经验分享谈谈 cuda 线程束与内存模型
Posted 极智视界
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经验分享谈谈 cuda 线程束与内存模型相关的知识,希望对你有一定的参考价值。
欢迎关注我的公众号 [极智视界],获取我的更多学习笔记
大家好,我是极智视界,本文谈谈 cuda 线程束与内存模型。
Cuda thread 组成 block,block 组成 grid,形成嵌套网格状结构,目的是为了矩阵并行计算时,能对应矩阵位置。
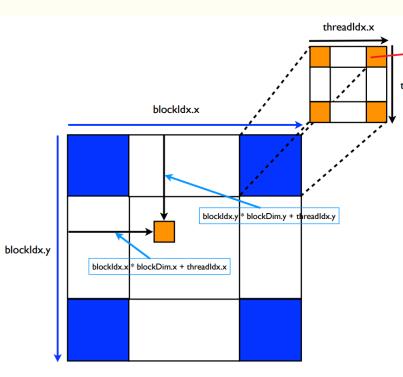
文章目录
1 线程束
SM 是一种单指令多线程 (single Instruction MultipleThread, SIMT) 架构的处理器,线程束是 SM 中基本的执行单元,cuda 执行的实质是线程束的执行 (所有线程按照 SIMT 的方式执行,每一步执行相同的指令,但是处理的数据为私有数据)。
当一个 grid 被启动后等价于 core 被启动,每个 core 对应自己的 grid,grid 里包含了 blocks,当线程块被分到 SM 之后会被分成多个线程束 (线程块分批在物理机器上运行,线程块内线程束可能进度不一样,线程束内线程进度一样),每个线程束一般有 32 个线程。

当一个线程块中有 128 个线程的时候,其分配到 SM 上执行时,会分成 4 个块:
Warp1:thread 0... thread31
Warp2:thread 32... thread63
Warp3:thread 64... thread95
Warp4:thread 96... thread127
计算 threadID 的目的是将多维的线程转化到内存中的一维。
2 内存模型
cuda 编程内存模型示意如下:
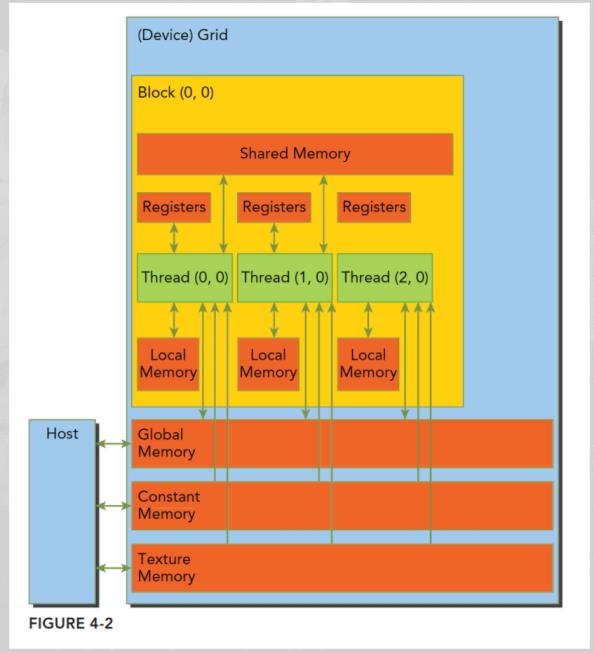
寄存器:速度最快的内存空间;
共享内存:片上内存 L1;
本地内存:高延迟,低带宽;
常量内存:SM 都有专用的常量内存缓存;
纹理内存:通过指定缓存访问全局内存,完成一些如滤波的操作;
全局内存:GPU 上最大的内存空间,延迟最高;
3 内存访问模式
每个 SM 都有自己的 L1,而 L2 是所有 SM 公用的,如下:
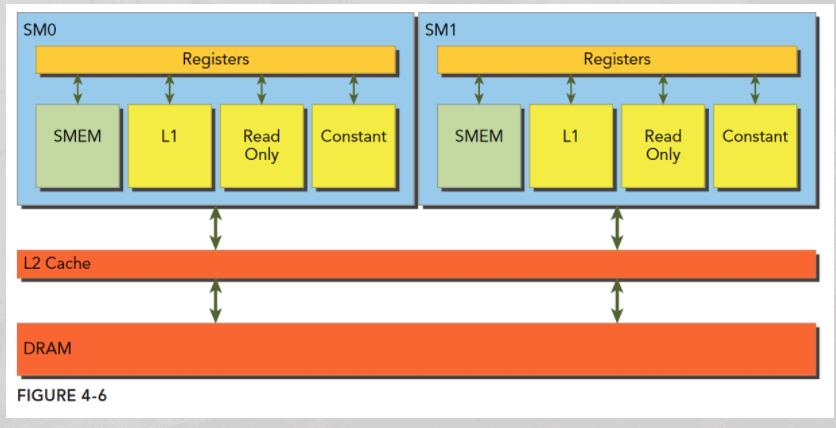
Kernel 函数在运行时需要在全局内存 DRAM 中读取数据,有两种粒度:
- 使用L1 :128字节
- 不使用L1:32字节
注意 SM 执行的基础是 线程束,也就是说,当一个 SM 中正在被执行的某个线程需要访问内存,此时和它同线程束的其他 31 个线程也要访问内存,这个基础就表示即使每个线程只访问一个字节,在执行的时候,只要有内存请求,就至少是 32 个字节,所以不使用一级缓存的内存加载时,一次粒度是 32 字节而不是更小。
对齐访问是由于当访问地址是 32 或 128 的偶数倍时,非对齐会造成资源浪费。合并访问是当一个线程束内的线程访问的内存都在一个内存块中时。如下:
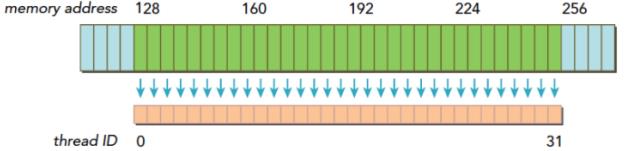
上图中蓝色的是 DRAM,绿色的是对齐地址段,橙色的是线程需要的数据,如果所需要的数据都在对齐地址段中,无论连续不连续,只需要读取一次。而如果数据不在对齐地址段中,至少读取 2 次。最极端的情况,每个 128 上只有 1 个,那么就需要读取 32 次,利用率只有 1/128。
下面来看几种情况。
**L1 缓存加载,粒度 128 **,如下:
- 对齐合并的访问,利用率为 100%

