Elasticsearch:如何在 Elasticsearch 中轻松编写 Painless 脚本
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:如何在 Elasticsearch 中轻松编写 Painless 脚本相关的知识,希望对你有一定的参考价值。
你可以在我之前的文章 “Elastic:开发者上手指南” 的 “Painless 编程” 章节里找到许多介绍 Elasticsearch Painless 脚本编程的教程。在那些文章中,我大量地介绍了许多的使用案例。在今天的文章中,我更着重于介绍 Painless 这个脚本语言的语法。这个是在之前的文章中缺少的一部分。
随着 Elasticsearch 5.x 及以后版本的推出,我们获得了一种新的脚本语言 Painless。 Painless 是一种由 Elastic 开发和维护并针对 Elasticsearch 进行优化的脚本语言。 虽然它仍然是一种脚本语言,但其核心 Painless 被宣传为一种快速、安全、易于使用和安全的语言。
在本文中,我们将为你简要介绍 Painless,并向你展示如何在搜索和更新数据时使用该语言。
Painless 简介
Painless scripting 的目标是让用户轻松编写脚本,尤其是当你来自 Java 或 Groovy 环境时。 虽然你可能不熟悉 Elasticsearch 中的脚本,但让我们从基础开始。
变量及数据类型
可以使用原始、引用、字符串、void(不返回值)、数组和动态类型在 Painless 中声明变量。 Painless 支持以下原始类型:byte、short、char、int、long、float、double 和 boolean。 它们以类似于 Java 的方式声明,例如 int i = 0; double a; boolean g = true;。
Painless 中的引用类型也与 Java 类似,只是它们不支持访问修饰符,但支持类似 Java 的继承。 这些类型可以在初始化时使用 new 关键字进行分配,例如在将 a 声明为 ArrayList 或简单地将单个变量 b 声明为 null Map 时,例如:
ArrayList a = new ArrayList();
Map b;
Map g = [:];
List q = [1, 2, 3]; 在最新的 Kibana 中,它集成了一个叫做 Painless Lab 的环境来对我们的 Painless 脚本进行测试,比如:
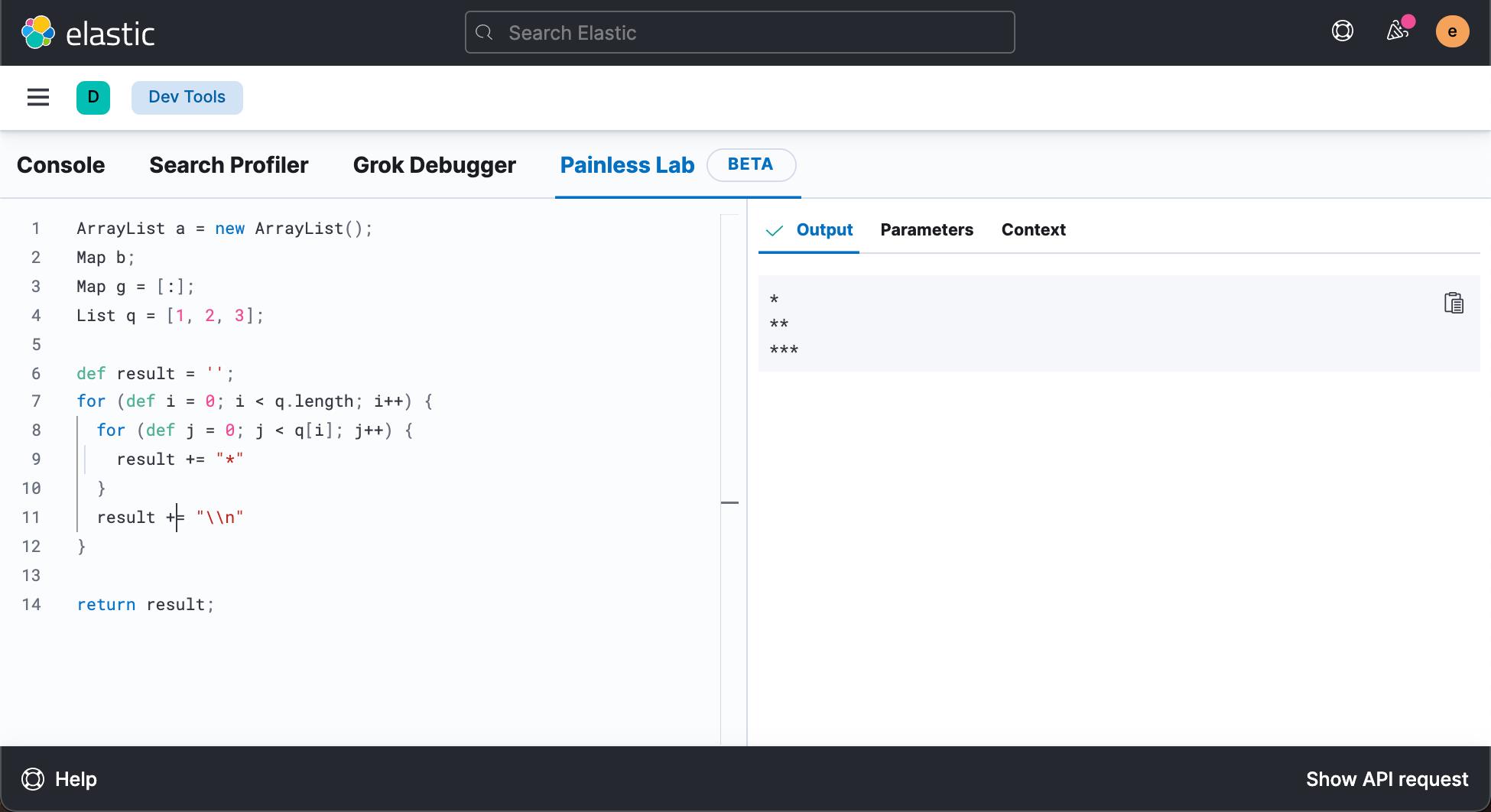
你可以参考我之前的文章 “Kibana:使用 Painless Lab 来测试代码”。
Lists 和 Maps 类似于数组(arrays),只是它们在初始化时不需要 new 关键字,但它们是引用类型,而不是数组。
字符串类型可以使用如下的方式来进行定义。 例如:
String a = "a";
String u;Painless 中的数组类型支持以 null 作为默认值的单维和多维数组。 与引用类型一样,数组是使用 new 关键字分配的,然后是类型和每个维度的一组括号。 可以像下面这样声明和初始化数组:
int[] x = new int[2];
x[0] = 3;
x[1] = 4; 数组的大小可以是明确的,例如 int[] a = new int[2] 或者你可以使用以下命令创建一个值为 1 到 5 且大小为 5 的数组:
int[] b = new int[] 1,2,3,4,5; 与 Java 和 Groovy 中的数组一样,数组数据类型在声明和初始化时必须有一个原始的数据类型(比如,byte,short 等)、字符串,甚至是动态的 def 数据类型定义。
def 是 Painless 支持的唯一动态类型。 它的作用是模仿它在运行时分配的任何类型的行为。 因此,在定义变量时:
def a = 1;
def b = "foo"; 在上面的代码中,Elasticsearch 将始终假定 a 是原始类型 int,值为 1,b 为字符串类型,值为 “foo”。 数组也可以用 def 分配,例如,注意以下几点:
def[][] h = new def[2][2];
def[] f = new def[] 4, "s", 5.7, 2.8C; 抛开变量,让我们看一下条件和运算符。
运算符及条件
