解读:小爱同学智能问答系统
Posted 卓寿杰SoulJoy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解读:小爱同学智能问答系统相关的知识,希望对你有一定的参考价值。
1. 基于检索匹配的问答
1.1 FAQ问答框架
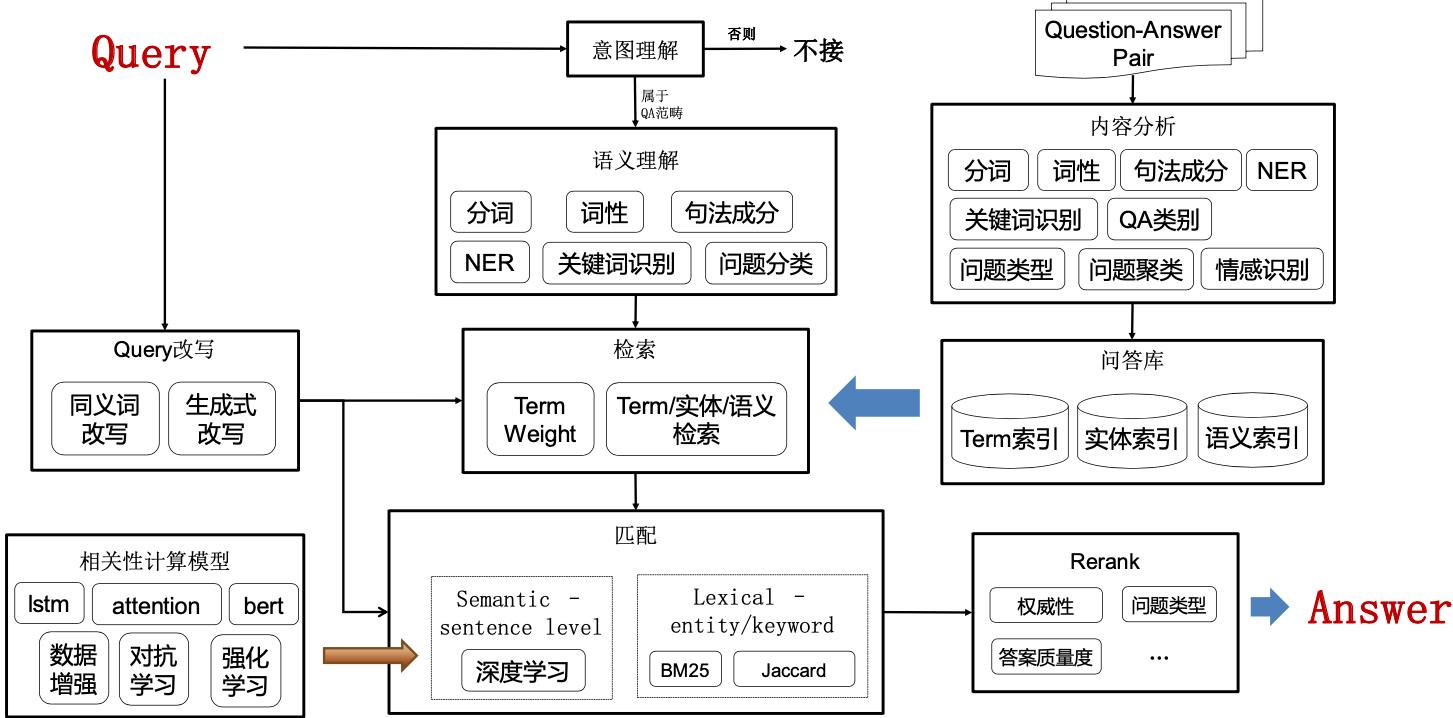
1.2 检索
检索召回分为以下三种方式:
- term检索
- 实体检索
- 语义检索
1.2.1 语义检索
学习得到每个doc的语义向量:
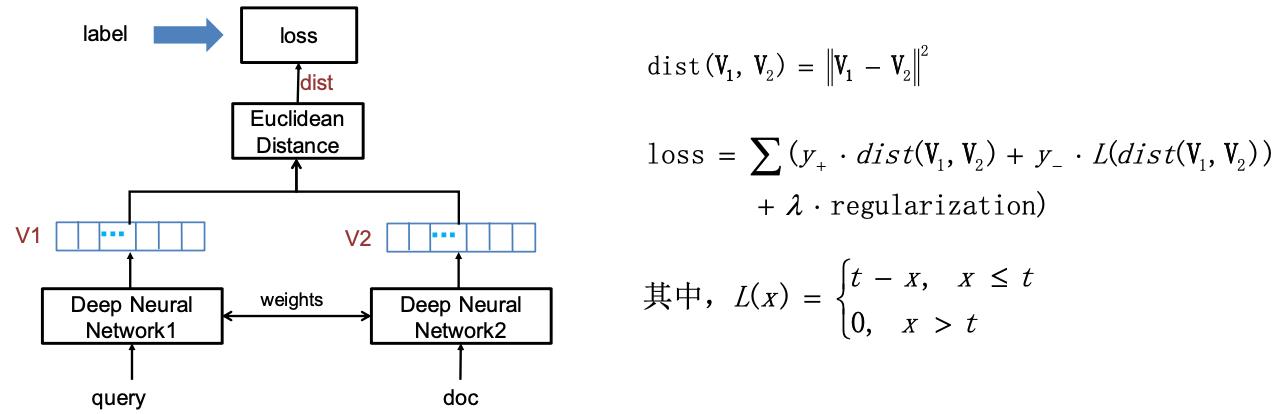
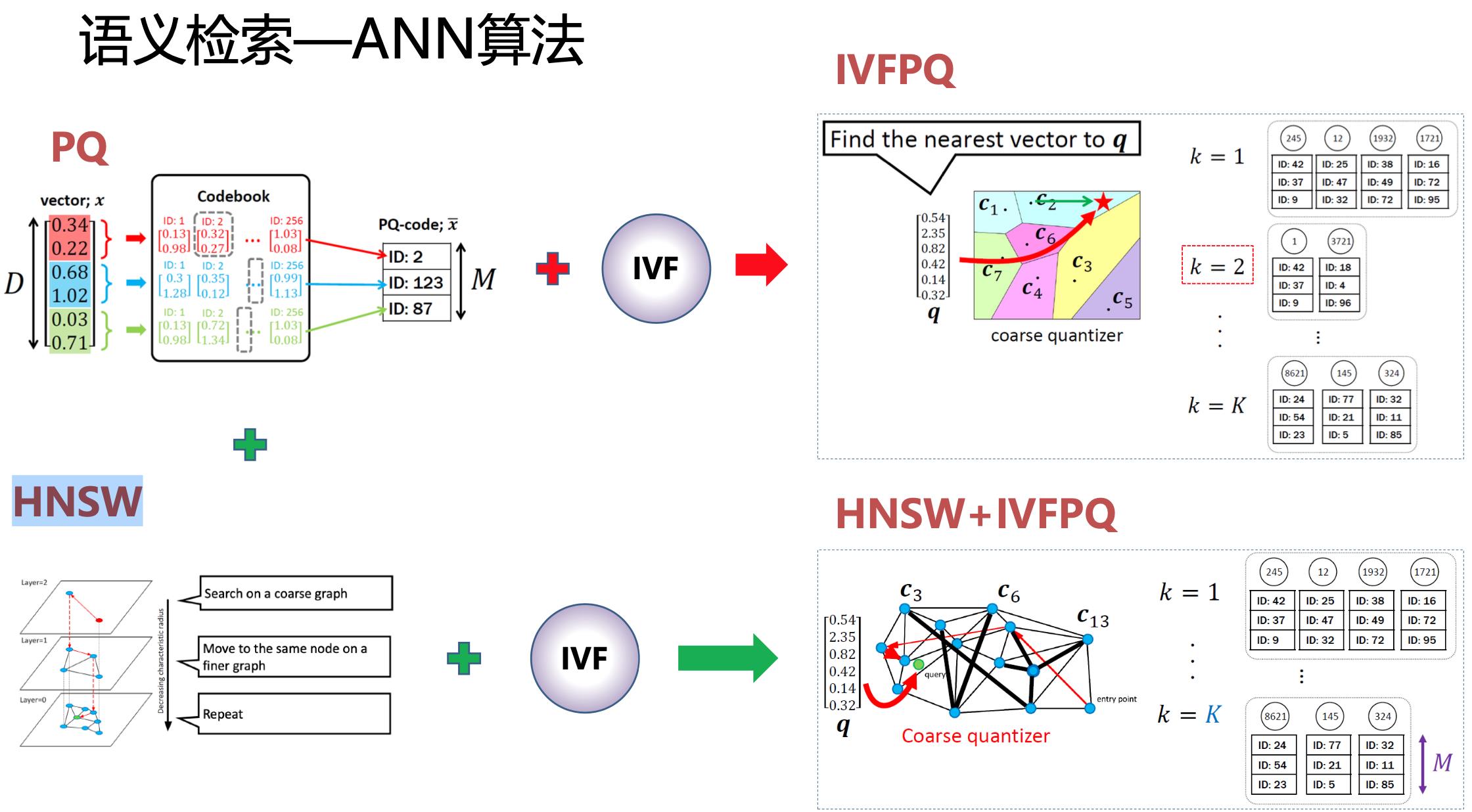
