/文本/字符串雷同率
Posted 、Dong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了/文本/字符串雷同率相关的知识,希望对你有一定的参考价值。
文章目录
前言
计算文章/字符串的相似度有多种算法,本文将采用java+jieba/hanlp分词进行余弦相似性计算。一、理论知识
余弦距离,也称为余弦相似度,是用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小的度量。
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,这就叫"余弦相似性"。
为了简单起见,我们先从句子着手。
句子A:我喜欢看电视,不喜欢看电影。
句子B:我不喜欢看电视,也不喜欢看电影。
请问怎样才能计算上面两句话的相似程度?
基本思路是:如果这两句话的用词越相似,它们的内容就应该越相似。因此,可以从词频入手,计算它们的相似程度。
1.分词
句子A:我/喜欢/看/电视,不/喜欢/看/电影。
句子B:我/不/喜欢/看/电视,也/不/喜欢/看/电影。
2.列出所有的词
我,喜欢,看,电视,电影,不,也。
3.计算词频
句子A:我 1,喜欢 2,看 2,电视 1,电影 1,不 1,也 0。
句子B:我 1,喜欢 2,看 2,电视 1,电影 1,不 2,也 1。
4.写出词频向量
句子A:[1, 2, 2, 1, 1, 1, 0]
句子B:[1, 2, 2, 1, 1, 2, 1]
到这里,问题就变成了如何计算这两个向量的相似程度。
5.计算相似度
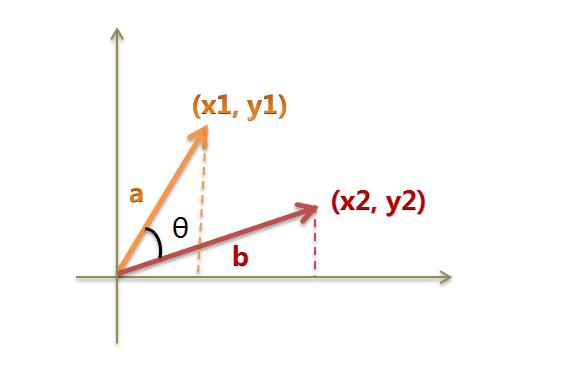
我们可以把它们想象成空间中的两条线段,都是从原点([0, 0, …])出发,指向不同的方向。两条线段之间形成一个夹角,如果夹角为0度,意味着方向相同、线段重合;如果夹角为90度,意味着形成直角,方向完全不相似;如果夹角为180度,意味着方向正好相反。因此,我们可以通过夹角的大小,来判断向量的相似程度。夹角越小,就代表越相似。

以二维空间为例,上图的a和b是两个向量,我们要计算它们的夹角θ。余弦定理告诉我们,可以用下面的公式求得:
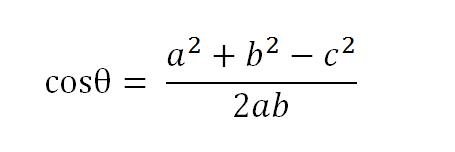

假定a向量是[x1, y1],b向量是[x2, y2],那么可以将余弦定理改写成下面的形式:
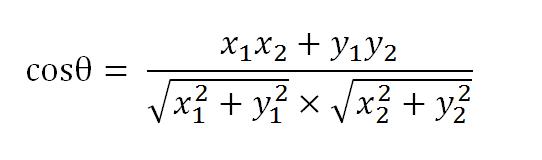
数学家已经证明,余弦的这种计算方法对n维向量也成立。假定A和B是两个n维向量,A是 [A1, A2, …, An] ,B是 [B1, B2, …, Bn] ,则A与B的夹角θ的余弦等于:
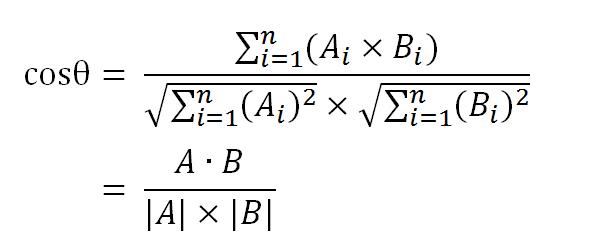
使用这个公式,我们就可以得到,句子A与句子B的夹角的余弦。
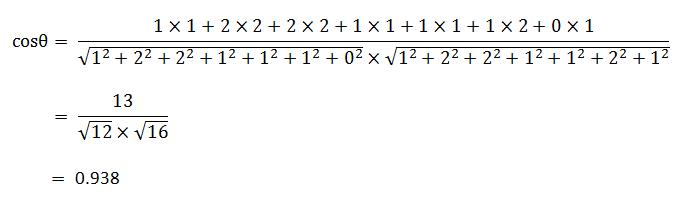
余弦值越接近1,就表明夹角越接近0度,也就是两个向量越相似,所以,上面的句子A和句子B是很相似的。
二、java开发样例
1.pom.xml
引入分词jar包,样例中使用了jieba和hanlp,实际选择一个即可
<!-- jieba分词 -->
<dependency>
<groupId>com.huaban</groupId>
<artifactId>jieba-analysis</artifactId>
<version>1.0.2</version>
</dependency>
<!-- hanlp分词 -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.8.2</version>
</dependency>
2.相似度计算代码
package com.neu.his.domain.control;
import com.google.common.util.concurrent.AtomicDouble;
import com.hankcs.hanlp.HanLP;
import com.hankcs.hanlp.seg.common.Term;
import com.huaban.analysis.jieba.JiebaSegmenter;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.stereotype.Service;
import java.math.BigDecimal;
import java.util.*;
import java.util.concurrent.atomic.AtomicInteger;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
import java.util.stream.Collectors;
@Service
public class QcSimilarDocDomain
private static final Logger log = LoggerFactory.getLogger(QcSimilarDocDomain.class);
private static Pattern pattern = Pattern.compile("[\\\\pP‘’“”]");
private final double COS_DOUBLE = 0.8;
/**
* 文本相似度对比处理
*
* @param firstText
* @param secondText
* @return
*/
public boolean process(String firstText, String secondText)
List<String> firstList = segmentByJieba(firstText);
Map<String, AtomicInteger> firstMap = getFrequency(firstList);
log.debug("第一个句子分词结果:", firstList);
log.debug("第一个句子词频结果:", firstMap);
List<String> secondList = segmentByJieba(secondText);
Map<String, AtomicInteger> secondMap = getFrequency(secondList);