如果你了解 Java、Groovy 或现代编程语言,那么 Painless 中的条件和使用运算符将会很熟悉。 Painless 文档包含与语言兼容的完整运算符列表,以及它们的优先顺序和关联性。 列表中的大多数运算符都与 Java 和 Groovy 语言兼容。 像大多数编程语言一样,运算符优先级可以用括号覆盖(例如 int t = 5+(5*5))。
在 Painless 中使用条件与在大多数编程语言中使用它们是相同的。 Painless 支持 if 和 else,但不支持 else if 或 switch。 对于大多数程序员来说,条件语句看起来很熟悉:
if (doc['foo'].value = 5)
doc['foo'].value *= 10;
else
doc['foo'].value += 10;
Painless 还有 Elvis 运算符 ?:,它的行为更像 Kotlin 中的运算符,而不是 Groovy。 基本上,如果我们有以下情况:
x ?: y 一个 Elvis 由两个表达式组成。 评估第一个表达式以检查是否为空值。 如果第一个表达式的计算结果为 null,则计算第二个表达式并使用其值。 如果第一个表达式的计算结果为非 null,则使用第一个表达式的结果值。 使用 elvis 运算符 '?:' 作为条件运算符的快捷方式。用例:
List x = new ArrayList();
List y = x ?: new ArrayList();
y = null;
List z = y ?: new ArrayList(); Methods
虽然 Java 语言是 Painless 获得大部分功能的地方,但并非 Java 标准库(Java 运行时环境,JRE)中的每个类或方法都可用。 Elasticsearch 有 Painless 可用的类和方法的白名单参考。 该列表不仅包括 JRE 提供的方法,还包括可用的 Elasticsearch 和 Painless 方法。
Painless Loops
Painless 支持 while、do...while、for 循环和控制流语句(如 break 和 continue),这些都在 Java 中可用。 Painless 中的 for 循环示例在大多数现代编程语言中看起来也很熟悉。 在下面的示例中,我们循环遍历包含文档 doc['scores'] 中分数的数组,并将它们添加到变量 total 中,然后返回它:
def total = 0;
for (def i = 0; i < doc['scores'].length; i++)
total += doc['scores'][i];
return total; 将该循环修改为以下内容也将起作用:
def total = 0;
for (def score : doc['scores'])
total += score;
return total; 现在我们已经了解了一些语言基础知识,让我们开始查看一些数据,看看我们如何将 Painless 与 Elasticsearch 查询结合使用。
装载数据
在将数据加载到 Elasticsearch 之前,请确保你设置了新的索引。 你需要在 Dev Tools 控制台、终端或使用你选择的编程语言中创建一个新索引。 我们将创建的索引称为 “sat”。 设置索引后,让我们收集数据。我们可以简单地在 Kibana Dev Tools 中打入:
PUT sat我们将使用的数据是加州教育部编制的 2015/16 年度学校平均 SAT 成绩列表。 加州教育部的数据来自 Microsoft Excel 文件。 我们将数据转换为 JSON,可以从这里的 Github 存储库下载。
git clone https://github.com/liu-xiao-guo/elasticsearch-painless下载 JSON 文件后,我们可以使用 Elasticsearch 的 Bulk API 将数据插入到我们创建的 “sat” 索引中。
curl -u username:password -s -H "Content-Type: application/x-ndjson" -XPOST localhost:9200/_bulk --data-binary @sat_scores.json 在上面,你需要根据自己集群的用户名及密码进行修改。等运行完上面的命令后,我们可以看到:
GET sat/_count我们可以发现有 2334 个文档:
"count" : 2334,
"_shards" :
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
