[3] Flink大数据流式处理利剑: Flink的部署架构
Posted 朱清云的技术博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[3] Flink大数据流式处理利剑: Flink的部署架构相关的知识,希望对你有一定的参考价值。
在前面的两个章节:《[1] Flink大数据流式处理利剑: 简介》和《[2] Flink大数据流式处理利剑: 用Flink进行统计的一个简单例子》 主要对Flink进行了简单介绍并演示了一个简单的例子;这个章节,我们来看看Flink的部署架构。Flink支持各种部署方式,单机版和集群版;本文将会给你大家介绍一下Flink的集群版的部署架构。
Flink集群版的部署架构如下:一主多从;主指的就是JobManager, 从指的就是TaskManager;
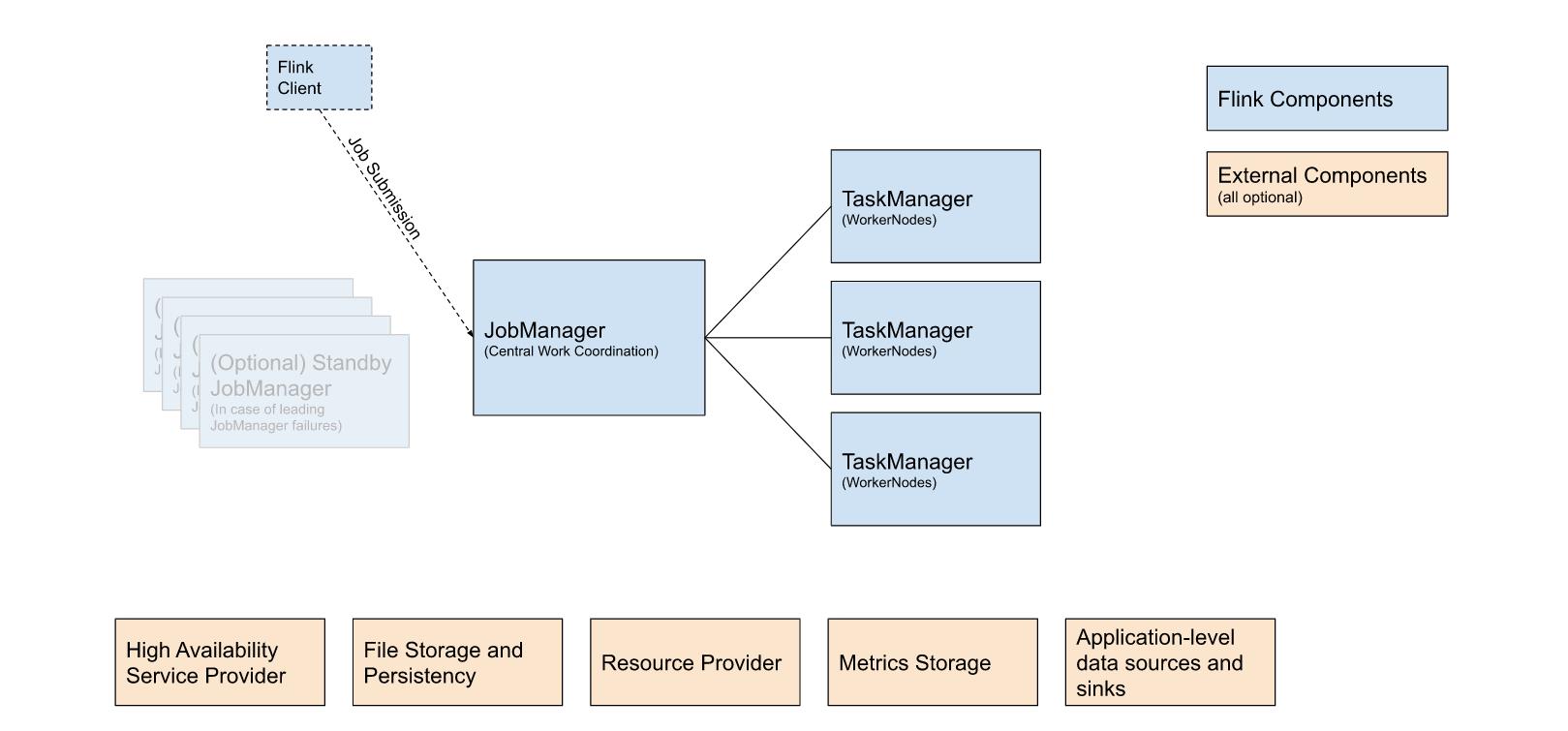
从上面可以看出,Flink集群主要有三大部分:
| 组件 | 目的 | 实现方式 |
|---|---|---|
| Flink Client | 编译批处理或者流处理到一个数据流图并上传到JobManager | 命令行,Restful终端,SQL客户端,Python 脚本,Scala脚本 |
| JobManager | 是Flink的中央协调管理者,其支持三种job计较方式: Application 模式, Per-Job 模式, Session模式 | 单机,Docker,Docker Swarm,K8s,Yarn 都可以用来安装部署JobManager |
| TaskManager | 是Job的具体执行者,其最终会执行Job |
