Python爬虫 Selenium -- Selenium元素定位Selenium访问元素信息Selenium交互
Posted CodeJiao
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫 Selenium -- Selenium元素定位Selenium访问元素信息Selenium交互相关的知识,希望对你有一定的参考价值。
游览之前先看 Selenium简介、安装Selenium、Selenium基本使用,有助于理解后面的知识点。
1. Selenium元素定位
元素定位:自动化要做的就是模拟鼠标和键盘来操作来操作这些元素,点击、输入等等。操作这些元素前首先 要找到它们,WebDriver提供很多定位元素的方法。
我们下面演示的案例都是基于百度的首页:
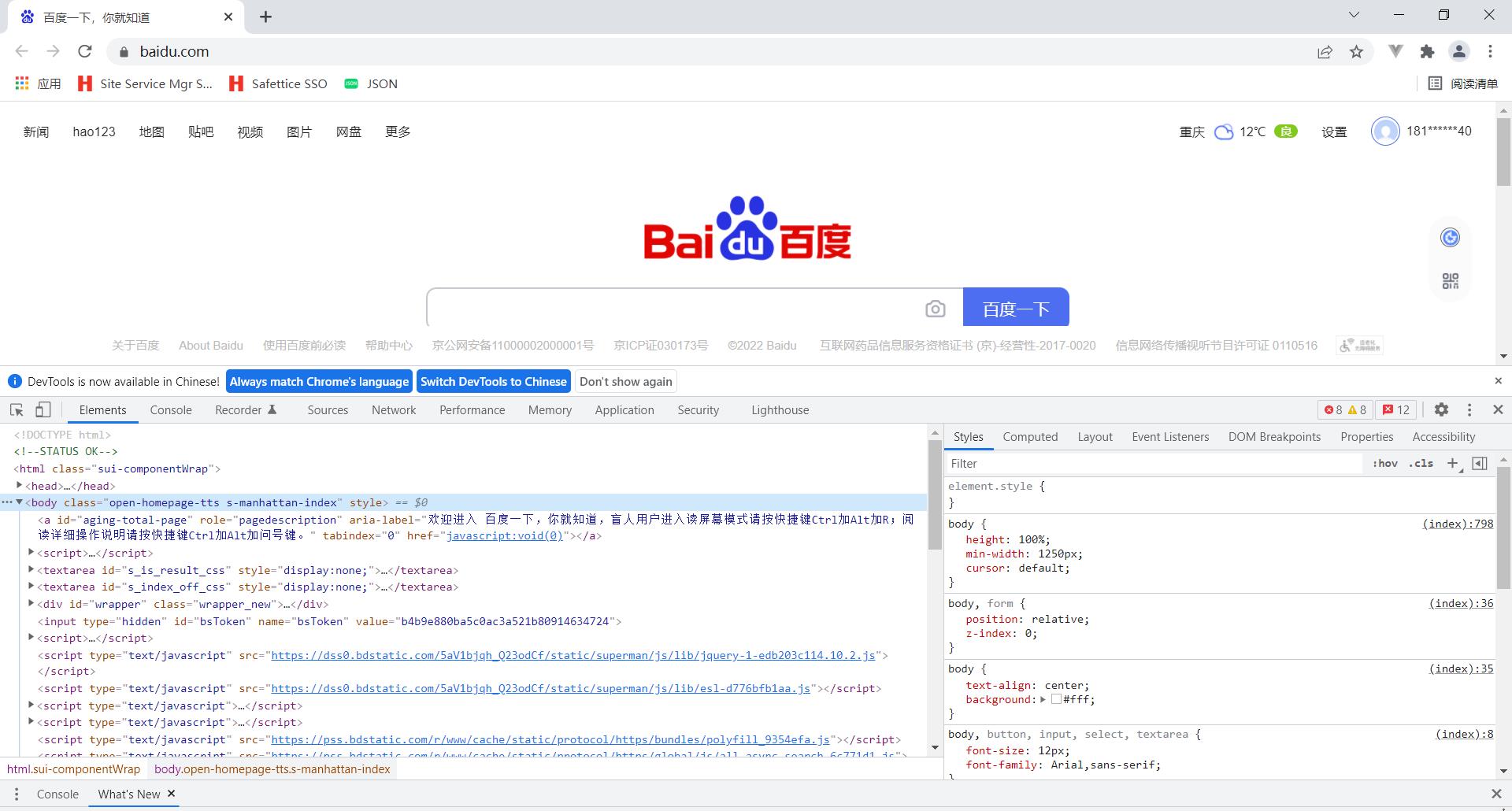
1.1 find_element_by_id
#根据id查找元素
eg:button = browser.find_element_by_id('su')
示例代码:
可以看见百度一下的id为 su

from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据id来找到对象
button = browser.find_element_by_id('su')
print(button)
运行结果:

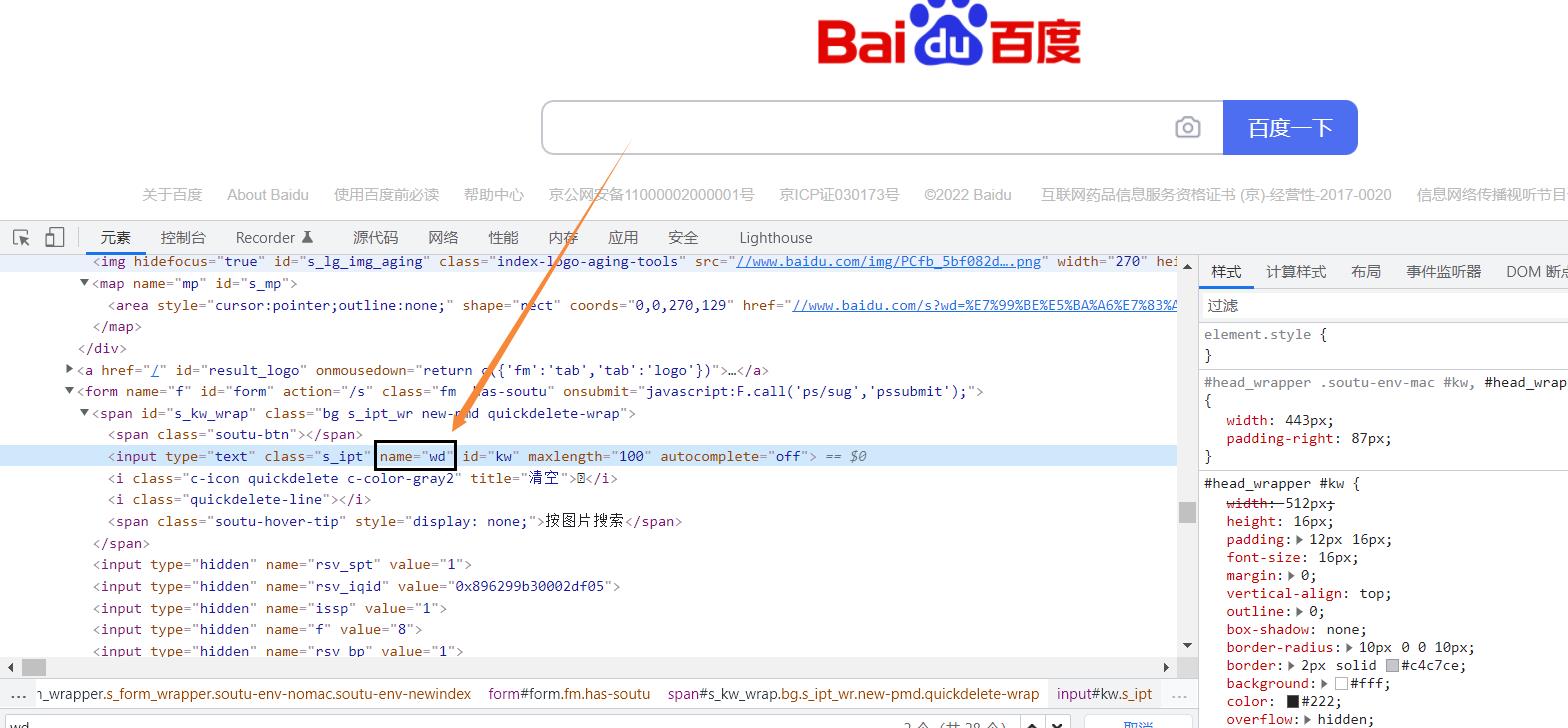
1.2 find_elements_by_name
# 根据标签属性的属性值来获取对象
eg:name = browser.find_element_by_name('wd')
示例代码:
可以看见输入框的name 为 wd
from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据标签属性的属性值来获取对象
button = browser.find_element_by_name('wd')
print(button)
运行结果:

1.3 find_elements_by_xpath
# 根据xpath语句来获取对象
eg:xpath1 = browser.find_elements_by_xpath('//input[@id="su"]')
示例代码:
from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据xpath语句来获取对象
button = browser.find_elements_by_xpath('//input[@id="su"]')
print(button)
运行结果:

1.4 find_elements_by_tag_name
# 根据标签的名字来获取对象
eg:names = browser.find_elements_by_tag_name('input')
示例代码:
from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据标签的名字来获取对象
button = browser.find_elements_by_tag_name('input')
print(button)
运行结果:

1.5 find_elements_by_css_selector
# 使用的bs4的语法来获取对象
eg:my_input = browser.find_elements_by_css_selector('#kw')[0]
示例代码:
from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 使用的bs4的语法来获取对象
button = browser.find_elements_by_css_selector('#su')
print(button)
运行结果:

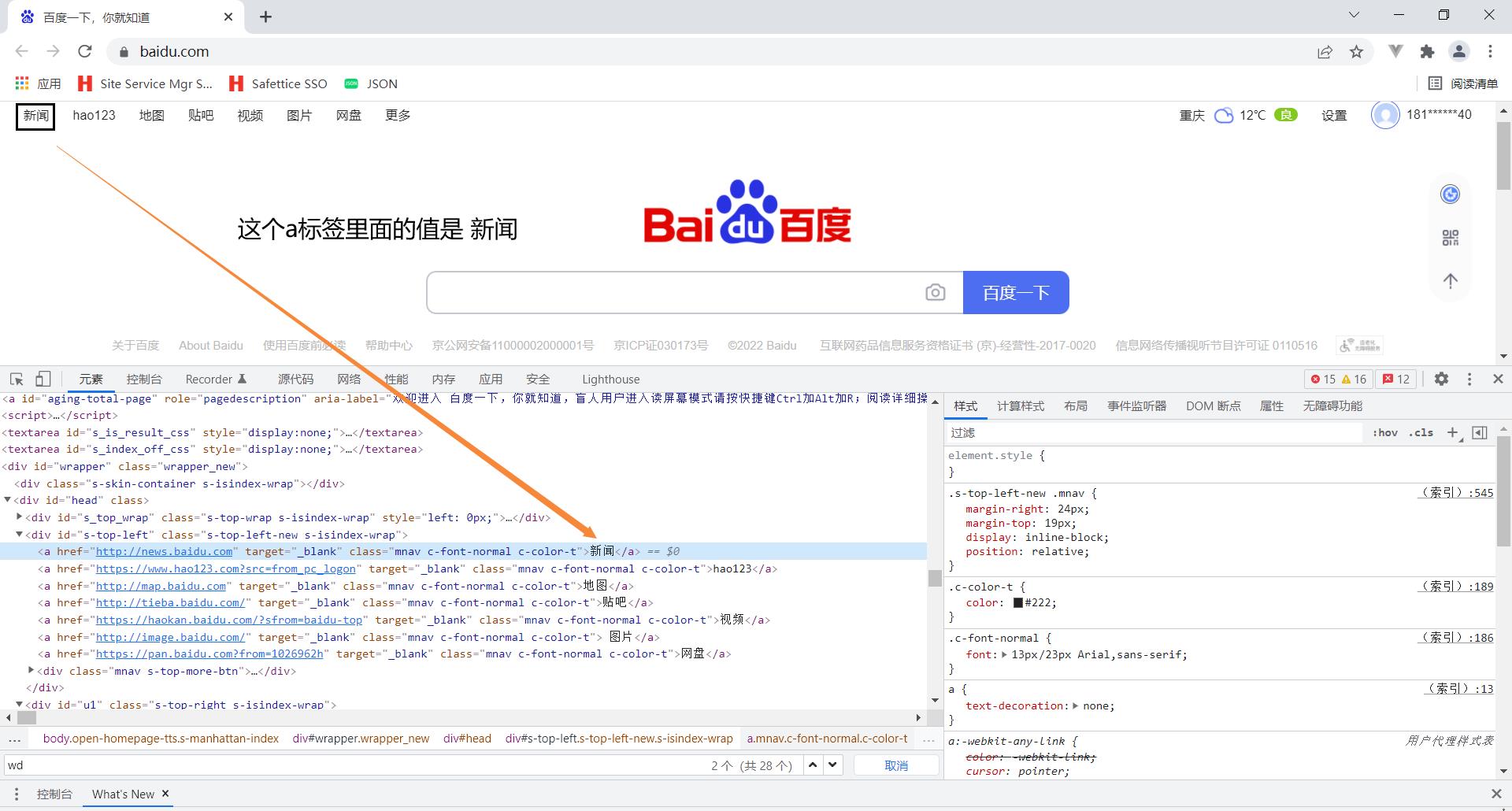
1.6 find_elements_by_link_text
# 根据链接标签里面的值找到链接标签
eg:browser.find_element_by_link_text("新闻")
示例代码:
from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
# 元素定位
# 根据链接标签里面的值找到链接标签
button = browser.find_element_by_link_text('新闻')
print(button)
运行结果:

2. Selenium访问元素信息
获取元素属性
.get_attribute('class')
获取元素文本
.text
获取标签名
.tag_name
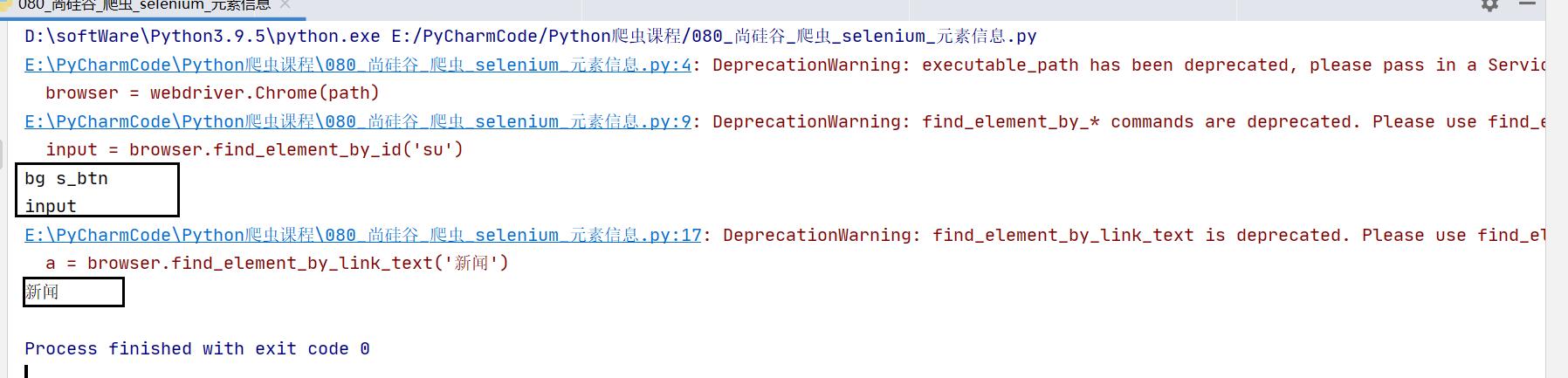
示例代码:
from selenium import webdriver
path = 'exe/chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
input = browser.find_element_by_id('su')
# 获取标签的属性
print(input.get_attribute('class'))
# 获取标签的名字
print(input.tag_name)
# 获取元素文本 获取的是标签中间的文本 里面 <a>新闻</a> 里面的 “新闻”
a = browser.find_element_by_link_text('新闻')
print(a.text)
运行结果:
3. Selenium交互
点击:click()
输入:send_keys()
后退操作:browser.back()
前进操作:browser.forword()
模拟JS滚动: js='document.documentElement.scrollTop=100000'
执行js代码: browser.execute_script(js)
获取网页代码:page_source
退出:browser.quit()
扩展:保存屏幕快照:browser.save_screenshot('baidu.png')
from selenium import webdriver
# 创建浏览器对象
path = './exe/chromedriver.exe'
browser = webdriver.Chrome(path)
# url
url = 'https://www.baidu.com'
browser.get(url)
import time
time.sleep(2)
# 获取文本框的对象
input = browser.find_element_by_id('kw')
# 在文本框中输入周杰伦
input.send_keys('周杰伦')
time.sleep(2)
# 获取百度一下的按钮
button = browser.find_element_by_id('su')
# 点击按钮
button.click()
time.sleep(2)
# 滑到底部
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(2)
# 获取下一页的按钮
next = browser.find_element_by_xpath('//a[@class="n"]')
# 点击下一页
next.click()
time.sleep(2)
# 回到上一页
browser.back()
time.sleep(2)
# 回去
browser.forward()
time.sleep(3)
# 退出
browser.quit()
运行结果:

以上是关于Python爬虫 Selenium -- Selenium元素定位Selenium访问元素信息Selenium交互的主要内容,如果未能解决你的问题,请参考以下文章