Python爬虫 Selenium -- Selenium简介安装SeleniumSelenium基本使用
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫 Selenium -- Selenium简介安装SeleniumSelenium基本使用相关的知识,希望对你有一定的参考价值。
1. Selenium简介
1.1 什么是selenium?
- Selenium是一个用于Web应用程序测试的工具。
- Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。(这样就可以保证获取到的数据是完整的)
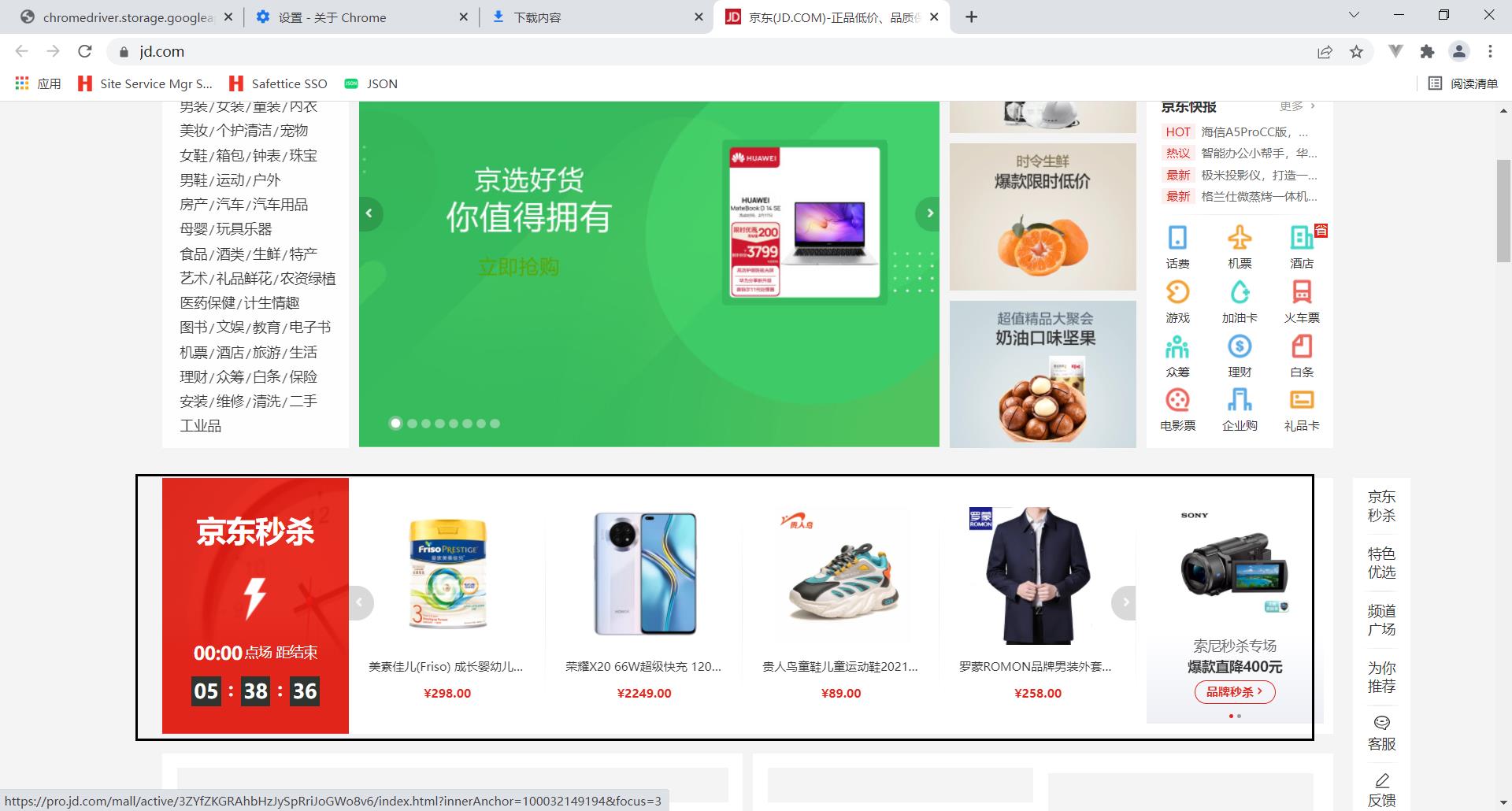
例如:京东秒杀的数据直接爬取是爬取不到的
import urllib.request
url = 'https://www.jd.com/'
headers =
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/92.0.4515.159 Safari/537.36'
# 因为urlopen方法中不能存储字典 所以headers不能传递进去
# 请求对象的定制
request = urllib.request.Request(url=url, headers=headers)
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)
运行结果:
- 支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动 真实浏览器完成测试。
- selenium也是支持无界面浏览器操作的。
1.2 为什么使用selenium?
