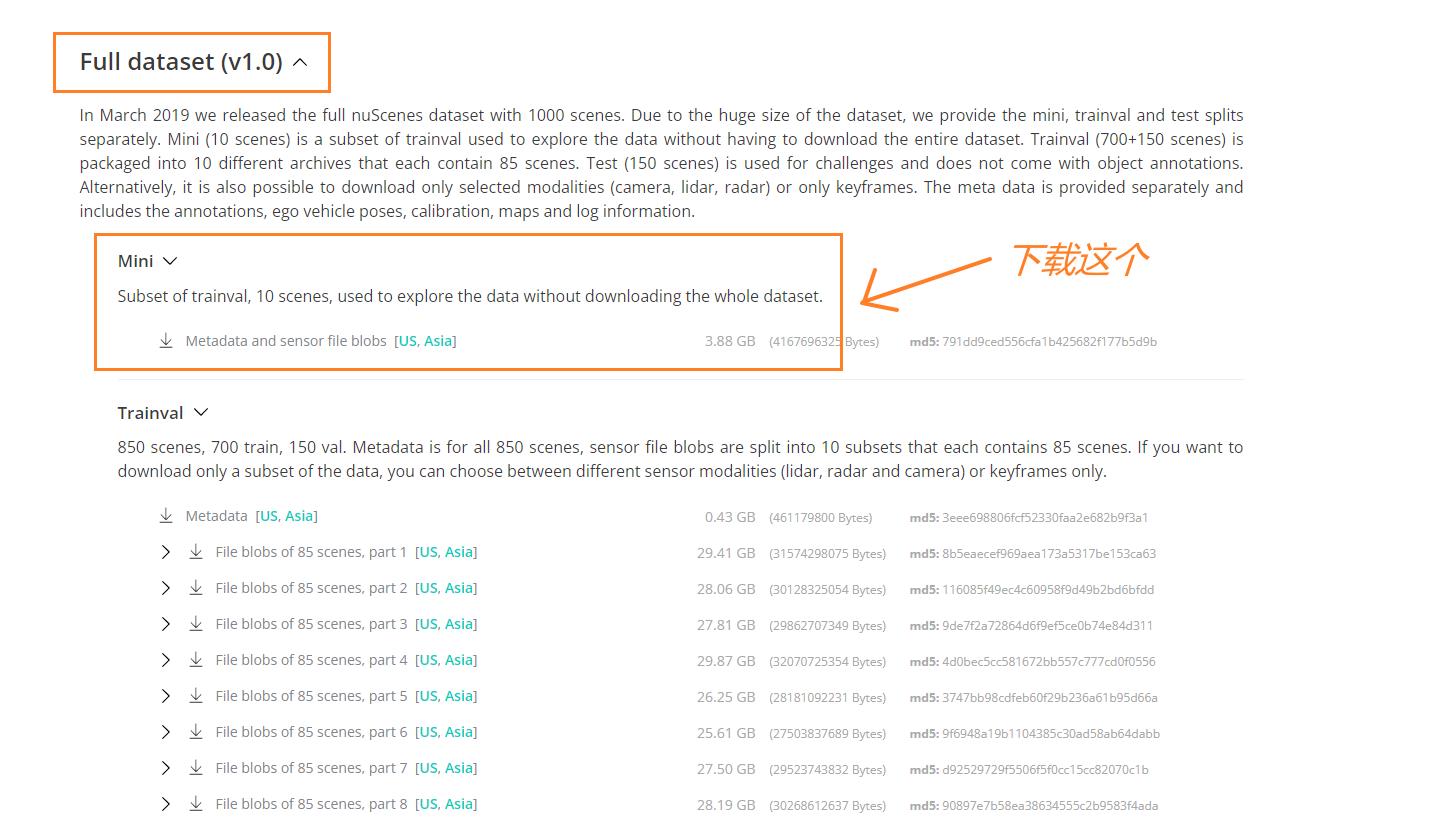
下载完成进行解压后,应该有如下的文件结构:
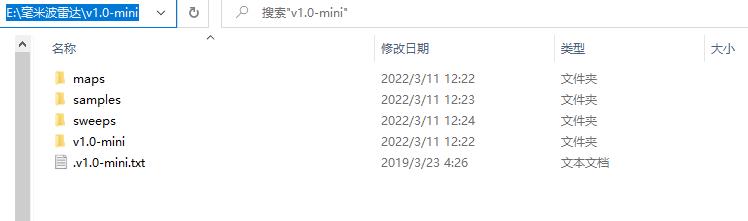
接下来我们对上图中的4个文件进行分析:
- maps文件夹
打开map文件夹,可以看到4个地图的图片,这种图片信息的文件我们很容易理解,这里不过多叙述。
- samples文件夹
打开samples文件夹,出现了这样的目录结构:不知道大家能不能看出来这些是什么,对于英语不好的我来说,打开文件夹出现一堆这种大写的英文着实反应不过来😭😭😭。好吧,不卖关子了🤐🤐🤐其实这里就是上文提到的传感器(6个相机、1个激光雷达、5个毫米波雷达)所采集到的信息。不信你可以打开6个相机所对应的文件夹,你可以发现里面都是采集到的图片,至于激光雷达和毫米波雷达所对应的文件夹里也存储着各自采集的信息,只是格式不能像图片那样直接进行查看。
