[机器学习与scikit-learn-3]:scikit-learn模型地图与模型选择
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-3]:scikit-learn模型地图与模型选择相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:
目录
if 样本数大于<50个, 则直接放弃(欠拟合),scikit-learn模型,至少需要有50个样本数据
if 样本数大于>=50个, 则scikit-learn能处理。
概述
scikit-learn提供了大量的已知模型,下图形展现了如何选择scikit-learn的模型,来解决特定的现实问题。

start->
if 样本数大于<50个, 则直接放弃(欠拟合),scikit-learn模型,至少需要有50个样本数据
if 样本数大于>=50个, 则scikit-learn能处理。
if 分类问题, 则为分类问题
if 标签数据,则为有监督的分类问题

if 样本数小于100K, 则优选选择线性SVC
if 是文本数据, 则选择Naive Bayes算法
else 选择K近邻居算法
else 样本大于100K, 则优选选择SGD分类算法
if 不能工作,则选择 选择复合增强算法,如Kernel approximation+SVC算法
else 无标签数据,则为无监督的分类问题:聚类问题

if 样本数目是已知的
if 样本数<10K, 则使用miniBatch KMeans算法
else 则使用 KMeans算法
if 不能工作,则选择特殊的聚类算法GMM
else 样本数未知
if 样本数<10, 则使用MeanShift算法
else 难度太大,不支持
else 则为非分类问题
if 数量性问题,则为拟合问题

if 样本数<100K, 则直接可以使用SGD拟合
else 样本>=100K, 则需要进一步确定
if 部分个别的特征起关键作用,则使用 弹性网络,Lasso
else 则选择 RidgeRegression
如果不能工作,则选择复合、增强算法
elsif 如果观察数据总体特性,则是降维问题
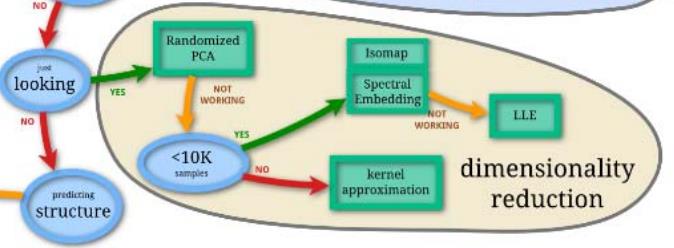
则直接使用Randomized PCA算法
如果不能工作,则进一步确定
if 样本数少于10K,
则使用Isomap算法
else 则使用 kernel approximation算法
else:目前还不支持

备注:从这样图上可以看出,scikit-learn也就20种左右常用的算法。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:
以上是关于[机器学习与scikit-learn-3]:scikit-learn模型地图与模型选择的主要内容,如果未能解决你的问题,请参考以下文章