上图中黄色正方形代表的是Flink和外部配合工作的组件(我就不一一翻译了)其是可选的;
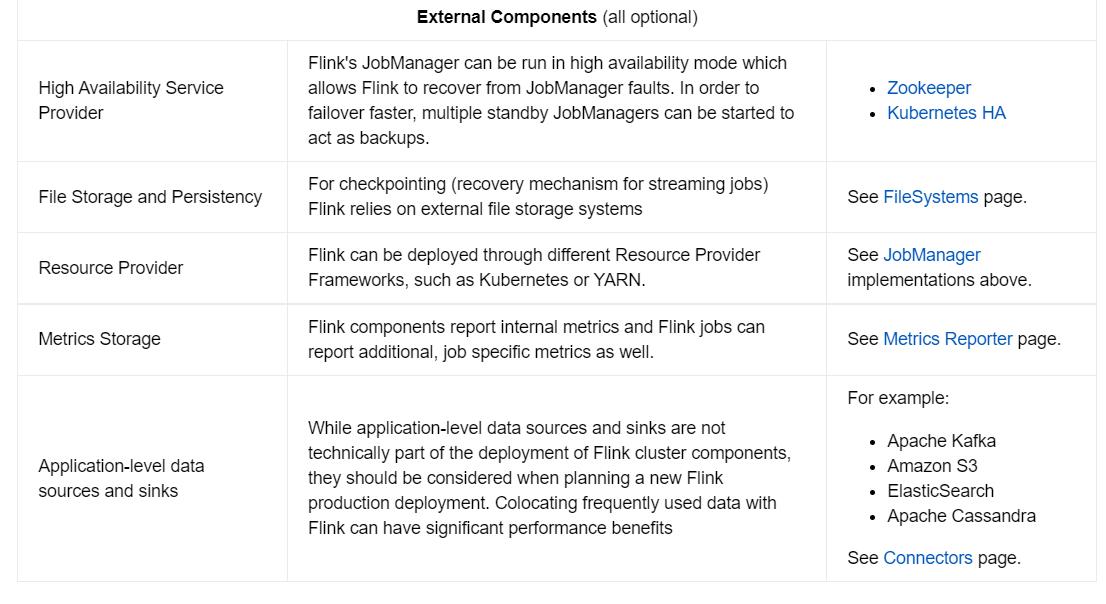
值得一提的是Flink的应用数据的来源(Source)和处理后的储存(Sinks),Flink目前支持了下面的连接器(Connectors),这些连接器在选型的时候可以根据不同的业务需求进行选型。需要的注意的是,有的连接器,只支持储存处理后的结果,有的只支持作为Flink的数据源,有的不但能作为Flink的数据源也能作为处理后的储存。


值得一提的是,当前很多云厂商的大数据流式处理方案都是基于Flink而进行托管的,比如下面的产品:
由此可见,Flink的应用是多么的广泛和优秀。
参考文献:
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/overview/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/connectors/datastream/overview/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/repls/python_shell/
https://nightlies.apache.org/flink/flink-docs-release-1.14/docs/deployment/repls/scala_shell/
以上是关于[3] Flink大数据流式处理利剑: Flink的部署架构的主要内容,如果未能解决你的问题,请参考以下文章