为每一个问题计算句子的语义向量,通过ANN算法进行检索:
1.2.2 词权重
- tf-idf
- 点击数据:根据Q=abc中a/b/c三个term在点击结果中的出现次数来计算;为了解决从未出现过的query没有点击数据的问题,把点击细化到ngram的粒度;
- 提取特征训练xgb模型

- 根据语境动态自适应的term weight。训练基于embedding的lstm网络,来动态计算每个term的词权重。
1.2.3 同义词挖掘
- 初始化种子数据(如:刘德华,华仔)
- 获取包含种子的句子集合(如:刘德华也被叫作华仔)
- 生成pattern
- 基于pattern集合获取更多的SPO数据(如:姚明也被叫作大姚)
- 将4的结果回灌1中,迭代整个流程
感觉该方案对数据要求很高。
1.2.4 生成式改写
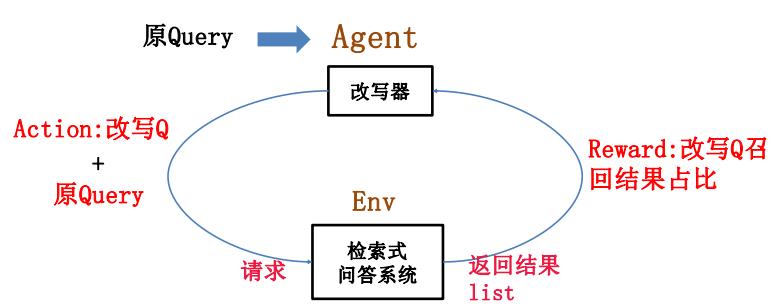
改写器:
- 利用人工标注数据预训练
- 利用线上未召回query进行强化学习训练
这里没有详细介绍。我理解改写器应该是一个GAN的框架。
1.3 匹配
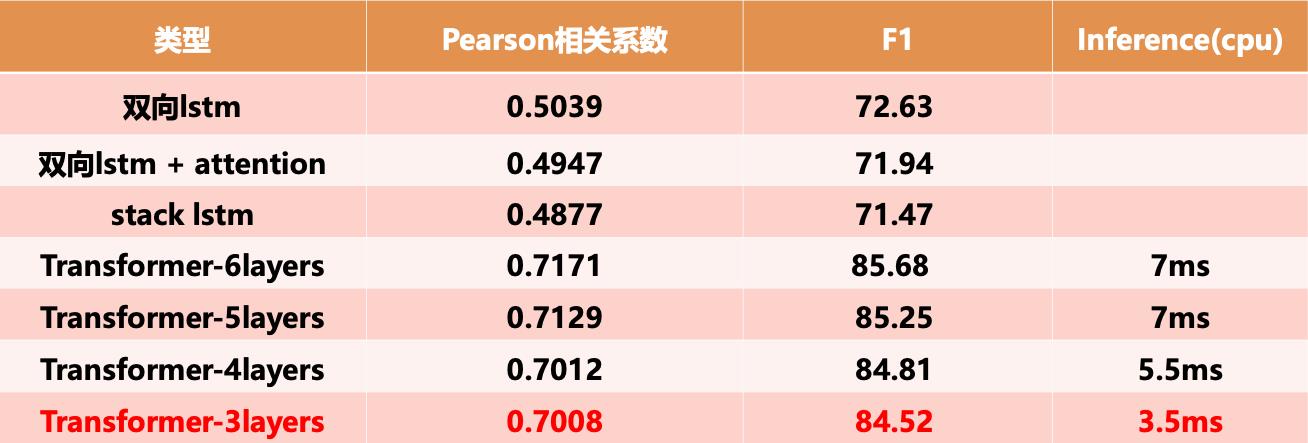
1.3.1 常用匹配模型
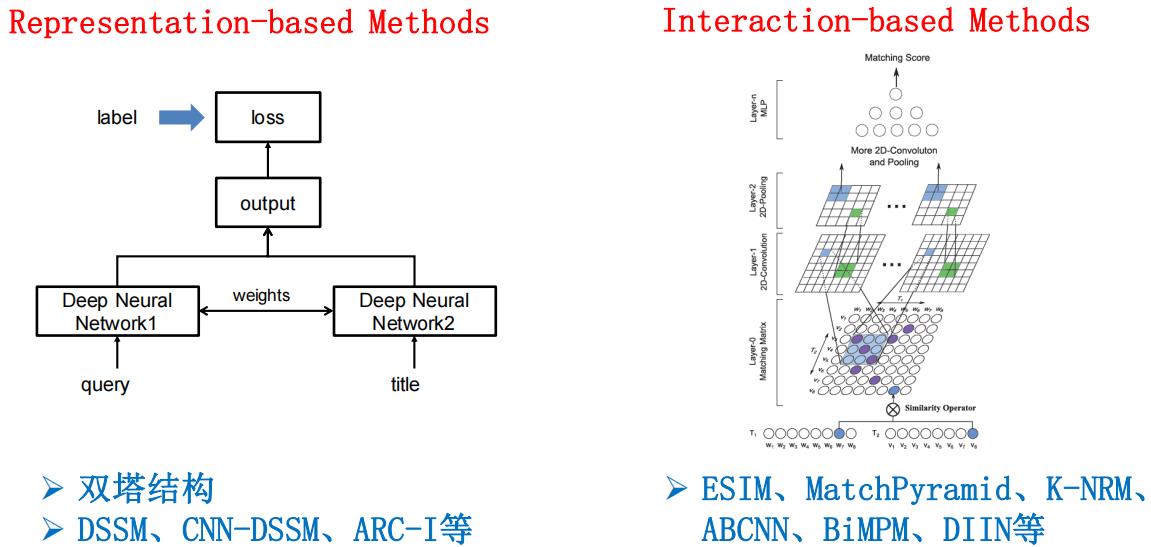
1.3.2 模型训练与数据增强

- 首先,基于用户行为日志的海量数据做粗训练(对抗学习生成的数据也应该是用于该阶段),这部分海量数据质量较低,噪音偏多。
- 然后,用高质的人工标注数据+数据增强做进一步的fine-tuning。
数据增强方案:
