重学SpringCloud系列七之服务熔断降级hystrix
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了重学SpringCloud系列七之服务熔断降级hystrix相关的知识,希望对你有一定的参考价值。
重学SpringCloud系列七之服务熔断降级hystrix
- 服务降级&熔断&限流
- Hystrix集成并实现服务熔断
- Jemter模拟触发服务熔断
- Hystrix服务降级fallback
- Hystrix结合Feign服务降级
- 远程服务调用异常传递的问题
- Hystrix-Feign异常拦截与处理
- Hystrix-DashBoard单服务监控
- Hystrix-dashboard集群监控
服务降级&熔断&限流
一、高并发&高可用
其实我们讲过所有的Spring Cloud知识,都为了解决两个问题:一个是高并发,一个是高可用。解决高并发&高可用问题的方法有很多,比如:
- 从应用层面:一个好汉三个帮,一个服务实例无法完成的事情,启动多个实例来完成,请求分流负载均衡。
- 从IO模型层面:越来越多的服务框架使用多路选择的异步IO模型,代替阻塞IO模型。
- 从架构层面:主从互备、读写分离等等
- 从算法层面:提高单位请求的运行效率,从而提高并发服务能力
- ……
但是无论你怎么升级硬件、改善架构、改善算法,永远都会有上限,也永远。服务能力就是会存在某一时间段内无法达到高可用的要求,甚至崩溃。
二、服务雪崩
在分布式服务的系统内,很多的用户请求在系统内部都是存在级联式远程调用的。如下图所示:一次请求先后经过Service A、B、C、D,如果此时服务D发生异常,长时间无法响应或者根本不响应,将导致Service C服务调用无法正常响应,进而导致Service B和Service A的响应也出现问题。这种因为服务调用链中某一个服务不可达或超时等异常情况,导致其上游的服务也出现响应异常或者崩溃。当这种情况在高并发环境下就会导致整个系统响应超时、资源等待耗尽,这种现象就是“服务雪崩”。

当一个服务Service1需要在其方法实现中,调用多个服务提供者时,其中一个服务不可达或者超时的的情况发生,也会导致请求失败。在高并发的环境下,这个问题会更加凸显,也会导致整个微服务系统资源出现等待、无法释放的情况。从而产生服务雪崩。

