一文了解循环神经网络
Posted 无乎648
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文了解循环神经网络相关的知识,希望对你有一定的参考价值。
循环神经网络
一、什么是循环神经网络:
循环神经网络(Rerrent Neural Network, RNN),是神经网络的一种,类似的还有深度神经网络DNN,卷积神经网络CNN,生成对抗网络GAN。RNN的特点是对具有序列特性的数据非常有效,它能挖掘数据中的时序信息以及语义信息,利用了RNN的这种能力,使深度学习模型在解决语音识别、语言模型、机器翻译以及时序分析等NLP领域的问题时有所突破。
对于序列特性,我个人理解,就是符合时间顺序,逻辑顺序,或者其他顺序就叫序列特性,举几个例子:
- 拿人类的某句话来说,也就是人类的自然语言,是不是符合某个逻辑或规则的字词拼凑排列起来的,这就是符合序列特性。
- 语音,我们发出的声音,每一帧每一帧的衔接起来,才凑成了我们听到的话,这也具有序列特性、
- 股票,随着时间的推移,会产生具有顺序的一系列数字,这些数字也是具有序列特性。
序列数据是常见的数据类型,前后数据通常具有关联性
例如句子“cats average 15 hours of sleep a day”

二、为什么要发明循环神经网络:
举个例子,现在有两句话:
第一句话:I like eating apple!(我喜欢吃苹果!)
第二句话:The Apple is a great company!(苹果真是一家很棒的公司!)
现在的任务是要给apple打Label,我们都知道第一个apple是一种水果,第二个apple是苹果公司,假设我们现在有大量的已经标记好的数据以供训练模型,当我们使用全连接的神经网络时,我们做法是把apple这个单词的特征向量输入到我们的模型中(如下图),在输出结果时,让我们的label里,正确的label概率最大,来训练模型,但我们的语料库中,有的apple的label是水果,有的label是公司,这将导致,模型在训练的过程中,预测的准确程度,取决于训练集中哪个label多一些,这样的模型对于我们来说完全没有作用。问题就出在了我们没有结合上下文去训练模型,而是单独的在训练apple这个单词的label,这也是全连接神经网络模型所不能做到的,于是就有了我们的循环神经网络。

NLP中常把文本看为离散时间序列,一段长度为T的文本的词依次为w1, W 2, … , WT其中 wt(1 ≤ t ≤T)是时间步(Time step) t的输出或标签
语言模型将会计算该序列概率P(W 1 , w2 ,… , WT)
“Cats average 15 hours of sleep a da y”
八个单词==>T=8
列如: chu fang li de shi you yong wan le
p(厨,房,里,的,食,油,用,完,了)>p(厨,房,里,的,石,油,用,完,了)
语言模型计算序列概率:
P
(
w
1
,
w
2
,
.
.
.
,
w
T
)
=
1
P
(
w
t
∣
w
1
,
.
.
.
,
w
t
1
)
.
P(w1 , w2, . . . , wT)=1P(wt | w1, .. . , wt_1 ).
P(w1,w2,...,wT)=1P(wt∣w1,...,wt1).
P
(
我
,
在
,
听
,
课
)
=
P
(
我
)
∗
P
(
在
│
我
)
∗
P
(
听
│
我
,
在
)
∗
P
(
听
│
我
,
在
,
听
)
P(我,在,听,课)=P(我)*P(在│我)*P(听│我,在)*P(听│我,在,听)
P(我,在,听,课)=P(我)∗P(在│我)∗P(听│我,在)∗P(听│我,在,听)
统计语料库(Corpus)中的词频,得到以上概率,最终得到P(我,在,听,课)
缺点:时间步t的词需要考虑t-1步的词,其计算量随t呈指数增长
3、 三种循环神经网络结构:
循环神经网络中一些重要的设计模式包括以下几种:
-
每个时间步都有输出,并且隐藏单元之间有循环连接的循环网络。

