spark技术学习与思考(sparkcore&sparksql)
Posted jiujielun_cys
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark技术学习与思考(sparkcore&sparksql)相关的知识,希望对你有一定的参考价值。
目录
1.spark 基础
1.1 spark 发展历程
spark 是加州大学伯克利分校 AMP 实验室开发的基于内存的通用并行计算框架。
发展历程:
- 2009 年诞生于美国加州大学伯克利分校 AMP 实验室;
- 2010 年通过 BSD 许可协议开源发布;
- 2013 年 6 月进入 Apache 孵化器项目;
- 2014 年 2 月成为 Apache 的顶级项目(仅8个月时间);
- 2014 年 5 月 spark1.0.0 发布;
- 2016 年 7 月 spark2.0.0 发布;
- 2020 年 6 月 spark3.0.0 发布;
既然已经有了 mapreduce,为什么还会流行 spark?
1.2 spark 与 mapreduce 对比
Spark 产生之前,已经有 MapReduce 这类非常成熟的并行计算框架存在了,并提供了高层次的 API(map/reduce),它在集群上进行计算并提供容错能力,从而实现分布式计算。
所以为什么 spark 会流行呢?
- 原因 1:优秀的数据模型和丰富的算子
虽然 MapReduce 提供了对数据访问和计算的抽象,但是对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中(例如 HDFS),所以会产生数据的复制备份,磁盘的 I/O 以及数据的序列化,所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。而这类操作是非常常见的,例如迭代式计算,交互式数据挖掘,图计算等。
所以在认识到这个问题后,AMPLab 提出了一个新的模型,叫做 RDD(弹性分布式数据集)。RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单),它可以让用户显式的将中间结果数据集保存在内存中,并且通过控制数据集的分区来达到数据存放处理最优化。同时 RDD 也提供了丰富的算子 API (map、reduce、filter、foreach、redeceByKey…)来操作数据集。后来 RDD 被 AMPLab 放在一个叫做 Spark 的框架中并开源。
简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度。
- 原因2:fullstack-完善的生态圈
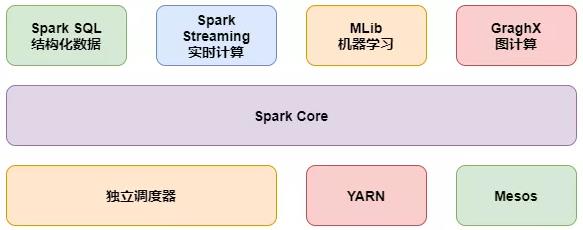
spark 目前主要由五个组件构成, sparkcore 提供内存计算,sparksql 提供即时查询,spark streaming 提供实时计算,mlib提供机器学习,graphx提供图处理,spark 其他四个组件都会依赖于核心项目 sparkcore 中的组件模块。
- 原因3:运行模式多样化
由上图可知,spark 可以运行在多个资源管理调度平台上,其中包括 spark standalone、spark on yarn、mesos、k8s等,下面将对其中几个运行模式进行说明
1.3 spark 运行模式
- 本地模式
spark 本地模式是在一台计算机上的运行模式,一般用于学习与测试,例如在idea中:
var conf=new SparkConf().setMaster("local[*]").setAppName("test1")
var sc:SparkContext=...
sc.操作
sc.stop()
其中设置本地模式有三种方式:
setMaster(“local”) 表示用单线程来运行
setMaster(“local[number]”) 表示用 number 个线程并行
setMaster(“local[*]”) 表示该计算机的 cpu 核数个线程并行
- spark on yarn
spark on yarn 模式是在 yarn 集群中运行,适用于生产环境,其中包含 cluster 与 client 两种模式
i. spark on yarn 的 cluster 模式,指的是 driver 程序运行在 yarn 集群上,当用户提交了作业后,可以关闭 client,作业会继续在 yarn 上运行。
ii. spark on yarn 的 client 模式,指的是 driver 程序运行在提交任务的客户端上,当用户提交了作业后会在 client 上生成 sparksubmit 进程,client 不能中途离开。
两种模式的本质区别是:driver 程序运行的位置
- k8s
k8s是 spark 上全新的集群管理和调度系统,spark2.3 后 spark 可以部署在 k8s 上
常用有两种方法可以将 spark 应用提交到 k8s 上:
i. 通过 spark 原生的 spark-submit 提交
ii. 通过谷歌提供的 spark-on-k8s operator 提交
两种模式区别是:spark-on-k8s operator 可以通过一系列的内置工具获取很多作业相关的信息,而spark-submit 则无法查看作业的运行信息。
- why spark on k8s?
spark on yarn 与 spark on k8s 都可以用于实际生产,但为什么很多大公司更倾向于 k8s 呢?
yarn 是资源管理工具,用于管理 cpu 与 memory 的资源隔离;
k8s 是容器编排工具,显然资源管理是其功能之一;
如果按照“编排”的概念方向去理解 yarn,那么 yarn 就是一个 JVM 负载的编排工具,而 k8s 是容器负载的编排工具。这么一比较,k8s 显然胜出一筹,因为容器在应用的支持方面更广泛,更不要说 k8s 能够实现比 yarn 好得多的多的隔离了。
简而言之,用了 k8s 之后,不仅仅可以在这个集群运行 spark 负载,显然也可以运行其他所有的基于容器的负载,那么只需要把应用都进行容器化即可。比如 BI 工具、报表工具、查询工具等都可以在一个 k8s 集群上运行,而 spark 只是作为其中的应用之一。
so why not k8s?
1.4 spark 常用命令
- spark-shell
spark 提供的终端命令,允许在终端中使用 scala、java、python 等语言编写 spark 程序。
- spark-sql
spark 提供的终端命令,允许在终端使用 sql 语言操作数据。
- spark-submit
spark 提供的终端作业提交命令,允许将打包好的程序提交到集群中运行。
常用语法:
1.spark-submit [options] <app jar | python file | R file> [app arguments]
2.spark-submit --kill [submission ID] --master [spark://...]
3.spark-submit --status [submission ID] --master [spark://...]