- 对齐的,但是不是连续的,每个线程访问的数据都在一个块内,但是位置是交叉的,此时利用率也为 100%

- 连续非对齐的,线程束请求一个连续的非对齐的 32 个 4 字节数据,会出现数据横跨两个块,但并没有对齐。当启用一级缓存的时候,就要两个 128 字节的事务来完成、

- 线程束所有线程请求同一个地址,此时肯定落在一个缓存行范围,若按照请求的是 4 字节数据来说,使用一级缓存的利用率是 4 / 128 = 3.125%

- 最坏的情况是每个线程束内的线程请求的都是不同的缓存行内,所有数据分布在 N 个缓存行上,其中 1 <= N <= 32,那么请求 32 个 4 字节的数据,就需要 N 个事务来完成,此时利用率为 1 / N

没有L1缓存的加载,粒度32,如下:
- 对齐合并访问 128 字节,此时是理想情况,使用 4 个段,利用率为 100%

- 对齐不连续访问 128 字节情况,都在四个段内且互不相同,此时利用率也是 100%

- 连续不对齐,一个段 32 字节,一个连续的 128 字节的请求,即使不对齐,最多也不会超过 5 个段,利用率为 4 / 5 = 80%

- 所有线程访问一个 4 字节的数据,此时的利用率为 4 / 32 = 12.5%

- 所有目标数据分散在内存的各个角落,假设需要 N 个内存段,此时与使用一级缓存比较也是具有优势的,因为 N x 128 还是要比 N x 32 大不少,假设 N 不会因为 128 或 32 而变化,当使用大粒度的缓存行时,N 有可能会减小

