javaLongAdder源码分析原理分析
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了javaLongAdder源码分析原理分析相关的知识,希望对你有一定的参考价值。

1.概述
先参考使用相关的文档:
【java】阿里为什么推荐使用LongAdder,而不是volatile?
针对JDK中的原子类,想必大家都熟悉AtomicInteger,AtomicLong等类。他们都是采用CAS乐观锁方式来实现的。
但是这种方式是否还有继续优化的空间呢?答案是肯定的。
CAS乐观锁对临界区的数据(也就是atomicLong中的volatile long value属性)进行修改,这个属性是热点数据。并发量高的时候,会出现很多线程都轮询修改value属性的情况,CPU消耗比较高。
大家在想一下,在秒杀,拍卖,银行转账等业务场景下,可能存在以下情况:大量客户的请求都需要修改某个银行账户的余额。有一种优化策略就是将该银行热点账户拆分为多条记录,将请求hash路由到不同的子账户中进行计算。那么上述Atomic类也可以采用该种策略:热点数据拆分。
这就是阅读源码的作用,可以学习到各种各样的优秀设计,并且可以将其应用到具体的工作之中。
2.LongAdder案例
编写java代码测试LongAdder:
@Test
public void test() throws InterruptedException
LongAdder longAdder = new LongAdder();
AtomicLong aLong = new AtomicLong();
ExecutorService threadPool = Executors.newFixedThreadPool(100);
for(int i = 0; i < 1000000;i++)
threadPool.execute(() ->
longAdder.increment();
aLong.incrementAndGet();
);
TimeUnit.SECONDS.sleep(2);//等待线城池执行完成
System.out.println(longAdder.longValue());
System.out.println(aLong.get());
注意上面线程数设置的多一点,才能造成比较激烈的竞争。
在longValue()方法中打断点看一下实际的结果分布,可以看到base中有值,并且有4个cells,每个cell都有值。将4个cell的值累加再加上base的值正好是100W,详细源码分析请继续阅读:
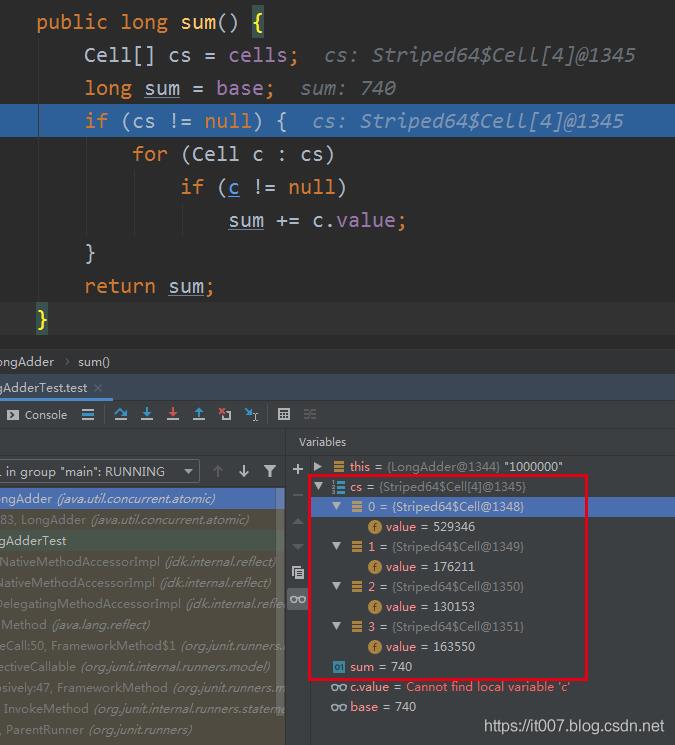
3.LongAdder源码分析
首先画一个AtomicLong和LongAdder的临界区数据对比图:

从上面的图中大家可以看到临界区数据的分布 ,至此可以完全理解LongAdder的优化思路了。
接下来看源码,主要关注红框内的方法

LongAdder继承自Striped64类。Striped64类中核心参数:
//CPU的数量,用于cell数组容量扩容
static final int NCPU = Runtime.getRuntime().availableProcessors();
/**
* 容量大小是2的幂次方。当竞争大的时候,则会修改cell中的数值
*/
transient volatile Cell[] cells;
/**
* base基础数据,CAS竞争不大的话,则直接修改base
*/
transient volatile long base;
/**
* 是否竞争激烈
*/
transient volatile int cellsBusy;
可以看到都是volatile修饰的,都解决了JMM中的可见性的问题。
首先看一下LongAdder核心的Cell类:
/**
* Padded variant of AtomicLong supporting only raw accesses plus CAS.
*
* JVM intrinsics note: It would be possible to use a release-only
* form of CAS here, if it were provided.
*/
@jdk.internal.vm.annotation.Contended static final class Cell
volatile long value;//Cell中存储数据的属性,volatile 修饰保证可见性
Cell(long x) value = x;
final boolean cas(long cmp, long val)
return VALUE.compareAndSet(this, cmp, val); //CAS修改
final void reset()
VALUE.setVolatile(this, 0L);
final void reset(long identity)
VALUE.setVolatile(this, identity);
final long getAndSet(long val)
return (long)VALUE.getAndSet(this, val);
// VarHandle mechanics
private static final VarHandle VALUE;
static
try
MethodHandles.Lookup l = MethodHandles.lookup();
VALUE = l.findVarHandle(Cell.class, "value", long.class);
catch (ReflectiveOperationException e)
throw new ExceptionInInitializerError(e);
@jdk.internal.vm.annotation.Contended这个注解的意思是JVm内部进行了优化,解决了伪共享问题。
再看一下获取数据的方法:
public long longValue()
return sum();
public long sum()
Cell[] cs = cells;//cell中的数据
long sum = base;//基本数据
if (cs != null)
for (Cell c : cs)
if (c != null)
sum += c.value;
return sum;
可以看到很简单,将base和cells数组中的数据累加起来即可。
继续,看如何CAS递增数据,这里比较复杂一些。
/**
* Adds the given value.
*
* @param x the value to add
*/
public void add(long x)
Cell[] cs; long b, v; int m; Cell c;
if ((cs = cells) != null || !casBase(b = base, b + x))
boolean uncontended = true;
if (cs == null || (m = cs.length - 1) < 0 ||
(c = cs[getProbe() & m]) == null ||
!(uncontended = c.cas(v = c.value, v + x)))
longAccumulate(x, null, uncontended);
/**
* Equivalent to @code add(1).
*/
public void increment()
add(1L);
初始化时,cells肯定为空。我们先看一下casBase(b = base, b + x)的实现
/**
* CASes the base field.
*/
final boolean casBase(long cmp, long val)
return BASE.compareAndSet(this, cmp, val);
当CAS修改base的值失败时,则说明并发比较高,则进入到if内部代码,首先设置uncontended =true,表明竞争激烈。
接下来需要判断4个条件:
cs == null
(m = cs.length - 1) < 0
(c = cs[getProbe() & m]) == null
!(uncontended = c.cas(v = c.value, v + x))
前两个条件判断cells数组是否为空,如果是空,则走longAccumulate方法。
第三个条件是根据当前线程与数组进行逻辑与操作,获得的cell位置如果为空则走longAccumulate方法。
第三步的结果c是线程路由的cells数组的位置。
第四个条件是对这个cell中的value进行CAS修改,修改失败则走longAccumulate方法。
通过这几步可以知道,LongAdder是在遇到并发激烈时,将线程路由到cells数组中的某个位置对该位置的Cell的value进行cas修改。而longAccumulate则会对cells数组进行扩容等维护工作。看看longAccumulate源码:
final void longAccumulate(long x, LongBinaryOperator fn,
boolean wasUncontended)
int h;
if ((h = getProbe()) == 0)
ThreadLocalRandom.current(); // 强制初始化
h = getProbe();//返回当前线程的threadLocalRandomProbe值
wasUncontended = true;
boolean collide = false; // True if last slot nonempty
done: for (;;)
Cell[] cs; Cell c; int n; long v;
if ((cs = cells) != null && (n = cs.length) > 0)
if ((c = cs[(n - 1) & h]) == null)
if (cellsBusy == 0) // 尝试添加新的Cell
Cell r = new Cell(x); // Optimistically create乐观创建cell
if (cellsBusy == 0 && casCellsBusy())
try // Recheck under lock
Cell[] rs; int m, j;
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
rs[j = (m - 1) & h] == null)
rs[j] = r;
break done;
finally
cellsBusy = 0;
continue; // Slot is now non-empty
collide = false;
else if (!wasUncontended) // CAS already known to fail
wasUncontended = true; // Continue after rehash
else if (c.cas(v = c.value,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
//上面这里是对cell中的value进行cas修改
break;
else if (n >= NCPU || cells != cs)
collide = false; // 判断数组大小是否大于核数【cells数组最大不超过CPU可用核数】
else if (!collide)
collide = true;
else if (cellsBusy == 0 && casCellsBusy())
try //对cells数组进行扩容,直接扩容为2倍,下面是采用位移操作 : n << 1
if (cells == cs) // Expand table unless stale
cells = Arrays.copyOf(cs, n << 1);
finally
cellsBusy = 0;
collide = false;
continue; // Retry with expanded table
h = advanceProbe(h);
else if (cellsBusy == 0 && cells == cs && casCellsBusy())
try // Initialize table
if (cells == cs)
Cell[] rs = new Cell[2];//初始化cells数组大小是2
rs[h & 1] = new Cell(x);
cells = rs;
break done;
finally
cellsBusy = 0;
// cas修改base变量。
else if (casBase(v = base,
(fn == null) ? v + x : fn.applyAsLong(v, x)))
break done;
该方法大概思路就是无限循环对cells数组进行操作更新。如果对应的cell为空则cas创建cell并插入,如果不为空则cas修改其value值。如果cas修改失败则扩容,但是扩容最大值是CPU核数。
以上是关于javaLongAdder源码分析原理分析的主要内容,如果未能解决你的问题,请参考以下文章