神经网络机器翻译与注意力机制
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了神经网络机器翻译与注意力机制相关的知识,希望对你有一定的参考价值。

-
路荣伟 : (2021214341 信息科学与技术 计算机技术 tntnnlrw@163.com)
-
摘 要: 神经网络机器翻译是深度神经网络取得杰出成就的领域之一,与传统的统计机器翻译需要大量提取特征,存储信息不同,神经网络机器翻译的目的从一开始就是构造出一个单一的模型来实现最完美的翻译,无论句子长短。本文着重介绍了使用RNN和LSTM的NMT网络,并对注意力机制进行了介绍。
-
关键词: 神经网络机器翻译;注意力机制;编码器与解码器
§01 引 言
由于神经网络的重新发现,自然语言处理NLP领域的各个领域都得到了提升[1],然而,长期以来,将神经网络集成到机器翻译(MT)系统中还很肤浅。早期有人尝试用前馈神经网络语言模型来为目标语言重新排序来进行翻译[2]。第一个将源语言考虑在内的神经网络模型扩展了这一思想[3],使用双语元组而不是目标语句单词的相同模型[4],直接用前馈网络进行评分,或者向神经语言模型添加源上下文窗口[5]。Kalchbrenner[6]和Cho[7]等人引入递归网络用于翻译建模。所有这些方法都将神经网络应用于传统的统计机器翻译系统SMT中。因此,他们保留了对数线性模型组合,仅交换了传统架构中的部分。
神经机器翻译NMT克服了这种分离,它使用单一的大型神经网络,直接将源句转换为目标句[8, 9]。NMT的出现无疑是MT历史上一个重要的里程碑,并导致了主流研究与以往许多研究路线的突然背离。这一点最好地反映在过去几年中与NMT相关的论文的激增和大量公开可用的NMT工具上[10, 11]。NMT现在已经在行业中被广泛采用[6, 12, 13],并部署在谷歌、微软、Facebook等公司的生产系统中。本文将介绍NMT的编码器解码器网络,以及NMT中非常重要的注意力机制。
§02 译码器-解码器
K&B[6]是第一个将目标句子的分布设定在源句的分布固定长度表征上的人。他们的循环连续翻译模型(RCTM)I和II产生了编码器-解码器网络,这是当今流行的NMT架构。编码器-解码器网络被细分为计算源语句表示的编码器网络和从该表示中产生目标语句的解码器网络。我们表示源句为X=𝑥𝑥1𝐼𝐼,目标句为Y=𝑦𝑦1𝐽𝐽,所有的NMT模型都通过将目标句分解为条件句来定义其概率分布。
P ( y ∣ x ) = ∏ j = 1 J P ( y j ∣ y 1 j − 1 , x ) P\\left( y|x \\right) = \\prod\\limits_j = 1^J P\\left( y_j |y_1^j - 1 ,x \\right) P(y∣x)=j=1∏JP(yj∣y1j−1,x)
不同的编码器解码器架构在他们如何定义分布P(𝑦𝑦𝑗𝑗|𝑦𝑦1𝑗𝑗−1,x),我们首先讨论编码器代表固定长度源句子的编码器解码器网络,这里分布P(𝑦𝑦𝑗𝑗|𝑦𝑦1𝑗𝑗−1,x)被定义为:
P
(
y
j
∣
y
1
j
−
1
,
x
)
=
g
(
y
j
∣
s
j
,
y
j
−
1
,
c