4 共享内存
全局内存是较大的板载内存,延迟高、带宽低;共享内存 (shared memory,SMEM) 是片上的较小的内存,延迟低、带宽高。SM 上有共享内存、L1、Read Only 和 constant,所有从 DRAM 上来的数据都要经过 L2,更接近 SM 计算核心的 SMEM、L1、ReadOnly 和 Constant 拥有更快的读取速度,SMEM 和 L1 相比于 L2 延迟低大概 20~30 倍,带宽大约是 10 倍。
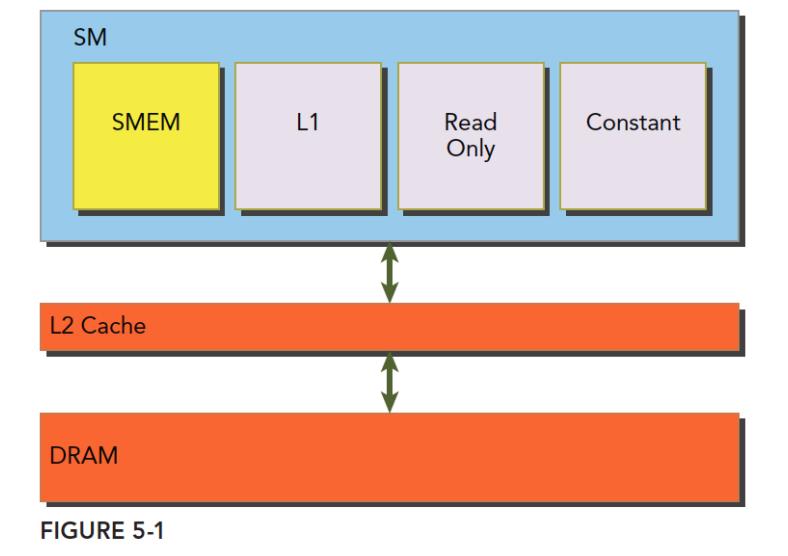 共享内存是有限的,与 L1 Cache 共用一块 on-chip 内存,用户可以调整 L1 cache 与共享内存的大小组合。
共享内存是有限的,与 L1 Cache 共用一块 on-chip 内存,用户可以调整 L1 cache 与共享内存的大小组合。
对于每个线程对共享内存的访问请求:
1. 最好的情况是当前线程束中的每个线程都访问一个不冲突的共享内存;
2. 当访问冲突的时候,一个线程束 32 个线程,需要处理 32 个事务;
3. 当 32 个线程束访问同一个地址,那个一个线程以广播的形式给其他线程(全局内存读一个并不是广播);
把共享内存看成一个二维结构,每一列为一个存储体 (bank,每一行不同单元的地址是连续的,可以同时访问,32 个存储体的目的是对应一个线程束中有 32 个线程。
一个储存体有多个地址,当多个线程访问(不同地址)同一个储存体时,发生冲突,因为储存体一个周期只能执行一次操作,如果是同一地址,那么在得到地址后以广播的形式给其他线程 (多线程只读取了一个数据相对效率低)。
线程束访问共享内存的时候有下面 3 种经典模式:
- 并行访问,多地址访问多存储体 ;
- 串行访问,多地址访问同一存储体 ;
- 广播访问,单一地址读取单一存储体 x ;
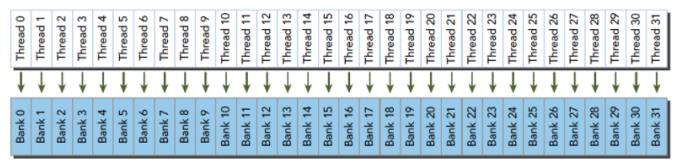
最优访问模式 --> 并行不冲突:
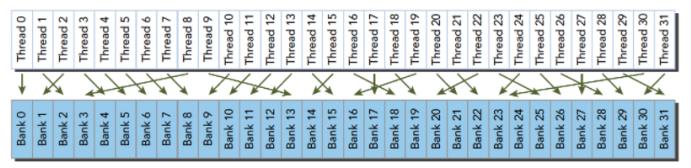
不规则的访问模式 --> 并行不冲突:
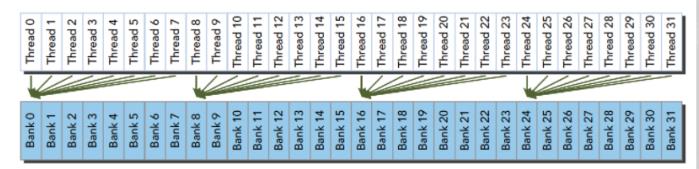
不规则的访问模式 --> 并行可能冲突,也可能不冲突:
好了,以上分享了 cuda 线程束与内存模型相关内容,希望我的分享能对你的学习有一点帮助。
【公众号传送】

扫描下方二维码即可关注我的微信公众号【极智视界】,获取更多AI经验分享,让我们用极致+极客的心态来迎接AI !

以上是关于经验分享谈谈 cuda 线程束与内存模型的主要内容,如果未能解决你的问题,请参考以下文章