LeetCode 解题笔记(C++每日一题)
Posted 火山上的企鹅
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LeetCode 解题笔记(C++每日一题)相关的知识,希望对你有一定的参考价值。
文章目录
- 一、常用技巧
- 二 、常用翻译
- 三、题目
- 1. 数组
- x. 其他
- 17. 电话号码的字母组合--2022/01/15
- 20. 有效的括号--2021/12/06
- 21. 合并两个有序链表--2021/12/08
- 53. 最大子序和--2021/12/07
- 55. 跳跃游戏--2021/12/05
- 70. 爬楼梯--2021/12/10
- 121. 买卖股票的最佳时机--2021/12/13
- 141. 环形链表--2021/12/16
- 169. 多数元素--2021/12/17
- 283. 移动零--2021/12/12
- 461. 汉明距离--2021/12/15
- 448. 找到所有数组中消失的数字--2021/12/11
- 1636. 按照频率将数组升序排序--2021/12/4
● 建议:
1、不会的,没有头绪的,先学习答案,有些方法你脑海中都没有,如何又能想到呢?先学习答案吧
2、暴力解法也是解,先出答案再考虑时间复杂度和空间复杂度
3、选择题目,除了在难度上要循序渐进,还建议在算法上进行划分。目前先刷个100题再说
4、同一类型,批量答题,将有助于系统性的学习!
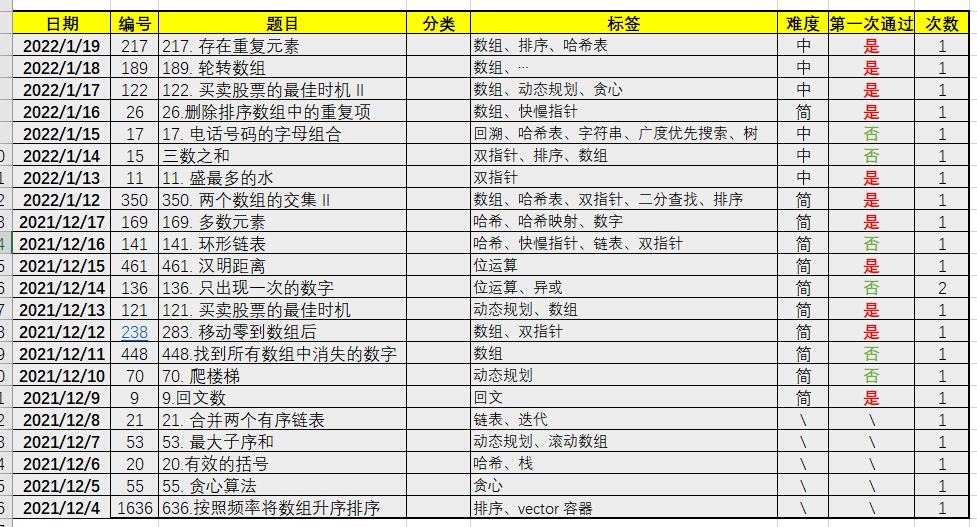
● 刷题记录
01月19日 更新
一、常用技巧
● 字符串长度或大小:
s.length();
s.size();
● 反转一个数的技巧
resverdNum = resverdNum *10 + x%10;
x/= 10;
● 指针对应的空位 nullptr
if(digits.empty()) return vector<string>();
● ++写在前面
++i:
● range-based for:
string s1 = "123456";
for (auto i : s1 ) //普通方式改变访问
i ++; //改变字符串的每个字符, 不会改变整个字符串s1(123456)
for(const auto& i : s3) //常引用方式访问元素,避免拷贝代价 s1(123456)
// i ++; //报错
for (auto& i : s2 ) //引用方式访问元素
i ++; //改变字符串的每个字符, 使用引用会改变整个字符串s1(234567)
● vector 相关,(代替数组)
int maxArea(vector<int>& height) int n = height.size() //取大小
vector<int>v(201, 0); //用于存储nums数组中元素的重复次数
vector<int>vret; //用于返回最终结果vret
vret.push_back(3); //在vret中数组最后插入3
vert.pop_back(); //在vret中最后去掉一个数
void threeSum(vector<int>& nums)
vector<vector<int>> ans; //二维数组
ans.push_back( nums[i], nums[j], nums[k]; //二维数组添加
...
//没有指定 vector 的大小,不能在中间直接插入数据的!
● 普通数组
//初始化
int[] array= new int[5];
● 直接调用函数:交换、快速排序
swap(x,y); //值交换直接调用
void fun(vector<int>& nums)
std::sort(nums.begin(), nums,end()) //快速排序
...
● 无穷大的数
int inf = 1e9; //1e9 表示一个大数,记为无穷大
● map、unordered_map、set、unordered_set
其中 unordered_map、unordered_set 用的太多了!
