第九周.02.KAT
Posted oldmao_2000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了第九周.02.KAT相关的知识,希望对你有一定的参考价值。
文章目录
本文内容整理自深度之眼《GNN核心能力培养计划》
公式输入请参考: 在线Latex公式
论文: KGAT: Knowledge Graph Attention Network for Recommendation
将GNN(或者说KG)引入到推荐系统里面
具体可以关注中科院何向南教授工作组的论文
摘要
两段式的摘要比较少见,而且比较长。
第一段主要讲现有的推荐系统的目标more accurate, diverse, and explainable,实现这个目标需要额外的信息(side information),这是传统算法没法整的。
第二段是介绍原理以及相应结果。原来在协同过滤的算法中,假设所有的用户之间、item之间是没有联系的,实际上他们之间可以用KG来引入关系,使得他们之间可以有message的传递。
这里的KG之间的关系用的不是基础的GCN,而是带权重的GAT。
Introduction
讲了现有方法的不足
CF methods suffer from the inability of modeling side information [30, 31], such as item attributes, user profiles, and contexts, thus perform poorly in sparse situations where users and items have few interactions.
对于监督学习的方法:some representative models include factorization machine (FM) [23], NFM (neural FM) [11], Wide&Deep [7], and xDeepFM [18], etc.
Although these methods have provided strong performance, a deficiency is that they model each interaction as an independent data instance and do not consider their relations.
补充:工业界RS的发展
LR、XGBoost
FM、FFM(相当于在FM的基础上做了特征交叉)
Wide & Deep、DeepFM、DIN
对于RS中的某个模块:DSSM召回、ESSM多任务、MMOE
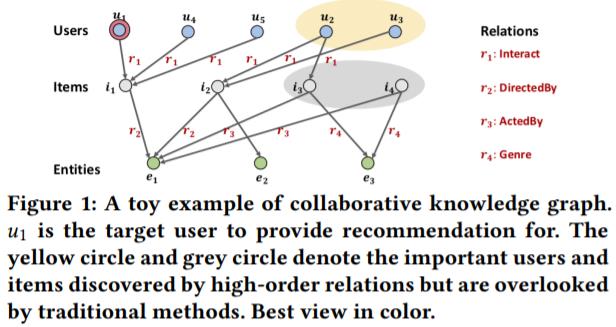
上图是这个文章的创新点。如果单独看Users和Items,那么就相当于协同过滤推荐,那么图中的
u
2
u_2
u2和
u
3
u_3
u3不会影响其他User,
i
3
i_3
i3和
i
4
i_4
i4不会影响其他Item,因为他们是没有交互关系的,通过加入KG的实体,实体与Item之间的关系看右边,那么原来没有关系的Users和Items就有了关系,从而实现了消息传递,学习到的表征更加精确。
当然这里的消息传递不可能通过一跳完成(First order),而是要多跳(high-order relations,这里不是该翻译多种关系?)
当然这样玩会带来两个缺点,当然也给出了解决方案:
- the nodes that have high-order relations with the target user increase dramatically with the order size, which imposes computational overload to the model
多跳意味每次参与计算的节点会指数级增长,需要使用sample技术来减少计算量(参考GraphSAGE) - the high-order relations contribute unequally to a prediction, which requires the model to carefully weight (or select) them
加入更多的关系当然要带权才能更加精准
对于Path-based methods(类似Metapath的方法),需要先用领域知识(缺点1)定义路径,然后在根据path进行训练,这样两步走的方法太不端到端(缺点2)了。
对于Regularization-based method(类似KTUP and CFKG,这两个方法没学过)也有缺点,貌似是直接把KG直接加到原来的图里面直接训练,缺点是:neither the long-range connectivities are guaranteed to be captured, nor the results of high-order modeling are interpretable
然后提出本文模型的优点(就是针对上面的缺点):efficient, explicit, and end-to-end - recursive embedding propagation
- attention-based aggregation
上面两个步骤是不是很熟悉,propagation + aggregation
TASK FORMULATION
User-Item Bipartite Graph
Knowledge Graph,直接参考Trans系列文章即可
合成上面二者得到:
Collaborative Knowledge Graph
METHODOLOGY
先是公式1,就是trasR的计算,分别将head和tail通过映射(
W
r
W_r
Wr)转到r的空间,然后做计算
g
(
h
,
r
,
t
)
=
∣
∣
W
r
e
h
+
r
−
W
r
e
t
∣
∣
2
2
g(h,r,t)=||W_re_h+r-W_re_t||_2^2
g(h,r,t)=∣∣Wreh+r−Wret∣∣22
如果是正样本那么分数越低反正越大
然后KG这块的loss就是取正样本和负样本的pairwise的loss,对应公式2
公式3则表示了聚合方式:
e
N
h
=
∑
(
h
,
r
,
t
)
∈
N
h
π
(
h
,
r
,
t
)
e
t
e_N_h=\\sum_(h,r,t)\\in N_h\\pi(h,r,t)e_t
eNh=(h,r,t)∈Nh∑π(h,r,t)et
就是将所有和当前节点有关系的邻居
(
h
,
r
,
t
)
∈
N
h
(h,r,t)\\in N_h
(h,r,t)∈Nh按照权重
π
\\pi
π进行加权求和
Knowledge-aware Attention就是权重计算是用的映射后点乘的结果(head和tail相似度大传递信息的权重越大),对应公式4。
公式5是softmax
公式678分别定义了不同的聚合方式,其中第三种是文章提出的,就是多加了elementwise的信息,这个做法是针对某些任务会有好的效果。
公式9是第
l
l
l层表征更新的公式
是节点u最后经过
l
l
l层的训练,每层都得到一个表征结果,第一层得到的是1跳邻居信息,第二层得到的除了1跳邻居之外还有2跳邻居信息,以此类推。公式11表示的是把所有
l
l
l层的表征结果concat起来得到最终结果
公式12表示两个节点的表征做相似性计算可以预测出用户是否购买该商品
公式13实际就是NGCF的loss
公式14是总体loss
以上是关于第九周.02.KAT的主要内容,如果未能解决你的问题,请参考以下文章