7篇顶会论文带你梳理多任务学习建模方法
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了7篇顶会论文带你梳理多任务学习建模方法相关的知识,希望对你有一定的参考价值。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“ 圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
公众号后台回复“ 多任务”,即可获取相关论文资料集合~
1. 多任务学习介绍
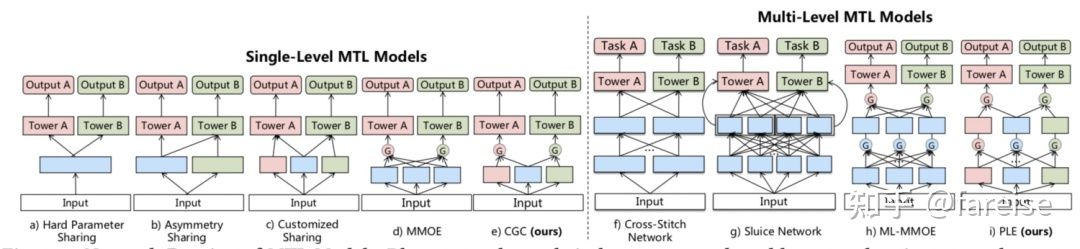
多任务学习(Multitask Learning)是迁移学习的一种方式,通过共享表示信息,同时学习多个相关任务,使这些任务取得比单独训练一个任务更好的效果,模型具有更好的泛化性。在深度学习模型中,多任务学习的最直接实现方法是多个Task共享底层的多层网络参数,同时在模型输出层针对不同任务配置基层Task-specific的参数。这样,底层网络可以在学习多个Task的过程中从不同角度提取样本信息。然而,这种Hard Parameter Sharing的方法,往往会出现跷跷板现象。不同任务之间虽然存在一定的关联,但是也可能存在冲突。联合训练导致不相关甚至冲突的任务之间出现负迁移的现象,影响最终效果。为了解决Hard Parameter Sharing的弊端,学术界涌现了如多专家网络(Multi-expert Network,MoE)等多种解决深度学习中多任务学习问题的方法,是学术界一直以来研究的热点,在工业界也有诸多应用。本文从最基础的多任务学习开始,梳理了近几年来7篇多任务学习顶会相关工作,包括Hard/Soft Parameter Sharing、参数共享+门控、学习参数共享方式等建模方式。
2. Hard/Soft Parameter Sharing
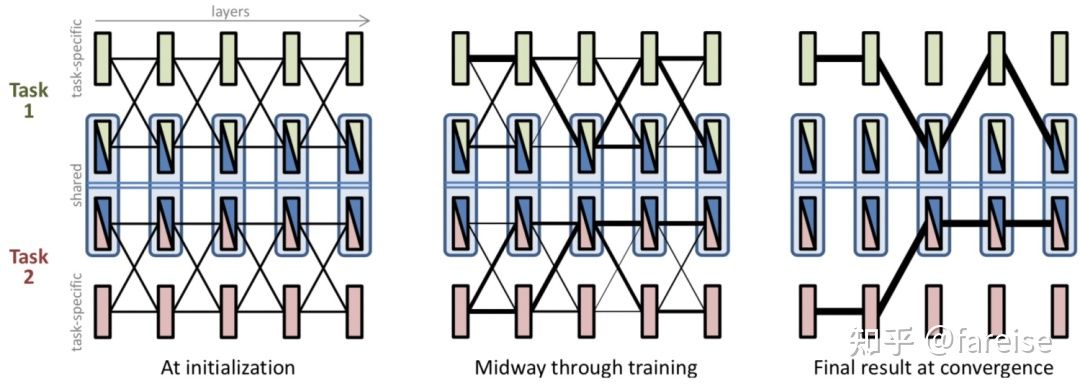
Hard Parameter Sharing通过共享参数的方法对多个任务联合建模,但是从哪一层开始共享、哪一层非共享没有有效的指导信息。Cross-stitch Networks for Multi-task Learning(CVPR 2016)提出Cross-stitch网络实现每层自动学习。Cross-stitch网络对于每个任务有一套单独的参数,在每层都会将两个任务的当前层的表示进行较差,学习两个任务融合后的表示,可以表示为矩阵乘法的形式:
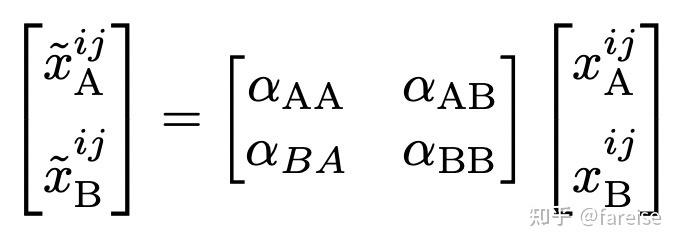
假如某一层不需要进行参数共享,而是Task-specific的,那么参数aAA和aBA就会被学习成接近0的数。Cross-stitch部分的整体结构如下图:
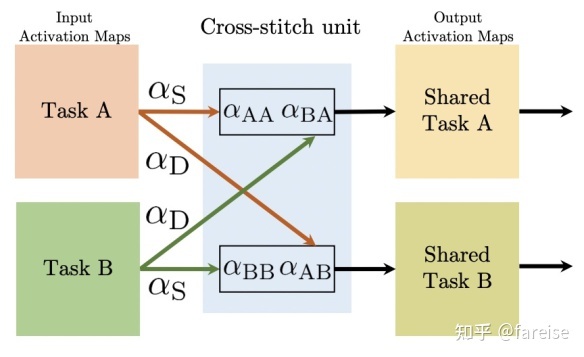
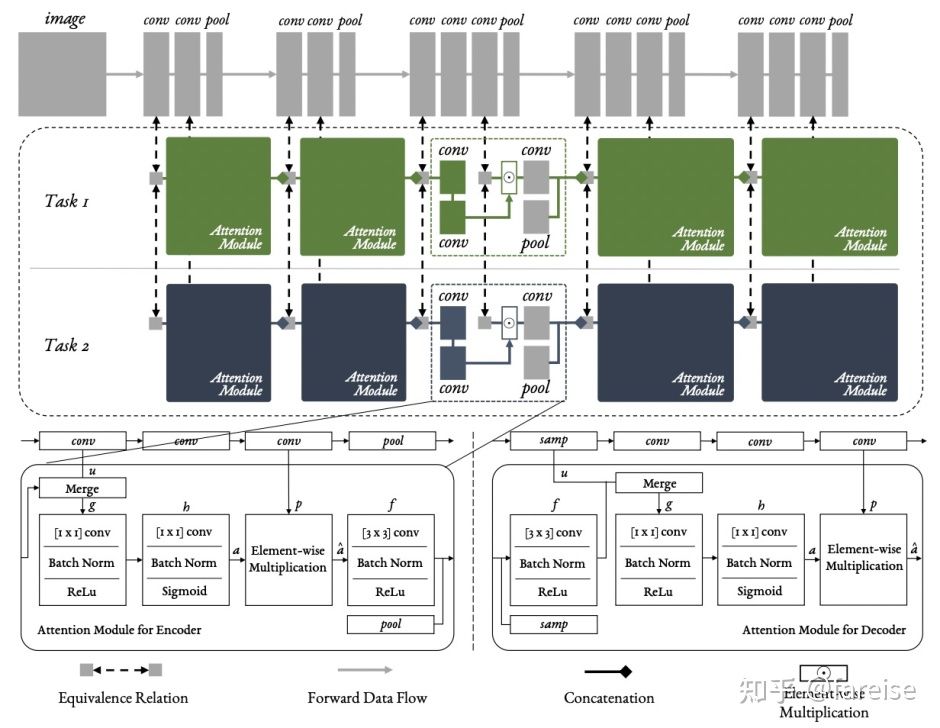
End-to-End Multi-Task Learning with Attention(CVPR 2019,MTAN)提出了一种基于参数共享+每个任务有自己独立Attention模块的多任务模型结构。每个任务的Attention模块从共享参数上进行Task-specific的特征选择。共享参数部分就是一个完整的预测模型(如CV中的VGG),在主模型外部,是每个Task针对每层的Attention模块。某个Task某层的输出即为共享网络中该层的输出和当前Task的Attention分对应元素加权平均,可以表示如下:
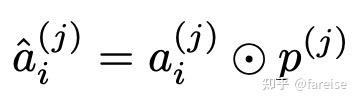
Attention的计算由一个单独的网络构成,每层Attention模块的输入为上一层输出的特征(第一层的时候输入为共享网络的输出,后面层的输入为共享网络输出+Attention处理后的Task-specific输出),经过多层卷积等处理,得到该任务在该层对应的Attention Mask。MTAN模型能够在Hard Parameter Sharing的同时,加入Attention对共享参数进行选择,提升了共享参数的泛化能力。
Hard Parameter Sharing的问题在于没有学习不同Task之间的关系,就强行进行了参数共享。在Low Resource Dependency Parsing: Cross-lingual Parameter Sharing in a Neural Network Parser(ACL 2015)中提出了将不同任务之间的参数通过L2正则进行约束的方法。在CV领域,一些研究已经验证了随着网络层数的增加,输出的表示越针对于具体Task,同时可迁移性也越来越差。因此,Learning Multiple Tasks with Multilinear Relationship Networks(ICML 2017)提出了MRN模型,针对接近输出端的全连接分类层的多任务学习优化。