每个文档的字段如下:
GET sat/_search?filter_path=**.hits
"hits" :
"hits" : [
"_index" : "sat",
"_type" : "_doc",
"_id" : "N0WXnn4Bcy_gZ0X44pp1",
"_score" : 1.0,
"_source" :
"cds" : 0,
"rtype" : "X",
"sname" : "",
"dname" : "",
"cname" : "",
"enroll12" : 492835,
"NumTstTakr" : 214262,
"AvgScrRead" : 484,
"AvgScrMath" : 494,
"AvgScrWrit" : 477,
"NumGE1500" : 89840,
"PctGE1500" : 41.93,
"year" : 1516
,
...使用 Painless 来搜索 Elasticsearch
现在我们已经将 SAT 分数加载到 “sat” 索引中,我们可以开始在 SAT 查询中使用 Painless。 在以下示例中,所有变量都将使用 def 来演示 Painless 的动态类型支持。
Elasticsearch 中的脚本格式类似于以下内容:
GET sat/_search?filter_path=**.hits
"script_fields":
"some_scores":
"script":
"lang": "painless",
"source": "def scores = 0; scores = doc['AvgScrRead'].value + doc['AvgScrWrit'].value; return scores;"
在脚本中,你可以定义脚本语言语言,其中 Painless 是默认语言。 另外,我们可以指定脚本的 source。 我们还可以选择使用存储,它们是存储在集群中的脚本。 此外,我们还有文件脚本,它们是存储在文件中并在 Elasticsearch 的配置目录中引用的脚本。
上面的脚本都写作一行,其实可读性不是很高。我们可以使用如下的格式:
GET sat/_search?filter_path=**.hits
"script_fields":
"some_scores":
"script":
"lang": "painless",
"source": """
def scores = 0;
scores = doc['AvgScrRead'].value + doc['AvgScrWrit'].value;
return scores;
"""
显然这种格式跟他容易让人读。
让我们更详细地看一下上面的脚本。
在上面的脚本中,我们使用了 _search API 和 script_fields 命令。 此命令将允许我们创建一个新字段,该字段将保存我们在脚本中编写的分数。 在这里,我们将其称为 some_scores 只是作为示例。
def scores = 0;
scores = doc['AvgScrRead'].value + doc['AvgScrWrit'].value;
return scores; 让我们看看结果:
"hits" :
"hits" : [
"_index" : "sat",
"_type" : "_doc",
"_id" : "N0WXnn4Bcy_gZ0X44pp1",
"_score" : 1.0,
"fields" :
"some_scores" : [
961
]
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "OEWXnn4Bcy_gZ0X44pp1",
"_score" : 1.0,
"fields" :
"some_scores" : [
1032
]
,
...该脚本在索引中的每个文档上运行。 上面的结果表明,已经创建了一个名为 fields 的新字段,其中另一个字段包含我们使用 script_fields 命令创建的新字段 some_scores 的名称。
让我们编写另一个查询来搜索 SAT 阅读分数低于 350 且数学分数高于 350 的学校。脚本如下所示:
doc['AvgScrRead'].value < 350 && doc['AvgScrMath'].value > 350和查询:
GET sat/_search?filter_path=**.hits
"query":
"script":
"script":