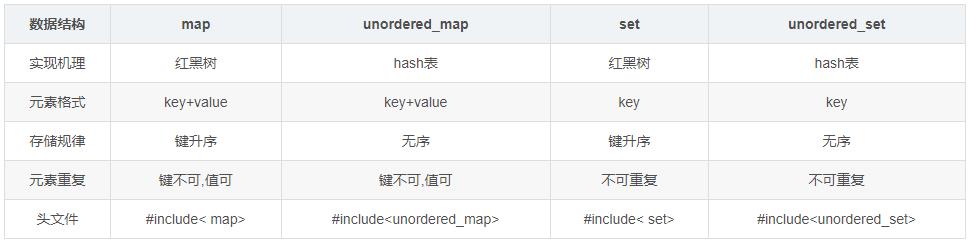
参考:map,unordered_map,set和unordered_set
● map
优点:有序性,这是map结构最大的优点(map 内部实现了一个 红黑树)
缺点:空间占用率高,因为map内部实现了红黑树,虽然提高了运行效率(低于unorder_map),但是因为每一个节点都需要额外保存父节点、孩子节点和红/黑性质,使得每一个节点都占用大量的空间(但占用的内存比unorder_map低)
适用处:对于那些数据存储有顺序要求的问题,用map会更高效一些
实例:
vector<int> list = 5,14,34,22,39,5;
map<int, int> map;
for (int i = list.size() - 1; i >= 0; i--)
map[i] = list[i]; //倒序插入
for (auto num = map.begin(); num != map.end(); num ++)
cout << num->first << ' ' << num->second << endl; //输出的数是有序的且有两个
//打印:
//0 5
//1 14
//2 34
//3 22
//4 39
//5 5
//find()和count()的输入参数都是key值
cout << map.find(3)->first << "," << map.find(3)->second; //3,22
//m.count(n)计算下标为n的位置有无数据,有返回1,无返回0
cout << map.count(5); // 1
参考:https://blog.csdn.net/bryant_zhang/article/details/111600209
● unordered_map(无序的映射 )
优点: 因为内部实现了哈希表,因此,其元素的排列顺序是无序的。因此其查找速度非常的快(运行效率快于map),时间复杂度可达到O(1),其在海量数据处理中有着广泛应用
缺点: 哈希表的建立比较耗费时间(unorder_map占用的内存比map要高)
适用处:对于查找问题,unordered_map会更加高效一些,因此遇到查找问题,常会考虑一下用 unordered_map
vector<int> list = 5,14,34,22,39,5;
unordered_map<int, int> map;
for (int i = list.size()-1; i>=0; i--)
map[i] = list[i]; //倒序插入
for (unordered_map<int, int>::iterator i = map.begin(); i != map.end(); i++) //auto 更好
cout << i->first << ' ' << i->second << endl; //输出的数是有序的且有两个
/*打印:unordered_map 是基于hash表的,因此元素是无序存储的( 不按键 升序排列)。
5 5
4 39
3 22
2 34
1 14
0 5
*/
//find()和count()的输入参数都是key值
cout << map.find(3)->first << "," << map.find(3)->second; //3,22
//m.count(n)计算下标为n的位置有无数据,有返回1,无返回0
cout << map.count(5); // 1
//删除下标为 5 的位置
cout << map.erase(5);
实例2:
leetcode :169. 多数元素
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数 大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
class Solution
public:
int majorityElement(vector<int>& nums)
//哈希, 不用数组因为是不知道有多大;对于乱序问题、查找问题,适用于 unordered_map
unordered_map<int,int> seen;
int n = nums.size();
int majority = 0;
for(auto const & num : nums)
seen[num]++;
if(seen[num] > n/2)
majority = num;
return majority;
;
实例3: 17. 电话号码的字母组合
unordered_map<char, string> phoneMap
'2', "abc",
'3', "def",
'4', "ghi",
'5', "jkl",
'6', "mno",
'7', "pqrs",
'8', "tuv",
'9', "wxyz"
;
● set
set 实现了红黑树的平衡二叉检索树的数据结构,插入元素时,它会自动调整二叉树的排列,把元素放到适当的位置,以保证每个子树根节点键值大于左子树所有节点的键值,小于右子树所有节点的键值;另外,还得保证根节点左子树的高度与右子树高度相等。**在set中每个元素的值都唯一,而且系统能根据元素的值自动进行排序。**平衡二叉检索树使用中序遍历算法,检索效率高于vector、deque和list等容器,另外使用中序遍历可将键值按照从小到大遍历出来。
实例1
vector<int> list = 5,14,34,22,39,5 ;
set<int> set1;
for (int i = list.size() - 1; i >= 0; i--)
set1.insert(list[i]); //倒序插入
for (auto num = set1.begin(); num != set1.end(); num ++)
cout << *num << endl; //输出的数是有序的且只有一个5
/*打印结果* set 是基于RBT的,因此元素是顺序存储的(默认按 键值 升序排列)。
5
14
22
34
39 */
cout << *set1.find(5) << endl; //5
cout << set1.count(5) << endl; //1
● STL 容器: unordered_set
