文本分类Deep Pyramid Convolutional Neural Networks for Text Categorization
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本分类Deep Pyramid Convolutional Neural Networks for Text Categorization相关的知识,希望对你有一定的参考价值。
·阅读摘要:
本文提出了DPCNN(深度金字塔CNN)模型。在transformer、bert还没兴起的年代,模型越深效果越好,但是模型的复杂度会随着深度提升。粗略地说,DPCNN就是为了解决CNN模型越深复杂度越高的导致计算成本高这一问题的。
·参考文献:
[1] Deep Pyramid Convolutional Neural Networks for Text Categorization
[0] 摘要
论文提出了一种低复杂度单词级别的深度卷积神经网络(DPCNN),用于文本分类。
模型的复杂度会随着神经网络深度的深入而增加;在大数据集上,浅层的词级CNN比深层字级CNN更快更好。
DPCNN综合二者,在使用词级CNN的基础上,提出一种效果等同于深层神经网络的浅层神经网络。使得DPCNN有着深层CNN的效果,但是训练起来可以接受。
[1] 介绍
RNN、CNN都可以利用句子中的词序来训练模型。
【注一】:CNN利用词序,是本文作者发表的另一篇论文《Effective use of word order for text categorization with convolutional neural networks》
虽然CNN、RNN都能利用词序信息,但是CNN可以并行处理数据,这更吸引作者。
研究表明,深层字级cnn优于浅层字级cnn,浅层词级cnn优于深层字级cnn。词的向量表示效果显著。
【注二】:词的向量表示即以词为单位来做embedding层,虽然词的个数特别多,但是训练时使用的30K个常用词就占数据集总词量的98%
在这些基础上,论文提出一个 深但低复杂度 的网络结构,叫做DPCNN。它的总计算时间在常数范围内。
DPCNN架构简单地交替一个卷积块和一个池化层,池化层会导致内部数据大小以金字塔形状收缩。这个网络的计算复杂度被限制为不超过一个卷积块的两倍。,随着网络的深化,“金字塔”能够有效地发现文本中的长距离关联。
【注三】:论文使用步长为2的池化层,这样每经过一次池化层,数据就会缩减一半。
【注四】:大小为3、步长为2的池化层,是常用的设置,这里论文中说成“金字塔”形状,可见作者写故事的能力不赖呀 哈哈。(只是调侃)
[2] 模型
DPCNN模型有几个关键词:
1、the number of the feature maps fixed
2、shortcut connections with pre-activation
3、no need for dimension matching
4、text region embedding
DPCNN模型如下图,以上关键词在叙述模型中介绍。
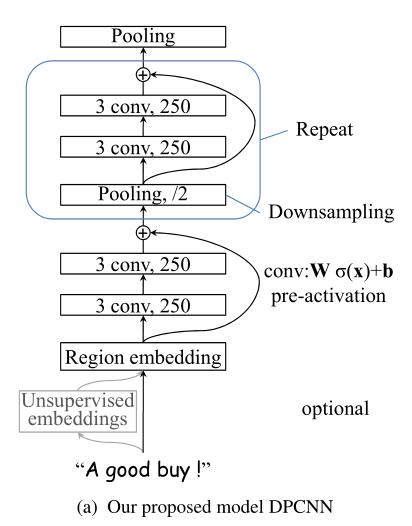
模型图从下往上看,一个文本有word embedding的表示,对应于图中的【Unsupervised embeddings】。
图中的【Region embedding】是对一个文本(比如3gram)进行一组卷积操作后生成的embedding。初始的embedding表示那里,论文采用了 “tv-embedding training”(还没有了解过),之后变成【Region embedding】就是对3元语法的一个卷积,把相邻的三个词的embedding卷积。
【注五】:今天看来这里可以直接使用预训练的词向量,特别是基于bert来微调
之后在模型主干上,经过两次卷积(会有padding操作)、激活(relu),然后使用shortcut connections把原先的
x
x
x与
f
(
x
)
f(x)
f(x)相加,作为下一层的输入。
此处,论文说的是shortcut connections with pre-activation,即预先激活的shortcut连接。就是说在模型主干的两个卷积层上先做激活(relu),然后直接加上
x
x
x,即
R
e
l
u
(
c
o
n
v
(
x
)
)
+
x
Relu(conv(x))+x
Relu(conv(x))+x;而不是在模型主干的两个卷积层上走完加上x后激活,即
R
e
l
u
(
c
o
n
v
(
x
)
+
x
)
Relu(conv(x)+x)
Relu(conv(x)+x)。
【注六】:这他喵的不就是resNet的残差链接吗?非要说成shortcut connections with pre-activation。。。。
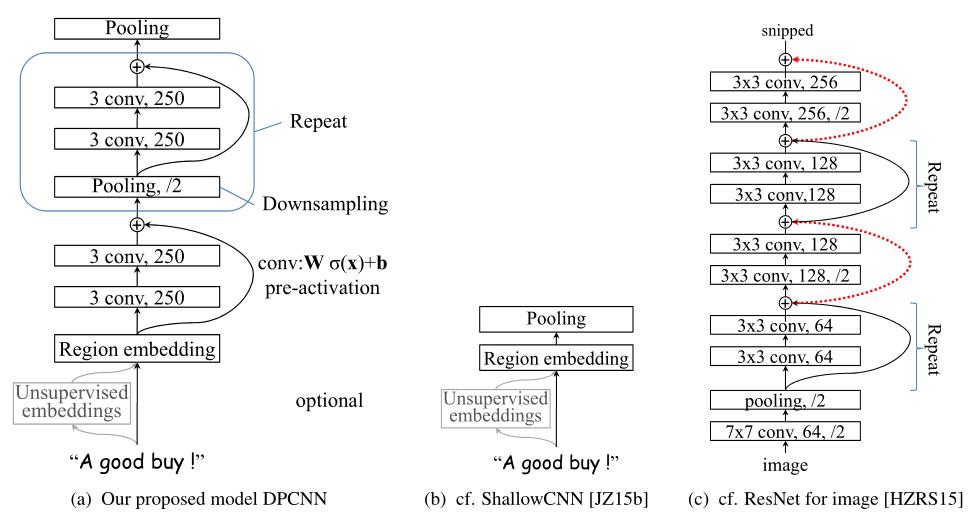
然后会进入一个循环的“池化-卷积块”。这里论文提到,feature map(可以认为是filter)的数量是固定的,这有利于做“池化-卷积块”内部的shortcut connections,也有利于模型加深而不提高复杂度。参考论文给的图c(下图右边),可以看到,模型加深往往伴随feature map数量的增多,而本篇论文中固定了feature map数量。
假设一次训练,数据走到【Repeat】部分前,batch=128,len=32,filter=250。
第一次循环:经过Pooling(size为3、步长为2,导致数据缩减一半),那么len=len/2=16,得到
x
x
x[128,16,250]。主干部分经过2个卷积(还有padding)变成
p
x
px
px[128,16,250],但是它的形状没有变。最后
x
=
p
x
+
x
x=px+x
x=px+x为[128,16,250],直接相加形状也没变。
第二次循环:同理,变为[128,8,250]。
第三次循环:同理,变为[128,4,250]。
第四次循环:同理,变为[128,2,250]。
第五次循环:同理,变为[128,1,250]。此时不在循环,接个fc就可以分类输出了。
以上是关于文本分类Deep Pyramid Convolutional Neural Networks for Text Categorization的主要内容,如果未能解决你的问题,请参考以下文章