一对相似问Q1、Q2。
• 正样本:
找到Q1’,与Q1相似度 > 0.7
找到Q2’,与Q2相似度 > 0.7
增强结果,得到正样本:Q1’、Q2’
• 负样本:
找到Q1’,与Q1相似度 < 0.3
找到Q2’,与Q2相似度 < 0.3
增强结果,得到负样本:Q1’、Q2’
更多的特征
匹配模型可能会出现语义焦点,如下2对话:
“圆柱体的体积怎么算”- “圆柱体的面积怎么算”
“为什么宝宝总不听话”- “为什么狗狗总不听话”
模型可能判断其相似度比较高。
作者提出的方案是,新增一路抽取关键词后的two-sentence pair 送入预训练模型:
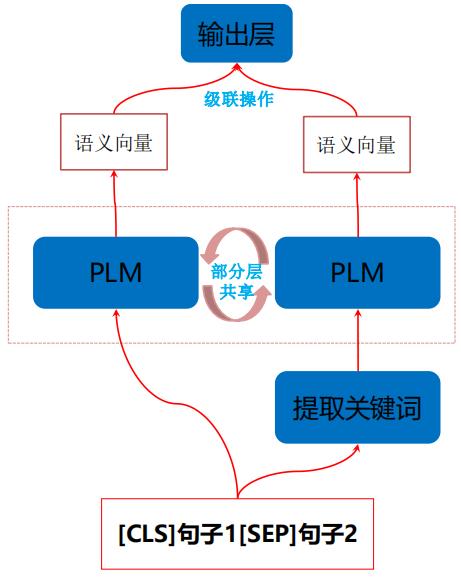
样本构造方法:

2. 基于知识图谱的问答