服务重试机制也会产生服务雪崩
很多朋友在遇到上面的问题时,很自然的想到我们之前为大家讲过的服务请求重试机制(Ribbon和OpenFeign都可以实现服务的请求失败重试)。
- 服务请求重试机制在很大程度上解决了由于网络瞬时不可达的问题,导致服务请求失败的问题。但是在很多的情况下:造成“服务雪崩”的元凶正是“服务重试”机制。
- 某个服务本来就已经出现问题了,造成资源占用无法释放、请求延时等问题。这时在请求失败之后又不断的发送重试请求,在原本就无法释放的资源基础上继续膨胀式占用,导致整个系统资源耗尽。导致服务雪崩。
- 那么是不是我们就应该将“服务重试”配置关闭掉呢?当然也不是,你不能因为马路上发生了车祸,就不让所有人开车。
三、如何解决雪崩的问题之一:服务熔断
理解“熔断”这个词的由来,可以帮助我们跟好的理解“熔断”在微服务体系应用的意义。
- 熔断机制的英文是circuit breaker mechanism,其中circuit breaker在电工学里就是断路器的意思。当电路中出现短路时,断路器会立即断开电路,保护电路负载的安全。
- 后来熔断机制被引入股票交易。最早起源于美国,1987年10月19日,纽约股票市场爆发了史上最大的一次崩盘事件,道琼斯工业指数一天之内重挫508.32点,跌幅达22.6%,由于没有熔断机制和涨跌幅限制,许多百万富翁一夜之间沦为贫民,这一天也被美国金融界称为“黑色星期一”。2020年(今年)由于新冠疫情的影响,美国股市多次触发熔断机制,在一段时间内暂停交易,进而对整个市场起到一定的保护作用。
服务熔断:指的是在服务提供者的错误率达到一定的比例之后, 断路器就会熔断一段时间,不再去请求服务提供者,从而避免上游服务被拖垮,进而达到保护整体系统可用性的目的。
熔断恢复:熔断时间过了以后再去尝试请求服务提供者,一旦服务提供者的服务能力恢复,请求将继续可以调用服务提供者,此过程完全不需认为参与。
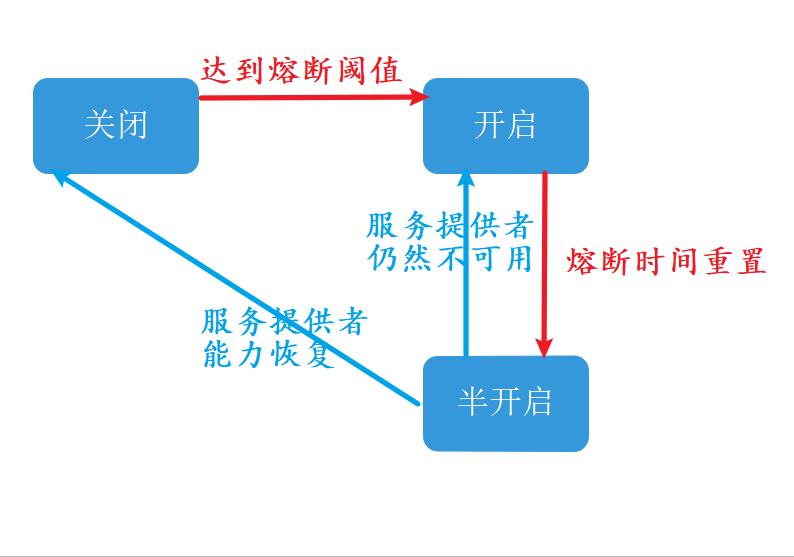
上图是“断路器”的状态转换图
- 断路器默认处于“关闭”状态,当服务提供者的错误率到达阈值,就会触发断路器“开启”。
- 断路器开启后进入熔断时间,到达熔断时间终点后重置熔断时间,进入“半开启”状态
- 在半开启状态下,如果服务提供者的服务能力恢复,则断路器关闭熔断状态。进而进入正常的服务状态。
- 在半开启状态下,如果服务提供者的服务能力未能恢复,则断路器再次触发服务熔断,进入熔断时间。
四、如何解决雪崩的问题之二:服务降级
通过上面的讲解,相信大家已经知道了服务熔断的含义及意义是什么。但是明显遗留了一个问题:服务熔断之后就不在去请求服务调用者原本的方法,那该去请求谁?总不能没有响应吧!这就需要使用到“服务降级”机制了。
白话说服务降级:服务降级是一种兜底的服务策略,体现了一种“实在不行就怎么这么样”的思想。想去北京买不到飞机票,实在不行就开车去吧;感冒了想去看病挂不上号,实在不行就先回家吃点药睡一觉吧;实在不行之后的处理方法,被称为fallback方法。
4.1.在服务调用端进行服务降级
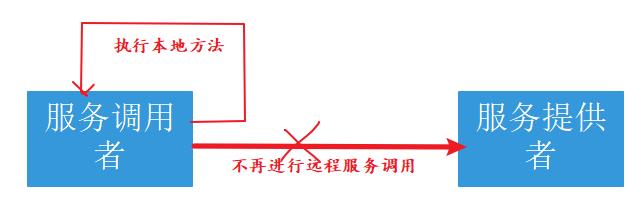
当服务提供者故障触发调用者服务的熔断机制,服务调用者就不再调用远程服务方法,而是调用本地的fallback方法。此时你需要预先提供一个处理方法,作为服务降级之后的执行方法,fallback返回值一般是设置的默认值或者来自缓存。
4.2.在服务提供端进行服务降级
除了可以在服务调用端实现服务降级,还可以在服务提供端实现服务降级。实际上在大型的微服务系统中,服务提供者和服务消费者并没有严格的区分,很多的服务既是提供者,也是消费者。