(
x
)
)
P\\left( y_j |y_1^j - 1 ,x \\right) = g\\left( y_j |s_j ,y_j - 1 ,c\\left( x \\right) \\right)
P(yj∣y1j−1,x)=g(yj∣sj,yj−1,c(x))
其中𝑠𝑠𝑗𝑗是RNN的隐层状态。例如LSTM[14]或者GRU[7]的门激活函数经常被用来解决训练RNN中的梯度消失问题[15],梯度消失最大的问题就是会很难捕捉到长范围的句子内的联系,这会很难训练RNN网络。2014年,叠层的LSTM的深度神经网络被提出,这是第一次首次完整实现端到端的序列翻译,也解决了深度神经网络中对于维度的要求。编码器可以是一个卷积神经网络,比如在RCTM I中,也可以是一个LSTM网络,或者一个GRU网络。g(·)是一个在结尾带有softmax层的反馈网络,以解码器状态s和前面语料的embedding为输入。此外g(·)也是以源句子的编码c(x)作为条件的输入。
此外,c(x)也被用来初始化解码状态s1,在下图中对比了两种方法。直观的说,一旦源句子被编码,解码器就开始生成第一个目标句子符号y1,然后将其反馈给解码器网络,当网络产生EOS时,算法终止。完整的端到端的NMT图见图2,这个工作首先提出了第一个独立的不依赖于任何SMT基准的NMT网络,这和传统需要大量引擎特征的统计机器翻译系统有着天壤之别。
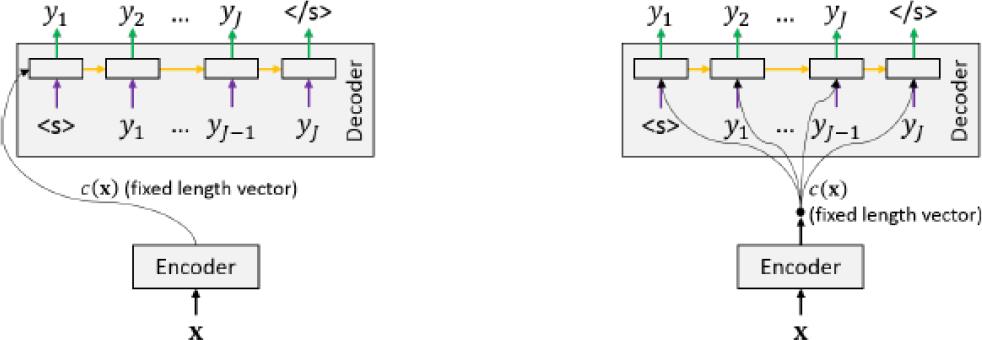
▲ 图2.1 带有固定长度编码的编码器-加码器架构
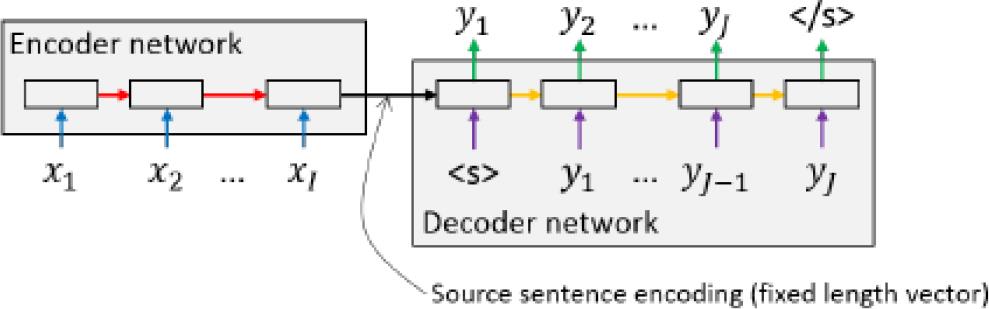
▲ 图2.2 Sutskever等人提出的编码器-加码器架构
过去已经探索了向编码器网络提供源语句的不同方法,Cho等人将符号按照他们在源句子中出现的自然顺序输入到编码器,Sutskever等人报告了简单地倒叙输入序列获得的增益。他们认为,这些改进可能是由于引入了许多对数据集的短期依赖,虽然这个假设并没有任何的理论证明。双向RNN可以捕获同时两个方向的信息,所以经常被用在带有注意力机制的NMT中。
§03 注意力机制
一直困扰NMT模型的问题就是,他们对于足够长的句子并不能很好的翻译[16]。Cho等人说这种薄弱很可能是由于固定长度的源句编码,具有可变长度的句子表达了不同数量的信息。因此,即使很适合翻译短句子,固定长度的向量并没有足够的能力来对具有复杂结构和含义的句子进行编码。Pouget-Abadie等人[17]尝试将源句子分割成简短的从句来缓解这个问题。但是这种方法并不能很好的处理长距离的重新排列,因为这种排序只能在子句中进行。
Bahdanau[8]引入了注意力的概念,来避免使用固定长度的源句表征。他们的模型不再使用固定的上下文向量c(x)。相比之下,注意力解码器能将其注意力放在源句子中对产生下一个标记有用的部分上。因此,常量上下文向量c(x)被一系列上下文向量c替代。我们遵循Vaswani[18]等人的术语,将注意力描述为根据存储的映射表将n个查询向量映射到n个输出向量。这种观点和增强记忆神经网络有关。我们做一个简单的假设,假设所有的向量都有d维,这样我们就可以把这些向量叠加到矩阵Q、K和V中,直观上来讲,对于每个查询向量,我们将输出向量作为值向量的加权和计算。权重是由查询向量和键之间的相似度分数决定的。
