阿里云天池 零基础入门NLP - 新闻文本分类 2种做法,F1=0.87
Posted 小哈里
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了阿里云天池 零基础入门NLP - 新闻文本分类 2种做法,F1=0.87相关的知识,希望对你有一定的参考价值。
problem

1、赛题理解
-
数据集:
在NLP_data_list_0715.csv中,有三个链接。
分别可以下载训练集,测试集A,测试样例。
-
f1_score介绍:
F1分数(F1-score)是分类问题的一个衡量指标 。一些多分类问题的机器学习竞赛,常常将F1-score作为最终测评的方法。它是精确率和召回率的调和平均数,最大为1,最小为0。

-
不太明白,按照字符级别进行了匿名处理是什么意思?
先用panda读一下数据。

2、数据分析(数据探索 EDA)
-
句子长度分析
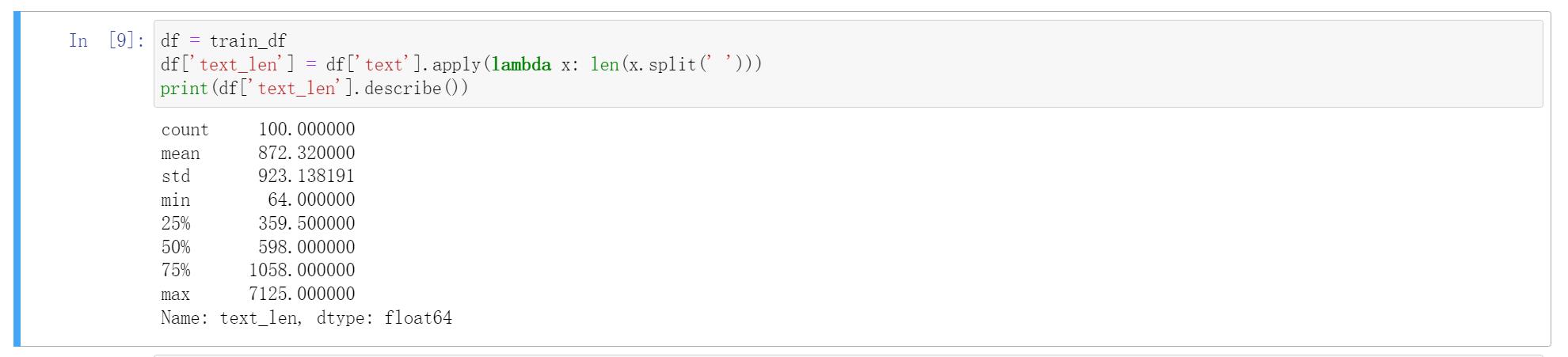
新闻文本数据的每个单词由空格隔开,所以我们可以直接统计单词的个数来得出每段新闻的长度。
可以知道:每个句子平均由923个字符构成,最短的句子长度为64,最长的句子长度为7125。
-
单词分析

-
类别分布分析
接下来我们可以对数据集类别分布进行统计,即统计每类新闻的样本个数。

-
数据结论:
抽取训练集中100个样本进行数据分析,得到以下结论- 给定的文本比较长,每个句子平均由923个字符构成,最短的句子长度为64,最长的句子长度为7125。
- 在训练集中总共包括2405个字,其中编号3750的字出现的次数最多,编号5034的字出现的次数最少。
- 各类标签有不平衡的问题,其中最多的是科技类新闻,最少的是星座类新闻。
- 样本偏长,需要做截断。
- 类别不均衡会影响模型的精度。
3、特征工程 + 模型训练
-
解题思路:
由于数据脱敏,我们需要对匿名字符进行建模,进而完成文本分类。由于文本数据是一种典型的非结构化的数据 ,因此可能涉及到‘特征提取’和‘分类模型’两个部分。 -
主要思路(特征提取+分类模型):
- TF-IDF+机器学习分类器
直接使用TF-IDF对文本提取特征,并使用分类器进行分类。在分类器的选择上,可以使用SVM、LR、或者XGBoost。 - WordVec+深度学习分类器
WordVec是进阶款的词向量,并通过构建深度学习分类完成分类。深度学习分类的网络结构可以选择TextCNN、TextRNN或者BiLSTM。 - FastText
FastText是入门款的词向量,利用Facebook提供的FastText工具,可以快速构建出分类器。 - Bert词向量
Bert是高配款的词向量,具有强大的建模学习能力。
- TF-IDF+机器学习分类器
4、TF-IDF+RidgeClassifier(线性模型)
-
原理:

-
代码:
import pandas as pd from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.linear_model import RidgeClassifier from sklearn.metrics import f1_score train_data=pd.read_csv("train_set.csv",sep='\\t') test_data=pd.read_csv("test_a.csv",sep='\\t') train_data.shape (200000, 2) train_data[:5] # Tfidf tf_idf=TfidfVectorizer(max_features=2000).fit(train_data['text'].values) train_tfidf=tf_idf.transform(train_data['text'].values) train_tfidf.shape (200000, 2000) test_tfidf=tf_idf.transform(test_data['text'].values) # 岭回归 clf=RidgeClassifier() clf.fit(train_tfidf,train_data['label'].values) RidgeClassifier() # F1值 val_pred = clf.predict(train_tfidf[10000:]) print(f1_score(train_data['label'].values[10000:], val_pred, average='macro')) # 测试集 df=pd.DataFrame() df['label']=clf.predict(test_tfidf) df.to_csv('submit.csv',index=None)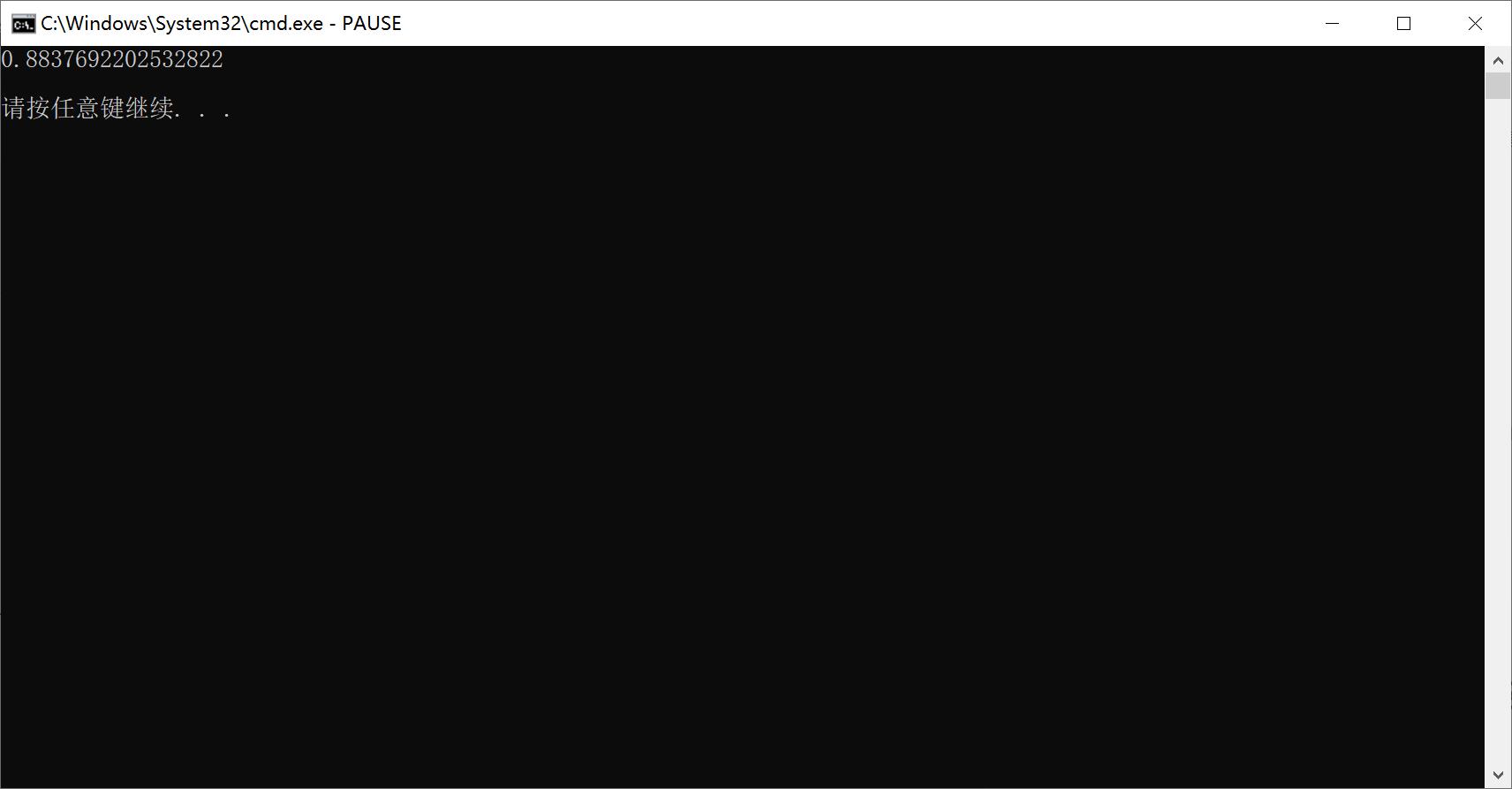
-
结果:
F1_Score = 0.8837
5、WordVec+TextCNN(卷积神经网络)
-
原理:

-
运行结果
F1_Score = 0.8562
以上是关于阿里云天池 零基础入门NLP - 新闻文本分类 2种做法,F1=0.87的主要内容,如果未能解决你的问题,请参考以下文章