服务提供者原本的处理请求方法是AMethod(如运行时异常),已经不能响应请求,实在不行了就去执行预先定义好的fallback方法。fallback返回值一般是设置的默认值或者来自缓存。
当然,除了服务熔断会触发服务降级和程序运行时异常,还有其他几种异常也可以触发服务降级
- 响应超时
- 达到服务限流标准
- hystrix线程池或信号量爆满
五、服务限流
服务限流:通过对并发访问/请求进行限速或者一个时间窗口内的请求数量进行限制来保护系统,一旦达到限制速率则可以拒绝服务。拒绝服务之后,可以有如下的处理方式:
- 定向到错误页或告知资源没有了
- 排队或等待(比如秒杀、评论、下单)、
- 降级(返回默认数据或缓存数据)
Hystrix集成并实现服务熔断
一、Hystrix简介
Hystrix是一个用于微服务系统的延迟和容错库,旨在远程系统、服务和第三方库出现故障的时候,隔离服务之间的接口调用,防止级联故障导致服务雪崩。
- Hystrix github官网:https://github.com/Netflix/Hystrix
- Hystrix项目目前已经进入到维护阶段,不再开发新版本。即便如此,Hystrix的很多概念和设计思想都非常有价值,仍然值得学习
- Hystrix进入维护阶段之后,Netflix的建议是使用resilience4j,但是目前国内使用者比较少。更多的还是使用了 Spring Cloud Alibaba的sentinel。(后面章节为大家介绍)
- 无论是setinel还是hystrix都借鉴了hystrix的设计,所以学习hystrix还是非常有必要的
笔者强烈建议:Spring Cloud微服务系统使用sentinel代替hystrix。除非你的既有项目代码改造难度比较大,新项目一定要用Sentinel。
二、微服务集成Hystrix
在aservice-rbac和aservice-sms微服务项目中通过maven坐标引入hystrix。在旧的版本中引入hystrix使用spring-cloud-starter-hystrix,但在笔者使用的Spring Cloud Hoxton.SR3版本中要使用spring-cloud-starter-netflix-hystrix。
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-hystrix</artifactId>
<!--artifactId>spring-cloud-starter-hystrix 新版不要用这个</artifactId-->
</dependency>
在Spring Cloud项目最开始的时候几乎所有组件都是netflix公司贡献的,随着netflix公司对spring cloud社区的支持减弱,更多的厂商加入spring cloud开源社区。Spring Cloud社区开始通过maven坐标区别类库,如:
spring-cloud-starter-alibaba-*、spring-cloud-starter-netflix-*
- yml配置文件(本地application.yml或config git仓库中的yml配置文件)和之前的章节不需要有任何变化,但配置文件中要包含最基本的spring boot启动信息和eureka注册信息。
- 在服务入口启动类上面加上
@EnableCircuitBreaker注解

三、服务熔断注解实现方式(方法级别)
我们仍然以SystemService的密码重置接口为例,讲解服务熔断配置的代码实现方法。通过在方法上加上HystrixCommand注解和HystrixProperty注解来实现某个方法的服务熔断配置。
@PostMapping(value = "/pwd/reset")
@HystrixCommand(
commandProperties =
@HystrixProperty(name = "metrics.rollingStats.timeInMilliseconds", value = "10000") //统计窗口时间
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"), //启用熔断功能
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20"), //20个请求失败触发熔断
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "60"), //请求错误率超过60%触发熔断
@HystrixProperty(name = "circuitBreaker.sleepWindowInMilliseconds", value = "300000"),//熔断后开始尝试恢复的时间
)
public AjaxResponse pwdreset(@RequestParam Integer userId)
sysuserService.pwdreset(userId);
return AjaxResponse.success("重置密码成功!");
- 熔断开关:enabled=ture,打开断路器状态转换的功能。
- 熔断阈值配置
- requestVolumeThreshold=20,表示在Hystrix默认的时间窗口10秒钟之内有20个请求失败(没能正常返回结果),则触发熔断。断路器由“关闭状态”进入“开启状态”。
- errorThresholdPercentage=60,表示在Hystrix默认的时间窗口10秒钟之内有60%以上的请求失败(没能正常返回结果),则触发熔断。断路器由“关闭状态”进入“开启状态”。
- 熔断恢复时间:sleepWindowInMilliseconds=300000,表示断路器开启之后300秒钟进入半开启状态。(为了后面测试方便,我们把熔断恢复时间设置为5分钟)
通过上面的配置,我们就可以针对pwdreset实现服务熔断,下一节课我们将针对上面的配置信息进行测试。上面用到的配置项是我们在使用Hystrix进行服务熔断最常用的配置,如果你想了解更多的关于Hystrix的配置,请参考附录(其中一些关于服务降级的配置,我们后面章节还会讲)。
四、服务熔断全局配置
我们可以看到上面的使用注解针对方法进行服务熔断的配置,虽然可以实现功能,但是无疑增大了我们的代码量,而且非常冗余。为了解决这个问题,我们可以使用全局配置来实现:
hystrix:
command:
default:
circuitBreaker:
enabled: true
requestVolumeThreshold: 20
errorThresholdPercentage: 60
sleepWindowInMilliseconds: 300000
全局配置完成之后,想让哪一个方法实现断路器功能,就在哪一个方法上加上注解:
@HystrixCommand
比较好的实践方案是:针对系统内的绝大部分接口调用采用全局配置的方式,针对个别个性化重点业务接口使用注解配置。注解配置属性会覆盖全局配置属性,注解配置的优先级更高。
附录:HystrixCommand所有配置项
英文官方文档:https://github.com/Netflix/Hystrix/wiki/Configuration
Jemter模拟触发服务熔断
一、Jemter 简介
JMeter是开源软件Apache基金会下的一个性能测试工具,用来测试部署在服务器端的应用程序的性能。模拟用户并发请求的操作,我们为了更好的测试服务熔断,所以使用Jmeter。
https://jmeter.apache.org/download_jmeter.cgi