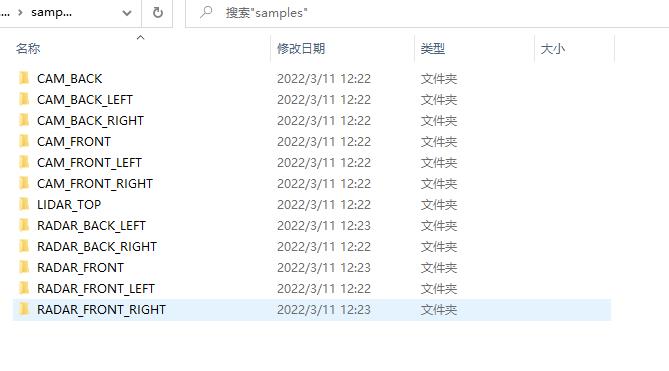
- sweeps文件夹
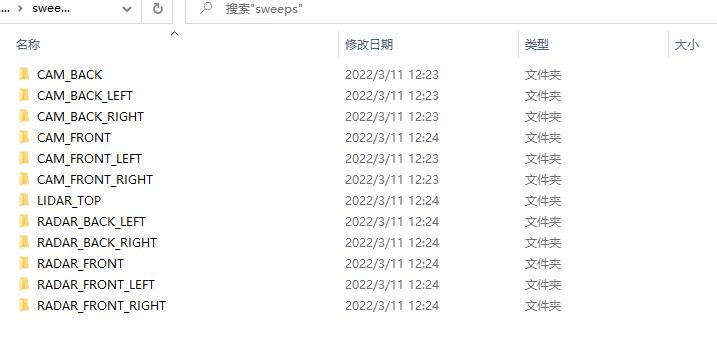
打开sweeps文件夹,你会发现其结构和samples文件夹是完全一样的。那么samples文件夹和sweeps文件夹有什么区别呢?可以这样理解,samples文件夹中存储的信息是较为关键、重要的,而sweeps文件夹中的信息则相对次要。
- v1.0-mini文件夹
打开v1.0-mini文件夹,或许你又懵了,里面是一堆json格式的文件。
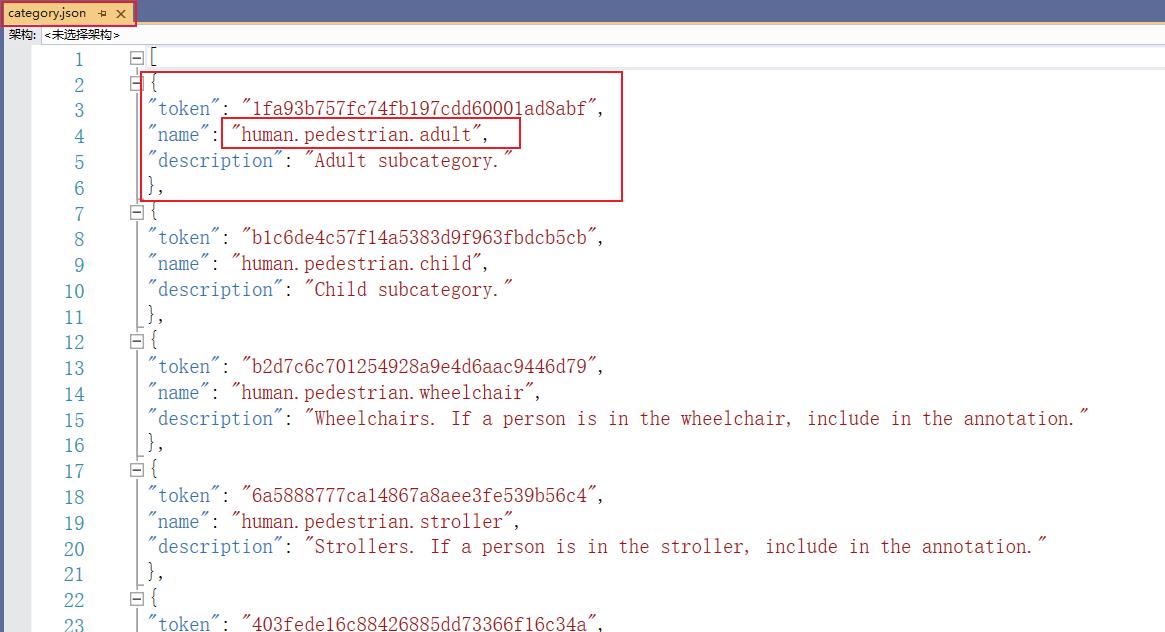
这些json文件是干什么的呢,我们尝试打开一个看看里面的内容(这里打开的是category.json)。首先提示一下category是种类的意思,那么这个josn文件中就存储了一些关于目标对象属于哪一类的信息,如下图红框框住部分,表示目标对象是一个adult。【图中的种类显示的是human.pedestrian.adult,表示一种所属关系,即adult属于pedestrian,pedestrian属于human】
数据读取✨✨✨
安装库
首先需要按照nuscenes-devkit库,使用pip安装即可。【注意:后文的代码我都是在jupyter notebook上运行的,若用其他软件运行,代码可能需要略微进行改变】
pip install nuscenes-devkit
导入相关模块和数据集
这里的dataroot为下载的mini数据集的路径,运行成功后应出现如下的信息:
%matplotlib inline
from nuscenes.nuscenes import NuScenes
nusc = NuScenes(version='v1.0-mini', dataroot='E:\\\\毫米波雷达\\\\v1.0-mini', verbose=True)