"lang": "painless",
"source": """
doc['AvgScrRead'].value < 350 && doc['AvgScrMath'].value > 350
"""
上面执行的结果为:
"hits" :
"hits" : [
"_index" : "sat",
"_type" : "_doc",
"_id" : "70WXnn4Bcy_gZ0X44pp2",
"_score" : 1.0,
"_source" :
"cds" : 7617960733659,
"rtype" : "S",
"sname" : "John F. Kennedy High",
"dname" : "West Contra Costa Unified",
"cname" : "Contra Costa",
"enroll12" : 175,
"NumTstTakr" : 128,
"AvgScrRead" : 349,
"AvgScrMath" : 352,
"AvgScrWrit" : 345,
"NumGE1500" : 5,
"PctGE1500" : 3.91,
"year" : 1516
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "90WXnn4Bcy_gZ0X44px3",
"_score" : 1.0,
"_source" :
"cds" : 19647330126508,
"rtype" : "S",
"sname" : "Augustus F. Hawkins High C Responsible Indigenous",
"dname" : "Los Angeles Unified",
"cname" : "Los Angeles",
"enroll12" : 108,
"NumTstTakr" : 66,
"AvgScrRead" : 349,
"AvgScrMath" : 353,
"AvgScrWrit" : 338,
"NumGE1500" : 1,
"PctGE1500" : 1.52,
"year" : 1516
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "DEWXnn4Bcy_gZ0X44qF4",
"_score" : 1.0,
"_source" :
"cds" : 38684780119875,
"rtype" : "S",
"sname" : "S.F. International High",
"dname" : "San Francisco Unified",
"cname" : "San Francisco",
"enroll12" : 73,
"NumTstTakr" : 56,
"AvgScrRead" : 326,
"AvgScrMath" : 368,
"AvgScrWrit" : 311,
"NumGE1500" : 3,
"PctGE1500" : 5.36,
"year" : 1516
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "FkWXnn4Bcy_gZ0X44qF4",
"_score" : 1.0,
"_source" :
"cds" : 38684783830403,
"rtype" : "S",
"sname" : "Marshall (Thurgood) High",
"dname" : "San Francisco Unified",
"cname" : "San Francisco",
"enroll12" : 139,
"NumTstTakr" : 66,
"AvgScrRead" : 347,
"AvgScrMath" : 447,
"AvgScrWrit" : 350,
"NumGE1500" : 3,
"PctGE1500" : 4.55,
"year" : 1516
]
这将给我们四所学校。 在这四所学校中,我们可以使用 Painless 创建一个包含四个值的数组:来自我们数据的 SAT 分数和总 SAT 分数,或所有 SAT 分数的总和:
def sat_scores = [];
def score_names = ['AvgScrRead', 'AvgScrWrit', 'AvgScrMath'];
for (int i = 0; i < score_names.length; i++)
sat_scores.add(doc[score_names[i]].value)
