Python-机器学习-K近邻算法的原理与鸢尾花数据集实现详解
Posted 你隔壁的小王
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python-机器学习-K近邻算法的原理与鸢尾花数据集实现详解相关的知识,希望对你有一定的参考价值。
-
算法原理
- k近邻法(k-nearest neighbor, k-NN)是一种基本分类与回归方法,由Cover和Hart于1968年提出。分类时,对于新的实例,根据与它最接近的k个训练实例的类别,通过多数表决等方式,进行预测。对新的输入实例,在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,就把该输入实例分类到这个类中。(类似于现实生活中少数服从多数的意思)按照这个说法,我们来看下面这个图片:
-

如上图所示,其中蓝色小方块和红色三角形分别代表两种不同的样本数据,而带有问好的绿色小圆圈则表示待分类数据,我们如何来给这个绿色小圆圈进行分类正是我们的目的:
- 如果K=3,绿色圆点的最邻近的3个点是2个红色小三角形和1个蓝色小正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点应该归属于红色的三角形一类。
- 如果K=5,绿色圆点的最邻近的5个邻居是2个红色三角形和3个蓝色的正方形,少数从属于多数,基于统计的方法,判定绿色的这个待分类点应该归属于蓝色的正方形一类。
- 是不是比较容易理解那?下面我们来进行各总结:
- 该算法的核心思想:不标记样本的类别,由距离其最近的K个邻居投票来决定,所以K值的选择比较关键
- 该算法的原理:计算待标记的数据样本和数据集中每个样本的距离,取距离最近的k个样本。待标记的数据样本所属的类别,就由这k个距离最近的样本投票产生。
- 但在实际运用中,我们应该如何判断K的取值那?
-
# make_blobs这个函数是用来生成数据的 font = 'family':"SimHei",'size':20 plt.rc('font',**font) ##正常显示负号 plt.rcParams['axes.unicode_minus']=False from sklearn.datasets import make_blobs #设置中心点 centers = [[-2,2],[2,2],[0,4]] #n_samples的意思是要生成多少个样本数量 # centers的意思是围绕着哪些点生成, cluster_std表示标准差生成的点离着多远 x,y=make_blobs(n_samples=50,centers=centers,cluster_std=0.6) plt.figure(figsize=(16,10)) c=np.array(centers) plt.scatter(x[:,0],x[:,1],c=y,s=100,cmap='cool') #中心点绘制 plt.scatter(c[:,0],c[:,1],s=100,marker='*',c='black') plt.show()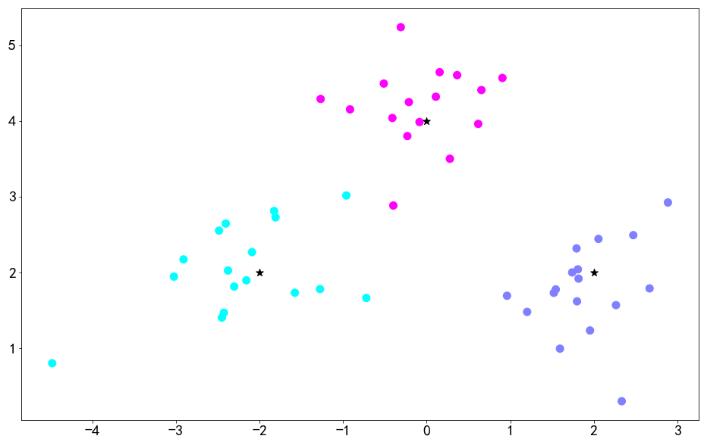
如图可以看到 三个维度的数据及其中心点,使用KNeighborsClassifier 对算法进行训练
- 该算法的核心思想:不标记样本的类别,由距离其最近的K个邻居投票来决定,所以K值的选择比较关键
from sklearn.neighbors import KNeighborsClassifier
k=5
#对模型训练
clf = KNeighborsClassifier(n_neighbors=k)
clf.fit(x,y)
#对样本进行预测
x_sample = [[0,2]]
neighbors = clf.kneighbors(x_sample)
neighbors[1]
plt.figure(figsize=(16,10))
plt.scatter(x[:,0],x[:,1], c=y, s=100, cmap='cool')
# 中心点画一下
plt.scatter(c[:,0],c[:,1], s= 100, marker="^", c='black')
#画出待预测的点
plt.scatter(x_sample[0][0],x_sample[0][1],marker='*',s=200,cmap='cool')
# 把预测点与距离最近的5个样本连成线
for i in neighbors[1][0]:
plt.plot([x[i][0], x_sample[0][0]], [x[i][1],x_sample[0][1]], 'k--', linewidth=0.6)
plt.show()
鸢尾花数据集
- Iris 鸢尾花数据集内包含 3 类分别为山鸢尾、虹膜锦葵、变色鸢尾,共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:萼片长度、萼片宽度、花瓣长度、花瓣宽度,可以通过这4个特征预测鸢尾花卉属于哪一品种。