可选配置:
--master 运行模式,默认为 local[*]
--class 主方法所在类名
--name 应用名称
--deploy-mode 指定 sparkonyarn 的客户端/集群模式,默认为 client,可以设置为 cluster
--executor-memory 执行器内存大小,默认为1g
--num-executors 执行器个数,默认为2
--executor-cores 每个执行器的 cpu 个数,默认为1
--driver-cores 驱动器的 cpu 个数,默认为1,只支持在 cluster 模式下修改
--jars 额外依赖的第三方 jar 包
--files 需要分发到各节点的数据文件
--total-executor-cores 执行器的 cpu 个数,默认为集群中全部可用的 cpu 个数
1.5 spark 底层执行原理
- 常用名词说明
RDD:一组分布式的存储在节点内存中的只读性数据集,spark 的基本计算单元
DAG:有向无环图,反应了 RDD 之间的依赖关系
STAGE:一个 stage 包含一组相同的 task,也叫做taskset,stage 包含的 task 个数取决于分区个数,一个分区对应一个 task
DAG Scheduler:有向无环图调度器,负责将 DAG 根据宽依赖划分 stage,并将 stage 交给 taskscheduler
taskscheduler:任务调度器,负责将 task 分发给 executor 执行
- spark 作业运行流程
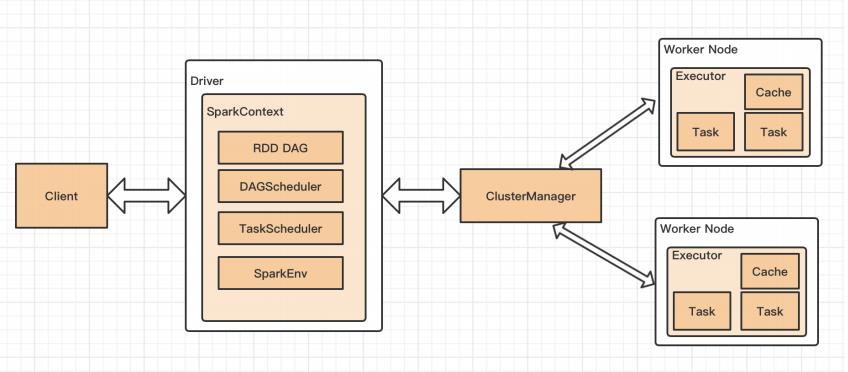
1.用户在客户端 spark-submit 提交 spark 程序给 clustermanager;
2.clustermanager 接收到程序之后会找一个 worker 启动 driver ,driver 开始运行 spark 程序的主函数;
3.然后 driver 创建 sparkcontext,将其作为资源调度的总入口,还会初始化 DAGscheduler 与 taskScheduler 以及 sparkenv;
4.driver 开始执行 spark 程序中的各种算子,根据 action 算子划分 job,一个 job 产生一个 DAG,一个 DAG 交给一个 DAGscheduler,根据宽依赖划分 stage(stage 就是 task 集合),然后一个 stage 交给一个 taskscheduler,它会将每个 task 交给 worker 上的 executor 去执行,并且执行器会开启线程去执行这些 task;
5.sparkenv 会启动一些控制组件,进行 shuffle 管理或者广播变量等的管理;
6.当所有 task 完成后,driver 关闭 sc,spark 作业结束。
- stage 划分
Spark 的计算发生在 RDD 的 Action 操作,而对 Action 之前的所有 Transformation,Spark 只是记录下 RDD 生成的轨迹,而不会触发真正的计算。
划分依据:Stage 划分的依据就是宽依赖,像 reduceByKey,groupByKey 等产生shuffle的算子,会导致宽依赖的产生。
窄依赖:父 RDD 的一个分区只会被子 RDD 的一个分区所使用。即一对一的关系。常见的产生窄依赖的算子有:map、filter、union、mapPartitions等。
宽依赖:父 RDD 的一个分区会被子 RDD 的多个分区所使用(涉及到 shuffle)。即一对多的关系。常见的产生宽依赖的算子有 groupByKey、reduceByKey、join等。
核心算法:回溯算法
从后往前回溯,遇到窄依赖就加进当前 Stage,遇见宽依赖进行 Stage 切分。
Spark 内核会从触发 Action 操作的那个 RDD 开始从后往前推,首先会为最后一个 RDD 创建一个 Stage,然后继续倒推,如果发现它对某个 RDD 是宽依赖,那么就会将宽依赖的那个 RDD 创建一个新的 Stage,那个 RDD 就是新的 Stage 的最后一个 RDD。然后依次类推,继续倒推,根据宽依赖进行 Stage 的划分,直到所有的 RDD 全部遍历完成为止。
例如:
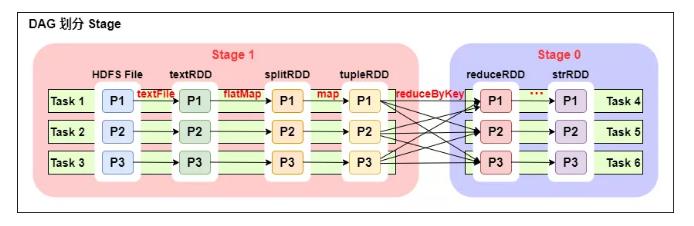
一个 Spark 程序可以有多个 DAG(有几个 Action,就有几个 job ,就有几个 DAG,上图最后只有一个 Action(图中未标出),那么就是一个 DAG)。
一个 DAG 可以有多个 Stage(根据宽依赖/shuffle 进行划分)。
同一个 Stage 可以有多个 Task 并行执行(task 数=分区数,如上图,Stage1 中有三个分区 P1、P2、P3,对应的也有三个 Task)。
可以看到这个 DAG 中只有 reduceByKey 操作是一个宽依赖,Spark 内核会以此为边界将其前后划分成不同的 Stage。