看到上图红框中的内容不知大家是否有种似曾相似的感觉,没错👉🏼👉🏼👉🏼就是之前v1.0-mini文件夹中的那些文件。下面对这些名词进行解释,英文为官方给出的解释,中文为自己总结的。


看来上图中各名词的解释,估计还是比较迷惑的,下面会对这些内容进行逐一的解释🎨🎨🎨
场景scene⭐⭐⭐
使用nusc.list_scenes()可以查看数据中的所有场景。
nusc.list_scenes()
输出结果 : mini数据集中只包含10个场景,每个场景大约持续20s【有的19s】,即每个场景有20秒采集到的信息。
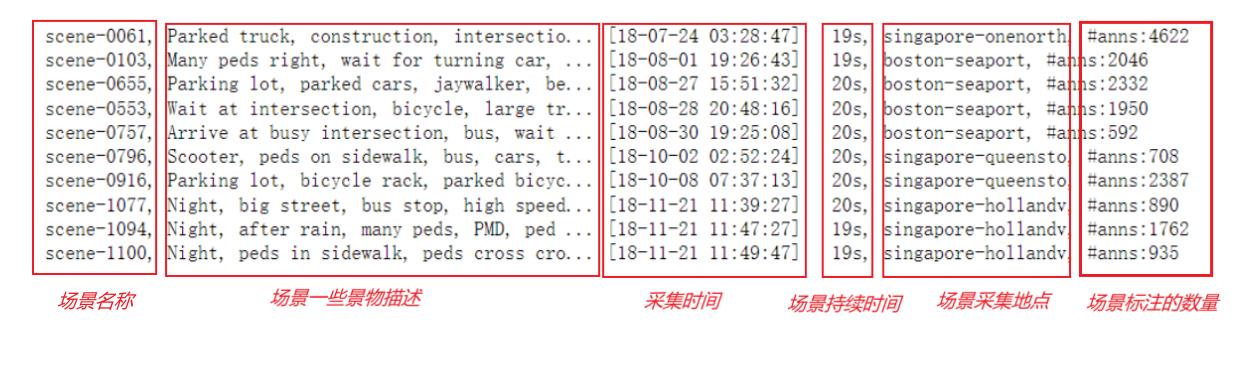
可以使用下列命令来查看某个场景中的信息:
my_scene = nusc.scene[0]
my_scene
输出结果 :token为唯一标识,通过token可以获取对应信息。

