Java Review - 并发编程_伪共享
Posted 小小工匠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java Review - 并发编程_伪共享相关的知识,希望对你有一定的参考价值。
文章目录

what’s 伪共享
为了解决计算机系统中主内存与CPU之间运行速度差问题,会在CPU与主内存之间添加一级或者多级高速缓冲存储器(Cache)。这个Cache一般是被集成到CPU内部的,所以也叫 CPU Cache .
下图所示是两级Cache结构
在Cache内部是按行存储的,其中每一行称为一个Cache行。Cache行(如下图所示)是Cache与主内存进行数据交换的单位,Cache行的大小一般为2的幂次数字节。
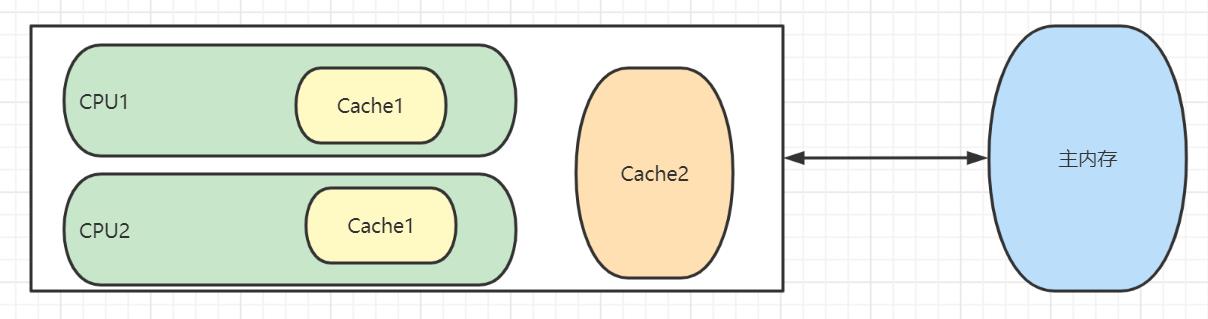
当CPU访问某个变量时,首先会去看CPU Cache内是否有该变量,如果有则直接从中获取,否则就去主内存里面获取该变量,然后把该变量所在内存区域的一个Cache行大小的内存复制到Cache中。
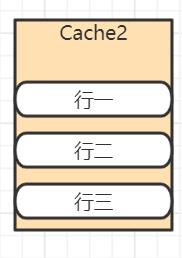
由于存放到Cache行的是内存块而不是单个变量,所以可能会把多个变量存放到一个Cache行中。当多个线程同时修改一个缓存行里面的多个变量时,由于同时只能有一个线程操作缓存行,所以相比将每个变量放到一个缓存行,性能会有所下降,这就是伪共享 .
如下所示。
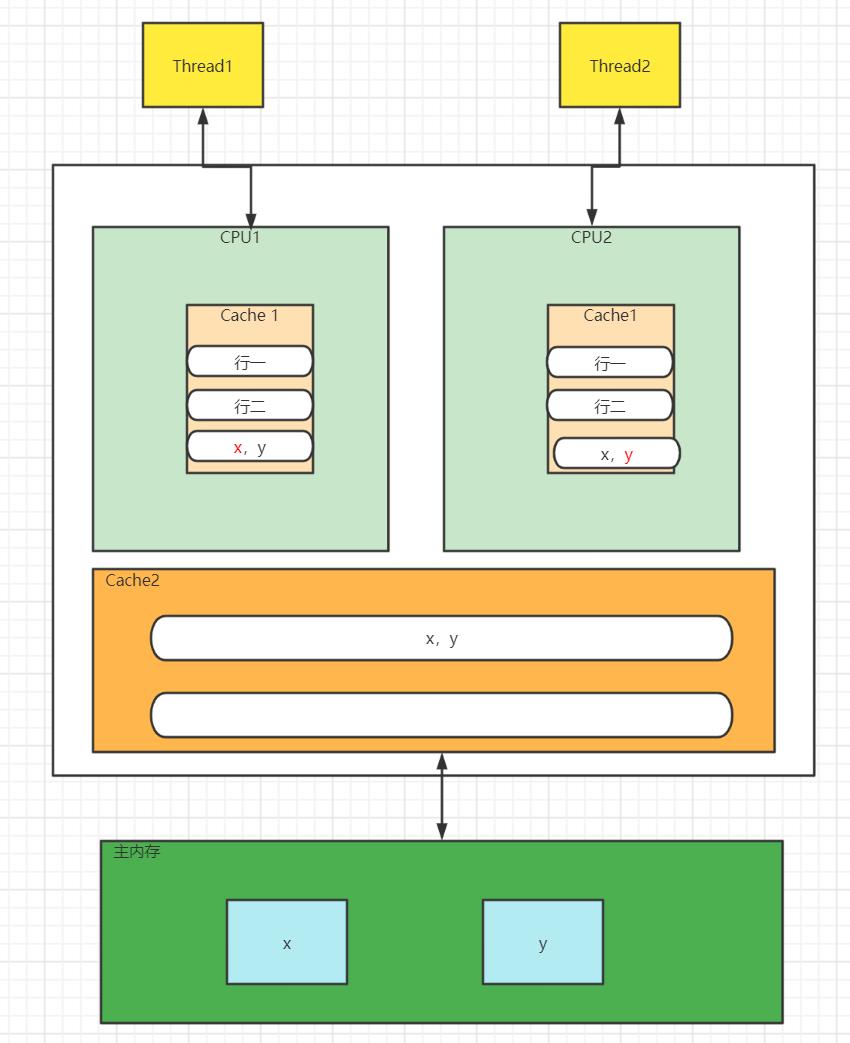
变量x和y同时被放到了CPU的一级和二级缓存,当线程1使用CPU1对变量x进行更新时,首先会修改CPU1的一级缓存变量x所在的缓存行,这时候在缓存一致性协议下,CPU2中变量x对应的缓存行失效。
那么线程2在写入变量x时就只能去二级缓存里查找,这就破坏了一级缓存。而一级缓存比二级缓存更快,这也说明了多个线程不可能同时去修改自己所使用的CPU中相同缓存行里面的变量。更坏的情况是,如果CPU只有一级缓存,则会导致频繁地访问主内存。

为何会出现伪共享
伪共享的产生是因为多个变量被放入了一个缓存行中,并且多个线程同时去写入缓存行中不同的变量。
那么为何多个变量会被放入一个缓存行呢?其实是因为缓存与内存交换数据的单位就是缓存行,当CPU要访问的变量没有在缓存中找到时,根据程序运行的局部性原理,会把该变量所在内存中大小为缓存行的内存放入缓存行。
long a ;
long b ;
long c ;
long d ;
如上代码声明了四个long变量,假设缓存行的大小为32字节,那么当CPU访问变量a时,发现该变量没有在缓存中,就会去主内存把变量a以及内存地址附近的b、c、d放入缓存行。也就是地址连续的多个变量才有可能会被放到一个缓存行中。
当创建数组时,数组里面的多个元素就会被放入同一个缓存行。那么在单线程下多个变量被放入同一个缓存行对性能有影响吗?其实在正常情况下单线程访问时将数组元素放入一个或者多个缓存行对代码执行是有利的,因为数据都在缓存中,代码执行会更快。
来看个代码
【Code1】
/**
* @author 小工匠
* @version 1.0
* @description: TODO