MRN模型是历史对多任务学习研究中贝叶斯方法的一个扩展,通过FC层的参数,学习不同任务之间的关系。该方法建立了所有任务的数据(X,Y)、所有任务的分类层参数W的后验概率分布,即求解给定所有任务的特征和Label,后验概率最大的所有任务的参数是什么,可以表示如下方程,其中所有Task的先验概率通过Tensor Normal Distribution求得:
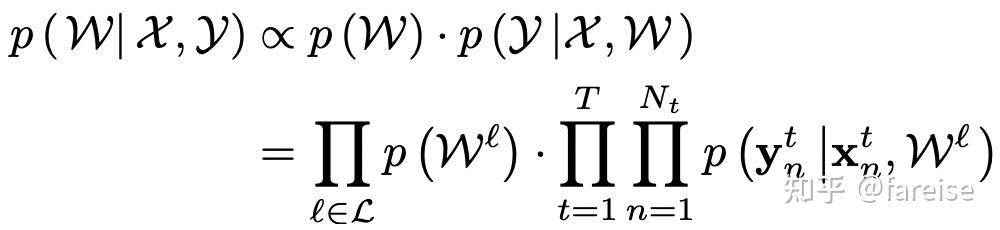
3. 参数共享+门控——MoE模型
2017年Google第一次提出了MoE模型结构:OUTRAGEOUSLY LARGE NEURAL NETWORKS: THE SPARSELY-GATED MIXTURE-OF-EXPERTS LAYER(2017)。模型包括一个门控网络,输入样本特征,输出对每个Expert的选择得分,并将原来每层所有样本共享的参数,变成多组参数,每组参数被称为一个Expert。这篇工作最开始提出并不是为了解决多任务学习问题,而是实现了一种理论模型:在保证运算效率不大幅提升的前提下,通过多组参数增加模型容量,每个样本激活模型中的一部分参数。
在此基础上,Modeling Task Relationships in Multi-task Learning with Multi-gate Mixture-of-Experts(KDD 2018)提出了用多专家网络(MMoE)解决多任务学习问题。网络由多个多任务共享的Expert,以及每个任务独有的Gate网络构成。每一个任务k的具体输出结果表示如下(fi表示第i个专家,gk表示第k个任务的门网络):
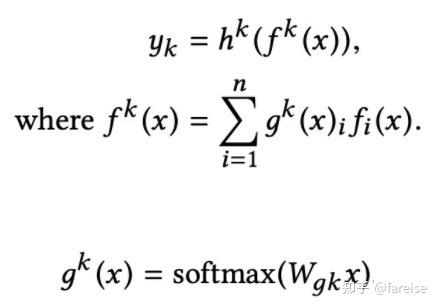
通过这种方式,每个Task的门网络可以基于样本信息学习如何选择一组专家进行预测。MMoE通过这种灵活的模型设计,希望模型能够自动根据底层Task的关系学习Expert参数如何分配。例如,当底层任务关系较弱时,模型能够学到让每个Task只激活一个其对应的Expert,相当于将Experts分割给不同的任务。
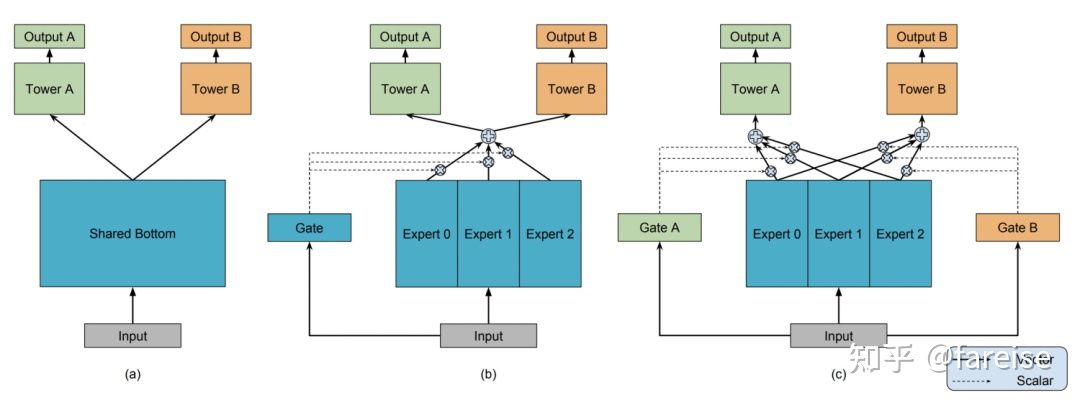
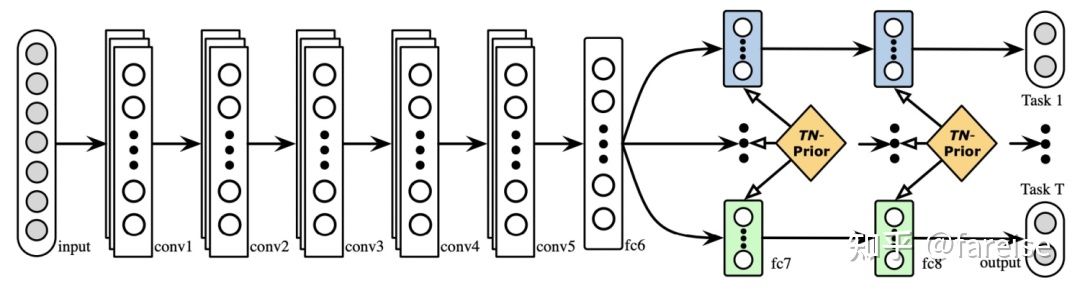
