Elasticsearch 磁盘使用率超过警戒水位线,怎么办?
Posted 铭毅天下
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 磁盘使用率超过警戒水位线,怎么办?相关的知识,希望对你有一定的参考价值。
1、引言
本系列文章介绍如何修复 Elasticsearch 集群的常见错误和问题。
这是系列文章的第一篇,主要探讨:Elasticsearch 磁盘使用率超过警戒水位线,怎么办?
2、从磁盘常见错误说开去
当客户端向 Elasticsearch 写入文档时候报错:
cluster_block_exception [FORBIDDEN/12/index read-only / allow delete (api)];在 elasticsearch 的日志文件中报错如下:
flood stage disk watermark [95%] exceeded ... all indices on this node will marked read-only出现如上问题多半是:磁盘使用量超过警戒水位线,索引存在 read-only-allow-delete 索引块数据。
3、报错释义
基础认知:磁盘三个警戒水位线:
推荐阅读:你不得不关注的 Elasticsearch Top X 关键指标。
| 属性名 | 属性值 | 含义 |
|---|---|---|
| cluster.routing.allocation.disk.watermark.low | 85% | 低警戒水位线 |
| cluster.routing.allocation.disk.watermark.high | 90% | 高警戒水位线 |
| cluster.routing.allocation.disk.watermark.flood_stage | 95% | 洪泛警戒水位线 |
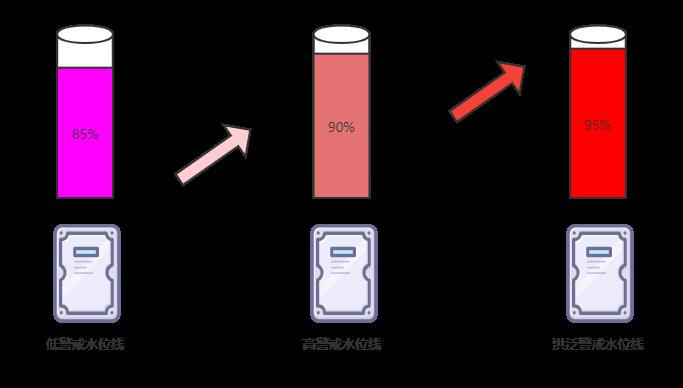
文章第 2 小节的报错表明数据节点的磁盘空间严重不足,并且已达到磁盘洪泛警戒水位线(磁盘使用率95%+,洪水泛滥的意思)。
为防止磁盘变满,当节点达到洪泛警戒水位线时,Elasticsearch 会阻止向该节点的任何索引分片写入数据,后面还会具体介绍如何阻止。
如果该数据块影响到相关的系统索引,可能会导致 Kibana 或者其他 Elastic Stack 功能不可用。
4、修复指南
4.1 cat shards 验证分片分配
要验证分片是否正在移出受影响的节点,请使用 cat shards API。
GET _cat/shards?v=true4.2 explain 验证分配细节
如果分片仍然保留在节点上,请使用集群 allocation/explain API 获取其分配状态的说明。
GET _cluster/allocation/explain
"index": "my-index",
"shard": 0,
"primary": false,
"current_node": "my-node"
如上 API几个参数解释如下:
index: 对应索引。
shard:分片号。
primary:是否主分片。
current_node: 节点名称。
四个参数需要结合业务实际进行修改。
4.3 恢复写入,可以上调磁盘警戒水位线。
要立即恢复写入操作,你可以暂时上调磁盘警戒水位并移除写入块。
如下命令行是集群层面更新设置的操作。
PUT _cluster/settings
"persistent":
"cluster.routing.allocation.disk.watermark.low": "90%",
"cluster.routing.allocation.disk.watermark.high": "95%",
"cluster.routing.allocation.disk.watermark.flood_stage": "97%"
索引块的五种不同状态如下:
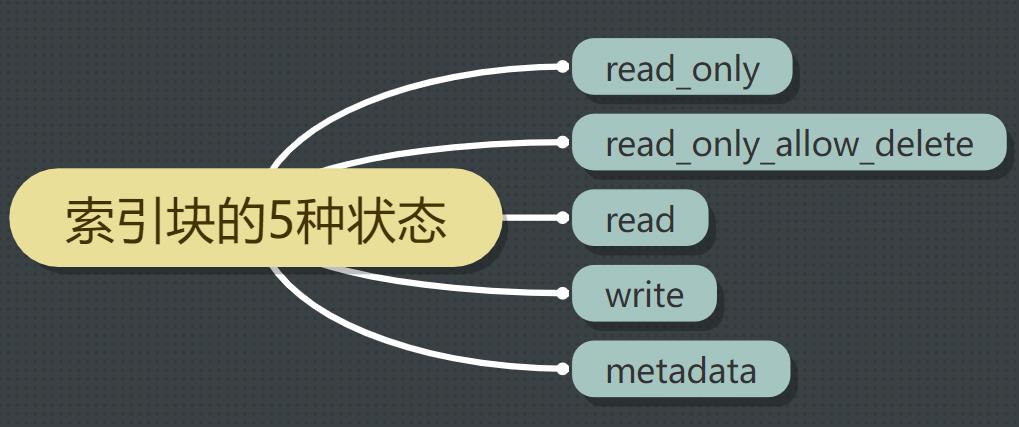
状态一:index.blocks.read_only
设置为 "true"可以使索引和索引元数据只读,"false "可以允许写入和元数据改变。
状态二:index.blocks.read_only_allow_delete
类似于index.blocks.read_only,但也允许删除索引释放磁盘资源。
基于磁盘的分片分配器(The disk-based shard allocator)可以自动添加和删除index.blocks.read_only属性的数据块。