* @date 2021/11/28 21:44
* @mark: show me the code , change the world
*/
public class TestWGX
static final int LINE_NUM = 1024;
static final int COLUM_NUM = 1024;
public static void main(String[] args)
long[][] array = new long[LINE_NUM][COLUM_NUM];
long startTime = System.currentTimeMillis();
for (int i = 0; i < LINE_NUM; ++i)
for (int j = 0; j < COLUM_NUM; ++j)
array[i][j] = i * 2 + j;
long endTime = System.currentTimeMillis();
long cacheTime = endTime - startTime;
System.out.println("cache time:" + cacheTime);
【Code2】
/**
* @author 小工匠
* @version 1.0
* @description: TODO
* @date 2021/11/28 22:05
* @mark: show me the code , change the world
*/
public class TestWGX2
static final int LINE_NUM = 1024;
static final int COLUM_NUM = 1024;
public static void main(String[] args)
long[][] array = new long[LINE_NUM][COLUM_NUM];
long startTime = System.currentTimeMillis();
for (int i = 0; i < COLUM_NUM; ++i)
for (int j = 0; j < LINE_NUM; ++j)
array[j][i] = i * 2 + j;
long endTime = System.currentTimeMillis();
System.out.println("no cache time:" + (endTime - startTime));
Code1 5ms以内
Code2 5ms以上
代码(1)比代码(2)执行得快,这是因为数组内数组元素的内存地址是连续的,当访问数组第一个元素时,会把第一个元素后的若干元素一块放入缓存行,这样顺序访问数组元素时会在缓存中直接命中,因而就不会去主内存读取了,后续访问也是这样。
也就是说,当顺序访问数组里面元素时,如果当前元素在缓存没有命中,那么会从主内存一下子读取后续若干个元素到缓存,也就是一次内存访问可以让后面多次访问直接在缓存中命中。而代码(2)是跳跃式访问数组元素的,不是顺序的,这破坏了程序访问的局部性原则,并且缓存是有容量控制的,当缓存满了时会根据一定淘汰算法替换缓存行,这会导致从内存置换过来的缓存行的元素还没等到被读取就被替换掉了。