然而,MMoE由于所有参数都是所有任务共享的,没有显示定义不同任务的私有参数,当不同任务的关系较弱时,可能会导致不同任务的跷跷板现象,即两个任务无法同时达到最好,一个任务效果提升,伴随着另一个任务效果下降。因此,Progressive Layered Extraction (PLE): A Novel Multi-Task Learning (MTL) Model for Personalized Recommendations(Recsys 2020)提出了PLE方法,将模型参数显示的划分为私有部分和公共部分,提升多任务学习的鲁棒性,缓解私有知识和公共知识之间的负向影响。PLE和MMoE的主要区别在于,将多专家分成公共部分和每个Task独有的部分。同时,论文中指出在网络最初阶段并不能真正确定哪些Expert需要共用哪些Expert独有。因此论文提出了多层次的信息提取方法,在网络的最底层增加多个Extraction Layer全局Gate,用来给所有Expert打分,在上层再区分公共和独有部分。其实可以理解底层先通过MoE不区分公共/私有部分提取基础特征,在上层再逐渐将公共/私有部分区分开。
MoE模型结构也被广泛应用于高效进行模型容量扩充,Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity(2021)中就利用MoE结构扩展Transformer模型容量,并设计了多种MoE调优方法。
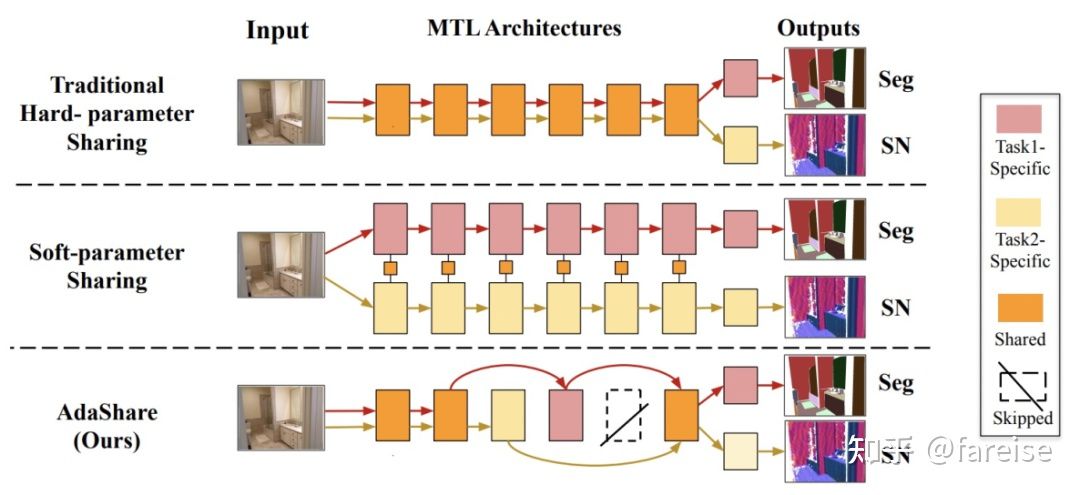
4. 自动学习参数共享/私有方式
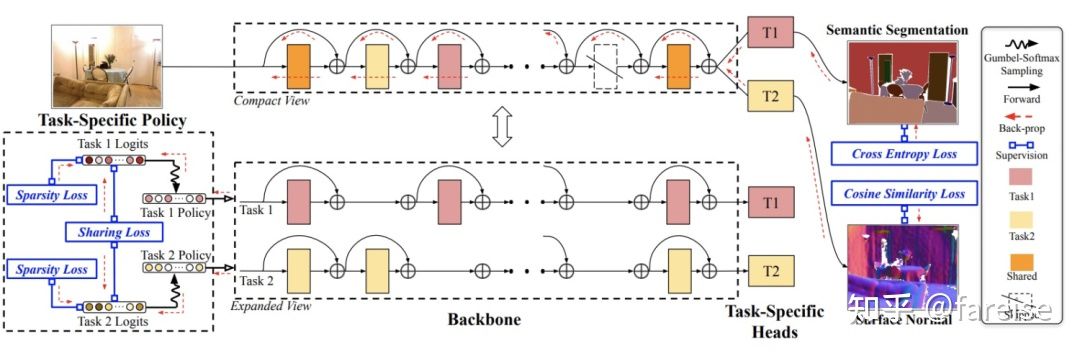
MoE类的方法主要通过参数共享和门控的方式进行多任务学习,PLE提出了将共享参数和私有参数显示区分。那么更进一步,我们能不能让网络自动学习哪些参数应该share,哪些参数应该private呢?AdaShare: Learning What To Share For Efficient Deep Multi-Task Learning(NIPS 2020)提出了学习网络中每组参数的共享/私有方式。对于每一个Task、每一层参数,AdaShare通过一个Policy Network,结合Gumbel Softmax,学习一个当前Task当前层参数是跳过还是复用。这相当于在每个Task的网络中增加了shortcut。为了提升模型性能,文中提出了两个正则化Loss约束学习过程,这两个正则化Loss都和Policy Network学到的打分有关。