log.debug("第二个句子分词结果:", secondList);
log.debug("第二个句子词频结果:", secondMap);
Set<String> allWordsSet = new TreeSet<>();
allWordsSet.addAll(firstList);
allWordsSet.addAll(secondList);
log.debug("所有词:", allWordsSet);
double cos = cos(firstMap, secondMap, allWordsSet);
log.info("余弦相似度:", cos);
return cos >= COS_DOUBLE ? true : false;
/**
* jieba分词
**/
public List<String> segmentByJieba(String words)
JiebaSegmenter segmenter = new JiebaSegmenter();
List<String> resultList = segmenter.sentenceProcess(words);
//去除分词标点符号
return resultList.stream().filter(s ->
Matcher matcher = pattern.matcher(s);
return !matcher.find();
).collect(Collectors.toList());
/**
* hanlp分词
*
* @param text
* @return
*/
public List<String> segmentByHanLP(String text)
List<Term> termList = HanLP.segment(text);
return termList.stream().map(s -> s.word).collect(Collectors.toList());
/**
* 计算词频
*
* @param words
* @return
*/
private static Map<String, AtomicInteger> getFrequency(List<String> words)
Map<String, AtomicInteger> freq = new HashMap<>();
words.forEach(i -> freq.computeIfAbsent(i, k -> new AtomicInteger()).incrementAndGet());
return freq;
/**
* 计算余弦相似度
*
* @param firstMap
* @param secondMap
* @param allWordsSet
* @return
*/
public double cos(Map<String, AtomicInteger> firstMap, Map<String, AtomicInteger> secondMap, Set<String> allWordsSet)
AtomicDouble ab = new AtomicDouble();// a.b
AtomicDouble aa = new AtomicDouble();// |a|的平方
AtomicDouble bb = new AtomicDouble();// |b|的平方
allWordsSet.parallelStream().forEach(word ->
//看同一词在a、b两个集合出现的此次
AtomicInteger x1 = firstMap.get(word);
AtomicInteger x2 = secondMap.get(word);
if (x1 != null && x2 != null)
//x1x2
double oneOfTheDimension = x1.doubleValue() * x2.doubleValue();
//+
ab.addAndGet(oneOfTheDimension);
if (x1 != null)
//(x1)^2
double oneOfTheDimension = x1.doubleValue() * x1.doubleValue();
//+
aa.addAndGet(oneOfTheDimension);
if (x2 != null)
//(x2)^2
double oneOfTheDimension = x2.doubleValue() * x2.doubleValue();
//+
bb.addAndGet(oneOfTheDimension);
);
//|a| 对aa开方
double aaa = Math.sqrt(aa.doubleValue());
//|b| 对bb开方
double bbb = Math.sqrt(bb.doubleValue());
//使用BigDecimal保证精确计算浮点数
//double aabb = aaa * bbb;
BigDecimal aabb = BigDecimal.valueOf(aaa).multiply(BigDecimal.valueOf(bbb));
//similarity=a.b/|a|*|b|
//divide参数说明:aabb被除数,9表示小数点后保留9位,最后一个表示用标准的四舍五入法
double cos = BigDecimal.valueOf(ab.get()).divide(aabb, 9, BigDecimal.ROUND_HALF_UP).doubleValue();
return cos;
public static void main(String[] args)
QcSimilarDocDomain qcSimilarDocDomain = new QcSimilarDocDomain();
String firstText = "我喜欢看电视,不喜欢看电影。";
String secondText = "我不喜欢看电视,也不喜欢看电影。";
qcSimilarDocDomain.process(firstText, secondText);
结尾
- 感谢大家的耐心阅读,如有建议请私信或评论留言。
- 如有收获,劳烦支持,关注、点赞、评论、收藏均可,博主会经常更新,与大家共同进步
以上是关于/文本/字符串雷同率的主要内容,如果未能解决你的问题,请参考以下文章