同时我们可以注意到,在图中 Stage1 中,从 textFile 到 flatMap 到 map 都是窄依赖,这几步操作可以形成一个流水线操作,通过 flatMap 操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 map 操作,这样大大提高了计算的效率。
2.sparkcore
2.1 SparkContext 介绍
Sparkcontext 是整个 spark 应用程序的上下文,控制应用的生命周期,它负责与 clustermanager 进行通信,并负责对资源的申请与任务分配,最重要的是它可以用来创建 RDD、累加器、广播变量,详情见源码
- sparkcore编程流程:
两种思路:
一种是在 idea 中编写 spark 代码,构建 Sparkcontext,然后 sc 进行各种操作(构建 RDD、调用一系列算子操作、关闭sc),打包上传到 spark client 上提交作业。
还一种是终端 spark-shell 中编写 spark 代码,不需要创建 sparkcontext,直接进行算子操作。
2.2 RDD 介绍
弹性分布式数据集是 spark 中最基本的数据抽象,主要属性包括:
1.数据分区
用来查看当前 rdd 的分区列表
2.计算函数
该函数由 spark 开发人员使用,用来编写 rdd 计算函数(如 map、flatMap 等算子)
3.依赖关系
展示分区间的依赖关系,可以用来构建血缘系统,当数据分区丢失后通过分区间的依赖关系进行恢复
4.分区方式
类似 mapreduce 的分区,默认采用 hashpartitioner ,键值对类型的 rdd 才会有分区方式
5.最佳位置
rdd 分区放置的最佳位置
数据分区、分区方式、最佳位置,这三个属性其实说的就是数据集在哪,在哪计算更合适,如何分区;
计算函数、依赖关系,这两个属性其实说的是数据集怎么来的。
2.3 RDD 数据分区
- 数据分区:站在数据的角度思考 RDD,它是由数据分区组成,这些分区运行在集群中的不同节点上,一个 RDD 可以包含多个分区,一个分区被封装成一个 task。例如:
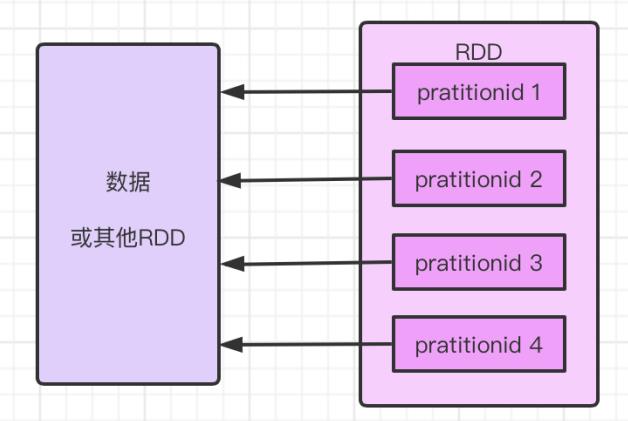
所以数据分区存储的是真正的数据吗?
数据分区内部并不会存储具体的数据,源码如下:

由上图知,分区包含一个index字段,表示了该分区在 RDD 内的编号,通过 RDD 编号和分区编号可以唯一确定该分区对应的块编号,进而可以从存储介质(比如hdfs)中提取出分区对应的数据。并且分区方式采用的是hashpartitioner。
- 分区方式:
spark 通过控制 RDD 分区方式来减少通信开销,只有 kv 类型的 RDD 才会有分区,默认采用hashpartitioner(类似 mapreduce 的分区)
2.4 RDD 操作
2.4.1 RDD 构建
- 读取外部数据集
常用 textFile、wholeTextFiles、sequenceFile等
sc.textFile(path[,minPartitions])
sc.wholeTextFiles(path[,minPartitions])
sc.sequenceFile(path,keyClass,valueClass[,minPartitions])
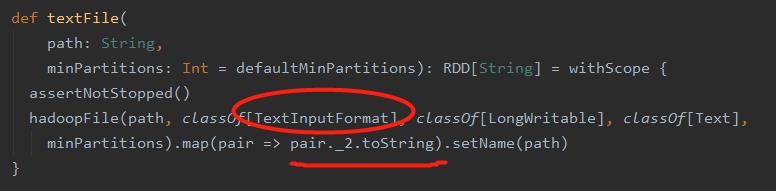
例如:
var rdd:RDD[String] = sc.textFile("a.txt",2)
path 可以是文件也可以是目录,也可以是带正则的路径
minpartitions 指定最小分区数
keyClass、valueClass 是指数据文件中 kv 的数据类型
- 集合并行化
sc.makeRDD(seq[,numPartition])
sc.parallelize(seq[,numPartition])
例如:
var rdd = sc.makeRDD(Array(1,2,3,4,5,6),2)
seq指集合,numpartition分区个数(并行度)
分区个数会决定 stage 中 task 的个数,代表了 spark 作业的并行度,那么分区个数可以变吗?
2.4.2 RDD 重分区
通过创建 RDD 我们可以指定分区个数,若我们需要调整分区个数时则需要进行重分区操作
常见重分区方法如下:


区别?
repartition 默认shuffle,网络开销大
coalesce 可以设置是否shuffle
如何使用?
调大分区数的时候需要将分区内的数据打乱再分发到多个分区,要shuffle,可以采用 repartition
而调小分区数可以直接让多个分区合并为一个大分区,没必要shuffle,可以采用coalesce,减小网络开销
2.4.3 RDD 算子
RDD 算子分为两大类,transform 算子与 action 算子
常用的转化算子如下:
- 基于元素进行操作

常规操作
- 基于分区进行操作

连接数据库时可以采用基于分区操作的算子,每个分区创建一个连接对象,避免创建大量连接对象!