首先,引入sparsity regularization,通过将Policy为复用的得分加入Loss,让每个Task有更多层跳过,实现模型大小上的缩减,提升运行效率。其次,为了让两个任务Share更多信息,引入两个Task的Policy打分的L1距离,让两个Task学到的Policy越近越好,促进两个Task共享更多的网络参数。AdaShare在训练阶段为了提升收敛速度,采用了多阶段的训练方法。首先让多任务共享所有参数训练几轮,然后随着训练轮数的增加,逐渐从最后几层开始使用Policy进行参数选择。
Sharing Less is More: Lifelong Learning in Deep Networks with Selective Layer Transfer(ICML 2021)中提出通过EM算法选择每个Task在每一层是否进行参数共享,是一种和具体模型结构无关的算法。对于某个Task,定义一个二元向量(Transfer Configuration),每个值表示某一层是使用Task-specific的参数还是共享的参数。本文的核心是求解各个Transfer Configuration的概率分布。在E阶段,评估每种Transfer Configuration的效果(即使用当前配置得到的最终表示在预测任务上的效果);在M阶段,更新Task-specific参数以及共享参数。具体流程为,对于每一个batch的数据,随机采样一个configuration向量,计算该configuration的效果,并进而得到后验概率。然后执行多步M-step,使用这个Loss更新模型参数。模型的原理示意图和算法流程如下:

5. 总结
本文通过7篇顶会论文介绍了多任务学习建模的核心思路以及学术界的经典工作,从最开始的Hard/Soft Parameter Sharing,到MoE模型,再到最近提出的自动学习参数共享/私有方式等方法,从不同角度介绍了多任务学习的核心思路,希望对大家在实际工作或研究中有所帮助。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“ 圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
公众号后台回复“ 多任务”,即可获取相关论文资料集合~
以上是关于7篇顶会论文带你梳理多任务学习建模方法的主要内容,如果未能解决你的问题,请参考以下文章