所以在单个线程下顺序修改一个缓存行中的多个变量,会充分利用程序运行的局部性原则,从而加速了程序的运行。而在多线程下并发修改一个缓存行中的多个变量时就会竞争缓存行,从而降低程序运行性能。

如何避免伪共享
在JDK 8之前一般都是通过字节填充的方式来避免该问题,也就是创建一个变量时使用填充字段填充该变量所在的缓存行,这样就避免了将多个变量存放在同一个缓存行中。
public final static class FilledLong
public volatile long value = 0L;
public long p1, p2, p3, p4, p5, p6;
假如缓存行为64字节,那么我们在FilledLong类里面填充了6个long类型的变量,每个long类型变量占用8字节,加上value变量的8字节总共56字节。另外,这里FilledLong是一个类对象,而类对象的字节码的对象头占用8字节,所以一个FilledLong对象实际会占用64字节的内存,这正好可以放入一个缓存行。
JDK 8提供了一个sun.misc.Contended注解,用来解决伪共享问题。将上面代码修改为如下。
@sun.misc.Contended
public final static class FilledLong
public volatile long value = 0L;
在这里注解用来修饰类,当然也可以修饰变量,比如在Thread类中。
/** The current seed for a ThreadLocalRandom */
@sun.misc.Contended("tlr")
long threadLocalRandomSeed;
/** Probe hash value; nonzero if threadLocalRandomSeed initialized */
@sun.misc.Contended("tlr")
int threadLocalRandomProbe;
/** Secondary seed isolated from public ThreadLocalRandom sequence */
@sun.misc.Contended("tlr")
int threadLocalRandomSecondarySeed;
Thread类里面这三个变量默认被初始化为0,这三个变量会在ThreadLocalRandom类中使用,后面章节会专门讲解ThreadLocalRandom的实现原理。
在默认情况下,@Contended注解只用于Java核心类,比如rt包下的类。如果用户类路径下的类需要使用这个注解,则需要添加JVM参数:-XX:-RestrictContended。填充的宽度默认为128,要自定义宽度则可以设置-XX:ContendedPaddingWidth参数。
小结
我们这里主要讲述了伪共享是如何产生的,以及如何避免,并证明在多线程下访问同一个缓存行的多个变量时才会出现伪共享,在单线程下访问一个缓存行里面的多个变量反而会对程序运行起到加速作用。理解这些知识有助于理解LongAdder的实现原理。

以上是关于Java Review - 并发编程_伪共享的主要内容,如果未能解决你的问题,请参考以下文章