- 前提:需要在Jmeter所在主机上安装java8以上版本的JDK
- 下载后解压到你系统下的任意目录,然后运行其bin/jmeter.bat文件

二、JMeter并发配置
2.1.新建线程组(用户组)
右键“Test Plan”-Add,新建线程组。一个线程模拟一个用户,新建线程组就是新建一组用户。
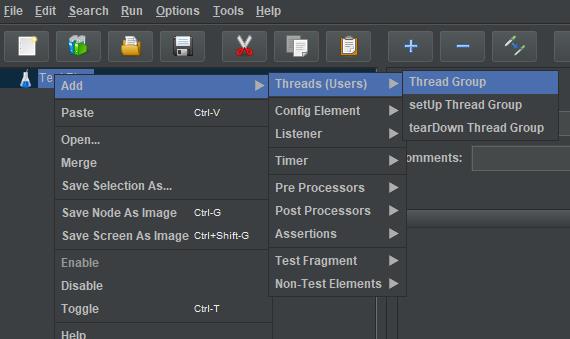
模拟时间窗口(Ramp-up period)10秒钟内,执行30次(users)请求,执行1轮(Loop Count)。该条件足以触发我们上一节定义的服务熔断标准。

2.2.添加测试样本(访问接口)


2.3.添加Results Tree(结果查看树)
Jmeter的每个请求的响应结果,可以在这里查看

2.3.启动测试的方法

三、服务熔断测试
“/sysuser/pwd/reset”接口测试此前已经多次讲过,这里就不过多介绍了。可以回看《第一个微服务调用》章节
参考下面这张图,理解测试过程。

- 第一步:首先我们把aservice-rbac和aservice-sms以及eureka、config、bus等项目需要的组件启动完成。然后使用postman向“/sysuser/pwd/reset”发送一个请求。请求结果正常,说明aservice-rbac正确的远程调用了aservice-sms。此时断路器处于关闭状态。
- 第二步:我们把aservice-sms服务停掉(模拟网络不可达或服务挂机)。然后使用postman向“/sysuser/pwd/reset”发送一个请求,结果如下(返回结果说明现在eureka服务上没有注册aservice-sms,本次请求出现错误)。此时断路器仍然处于关闭状态,只有一次请求错误还达不到熔断标准