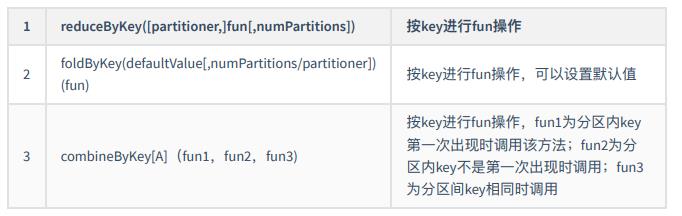
- 聚合操作
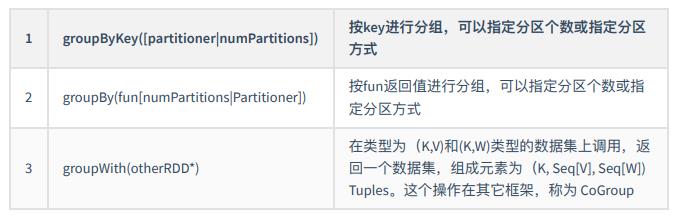
- 分组操作
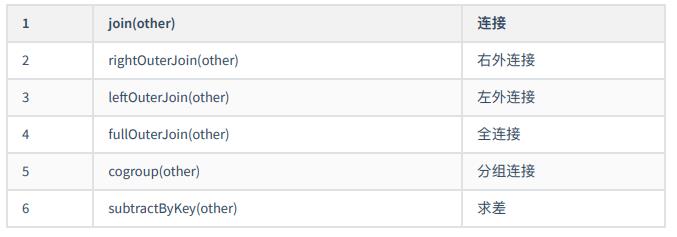
- 连接操作
- 排序操作

常用的 action 算子如下:
只有 action 算子执行后,transform 算子才会生效!
- 获取部分元素
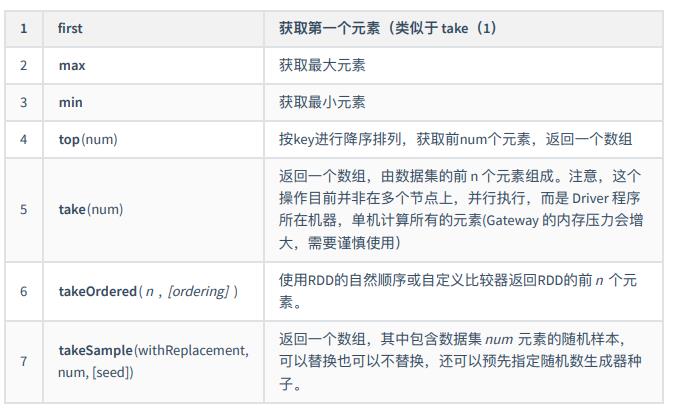
- 规约操作

- 输出到外部系统

- 其他操作
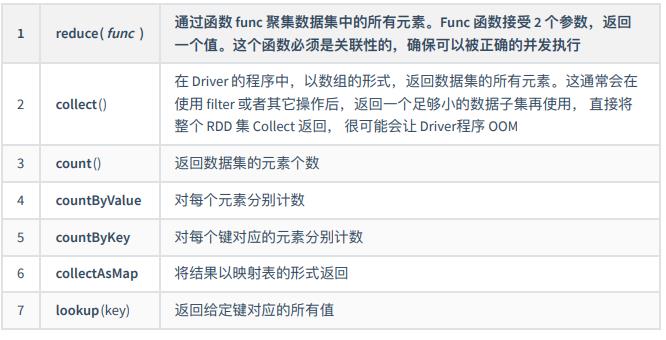
2.4.4 RDD 缓存操作
如果某个 RDD 频繁被使用,可以将 RDD 缓存在内存中,这样后续的其他操作就可以重用 RDD,以此来提高查询速度,缓存操作属于 transform 算子,需要 action 算子执行后才会生效。
常用方法:
- cache():只存储在内存中
- persist(持久化级别):指定一个持久化级别进行存储
常用持久化级别:
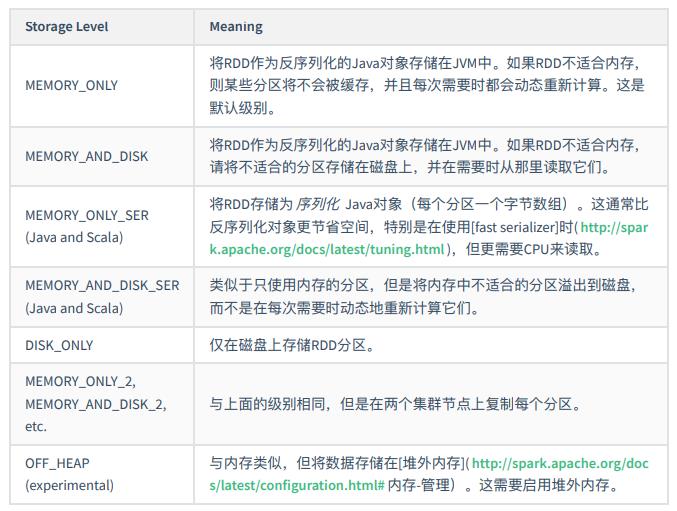
RDD 缓存可以把数据放在内存中,虽然很快,但同时也不可靠。我们也可以把数据放在磁盘上,但也不是完全可靠的,因为磁盘可能会坏!那 RDD 怎样才能保证容错呢?