模拟浏览器功能,自动执行网页中的js代码,实现动态加载
2. 安装selenium
查看谷歌浏览器版本 谷歌浏览器右上角,帮助,关于:
可以看到我的谷歌游览器版本是:98.0.4758.102(正式版本) (64 位)


下载完后解压,拖到项目目录下(也可以不拖动)
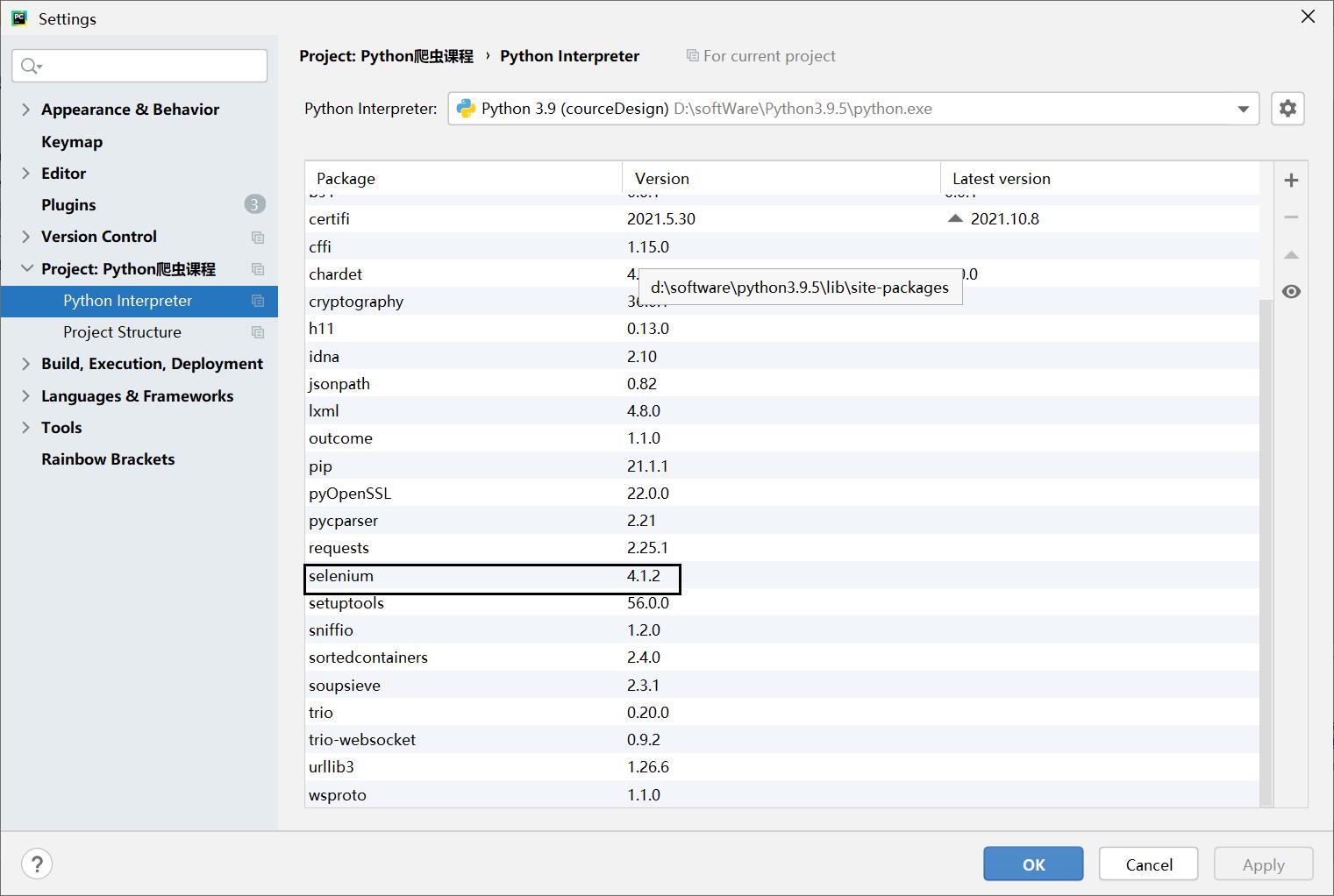
接下来我们给py环境中安装selenium

3. Selenium基本使用
selenium的使用步骤?