- 第三步:我们仍然把aservice-sms服务停掉。Jemeter向aservice-rbac发送并发请求,使用上面的配置的10秒钟发送30次请求。Jemeter并发请求完成之后,我们再使用postman向“/sysuser/pwd/reset”发送一个请求,结果如下(说明此时服务熔断已经被触发)。此时断路器处于开启状态,因为10秒钟得到了30次错误的请求响应结果,达到熔断标准
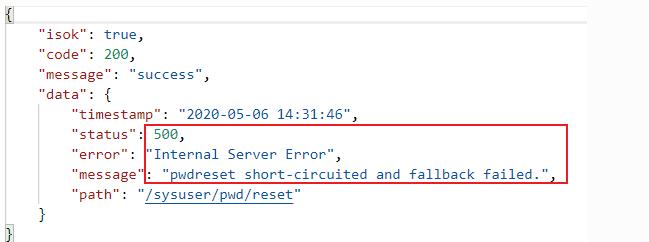
- 第四步:此时我们把aservice-sms服务启动恢复,再次使用postman向“/sysuser/pwd/reset”发送一个请求,结果如下:此时断路器处于开启状态,度过熔断恢复时间之后即将进入半开启状态。即使我们的aservice-sms服务恢复了,但断路器状态仍在熔断周期内,我们上一节设置的时间是5分钟:
- 第五步: 5分钟以后(熔断恢复时间),我们再次使用postman向“/sysuser/pwd/reset”发送一个请求,结果如下:(说明熔断恢复时间已经到达,断路器已经处于关闭状态,又可以正常提供服务)
Hystrix服务降级fallback
通过前面章节的讲解,我们都知道当服务熔断被触发之后,我们再次访问会返回如下结果:
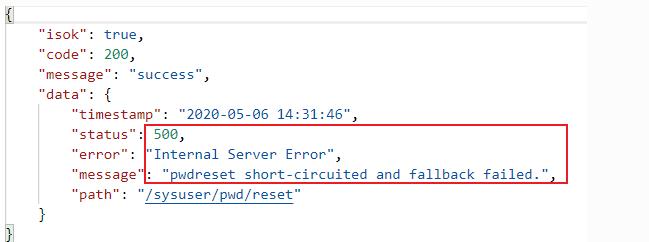
这样的响应结果,提供给用户显然是不够友好的。上面的提示信息有两层含义:
- 服务熔断被触发,也就是断路器处于开启状态
- 断路器被触发之后,访问fallback方法,但是这个fallback方法我们之前没有定义
当服务提供者故障触发熔断机制,此时你需要预先提供一个处理方法,作为降级后的执行方法一般叫fallback,fallback方法返回值一般是设置的默认值或者来自缓存,或者是一些友好提示信息。
一、服务降级发生的条件?
满足下列条件任何一个异常条件,都会产生服务降级
- 被访问的服务接口达到熔断标准(SHORT_CIRCUITED)
- 被访问的服务接口代码抛出异常(FAILURE)
- 被访问的服务接口响应超时(TimeOut)
- hystrix线程池或信号量爆满(THREAD_POOL_REJECTED 或SEMAPHORE_REJECTED )
| Failure Type | Exception class | Exception.cause | subject to fallback |
|---|---|---|---|
| FAILURE | HystrixRuntimeException | underlying exception (user-controlled) | YES |
| TIMEOUT | HystrixRuntimeException | j.u.c.TimeoutException | YES |
| SHORT_CIRCUITED | HystrixRuntimeException | j.l.RuntimeException | YES |
| THREAD_POOL_REJECTED | HystrixRuntimeException | j.u.c.RejectedExecutionException | YES |
| SEMAPHORE_REJECTED | HystrixRuntimeException | j.l.RuntimeException | YES |
所以我们可以认为:服务降级实际上也是“异常处理”的一种方式,处理的是上面的5种异常。
二、在控制层实现服务降级(方法级别)
在上一节服务熔断的代码的基础上加上服务降级方法配置
-
在
@HystrixCommand注解加上属性fallbackMethod属性 -
当捕获到任何一种服务降级的异常类型的时候,表示原函数(pwdreset)已经无法正确响应结果,执行fallback函数(pwdresetFallback)。
-
增加fallbackMethod对应的函数,返回值要与原函数一致。
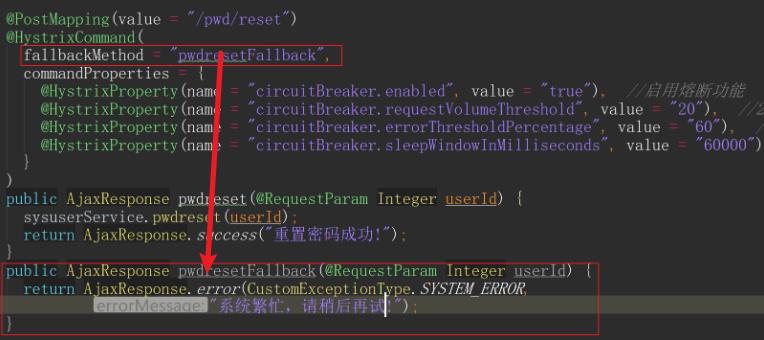
(重要) 为什么在控制层实现服务降级?
- 在实际的生产代码中,一种比较好的异常处理机制是:将服务层、持久层代码等所有底层代码抛出的异常转换为自定义异常不断的向上抛出,最后由控制层处理或者由Spring 全局异常处理。从而避免异常在底层被处理,上层无感应。可能造成一种现象:用户进行了一个操作,操作界面没有任何反应,但是后台服务报错了。
- 服务降级也是通过异常抛出及捕获实现的,所以一般不要在服务层和持久层等底层服务方法上进行hystrix配置。相当于把异常在底层处理了,造成上层无感应。
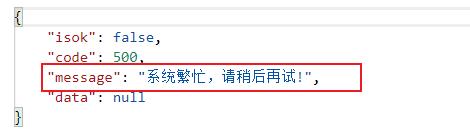
此时在服务熔断之后(或者其他的服务降级条件满足之后),我们再次访问“/sysuser/pwd/reset”接口。结果如下,说明执行了本地fallback方法。
三、Hystrix类级别的配置(笔者推荐)
第二小节中这种方法级别的服务降级配置方式的缺点十分的明显:那就是我们需要针对方法级别进行服务熔断和服务降级的配置;不只是配置,我们还需要针对每一个方法写fallback方法,无疑很大程度上增加了我们的代码量。那么有没有一种可以全局实现服务降级的配置方式呢?就是下面要为大家介绍的:
@DefaultProperties(defaultFallback = "commonFallbackMethod")
@DefaultProperties是一个类方法级别的注解- defaultFallback 可以指定该类中所有方法在发生服务降级的时候,执行的本地fallback函数。
- 需要我们在一个类中定义一个fallback函数,如:commonFallbackMethod
public AjaxResponse commonFallbackMethod()
return AjaxResponse.error(CustomExceptionType.SYSTEM_ERROR,
"系统繁忙,请稍后再试!");
最后在需要进行服务降级后执行fallback的方法的方法上面加上
@HystrixCommand
这样我们实现服务降级的代码就减少了很多,但是仍然存在一个问题让开发者不爽:我们需要在每一个类里面写一个commonFallbackMethod函数,为了降低fallback函数与实际Controller业务处理类的耦合,进一步减少代码的冗余,我们通常是可以定义一个BaseController,然后让其他的Controller类来继承。