样本sample⭐⭐⭐
先来说说sample和scene的关系,前面说到,每个scene大约持续20s,那sample就是每0.5秒进行一次采样。也可以这样理解sample和scene,sence相当于20s的视频,sample就是每0.5s取一帧的图像。
上文已经得到了某个场景的信息【scene-0061】,现可以通过my_scene得到某一个sample的token值。
first_sample_token = my_scene['first_sample_token'] #获取第一个sample的token值
first_sample_token
输出结果 :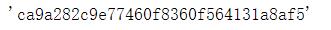
当我们得到第一个sample的token值后,我们可以通过 nusc.get命令来获取当前sample的信息:
my_sample = nusc.get('sample', first_sample_token)
my_sample
输出结果 :结果中包含了传感器采集到的信息、标注信息等等。

样本数据 sample_data⭐⭐⭐
使用my_sample['data']可以获取sample的数据sample_data。
my_sample['data']
输出结果 :这些传感器里包含了许多的样本数据。

我们可以使用下列命令来将这些传感器中采集的进行可视化:
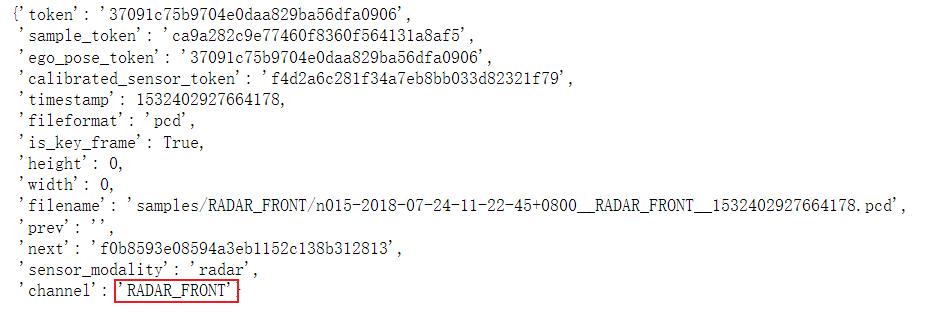
sensor_radar = 'RADAR_FRONT' #这里选择的传感器为前方的毫米波雷达传感器
radar_front_data = nusc.get('sample_data',my_sample['data'][sensor_radar])
radar_front_data
输出结果 :
nusc.render_sample_data(radar_front_data['token'])
输出结果 :
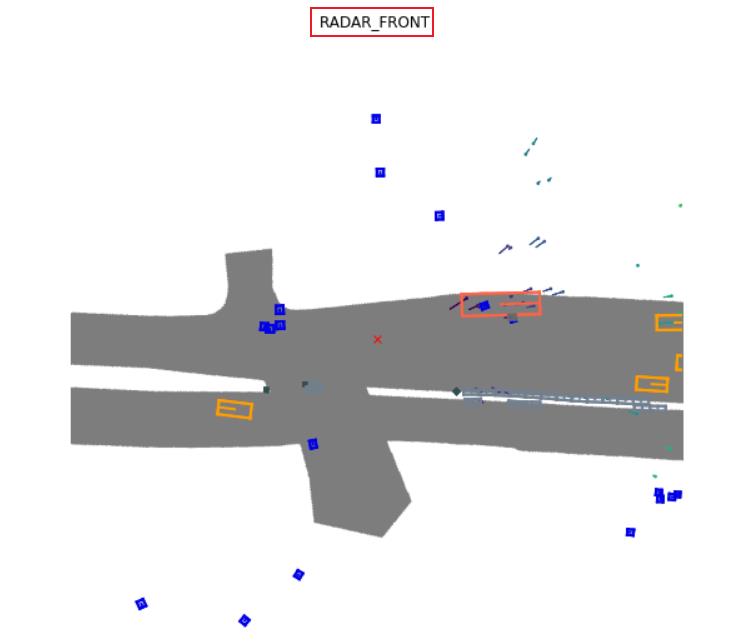
这里只展示了RADAR_FRONT,即前方毫米波雷达传感器的可视化结果,可视化其他传感器的方法和上文一致。
样本标注 sample_annotation⭐⭐⭐
上文提到my_sample中包含了传感器采集到的信息、标注信息,在sample_data中已经展示了传感器采集到的信息,这一部分将展示样本标注的信息,方法与之前是类似的。
my_annotation_token = my_sample['anns'][18]
my_annotation_metadata = nusc.get('sample_annotation',my_annotation_token)
my_annotation_metadata
输出结果 :

nusc.render_annotation(my_annotation_metadata['token'])

实例 instance
通过nusc.instance可以获取实例:
my_instance = nusc.instance[0]
my_instance
输出结果 :
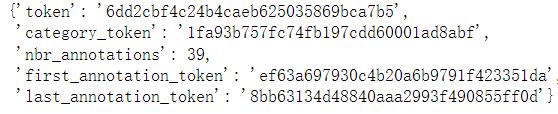
我们也可以可视化这个实例:
instance_token = my_instance['token']
nusc.render_instance(instance_token)
输出结果 :

类别categories
通过nusc.list_categories可以获取类别:
nusc.list_categories()
输出结果 :