这里依然会引申出删除索引文档和删除索引本身的区别等知识点:
(1)删除索引文档会出现删除后磁盘使用率反而增加的现象,因为删除的本质是 version 的 update;只有删除索引才相当于物理删除,会立即释放磁盘空间。
(2)当 index.blocks.read_only_allow_delete 被设置为true时,删除文档是不允许的,仅允许删除索引。
(3)当磁盘使用率达到洪泛警戒水位线 95% 时,Elasitcsearch 会强制所有包含分片数据的索引的数据库设置为:index.blocks.read_only_allow_delete 属性。
(4)当磁盘使用率低于高警戒水位线 90% 时,index.blocks.read_only_allow_delete 属性会自动释放。
状态三:index.blocks.read
设置为 "true",代表禁止对索引进行读操作。
状态四:index.blocks.write
设置为 "true "代表禁止对索引的数据写入操作。
与read_only不同,这个设置并不影响元数据。例如,你可以用一个 write 块关闭一个索引,但是你不能用一个 read_only 块关闭一个索引。
状态五:index.blocks.metadata
设置为 "true "代表禁用索引元数据的读写。
所以,如下的设置本质上是破除磁盘洪泛警戒水位线 95% 的 index.blocks.read_only_allow_delete 的限制,让索引继续可以写入数据。
个人评价:应急可以用。
PUT */_settings?expand_wildcards=all
"index.blocks.read_only_allow_delete": null
4.4 长期解决方案
作为长期解决方案,我们建议您将节点添加到受影响的数据层或升级现有节点实现节点磁盘扩容以增加磁盘空间。
比如:data_hot 热节点爆满,建议:
添加新的热节点
为已有热节点磁盘扩容。
要释放额外的磁盘空间,你可以使用删除索引 API 删除不需要的索引。
DELETE my-index4.5 重置磁盘警戒水位线操作
当长期解决方案到位时,可使用如下命令行重置磁盘警戒水位线。
PUT _cluster/settings
"persistent":
"cluster.routing.allocation.disk.watermark.low": null,
"cluster.routing.allocation.disk.watermark.high": null,
"cluster.routing.allocation.disk.watermark.flood_stage": null
5、小结
为避免磁盘使用率吃紧的问题,建议如下:
第一:“不等下雨天之前就修好屋顶”,而不是“下了雨之后应急修补屋顶”。
第二:做好磁盘使用率监控和预警操作。
第三:提前规划设置 total_shards_per_node 参数,以使得各个节点分片分配数相对均衡。
你在磁盘方面遇到哪些问题?如何解决的?欢迎留言反馈讨论。
和你一起,死磕 Elasticsearch!
参考
https://stackoverflow.com/questions/50609417/elasticsearch-error-cluster-block-exception-forbidden-12-index-read-only-all
https://www.elastic.co/guide/en/elasticsearch/reference/current/fix-common-cluster-issues.html
https://www.elastic.co/guide/en/elasticsearch/reference/7.16/index-modules-blocks.html
推荐
1、重磅 | 死磕 Elasticsearch 方法论认知清单(2021年国庆更新版)
2、Elasticsearch 7.X 进阶实战私训课(口碑不错)
更短时间更快习得更多干货!
已带领88位球友通过 Elastic 官方认证!

比同事抢先一步学习进阶干货!
以上是关于Elasticsearch 磁盘使用率超过警戒水位线,怎么办?的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch 出现 “429 rejected” 报错,怎么办?
Elasticsearch 集群状态变成黄色或者红色,怎么办?
Elasticsearch JVM 堆内存使用率飙升,怎么办?