2.1 基于模板的方法
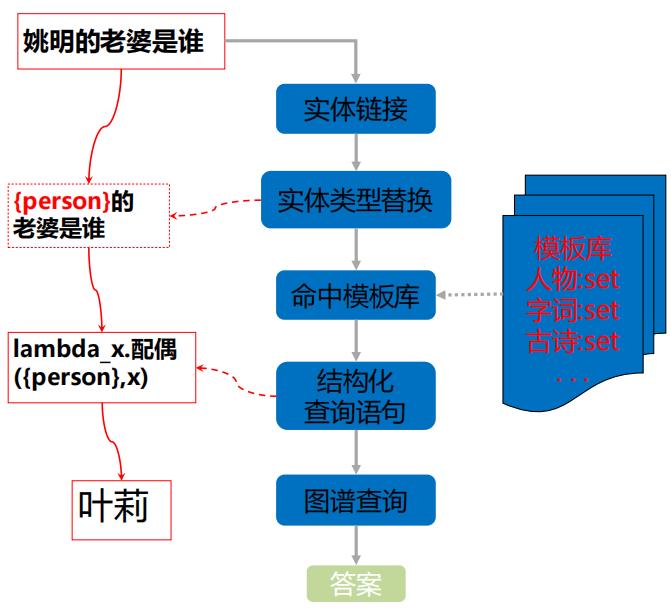
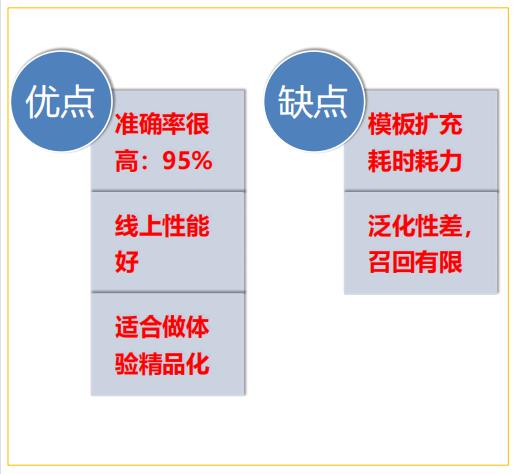
2.1.1 模板挖掘方法

作者基于结构化词条、问答论坛的数据,来进行模板挖掘的。如上图所示,结构化词条就可以看做是一个知识图谱。当问答论坛数据中,问题包含实体,答案包含属性值,就可以以此构造解析模板。如:

2.1.2 带约束的问答
上述挖掘的都是比较简单的模型。作者还构建了带约束的问答模板。如“世界之最”的问题。首先意图判断:query是否包含世界之最支持实体类型,以及是否包含最大、最小、第一、第二等触发词。然后进行结构化解析:
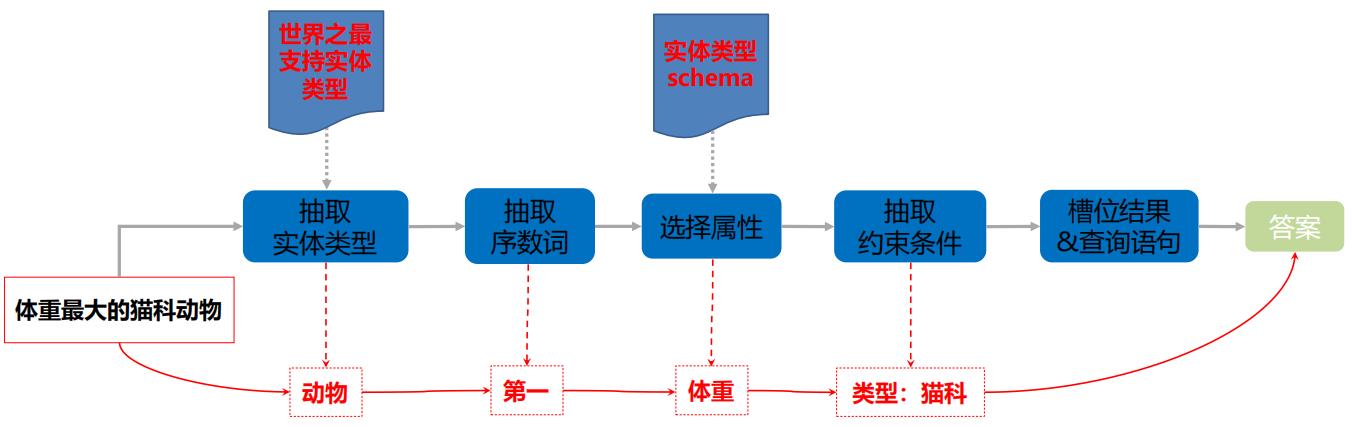