public class BaseController
//通用hystrix回退方法
public AjaxResponse commonFallbackMethod()
return AjaxResponse.error(CustomExceptionType.SYSTEM_ERROR,
"系统繁忙,请稍后再试!");
补充: 如何在降级方法处接收到抛出的异常信息
@RestController
public class SmsController
@GetMapping(value = "/pwd/reset")
@HystrixCommand(fallbackMethod = "fallBack")
public AjaxResponse pwdreset(@RequestParam Integer userId)
int i=1/0;
return AjaxResponse.success("重置密码成功!");
public AjaxResponse fallBack(@RequestParam Integer userId,Throwable e)
System.out.println(e);
return AjaxResponse.error(CustomExceptionType.SYSTEM_ERROR, "用户ID为: "+userId+" 错误信息为: "+e.getMessage());
注意点一: fallback的方法参数和需要降级的方法必须一致,否则会因为方法参数不匹配报错
注意点二:如果想要接收异常,方法的最后一个参数作为异常参数接收处,并且必须使用Throwable来接收异常,否则会因为方法参数不匹配报错
hystrix源码解析——FallbackMethod是如何接收异常的
Hystrix结合Feign服务降级
通过前面几个小节的说明,对于服务降级目前有两种方式:
- 使用DefaultProperties注解在类级别的代码上进行服务降级,这种方法一定程度上减少了很多冗余代码。但是通用fallback方法仍然与实际业务的处理方法耦合在一个类中,可以通过BaseController的方式解决。笔者较为推荐这种方式
- 使用HystrixCommand注解的CommandProperties配置,在方法级别实现服务降级。这种方法代码十分冗余,需要针对每一个方法做配置,写fallback。最好用于一些重点业务的个性化接口。
- 用一句话总结就是:追求统一处理、允许个性化实现
下面为大家介绍服务降级的另一类方法:在FeignClient上实现服务降级。为什么我称它是另一类方法,而不是另一种方法?因为FeignClient上实现服务降级与上面两种方法的思考的角度是不同的:
- FeignClient上实现服务降级,从服务调用者的角度考虑:如果服务提供者出现连接超时、服务宕机等问题,作为服务调用者我该如何快速的对服务提供者的接口进行降级,避免造成服务调用者自己的崩溃。
- HystrixCommand实现服务降级,从服务提供者角度考虑:如果有服务调用者调用我的服务,并且我自己的代码或者触发熔断降级规则后,我该如何快速的告知服务调用者,避免造成服务调用者崩溃。
一、在FeignClient上实现服务降级
- 首先还是要将Hystrix集成到Spring Cloud服务中,参考《Hystrix集成并实现服务熔断》得第三小节:微服务集成Hystrix
- 在服务配置文件中打开feign结合hystrix的开关
feign:
hystrix:
enabled: true
在FeignClient注解增加fallback处理实现类,如:SmsServiceFallback。
@FeignClient(name="ASERVICE-SMS",fallback = SmsServiceFallback.class)
public interface SmsService
@PostMapping(value = "/sms/send")
AjaxResponse send(@RequestParam("phoneNo") String phoneNo,
@RequestParam("content") String content);
书写SmsServiceFallback代码,该类要实现FeignClient注解的接口函数。当使用Feign客户端远程调用SmsService .send方法,如果远程服务不可达(网络不可达或宕机),就会执行SmsServiceFallback.send方法作为fallback。
@Component
public class SmsServiceFallback implements SmsService
@Override
public AjaxResponse send(String phoneNo, String content)
return AjaxResponse.error(CustomExceptionType.SYSTEM_ERROR
,"短信发送接口失败!");
- 优点:将fallback服务降级方法与实际的业务处理方法分离,耦合度降低,从这个角度来说对程序员比较友好。
- 缺点:FeignClient注解的接口有多个方法,实现类就要写多个fallback,所以代码冗余量仍然非常大。这个缺点在我看来似乎无关紧要了,因为接口函数定义实际根本就不用我们写,通过IDE一个回车就可以搞定。接口函数的实现内容通过提取公共代码方式就可以搞定。虽然代码行数可能仍然较多,但是独立整齐规范。
远程服务调用异常传递的问题
一、远程服务之间异常该如何传递?
- 如果是单体应用,控制层调用服务层代码,服务层调用持久层代码。异常在下层拦截转换成自定义异常向上层抛出,从而实现异常的传递。控制层或全局配置统一异常处理,将异常转换为前端用户可以理解的信息。
- 微服务应用之间的调用是使用HTTP协议来互相访问的,那么该如何有效的传递异常信息的渠道呢?
- 渠道一:HTTP的状态码,如:200表示请求成功,400表示非系统异常(用户输入参数等),500表示系统内部异常等等。
- 渠道二:HTTP的Response Body,在Response Body中包含异常信息。
二、远程服务异常传递的问题演示
为了让为大家更直观的感受,我们来做一个实验,感受一下远程服务异常传递问题。