def temp = 0;
for (def score : sat_scores)
temp += score;
sat_scores.add(temp);
return sat_scores; 我们将创建一个 sat_scores 数组来保存 SAT 分数(AvgScrRead、AvgScrWrit 和 AvgScrMath)以及我们将计算的总分。 我们将创建另一个名为 scores_names 的数组来保存包含 SAT 分数的文档字段的名称。 如果将来我们的字段名称发生变化,我们所要做的就是更新数组中的名称。 使用 for 循环,我们将使用 score_names 数组遍历文档字段,并将它们对应的值放入 sat_scores 数组。 接下来,我们将遍历 sat_scores 数组并将三个 SAT 分数的值相加,并将该分数放在临时变量 temp 中。 然后,我们将 temp 值添加到 sat_scores 数组中,得到三个单独的 SAT 分数加上他们的总分。
获取四所学校和脚本的整个查询如下所示:
GET sat/_search?filter_path=**.hits
"query":
"script":
"script":
"lang": "painless",
"source": """
doc['AvgScrRead'].value < 350 && doc['AvgScrMath'].value > 350
"""
,
"script_fields":
"scores":
"script":
"lang": "painless",
"source": """
def sat_scores = [];
def scores = ['AvgScrRead', 'AvgScrWrit', 'AvgScrMath'];
for (int i = 0; i < scores.length; i++)
sat_scores.add(doc[scores[i]].value)
def temp = 0;
for (def score : sat_scores)
temp += score;
sat_scores.add(temp);
return sat_scores;
"""
查询返回的每个文档将类似于:
"hits" :
"hits" : [
"_index" : "sat",
"_type" : "_doc",
"_id" : "70WXnn4Bcy_gZ0X44pp2",
"_score" : 1.0,
"fields" :
"scores" : [
349,
345,
352,
1046
]
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "90WXnn4Bcy_gZ0X44px3",
"_score" : 1.0,
"fields" :
"scores" : [
349,
338,
353,
1040
]
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "DEWXnn4Bcy_gZ0X44qF4",
"_score" : 1.0,
"fields" :
"scores" : [
326,
311,
368,
1005
]
,
"_index" : "sat",
"_type" : "_doc",
"_id" : "FkWXnn4Bcy_gZ0X44qF4",
"_score" : 1.0,
"fields" :
"scores" : [
347,
350,
447,
1144
]
]
使用 _search API 的一个缺点是不存储结果。 为此,我们必须使用 _update 或 _update_by_query API 来更新单个文档或索引中的所有文档。 所以,让我们用刚刚使用的查询结果更新我们的索引。
使用 Painless 来更新 Elasticsearch 文档
在我们进一步之前,让我们在数据中创建另一个字段,该字段将保存 SAT 分数的数组。 为此,我们将使用 Elasticsearch 的 _update_by_query API 添加一个名为 All_Scores 的新字段,该字段最初将作为一个空数组开始:
POST sat/_update_by_query
"script":
"lang": "painless",
"source": "ctx._source.All_Scores = []"
这将更新索引以包含我们可以开始添加分数的新字段。 为此,我们将使用脚本来更新 All_Scores 字段:
def scores = ['AvgScrRead', 'AvgScrWrit', 'AvgScrMath'];
for (int i = 0; i < scores.length; i++)
ctx._source.All_Scores.add(ctx._source[scores[i]]);
def temp = 0;
for (def score : ctx._source.All_Scores)
temp += score;
ctx._source.All_Scores.add(temp); 请注意在这个时候,我们需要使用 ctx 来访问字段,而不是像之前的 doc。这里涉及到 Painless 的上下文。具体是使用哪种格式,请参阅官方文档 “Painless contexts”。
使用 _update 或 _update_by_query API,我们将无法访问 doc 值。 相反,Elasticsearch 公开了 ctx 变量和 _source 文档,允许我们访问每个文档的字段。 从那里我们可以使用每个 SAT 分数和学校的总平均 SAT 分数更新每个文档的 All_Scores 数组。
整个查询如下所示:
POST sat/_update_by_query
"script":
"lang": "painless",
"source": """
def scores = ['AvgScrRead', 'AvgScrWrit', 'AvgScrMath'];
for (int i = 0; i < scores.length; i++)
ctx._source.All_Scores.add(ctx._source[scores[i]])
def temp = 0;
for (def score : ctx._source.All_Scores)
temp += score;
ctx._source.All_Scores.add(temp);
"""
经过上面的 update 后的文档现在变成了:
GET sat/_search?filter_path=**.hits
"hits" :
"hits" : [
"_index" : "sat",
"_type" : "_doc",
"_id" : "N0WXnn4Bcy_gZ0X44pp1",
"_score" : 1.0,
"_source" :
"All_Scores" : [
484,
477,
494,
1455
],
"year" : 1516,
"cname" : "",
"AvgScrRead" : 484,
"rtype" : "X",
"AvgScrMath" : 494,
"cds" : 0,
"sname" : "",
"PctGE1500" : 41.93,
"AvgScrWrit" : 477,
"NumTstTakr" : 214262,
"dname" : "",
"enroll12" : 492835,
"NumGE1500" : 89840
,
...如果我们只想更新一个文档,我们也可以使用类似的脚本来完成。 我们只需要在 POST URL 中指明文档的 _id。 在接下来的更新中,我们只是将 id 为 “AV2mluV4aqbKx_m2Ul0m” 的文档的 AvgScrMath 分数加了 10 分。
POST sat/scores/AV2mluV4aqbKx_m2Ul0m/_update
"script":
"lang": "painless",
"source": "ctx._source.AvgScrMath += 10"
总结
我们已经了解了 Elasticsearch 的 Painless 脚本语言的基础知识,并给出了一些关于它如何工作的示例。 此外,使用一些 Painless API 方法(如 HashMap 和循环),我们让你体验了在更新文档时可以使用该语言做什么,或者只是在返回搜索结果之前修改数据。 尽管如此,这只是 Painless 的冰山一角。
以上是关于Elasticsearch:如何在 Elasticsearch 中轻松编写 Painless 脚本的主要内容,如果未能解决你的问题,请参考以下文章
Observability:如何在使用 Elastic Agents 把多行的日志摄入到 Elasticsearch 中
Elasticsearch:如何分析和优化 Elastic 部署的存储空间
Elasticsearch:如何在 Elastic 中实现图片相似度搜索