- 问题1. 属性归一化
解决方案:同义词、词向量、句对相似度匹配

问题2. 无属性
解决方案:对量词(大、长)设置一些默认排序的属性

2.2 跨垂域粗粒度的语义解析方法
模型是用比较基础的:
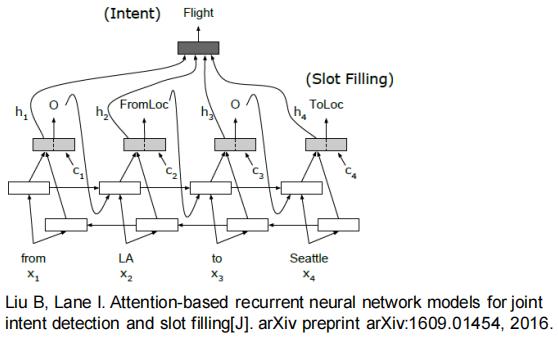
- 槽填充:通过NER方式提取槽位
- 意图识别:按文本分类方式识别query意图
- 多任务学习:将二者联合学习
- 后处理策略:根据领域词表对识别槽位进行纠错
主要创新思想是将不同意图下的槽位进行归并:
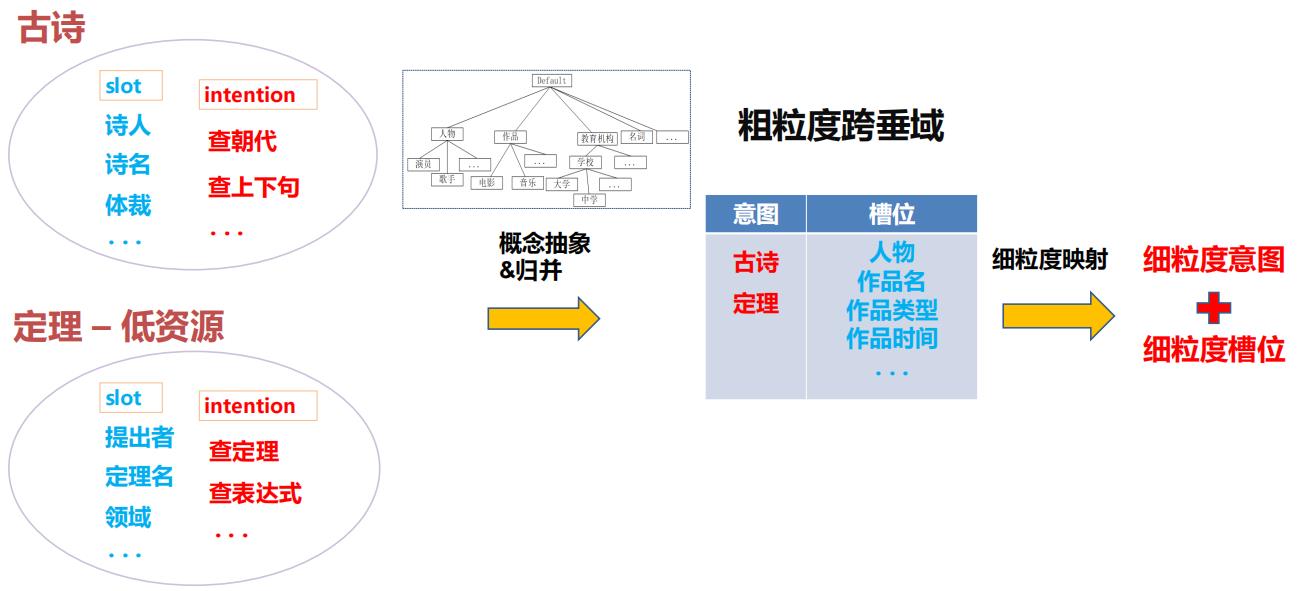
该方案可以缓解建设新垂类重复工作多、小垂类训练样本少的问题
2.3 基于路径匹配的方法