rom sklearn.datasets import load_iris
iris=load_iris()
iris_data=iris.data
iris_data
#获取样本标记值
iris_target = iris.target
iris_target
##target是一个数组,存储了data中每条记录属于哪一类鸢尾植物,
##所以数组的长度是150
##划分训练集和测试集
x_train,x_test,y_train,y_test= train_test_split(iris_data,iris_target,test_size=0.25)
# 训一下
knn = KNeighborsClassifier(n_neighbors=5)
knn.fit(x_train,y_train)
y_predict = knn.predict(x_test)
##展示一下预测结果
labels=['山鸢尾','虹膜锦葵','变色鸢尾']
for i in range(len(y_predict)):
print("第%d次测试:真实值是%s,预测值是%s" % ((i+1),labels[y_predict[i]],labels[y_test[i]]))
返回给定测试数据和标签的平均精度
knn.score(x_test,y_test)=0.9736842105263158
有预测错误,寻找最佳K值
from matplotlib.pyplot import MultipleLocator
from sklearn.model_selection import cross_val_score
plt.figure(figsize=(15,10))
k_range = range(1,30)
k_error = []
x = iris.data
y = iris.target
#循环取 看误差效果
for k in k_range:
knn = KNeighborsClassifier(n_neighbors=k)
#cv参数划分训练集和测试集
scores = cross_val_score(knn,x,y,cv=6)
k_error.append(1-scores.mean())
x_major_locator=MultipleLocator(1)
ax=plt.gca()
ax.xaxis.set_major_locator(x_major_locator)
plt.plot(k_range,k_error)
plt.xlabel('k的值')
plt.ylabel('错误')
plt.show()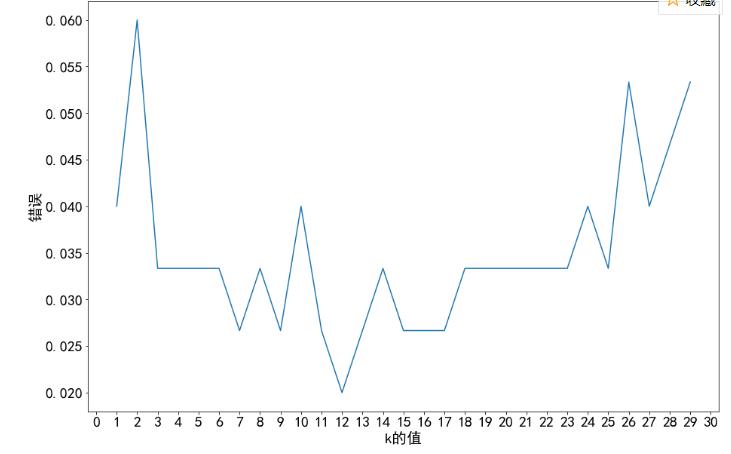
可以发现最佳K值是12 ,将K=12带回运算,此时误差最小

以上是关于Python-机器学习-K近邻算法的原理与鸢尾花数据集实现详解的主要内容,如果未能解决你的问题,请参考以下文章