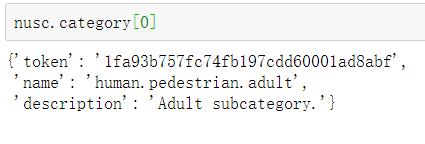
nusc.category[i]表示获取第i个类别的信息:
属性attributes⭐⭐⭐
通过nusc.list_attributes可以获取属性:
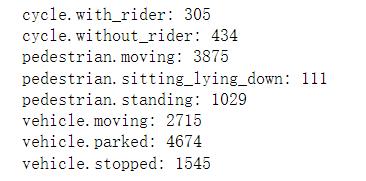
nusc.list_attributes()
输出结果 :
属性在一个场景中是可以变换的,下列代码展示了行人从移动到站立,属性发生了变换。【注意:这部分代码直接看可能不是很好理解,将代码一部分一部分的运行,看看每步的结果,你就会恍然大悟🥏🥏🥏】
my_instance = nusc.instance[27]
first_token = my_instance['first_annotation_token']
last_token = my_instance['last_annotation_token']
nbr_samples = my_instance['nbr_annotations']
current_token = first_token
i = 0
found_change = False
while current_token != last_token:
current_ann = nusc.get('sample_annotation', current_token)
current_attr = nusc.get('attribute', current_ann['attribute_tokens'][0])['name']
if i == 0:
pass
elif current_attr != last_attr:
print("Changed from `` to `` at timestamp out of annotated timestamps".format(last_attr, current_attr, i, nbr_samples))
found_change = True
next_token = current_ann['next']
current_token = next_token
last_attr = current_attr
i += 1
输出结果 :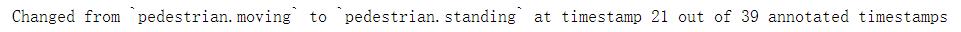
可视化 visibility
可视化在前文中其实已经讲过了,这里再看看代码加深印象。
anntoken = my_sample['anns'][9]
visibility_token = nusc.get('sample_annotation', anntoken)['visibility_token']
print("Visibility: ".format(nusc.get('visibility', visibility_token)))
nusc.render_annotation(anntoken)
输出结果 :

传感器 sensor
传感器前文其实也或多或少的讲过了,可以通过nusc.sensor来查看传感器,部分结果如下:

因sample_data中就存储着传感器的信息,因此可以通过nusc.sample_data[i]来获取传感器的信息,结果如下:
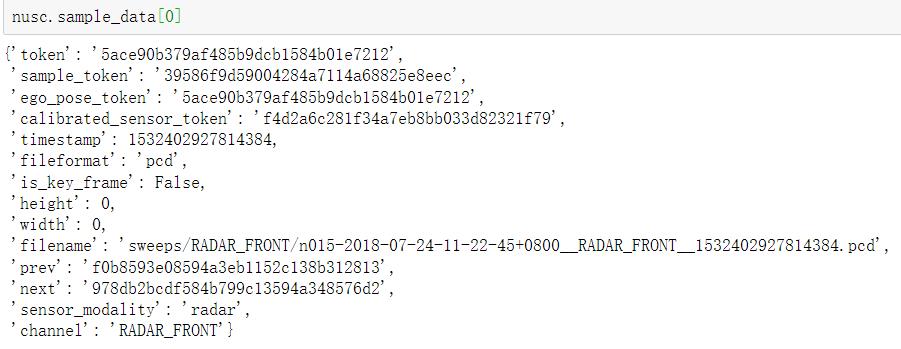
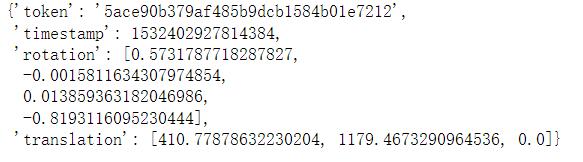
校准传感器 calibrated_sensor
通过下列命令来得到某传感器的校准信息:
sensor_token = nusc.calibrated_sensor[0]
sensor_token
输出结果 :

车辆姿态 ego_pose
nusc.ego_pose[0]
输出结果 :
日志 log
nusc.log[0]
输出结果 :

地图 map
nusc.map[0]
输出结果 :

总结
最后了,说点什么呢,上面这些东西你看是很难看明白的,自己动手多敲一敲,哪里不明白敲敲代码看看输出的结果,好记性不如烂笔头,加油各位📝📝📝
这部分官方是给了参考的代码的,可以再Google colab上直接运行,这里给出官方的链接:Nuscenes使用教程,但是我想大家还是自己敲一敲会印象更加深刻🀄🀄🀄
如若文章对你有所帮助,那就🛴🛴🛴
咻咻咻咻~~duang~~点个赞呗
以上是关于对Nuscenes数据集一无所知,手把手带你玩转Nusences数据集的主要内容,如果未能解决你的问题,请参考以下文章