2.4.5 RDD 容错机制 Checkpoint
Checkpoint 的产生就是为了更加可靠的数据持久化,在 Checkpoint 的时候一般把数据放在在 HDFS 上,这就天然的借助了 HDFS 天生的高容错、高可靠来实现数据最大程度上的安全,实现了 RDD 的容错和高可用。
例如:
SparkContext.setCheckpointDir("目录") //HDFS的目录
RDD.checkpoint
总结:
- 开发中如何保证数据的安全性性及读取效率:可以对频繁使用且重要的数据,先做缓存操作,再做 checkpoint 操作。
- 持久化和 Checkpoint 的区别:
- 位置:Persist 和 Cache 只能保存在本地的磁盘和内存中(或者堆外内存中),Checkpoint 可以保存数据到 HDFS 这类可靠的存储上。
- 生命周期:Cache 和 Persist 的 RDD 会在程序结束后会被清除或者手动调用 unpersist 方法,Checkpoint 的 RDD 在程序结束后依然存在,不会被删除。
所以,讲到这里可以总结一下 MapReduce 与 spark 的区别:
1.spark 把运算的中间结果保存在内存,迭代计算的效率更高,mr 中间结果保存在磁盘
2.spark 的容错性高,它采用弹性分布式数据集 RDD 实现高效容错( 缓存操作和 checkpoint 机制),某一部分数据如果丢失,可以通过整个计算过程的血缘关系(依赖关系)进行重建,而 mr 的容错只能重新计算。
3.spark更通用,它提供了 transform 算子和 action 算子这两大类 api 算子,而 mr 只有 map 和 reduce 两种方法。
2.5 闭包
运行如下代码,看看现象如何:
class Hello
val param = 1
def work(rdd: RDD[Int])
rdd.map(x => x + param).foreach(println)
object BibaoTest
def main(args:Array[String])=
//1.获取SparkConf对象
val conf=new SparkConf().setMaster("local[*]").setAppName("BibaoTest")
//2.获取SparkContext对象
val sc:SparkContext=SparkContext.getOrCreate(conf)
sc.setLogLevel("warn")
//3.构建rdd
val rdd=sc.makeRDD(1 to 10)
//4.构建对象调用方法
val rdd1=new Hello
rdd1.work(rdd)
sc.stop()
该程序产生异常:NotSerializableException
分析:
-
出现异常的原因:闭包
1. 如果 RDD 相关操作需要传递函数,而该函数需要访问外部变量,则此时会产生闭包。
2. 闭包需要遵循—定的规则(闭包内的对象必须可以进行序列化),否则会抛出运行时异常。
-
闭包函数传入到从节点时,需要经过下面的步骤:
1. 驱动程序,通过反射,运行时找到闭包访问的所有变量,并封装成一个对象,然后序列化该对象;
2. 将序列化后的对象通过网络传输到 worker 节点;
3. worker 节点反序列化闭包对象;
4. worker 节点执行闭包函数;
简而言之,通过网络,传递闭包函数,然后执行闭包函数。本地执行时,仍然会按照以上四步进行。
- 解决办法
1.让闭包所在的类实现序列化接口;
class Hello extends Serializable
val param = 1
def work(rdd: RDD[Int])
rdd.map(x => x + param).foreach(println)
2.尽量避免在闭包中使用全局变量;
class Hello
val param = 1
def work(rdd: RDD[Int])
val _param = this.param
rdd.map(x => x + _param).foreach(println)
2.6 累加器与广播变量
首先,以分割字符串的过程中统计 RDD 中空行出现的次数为例:
val file=sc.textFile("a.txt")
var blankLines=0
val callSigns=file.flatMap(
line =>
if (line == "")
blankLines +=1
line.split(" ")
)
callSigns.saveAsTextFile("output.txt")
println("Blank lines:"+blankLines)
结果为?
-
分析:外部变量在闭包内的修改不会被反馈到驱动程序
-
解决方法:使用共享变量解决该问题
spark 支持两种共享变量:
-
累加器
对数据信息进行聚合(聚合到驱动器程序中);
-
广播变量
用来高效分发较大的只读对象;
2.6.1 累加器
- 累加器类型:
-
LongAccumulator
-
DoubleAccumulator
-
CollectionAccumulator
-
自定义累加器(继承抽象类 AccumulatorV2)
- 累加器方法(借助于 SparkContext 类中的方法):
构造:
-
longAccumulator(name:String): LongAccumulator
-
doubleAccumulator(name:String): DoubleAccumulator
-
collectionAccumulator[T] (name:String): CollectionAccumulator[T]
(推荐在构造累加器的时候指定名字,这样在 spark web 界面就可以看到累加器了)
使用:
-
执行器代码可以使用累加器的 add 方法增加累加器的值
-
驱动器程序可以调用累加器的 value 属性来访问累加器的值
- 上述案例代码修改:
val file=sc.textFile("src/SparkTestFiles/count1.txt")
//var blankLines=0
val blankLines=sc.longAccumulator("blankLines");
val callSigns=file.flatMap(
line =>
if (line == "")
//blankLines +=1
blankLines.add(1);
line.split(" ")
)
callSigns.saveAsTextFile("src/SparkTestFiles/output.txt")
println("Blank lines:"+blankLines.value)
2.6.2 广播变量
将一个只读数据(非 RDD)通过广播的形式广播到各个执行器节点,并将该数据序列化缓存到节点上。
- 广播方法:
broadcast[T: ClassTag] (value: T): Broadcast[T]
(传入一个变量,将其变为广播变量)
- 广播用法:
观察如下代码:
//大数据集合
val list=1 to 100;
//获取RDD
val rdd=sc.parallelize(List(1,300,10,33,24,51,67,112,346,14,5))
//第一个job
rdd.filter(num=>
list.contains(num)
).foreach(println)
println("----")
//第二个job
rdd.map(num=>
list.contains(num)
).foreach(println)
说明:
-
两个 job 中使用了匿名函数的非局部变量 list
-
非局部变量 list 是一个较大的只读值
使用广播变量优化:
//为list创建广播变量
val list=1 to 100;
val broadcast=sc.broadcast(list);
//获取RDD
val rdd=sc.parallelize(List(1,300,10,33,24,51,67,112,346,14,5))
//第一个job
rdd.filter(num=>
val list=broadcast.value
list.contains(num)
).foreach(println)
println("----")
//第二个job
rdd.map(num=>
val list=broadcast.value
list.contains(num)
).foreach(println)
说明:
-
参数只会被广播到各个节点一次,应作为只读值处理,不应该再修改。
-
通过 Broadcast 对象的 value 属性访问该参数的值。
对比以上两种代码,可以得知广播变量的优缺点:
优点︰避免多次数据传输,进而减少通信的开销提高计算效率
缺点∶使用广播会使代码不够简洁
- 广播优化:
当广播一个比较大的值时,选择既快又好的序列化格式非常重要。
Spark 支持的序列化:
-
JavaSerializer 序列化
i. Spark 的 Scala 和 Java 的 API 默认使用 JAVA 的序列化进行序列化
ii. JavaSerializer 除基本类型以及基本类型的数组之外,其他类型都比较低效
-
KryoSerializer [k’raɪəʊ] 序列化
Kryo 是一个快速且高效的针对 Java 对象序列化的框架,
特点:
i. 序列化的性能非常高
ii. 序列化结果体积较小
iii. 提供了简单易用的 API
用法:
conf.set(“spark.serializer”,“org.apache.spark.serializer.KryoSerializer”)