A t t e n t i o n ( K , V , Q ) = S o f t max ( s c o r e ( Q , K ) ) ⋅ V Attention\\left( K,V,Q \\right) = Soft\\max \\left( score\\left( Q,K \\right) \\right) \\cdot V Attention(K,V,Q)=Softmax(score(Q,K))⋅V
score(Q,K)的输出是一个n*m的句子。softmax函数对该矩阵进的列进行归一化,来使得每个查询向量的权重总和为1。score的一个直接办法由Luong等人提出,他们使用点积的方式。一个普遍使用注意力机制的方法是在编码端和解码端中间加一层接口。Bahdanau等人使用隐藏解码状态s作为查询向量。所有的键和值向量都来自于递归编码器的隐藏状态h。
对注意力机制的一个重要的泛化就是多头注意力机制,这个机制在Transfomer中,由Vaswani等人提出,这个想法是为了执行H个注意力操作,而不是一个单独的操作,其中H是注意力head的数量,通常H=8,注意力head的查询、键、值向量分别是Q、K和V的投影。多头注意的输出是每个注意力head输出的串联。注意力head的维度通常除以H,来避免增加参数数量,从形式上可以被描述为 :
M u l t i H e a d A t t e n s i o n ( K , V , Q ) = C o n c a t ( h e a d 1 , ⋯ , h e a d H ) ⋅ W O MultiHeadAttension\\left( K,V,Q \\right) = Concat\\left( head_1 , \\cdots ,head_H \\right) \\cdot W^O MultiHeadAttension(K,V,Q)=Concat(head1,⋯,headH)⋅WO
下图中描述了多头注意力模块,head的数量为3。我们注意到如何提取一个单独的注意力权重矩阵并不容易,所以使用多头注意力机制的模型很难去解释。
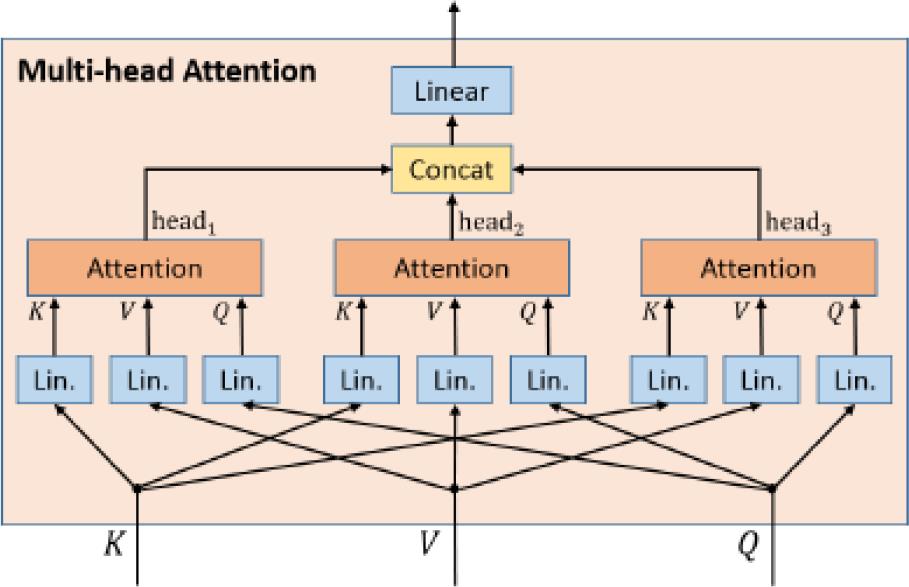
▲ 图3.1 多头注意机制
注意力的概念不仅仅是一种提高句子长度的技术。自从Bahdanau等人[8]引入以来,它已经成了各种NMT架构的重要组成部分。最终形成了完全基于注意力的Transformer架构。注意力被证明在识别物体、图像字幕生成、视频描述、语音识别、生物信息学、文本摘要、文本归一化、语法纠错、问题回答、自然语言理解和推理、不确定度测量、光学字符标识和自然语言对话这些领域都能取得杰出效果。
§04 参考文献
[1] GOLDBERG Y. A primer on neural network models for natural language processing [J]. Journal of Artificial Intelligence Research, 2016, 57: 345-420.