任何图灵可计算的函数都可以通过这样一个有限维的循环网络计算,在这个意义上的循环神经网络是万能的。RNN 经过若干时间步后读取输出,这与由图灵机所用的时间步是渐近线性的,与输入长度也是渐近线性的。由图灵机计算的函数是离散的,所以这些结果都是函数的具体实现,而不是近似。RNN 作为图灵机使用时,需要一个二进制序列作为输入,其输出必须离散化以提供二进制输出。利用单个有限大小的特定 RNN 计算在此设置下的所有函数是可能的。图灵机的‘‘输入’’ 是要计算函数的详细说明 ,所以模拟此图灵机的相同网络足以应付所有问题。用于证明的理论 RNN 可以通过激活和权重(由无限精度的有理数表示)来模拟无限堆栈。
现在我们研究图 10.3 中 RNN 的前向传播公式。这个图没有指定隐藏单元的激活函数。我们假设使用双曲正切激活函数。此外,图中没有明确指定何种形式的输出和损失函数。我们假定输出是离散的,如用于预测词或字符的 RNN。表示离散变量的常规方式是把输出 o 作为每个离散变量可能值的非标准化对数概率。然后,我们可以应用 softmax 函数 后续处理后,获得标准化后概率的输出向量 yˆ。RNN 从特定的初始状态 h(0) 开始前向传播。从 t = 1 到 t = τ 的每个时间步,我们应用以下更新方程:

其中的参数的偏置向量 b 和 c 连同权重矩阵 U、V 和 W,分别对应于输入到隐藏、隐藏到输出和隐藏到隐藏的连接。这个循环网络将一个输入序列映射到相同长度的输出序列。与 x 序列配对的 y 的总损失就是所有时间步的损失之和。例如,L(t) 为给定的 x(1), . . . , x(t) 后 y(t) 的负对数似然,则

-
每个时间步都产生一个输出,只有当前时刻的输出到下个时刻的隐藏单元之间有循环连接的循环网络。

-
隐藏单元之间存在循环连接,但读取整个序列后产生单个输出的循环网络。

4、循环神经网络RNN

RNN是针对序列数据而生的神经网络结构,核心在于循环使用网络层参数,避免时间步增大带来的参数激增,并引入隐藏状态(Hidden State)用于记录历史信息,有效的处理数据的前后关联性。

举个例子,有一句话是,I like study,那么在利用RNN做一些事情时,比如命名实体识别,上图中的
X
t
−
1
X_t-1
Xt−1代表的就是I这个单词的向量,
X
X
X 代表的是like这个单词的向量,
X
t
+
1
X_t+1
Xt+1代表的是study这个单词的向量,以此类推,我们注意到,上图展开后,W一直没有变,W其实是每个时间点之间的权重矩阵。RNN之所以可以解决序列问题,是因为它可以记住每一时刻的信息,每一时刻的隐藏层不仅由该时刻的输入层决定,还由上一时刻的隐藏层决定,公式如下,其中
O
t
O_t
Ot代表t时刻的输出,
S
t
S_t
St代表t时刻的隐藏层的值:
O
t
=
g
(
V
S
t
)
O_t=g(V S_t)
Ot=g(VSt)
S
t
=
f
(
U
X
t
+
W
S
t
−
1
)
S_t=f(U X_t+W S_t-1)
St=f(UXt+WSt−1)
值得注意的一点是,在整个训练过程中,每一时刻所用的都是同样的W。
隐藏状态(Hidden state)用于记录历史信息,有效处理数据的前后关联性激活函数采用Tanh,将输出值域限制在[-1,1],防止数值呈指数级变化

参数矩阵
[
W
x
h
、
W
h
h
、
W
h
q
]
[W_xh、W_hh、W_hq]
[Wxh、Whh、Whq]

四、例子
假设现在我们已经训练好了一个RNN,如图,我们假设每个单词的特征向量是二维的,也就是输入层的维度是二维,且隐藏层也假设是二维,输出也假设是二维,所有权重的值都为1且没有偏差且所有激活函数都是线性函数,现在输入一个序列,到该模型中,我们来一步步求解出输出序列:


W在实际的计算中,在图像中表示非常困难 ,所以我们可以想象上一时刻的隐藏层的值是被存起来,等下一时刻的隐藏层进来时,上一时刻的隐藏层的值通过与权重相乘,两者相加便得到了下一时刻真正的隐藏层,如图
a
1
,
a
2
a_1,a_2
a1,a2 可以看做每一时刻存下来的值,当然初始时
a
1
,
a
2
a_1,a_2
a1,a2 是没有存值的,因此初始值为0:
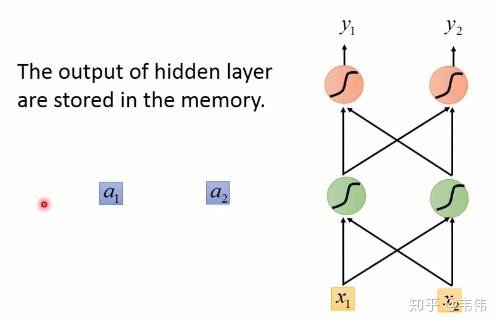
当我们输入第一个序列,[1,1],如下图,其中隐藏层的值,也就是绿色神经元,是通过公式
S
t
=
f
(
U
X
t
+
W
S
t
−
1
)
S_t=f(U X_t+W S_t-1)
St=f(UXt+WSt−1)计算得到的,因为所有权重都是1,所以也就是
1
∗
1
+
1
∗
1
+
1
∗
0
+
1
∗
0
=
2
1*1+1*1+1*0+1*0=2
1∗1+1∗1+1∗0+1∗0=2,输出层的值4是通过公式
O
t
=
g
(
V
S
t
)
O_t=g(V S_t)
Ot=g(VSt)计算得到的,也就是
2
∗
1
+
2
∗
1
=
4
2*1+2*1=4
2∗1+2∗1=4 ,得到输出向量[4,4]:
RNN 是通过时间返向传播(backpropagation through time)

当[1,1]输入过后,我们的记忆里的
a
1
,
a
2
a_1,a_2
a1,a2已经不是0了,而是把这一时刻的隐藏状态放在里面,即变成了2,如图,输入下一个向量[1,1],隐藏层的值通过公式
S
t
=
f
(
U
X
t
+
W
S
t
−
1
)
S_t=f(U X_t+W S_t-1)
St=f(UXt+WSt−1)得到,
1
∗
1
+
1
∗
1
+
1
∗
2
+
1
∗
2
=
6
1*1+1*1+1*2+1*2=6
1∗1+1∗1+1∗2+1∗2=6,输出层的值通过公式
O
t
=
g
(
V
S
t
)
O_t=g(V S_t)
Ot=g(VSt),得到
6
∗
1
+
6
∗
1
=
12
6*1+6*1=12
6∗1+6∗1=12,最终得到输出向量[12,12]:

由此,我们得到了最终的输出序列为:

五、RNN梯度传播
每一时刻的输出结果都与上一时刻的输入有着非常大的关系,如果我们将输入序列换个顺序,那么我们得到的结果也将是截然不同,这就是RNN的特性,可以处理序列数据,同时对序列也很敏感。

反向传播推导过程:
T=3
∂
L
∂
W
q
h
=
∑
t
=
1
T
p
r
o
d
(
∂
L
∂
o
t
,
∂
o
t
∂
W
q
h
)
=
∑
t
=
1
T
∂
L
∂
o
t
h
t
T
\\frac\\partial L \\partial W_qh=\\sum_t=1^Tprod(\\frac\\partial L\\partial o_t,\\frac\\partial o_t\\partial W_qh)=\\sum_t=1^T\\frac\\partial L\\partial o_t h_t^T
以上是关于一文了解循环神经网络的主要内容,如果未能解决你的问题,请参考以下文章