conf.registerKryoClasses(Array(classOf[MyClass1],classOf[MyClass2] ))
-
自定义序列化
Spark-Sql 中的核心抽象模型 Dataset 使用 Encoder[T] 专业编码器来替换序列化。
3.sparksql
3.1 sparksql 介绍
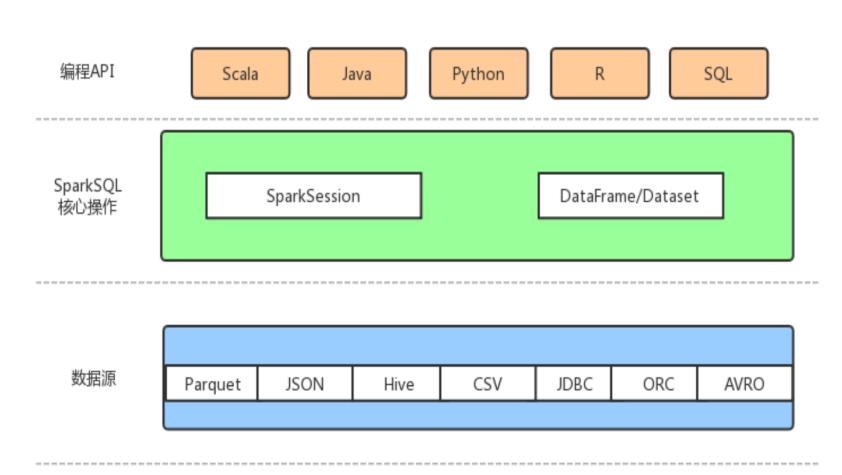
Spark SQL 是 Spark 中处理结构化数据的模块。提供了一种新的编程抽象 DataFrame/Dataset,并且可以充当分布式 SQL 查询引擎。
- 集成:无缝地将 SQL 查询集成到 Spark 程序中。
- 统—数据访问:使用统一的方式连接到常见数据源。
- Hive兼容:通过配置可以直接兼容 Hive,运行查询 Hive 数据。
- 标准的连接:通过 JDBC、ODBC 连接。Spark SQL 包括具有行业标准 JDBC 和 ODBC 连接的服务器模式。
3.2 sparksql 发展历程
Hive
Hive 是基于 Hadoop 的一个数据仓库工具
- 可以将结构化的数据文件映射为一张数据库表;
- 可以提供简单的 SQL 查询功能;
- 可以将 SQL 语句转换为 MapReduce 任务并行运算;
Hive 计算引擎依赖于 MapReduce 框架
- 随着时代的发展,对数据提取转化加载(ETL)需求越来越大;
- 因此开发一个更加高效的 SQL-on-Hadoop 工具更加的迫切;
shark
Shark 便是其中之一
- 修改了 Hive 中内存管理、物理计划、执行这三个模块,运行在 Spark 引擎上,使得 SQL 查询的速度得
到10-100倍的提升。
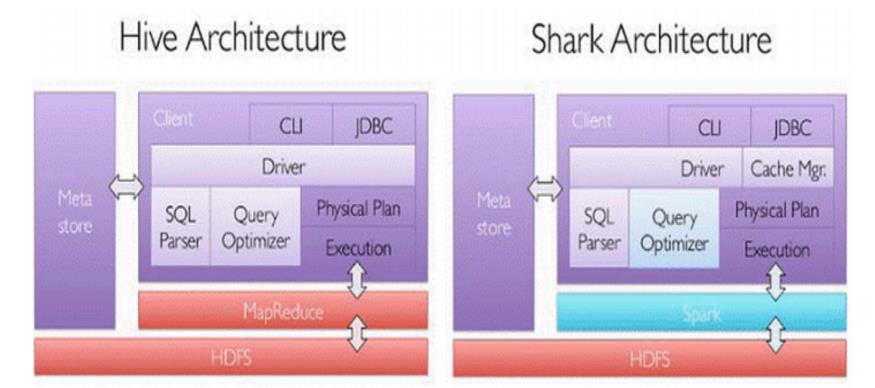
随着 Spark 的发展
- Shark 对于 Hive 太多依赖
- 制约了 Spark 各个组件的相互集成
- 所以提出了 SparkSQL 项目
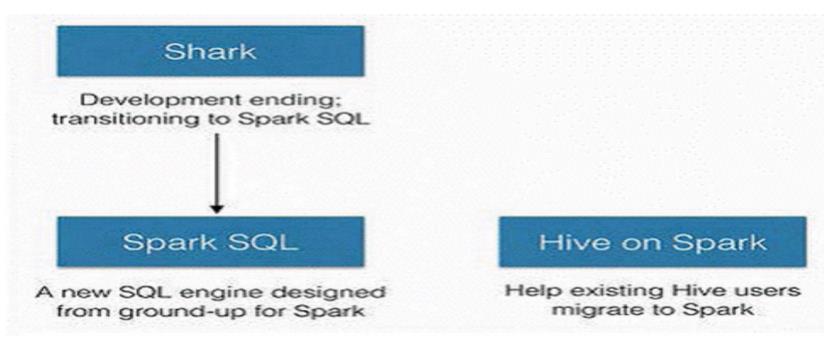
- 2014年宣布:停止开发 shark,至此 Shark 的发展画上了句号
- SparkSQL 作为 Spark 生态的一员继续发展
- 不再受限于 Hive,只是兼容 Hive
Hive on Spark 是 Hive 的发展计划
-
该计划将 Spark 作为 Hive 的底层引擎之一
-
也就是说,Hive 将不再受限于一个引擎。可以采用 MapReduce、Spark 等引擎
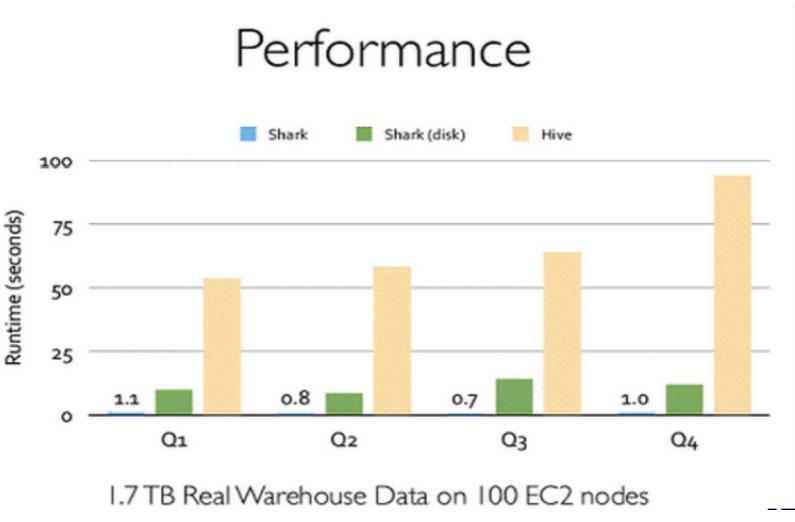
Shark 的出现,使得 SQL-on-Hadoop 的性能比 Hive 有了10-100倍的提高。
摆脱了 Hive 的限制,SparkSQL 的性能与 Shark 对比,也有很大的提升。
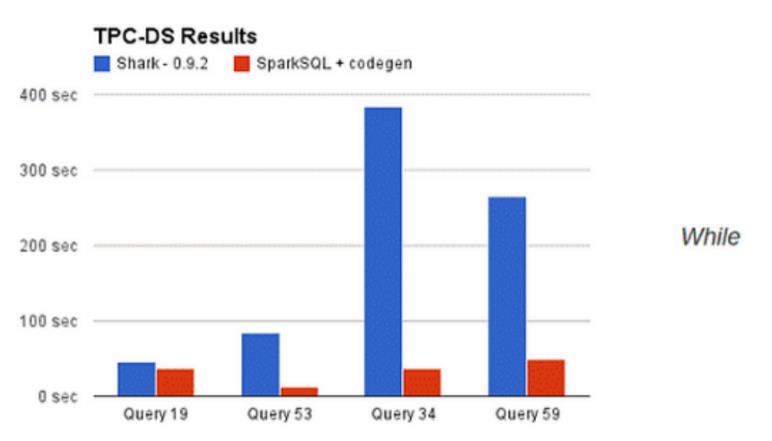
为什么 sparksql 的性能会得到如此大的提升呢?
3.3 sparksql 优点
SparkSQL 主要是在以下三点做了优化(主要是与 Sparkcore 对比):
-
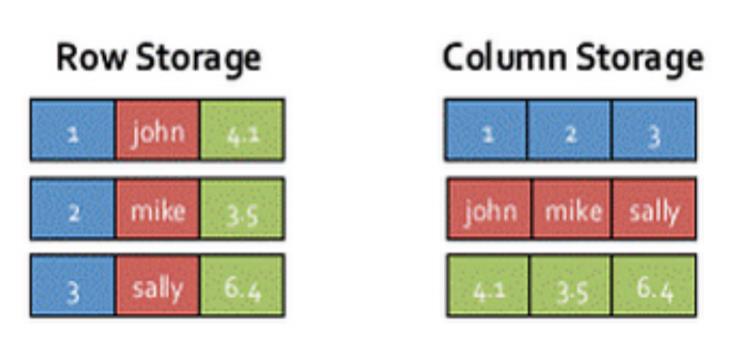
内存列存储(In-Memory Columnar Storage)
- SparkSQL 的表数据在内存中存储不是采用原生态的 JVM 对象存储方式,而是采用内存列存储,如下图所示。
-
采用了内存列存储之后,减少了对内存的消耗,减少 JVM 的 GC 性能开销。
-
字节码生成技术(bytecode generation,即 CG)
- Spark SQL 在其 catalyst 模块的 expressions 中增加了 codegen 模块。
- 对于 SQL 语句中的计算表达式,比如 select num + num from t 这种的 sql,就可以使用动态字节码生成技术来优化其性能。
-
Scala 代码优化
-
使用 Scala 编写的代码,对可能造成较大性能开销的代码,Spark SQL 底层会使用更加复杂的方式进行重写,来获取更好的性能。
-
比如 option 样例类、for 循环、map/filter/foreach 等高阶函数,以及不可变对象,都改成了用 null、while 循环等来实现,并且重用可变的对象。
3.4 sparksql 架构
3.4.1 基础架构
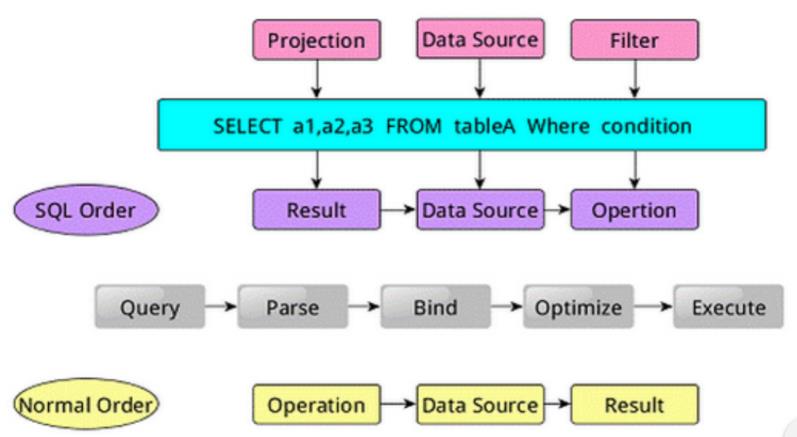
SparkSQL 语句由三部分组成,分别对应 SQL 查询过程中的 Result、Data Source、Operation。
- Projection (a1,a2,a3)
- Data Source (tableA)
- Filter (condition)