2.3.1 实体/属性值/数值抽取
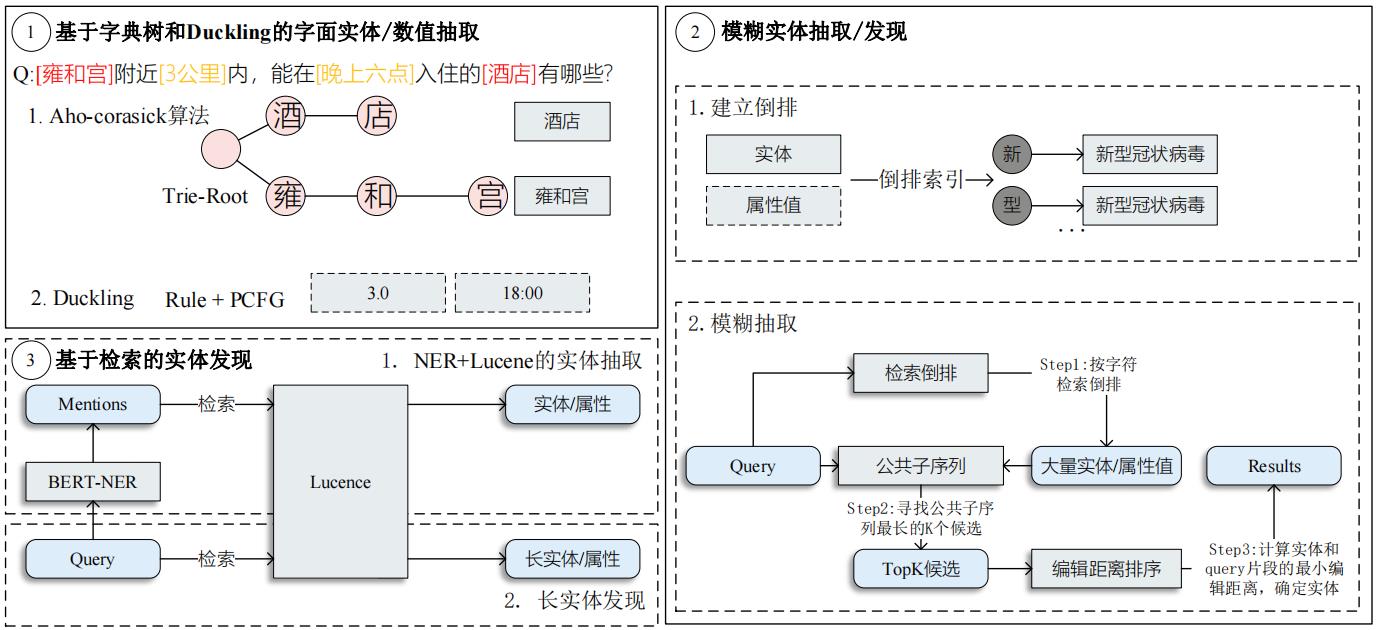
2.3.2 子图检索
2.3.2.1 子图模板
- 以单实体/多实体作为起点
- 按照预先定好的路径模板挖掘候选子图,如:

2.3.2.2 路径扩展&组合
- 路径扩展:
- 以Query中某个实体为出发节点,通过新增三元组来扩展路径
- 以当前路径的答案作为出发节点,通过三元组拼接路径
- 路径组合:
以答案作为合并节点来拼接路径
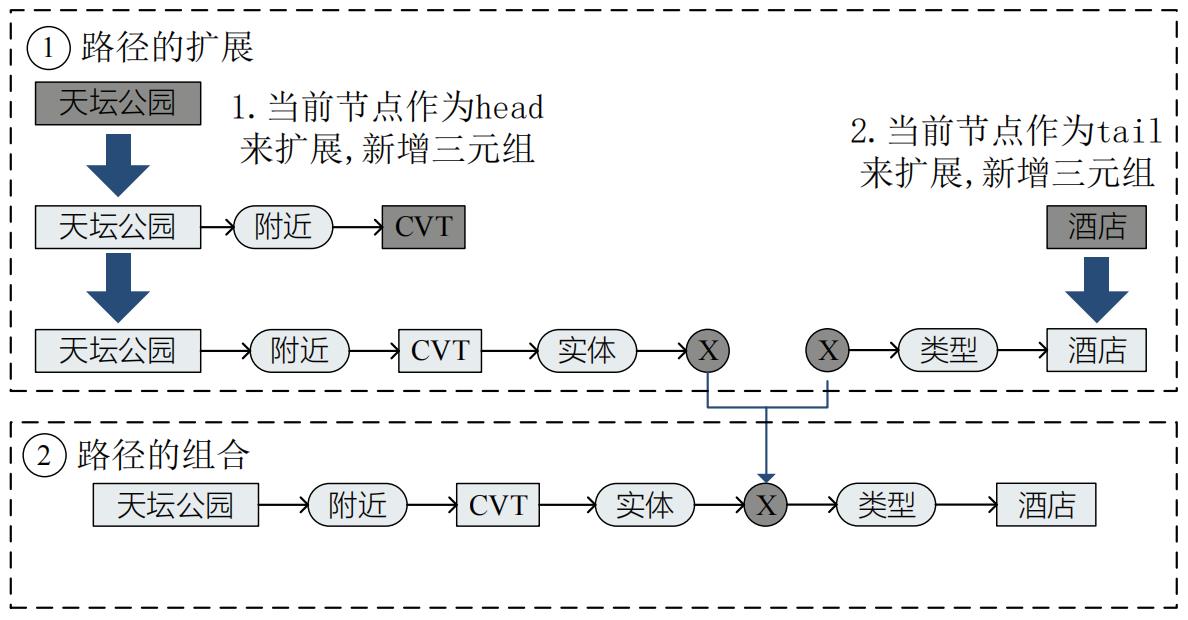
2.3.2.3 约束挂载
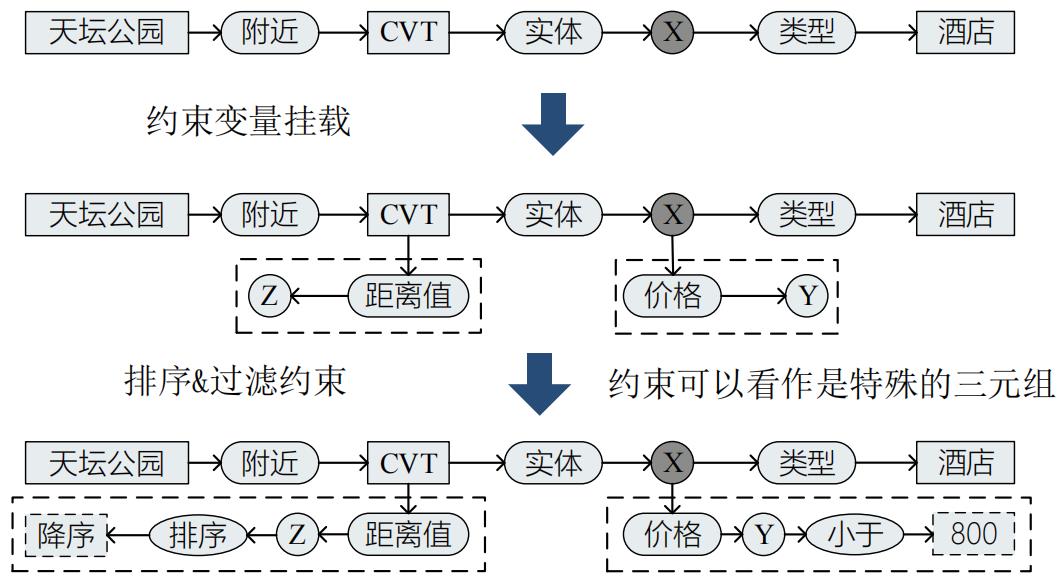
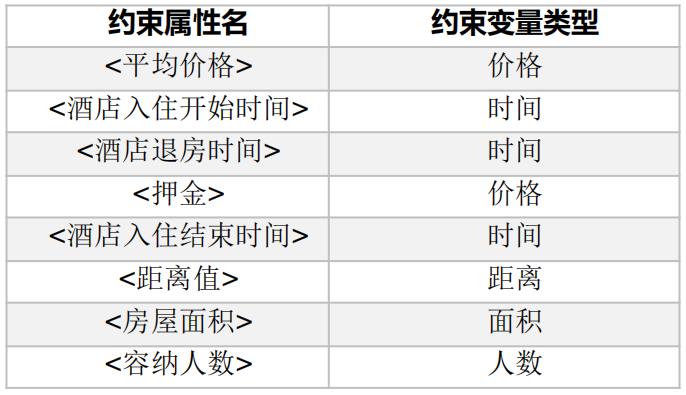