[2] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model [J]. Journal of machine learning research, 2003, 3(Feb): 1137-55.
[3] SCHWENK H, DéCHELOTTE D, GAUVAIN J-L. Continuous space language models for statistical machine translation; proceedings of the Proceedings of the COLING/ACL 2006 Main Conference Poster Sessions, F, 2006 [C].
[4] ZAMORA-MARTINEZ F, CASTRO-BLEDA M J, SCHWENK H. N-gram-based machine translation enhanced with neural networks for the French-English BTEC-IWSLT’10 task; proceedings of the International Workshop on Spoken Language Translation (IWSLT) 2010, F, 2010 [C].
[5] DEVLIN J, ZBIB R, HUANG Z, et al. Fast and robust neural network joint models for statistical machine translation; proceedings of the proceedings of the 52nd annual meeting of the Association for Computational Linguistics (Volume 1: Long Papers), F, 2014 [C].
[6] KALCHBRENNER N, BLUNSOM P. Recurrent continuous translation models; proceedings of the Proceedings of the 2013 conference on empirical methods in natural language processing, F, 2013 [C].
[7] CHO K, VAN MERRIëNBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [J]. arXiv preprint arXiv:14061078, 2014.
[8] BAHDANAU D, CHO K, BENGIO Y. Neural machine translation by jointly learning to align and translate [J]. arXiv preprint arXiv:14090473, 2014.
[9] SUTSKEVER I, VINYALS O, LE Q V. Sequence to sequence learning with neural networks; proceedings of the Advances in neural information processing systems, F, 2014 [C].
[10] KLEIN G, KIM Y, DENG Y, et al. Opennmt: Open-source toolkit for neural machine translation [J]. arXiv preprint arXiv:170102810, 2017.
[11] PERIS Á, CASACUBERTA F. NMT-Keras: a very flexible toolkit with a focus on interactive NMT and online learning [J]. arXiv preprint arXiv:180703096, 2018.
[12] CREGO J, KIM J, KLEIN G, et al. Systran’s pure neural machine translation systems [J]. arXiv preprint arXiv:161005540, 2016.
[13] SCHMIDT T, MARG L. How to move to neural machine translation for enterprise-scale programs—an early adoption case study [J]. 2018.
[14] HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural computation, 1997, 9(8): 1735-80.
[15] HOCHREITER S, BENGIO Y, FRASCONI P, et al. Gradient flow in recurrent nets: the difficulty of learning long-term dependencies [Z]. A field guide to dynamical recurrent neural networks. IEEE Press. 2001
[16] SOUNTSOV P, SARAWAGI S. Length bias in encoder decoder models and a case for global conditioning [J]. arXiv preprint arXiv:160603402, 2016.
[17] POUGET-ABADIE J, BAHDANAU D, VAN MERRIENBOER B, et al. Overcoming the curse of sentence length for neural machine translation using automatic segmentation [J]. arXiv preprint arXiv:14091257, 2014.
[18] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need; proceedings of the Advances in neural information processing systems, F, 2017 [C].
※ 评 语 ※
本文摘自本学期人工神经网络课程学生提交的作业。这是一篇综述性的文章。作者阅读了18篇相关论文并对神经网络机器翻译与注意力机制问题进行了综述。这是作者提交的两片论文中的一篇。
● 相关图表链接:
以上是关于神经网络机器翻译与注意力机制的主要内容,如果未能解决你的问题,请参考以下文章