(1)导入:from selenium import webdriver
(2)创建谷歌浏览器操作对象:
path = 谷歌浏览器驱动文件路径
browser = webdriver.Chrome(path)
(3)访问网址 url = 要访问的网址 browser.get(url)
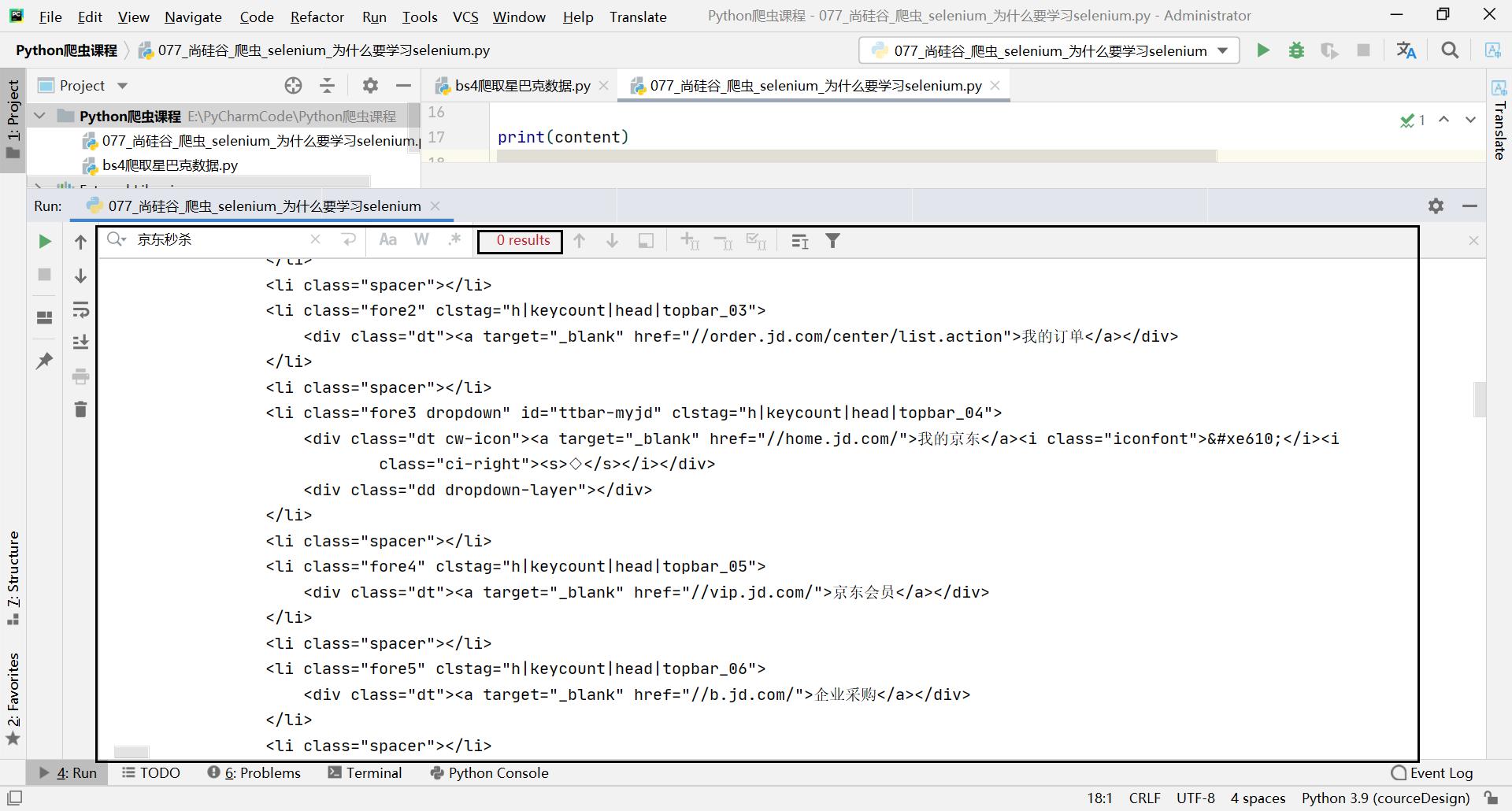
我们还是去访问京东的首页:
# (1)导入selenium
from selenium import webdriver
# (2) 创建浏览器操作对象
path = './exe/chromedriver.exe'
browser = webdriver.Chrome(path)
# (3)访问网站
url = 'https://www.jd.com/'
browser.get(url)
# page_source获取网页源码
content = browser.page_source
print(content)
运行结果:

以上是关于Python爬虫 Selenium -- Selenium简介安装SeleniumSelenium基本使用的主要内容,如果未能解决你的问题,请参考以下文章