常见约束类型:
- 排序类型: 降序、升序
- 过滤类型: 大于、 小于、 等于、 大于等于、 小于等于
2.3.3 子图匹配
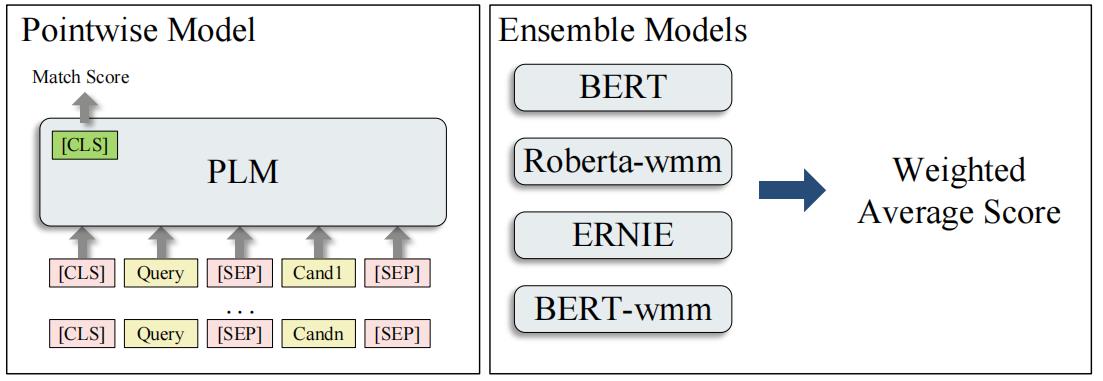
候选就是子图路径。路径表示方法:
作者实践发现以上几种方法效果差不多。。
模型可能对于某些类的预测比较差,而这些类在随机负采样中未能覆盖到。针对该问题,作者提出以下方案:
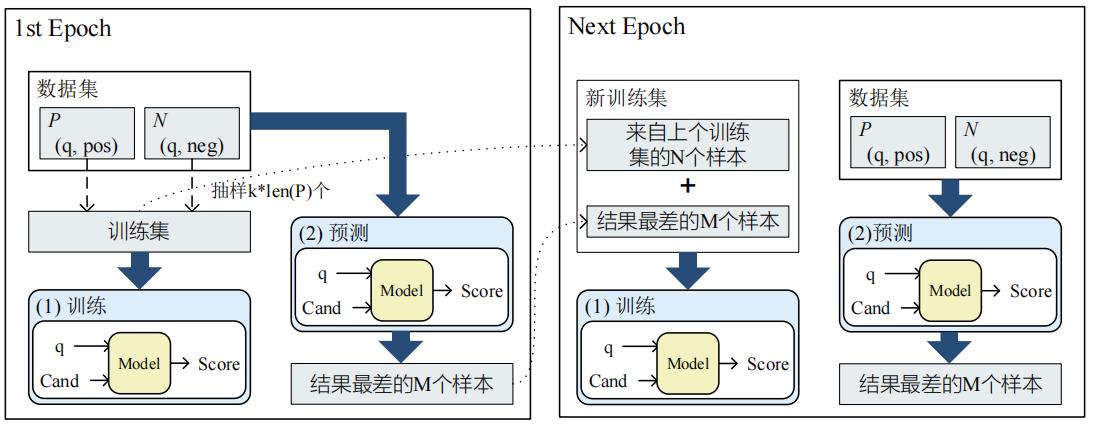
- 当前Epoch模型打分结果不理想的样本,加入到下一轮训练集中
- 为避免训练不稳定,需要抽样部分保留原有的样本
以上是关于解读:小爱同学智能问答系统的主要内容,如果未能解决你的问题,请参考以下文章