SQL 语句按 Result–>Data Source–>Operation 的次序描述。
3.4.2 执行流程
执行 SQL 语句的一般顺序为∶
1.对读入的 SQL 语句进行解析(Parse)
- 分辨出 SQL 语句中哪些词是关键词(如 SELECT、FROM、WHERE) ;
- 哪些是表达式;
- 哪些是 Projection;
- 哪些是 Data Source 等;
- 从而判断 SQL 语句是否规范;
2.将 SQL 语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind)。
- 如果相关的 Projection、Data Source 等都是存在的话,就表示这个 SQL 语句是可以执行的。
3.一般数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize)。
4.计划执行(Execute),按 Operation–>Data Source–>Result 的次序来进行。
- 在执行过程有时候甚至不需要读取物理表就可以返回结果。
- 比如重新运行刚运行过的 SQL 语句,可能直接从数据库的缓冲池中获取返回结果。
3.4.3 catalyst 解析与优化
Catalyst 是 Spark SQL 执行优化器的代号,所有 Spark SQL 语句最终都能通过它来解析、优化,最终生成可以执行的 Java 字节码。catalyst 采用的数据结构是 Tree 和 Rule,数和规则构成了 catalyst 解析优化器:
- Catalyst 最主要的数据结构是树,所有 SQL 语句都会用树结构来存储,树中的每个节点都拥有特定的数据类型,以及0或多个子节点。Scala 中定义的新的节点类型都是 TreeNode 这个类的子类。
- Catalyst 另外一个重要的数据结构是规则。基本上,所有优化都是基于规则的。可以用规则对树进行操作,树中的节点是只读的,所以树也是只读的。规则中定义的函数可能实现从一棵树转换成一颗新树。
优化策略:
-
RBO(Rule-based optimization) 基于规则的优化
- 优化思路主要是减少参与计算的数据量以及计算本身的代价。
-
CBO(Cost-based optimization) 基于代价优化策略
- 它充分考虑了数据本身的特点(如大小、分布)以及操作算子的特点(中间结果集的分布及大小)及代价,从而更好的选择执行代价最小的物理执行计划,即 SparkPlan。
整个Catalyst 的执行过程主要分为以下5个阶段:
- 解析阶段,解析出关键字,生成逻辑语法树
- 分析阶段,分析逻辑树,解决引用;
- 逻辑优化阶段;
- 物理计划阶段,Catalyst 会生成多个计划,并基于成本进行对比;
- 代码生成阶段;
具体过程:
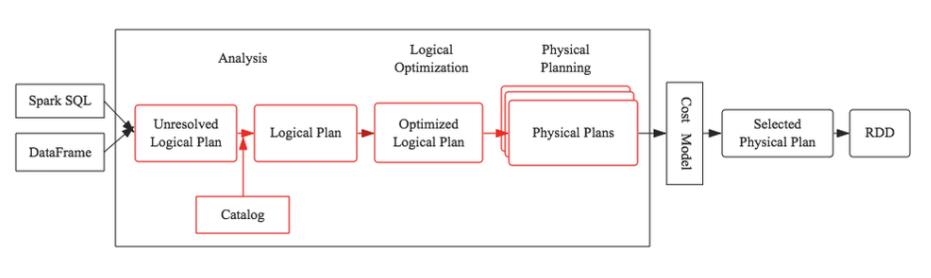
sparksql 程序经过 catalyst 的解析与优化后,最终会以 RDD 的方式(转变为 job、dag、stage)去执行 Physical Plan。
下面通过一个简单的示例进行解释:
Parser
Parser 简单来说是将 SQL 关键词切分成一个一个 Token,再根据一定语义规则解析为一棵语法树(根据关键字)。Parser 模块目前基本都使用第三方类库 ANTLR 进行实现,比如 Hive、 Presto、SparkSQL 等。下图是一个示例性的 SQL 语句(有两张表,其中 people 表主要存储用户基本信息,score 表存储用户的各种成绩),通过 Parser 解析后的 AST 语法树如下图所示:
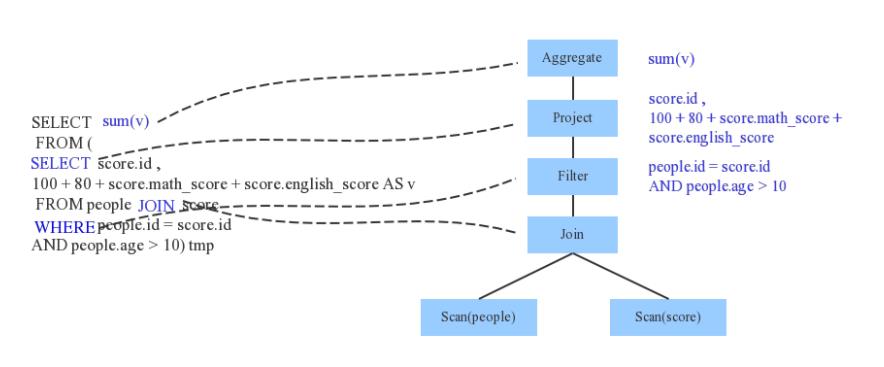
Analyzer
通过解析后的逻辑执行计划基本有了骨架,但是系统并不知道 score、people 这些都是些什么玩意儿,此时需要基本的元数据信息(catalog)来表达这些名词,最重要的元数据信息主要包括两部分:表的 Schema 和基本函数信息,表的 schema 主要包括表的基本定义(列名、数据类型)、表的数据格式(Json、Text)、表的物理位置等,基本函数信息主要指函数的类信息(聚合函数、udf)。
Analyzer 会再次遍历整个语法树,对树上的每个节点进行数据类型绑定以及函数绑定,比如 people 这个词会根据元数据表信息解析为包含 age、id 以及 name 三列的表,people.age 会被解析为数据类型为 int 的变量,sum 会被解析为特定的聚合函
以上是关于spark技术学习与思考(sparkcore&sparksql)的主要内容,如果未能解决你的问题,请参考以下文章
Spark学习之路 SparkCore的调优之开发调优[转]
Spark学习之路 SparkCore的调优之Spark内存模型