unordered_set的内部实现了一个 哈希表,因此, 其元素的排列顺序是无序的。
实例1:
//#include <unordered_set>
vector<int> list = 5,14,34,22,39,5 ;
unordered_set<int> set;
for (int i = list.size() - 1; i >= 0; i--)
set.insert(list[i]); //倒序插入
for (unordered_set<int>::iterator num = set.begin(); num != set.end(); num ++)
cout << *num << endl; //输出的数是无序的且只有一个5
/*打印结果: unordered_set是基于hash表的,因此元素是无序存储的( 不按键值 升序排列)。
5
39
14
22
34 */
cout << *set.find(39) << endl; //39
cout << set.count(14) << endl; //1
实例2:
//初始化一个结构体
unordered_set<ListNode *> seen;
//判断是否包含某一个元素
seen.count(head);
//添加一个元素
seen.insert(head);
实例三: 217.存在重复元素
class Solution
public:
bool containsDuplicate(vector<int>& nums)
unordered_set<int> s;
for (int x: nums)
if (s.find(x) != s.end())
return true;
s.insert(x);
return false;
;
二 、常用翻译
revertedNum //回收的数
merge // 合并
frequency //频率
三、题目
1. 数组
26.删除排序数组中的重复–2022/01/16
链接: 26.删除有序数组中的重复项
题目: 简单

标签: 数组、快慢指针
题解: 逆向思维!判断每一个不相等的数,并计数,答案就出来了!!!
class Solution
public:
int removeDuplicates(vector<int>& nums)
if(nums.size() <=0 )
return 0;
int c = 0;
nums[c++] = nums[0];
for(int i=1; i<nums.size(); i++)
if(nums[i] != nums[i-1])
nums[c++] = nums[i];
return c;
;
官方
思路: 快慢指针
定义两个指针 fast 和 slow 分别为快指针和慢指针,快指针表示遍历数组到达的下标位置,慢指针表示下一个不同元素要填入的下标位置,初始时两个指针都指向下标 1。
class Solution
public:
int removeDuplicates(vector<int>& nums)
int n = nums.size();
if (n == 0)
return 0;
int fast = 1, slow = 1;
while (fast < n)
if (nums[fast] != nums[fast - 1])
nums[slow] = nums[fast];
++slow;
++fast;
return slow;
;
122. 买卖股票的最佳时机 II–2022/01/17
题目: 中等

**标签:**数组、动态规划、贪心
我的答案:
思路:暴力解法,考虑边界条件,然后试错得出,效果还行:
class Solution
public:
int maxProfit(vector<int>& prices)
int minp = prices[0], maxp= 0;
int sum = 0, n=prices.size();
for(int i=1; i<n; i++)
if(prices[i] <= prices[i-1])
if(maxp)
sum += maxp - minp; //存在了最大利润了,并且这次又是新的最小值买入时机
maxp = 0;
minp = prices[i]; //最小值买入时机
else
maxp = prices[i]; //保存当前的最大利润
// minp = prices[i-1]; //不需要的,试错出来的
if(i == n-1)
sum += maxp - minp; //最大值结束的话,得计算一遍
return sum;
;
时间复杂度:O(n),其中 n 为数组的长度。我们只需要遍历一次数组即可。
空间复杂度:O(1),只需要常数空间存放若干变量。
参考答案:
看动态规划比较累,看这个贪心太舒服了:

class Solution
public:
int maxProfit(vector<int>& prices)
int res = 0;
for(int i = 0; i < prices.size() - 1; i++)
if(prices[i + 1] > prices[i])
res += prices[i + 1] - prices[i];
return res;
;
189. 轮转数组–2022/01/18
链接:189. 轮转数组
题目: 中等

标签: 数组
我的答案: 最容易想到的:建立个临时的数组
class Solution
public:
void rotate(vector<int>& nums, int k)
if(nums.size() == 0) return;
int n= nums.size();
vector<int> tmp ; // vector<int> tmp = 0; 这样初始化就已经添加了一个值
for(const auto& num: nums)
tmp.push_back(num);
for(int i=0; i<n; i++)
nums[(i+k)%n] = tmp[i];
;
官方:若干答案,后续补充…
217. 存在重复元素–2022/01/19
链接:217. 存在重复元素
标签: 数组、排序、哈希表
以上是关于LeetCode 解题笔记(C++每日一题)的主要内容,如果未能解决你的问题,请参考以下文章