- 调整服务提供者aservice-sms的代码,加入服务降级的功能。我们人为制造一个一个程序异常:被除数为0。所以产生服务降级,会执行commonFallbackMethod方法。
public AjaxResponse commonFallbackMethod()
return AjaxResponse.error(CustomExceptionType.SYSTEM_ERROR,
"系统繁忙,请稍后再试!");
代码中的error方法实际上做了几件事情:
- 设置 AjaxResponse.isOk = false
- 设置 AjaxResponse.code = 500 (基于CustomExceptionType.SYSTEM_ERROR。我自定义的异常分类)
- 设置 AjaxResponse.message = “系统繁忙,请稍后再试!”

- 在服务调用者aservice-rbac我们把smsService(FeignClient)远程服务调用的结果AjaxResponse打印出来
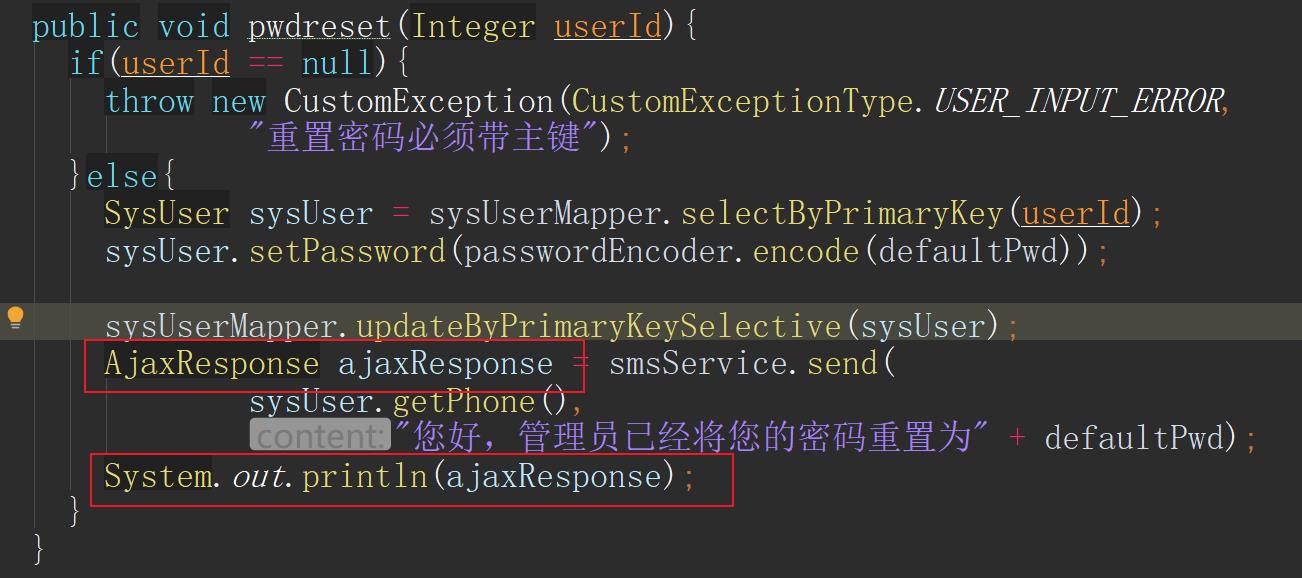
- 然后访问aservice-rbac的“/sysuser/pwd/reset”服务,结果如下:
- 密码修改成功了,即:数据库操作成功了。即:
sysUserMapper.updateByPrimaryKeySelective操作成功。

- 但是远程服务短信发送失败了(因为我们在aservice-sms被调用接口中定义了程序异常:被除数为0,并且执行fallback函数)。服务提供者aservice-sms的fallback返回的数据如下:

- 密码修改成功了,即:数据库操作成功了。即:
这显然不是我们希望看到的结果。如果只是发短信失败还不是非常要紧,如果是购物网站,订单服务成功了,账务服务失败了,这个影响就大了!我们期望看到的结果是:要么都成功,要么都失败!
三、重点理解一下服务提供者的响应数据
问自己几个问题:
- 这个数据是运行时异常么?不是,它只是数据,起不到数据库事务回滚回滚的作用。我们要非常明确的一点是:只有运行时异常才会导致数据库事务回滚,业务异常数据是不会导致数据库事务回滚的。
- 这个数据中的code:500是Http状态码么?也不是,500代表的是远程系统服务运行出现异常,是我自己定义的。当然你可以认为2或者3表示远程服务运行异常,但这样不好,谁能记住呢?(我自定义的AjaxResponse的code字段的含义与HTTP状态码含义一致,好记!)
- 这条数据响应的实际HTTP状态码是什么?是200-299其中的一个,因为我们成功的接收到了远程服务fallback函数响应的数据。成功的HTTP请求状态码都是200-299。
所以远程服务降级之后返回的结果是:
- HTTP协议的正常响应结果(200-299,HTTP协议规范)
- 业务上的异常数据(AjaxResponse.code = 500,我自己根据HTTP协议规范定义的业务结果状态码)
也就是说,我们介绍了服务异常传递的两个渠道:一是HTTP状态码,二是HTTP的Response Body。目前我们只能使用第二种渠道传递异常!
四、使用HTTP的Response Body传递异常(最简单的方式)
所以针对以上的异常传递不到位导致的问题,最简单的处理方式就是:我们在接收到远程服务的响应结果Response Body(对于我们的项目是AjaxResponse)后,判断其内部的状态信息。如果状态信息是业务失败,throw new 自定义异常抛出,触发数据库回滚!
- AjaxResponse.isOk = false
- AjaxResponse.code = 500
- AjaxResponse.message = “系统繁忙,请稍后再试!”

五、使用HTTP状态码传递异常(优化方式,符合RESTful风格)
目前很多应用都采用RESTful风格的接口,特点就是
- 看HTTP方法就知道动作,如:GET表示查询、POST表示修改、DELETE表示删除
- 看URL就知道操作的资源。比如:用GET请求/dogs资源,是查询所有的狗狗数据。
- 看HTTP返回的状态码,就知道动作的结果。如:200表示成功、400表示一些输入参数错误等、500表示系统内部错误。如果严格遵照这一项,我们有必要让HTTP响应结果的状态码与业务的运行结果AjaxResponse的code统一!
方法就是实现ResponseBodyAdvice接口:对项目的所有的Controller的JSON类型数据响应结果进行二次封装,然后再返回给服务调用端端。
- 统一数据响应格式为AjaxResponse(可以自定义)。
- 指定HTTP协议状态码status code = 业务运行结果AjaxResponse.code,前提是自定义的AjaxResponse的code字段的含义与HTTP状态码含义一致。
response.setStatusCode(HttpStatus.valueOf(
((AjaxResponse) body).getCode())
);
有了这样一层封装,服务调用端就能根据HTTP状态码判断服务提供者的响应数据是否异常。完整实现如下:
@Component
@ControllerAdvice
public class GlobalResponseAdvice implements ResponseBodyAdvice
@Override
public boolean supports(MethodParameter returnType, Class converterType)
//return returnType.hasMethodAnnotation(ResponseBody.class);
return true;
@Override
public Object beforeBodyWrite(Object body,
MethodParameter returnType,
MediaType selectedContentType,
Class selectedConverterType,
ServerHttpRequest request,
ServerHttpResponse response)
//对于JSON类型的响应数据
if(selectedContentType.equalsTypeAndSubtype(
MediaType.APPLICATION_JSON))
if(body instanceof AjaxResponse)
//如果Controller返回值body的数据类型是AjaxResponse(body instanceof AjaxResponse)
//就将body直接返回
response.setStatusCode(HttpStatus.valueOf(
((AjaxResponse) body).getCode()) //将业务异常状态码赋值给HTTP状态码
);
return body;
else
//如果Controller返回值body的数据类型不是AjaxResponse,
//就将body封装为AjaxResponse类型返回,总之要统一数据响应的类型
AjaxResponse ajaxResponse = AjaxResponse.success(body);
response.setStatusCode(HttpStatus.valueOf(
ajaxResponse.getCode()) //将业务异常状态码赋值给HTTP状态码
);
return AjaxResponse.success(body);
return body;
全局返回值处理,再实际开发过程中,和swagger,knifej等框架使用时,会存在不兼容的问题,需要手动处理进行兼容或者不使用全局返回值处理,而使用@ResponseStatus注解加在方法上,决定当前方法的响应的状态码
以上是关于重学SpringCloud系列七之服务熔断降级hystrix的主要内容,如果未能解决你的问题,请参考以下文章
SpringCloud系列七:Hystrix 熔断机制(Hystrix基本配置服务降级HystrixDashboard服务监控Turbine聚合监控)
4.SpringCloud -- 服务降级熔断 HystrixSentinel