一文读懂国产分布式数据库TiDB&Ocean Base原理
Posted 阿令_DBA
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂国产分布式数据库TiDB&Ocean Base原理相关的知识,希望对你有一定的参考价值。
目录
- 概述
- 产品架构
- 数据分片原理
- 数据同步原理
- 多版本并发控制
- 关键算法介绍
- 参考文献
概述
随着5G、物联网、人工智能的高速发展,企业所生产的数据会越来越多,其规模可能达到数百TB 甚至PB级别对于传统的数据库Oracle、mysql 当单表的数量达到一定值后,系能问题逐渐出现瓶颈,很多企业为了解决这个问题,对数据库进行分库分表的操作,通过应用逻辑的调整以及路由中间件的使用来解决这个问题,但是这种操作必然给数据库维护团队以及应用开发团队带来巨大的工作量。此时分布式数据库的使用就很好的契合了这个场景。
本文分析阿里云的OceanBase和PingCAP TiDB两款分布式数据库,主要从产品架构、数据分片原理、数据同步原理、MVCC多版本并发控制、相关底层的算法分析的层面浅谈两款数据库的特点。
| Ocean Base | TiDB | |
| 最小分区单位 | Partion | Region |
| 分区原理 | 自定义键值 | Hash+Range |
| 数据同步协议 | Paxos | Raft |
| MVCC | 索引结构+行操作链 | Key_version,Value |
| 存储引擎 | LSM_Tree(存储算法) | RocksDB |
产品架构
Ocean Base:
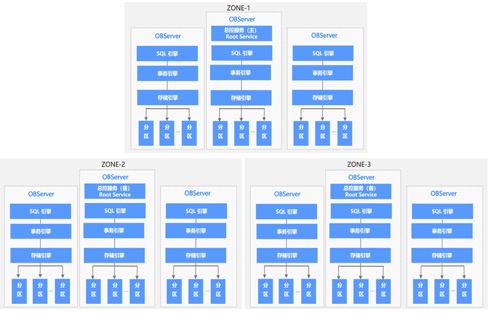
架构图可知的内容:
- OB的数据高可用通过多Zone来实现(也可以Region),每个Zone保存着完成的数据副本;
- 同步的最小单位为分区也叫做partion;
- 每个Zone下面对应的主机上都部署着Observer、SQL引擎、事物引擎、存储引擎等
工作机制说明:
每个Zone上面存在两个主要服务,一是总控服务,二是分区服务
1. 总控服务:RootService
其中每个Zone 上都会存在一个总控服务,运行在某一个OBServer 上,整个集群中只存在一个主总控服务,其他的总控服务作为主总控服务的备用服务运行。总控服务负责整个集群的资源调度、资源分配、数据分布信息管理以及Schema 管理等功能。
2. 分区服务:PartitionService
用于负责每个OBServer 上各个分区的管理和操作功能的模块,这个模块与事务引擎、存储引擎存在很多调用关系。
TiDB:
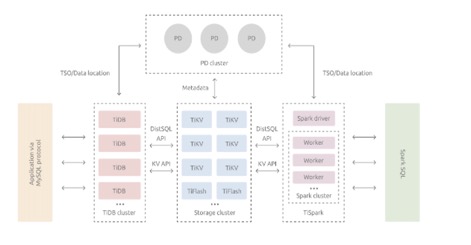
说句实话,咱真的没看懂tiDB的架构图,官网描述与图片对不上,可能是我没有理解,不过不影响我们对他的了解,数据库跑不了三层架构,我们只需要知道核心组件的功能。
- TiDB Cluster: 客户端的连接、SQL的解析到产生分布式执行计划
- PD(Placement Driver) Server: 元数据管理、负责数据的分布、分布式事物的管理
- 存储节点:负责数据的存储、采用Key-Value的分布式存储引擎,根据数据分布原则将数据分布在不通的region中,region是TiDB数据同步的最小单位,这里region和阿里云的region是不同的概念。
数据分片原理
对于分布式数据库分片常见的几种方案 List、Hash、Range或者按照tablet的大小超过就自动分区
Ocean Base:
和传统的Mysql以及Oracle的Partition功能类似,用户建表的时候指定使用哪些字段进行分区,OB的负载均衡可以把不同分区的主打散到多台机器上(这里后续会研究底层的负载均衡原理);
TiDB:
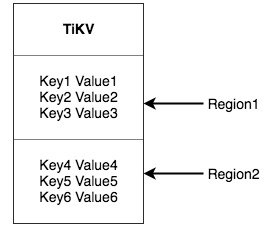
TiDB的数据分区采用的Hash+Range的方式,将一段连续的 Key 都保存在一个存储节点上,官方把这个节点叫做region
数据同步原理
Ocean Base
通过Paxos协议进行日志同步,每个分区和他的副本构成一个独立的paxos复制组,针对副本的写的请求,都会自动路由到对应的主分区上,对于不通副本写的操作会很分布到不同的数据节点上,从而实现数据的多点写入,提高性能。
TiDB:
通过Raft协议进行日志复制,每个数据变更都会产生一条Raft 日志,通过Raft 的日志复制功能,将数据安全可靠地同步到复制组的每一个节点中,实际写入中,根据Raft 的协议,只需要同步复制到多数节点,即可安全地认为数据写入成功。
后面会简单介绍Paxos和Raft协议
多版本并发控制
对于传统数据库Oracle以及MySQL的多版本并发控制更多的是通过内部锁机制实现多版本的控制,但对于数据上锁,在分布式系统中可能会带来严重的性能问题,对于TiDB和OB总体原则都是通过保留旧版本的数据来实现MVCC
Ocean Base:
OB的内部包含两个部分:索引结构及行操作链。其中,索引结构存储行头信息,采用内存B树实现;行操作链表中存储了不同版本的修改操作,索引结构记录了事物的相关信息,通过事物+多版本数据从而MVCC机制;
TiDB:
TiDB数据库采用的Key-Value的方式进行数据的存储,在并发下必然就会存在多个会话同时通过一个Key去修改数据的场景,TiDB通过控制Key的版本来解决MVCC的问题,如下;
传统的Key-Value
Key1 -> Value
Key2 -> Value
……
KeyN -> Value
有了MVCC机制后,TiDB的Key如下图
Key1_Version3 -> ValueKey1_Version2 -> ValueKey1_Version1 -> Value……Key2_Version4 -> ValueKey2_Version3 -> ValueKey2_Version2 -> Value
key是一个有序的排列,从大到小,当用户通过一个Key + Version 来获取Value 的时候,可以通过Key 和Version 构造出多版本的Key
关键算法介绍
Paxos:
由技术大师Lamport在1990年提出的一种基于消息传递的一致性算法,这个算法在过去10于年里面基本成为分布式领域内一致性协议的代名词,最终实现的结果就是让少数服从多数的方式,最后达成一致的建议......太深了 还在研究中;
Raft:
也是分布式一致性的协议,这个协议中提供几个重要的特点 Leader 选举、成员变更、日志复制 ;这里简单说一下日志复制的过程:
首先整个集群中存在一个主节点,每次数据的变更都会被记录到组节点的日志中,此时日志的状态是未提交的,然后主节点会将这个日志分发到各个Follower节点,直到多数的Follwer节点应用了这个日志才会通知主节点,最后主节点完成commit操作。
LSM_Tree :
起源于谷歌1996年的 一篇论文The Log-Structured MergeTree(LSM_Tree) 专门为key-value存储系统设计的,最大的特点就是利用了磁盘的顺序写,避免随机写入多层次的树;C0层是在内存里面,保留最近写入的(k,v) ,是有序的 ,剩下的c1 到ck层都是在磁盘上的.
写入的操作: 一个put的写入的操作,首先追加到当前日志(Write Ahead Log) 依然遵从日志先写的的原则。接下来是C0层,单c0层的数据达到一定大小后,几把c0和c1层合并,类似递归的排序,这个过程叫做compaction,合并出来新的c1会顺序的写入磁盘,然后替换到原来的c1,c1达到一定的大小之后会和下层合并然后删除之前的老的。
读取的操作:在写入的流程中可以看到,最新的数据在c0层,最小的数据在ck层,所以查询会先查c0层,如果没有在查询c1层,逐层往下.
参考文献:
https://docs.pingcap.com/zh/tidb/v4.0/overview
https://help.aliyun.com/document_detail/134480.html?spm=a2c4g.11174283.6.543.679c2f011VlFfx
https://blog.csdn.net/u010454030/article/details/90414063
https://www.baidu.com/link?url=sKf4Qw66RCv1EP5rZcxeaa5jjZro7JlIxJc8Jx55yIAeWh6vGZfJOUusmM_yvP5k&wd=&eqid=e3a24ae10007fd610000000460bb1e56
https://xie.infoq.cn/article/c98432267e7b7038718d199e1
https://blog.csdn.net/weixin_40581617/article/details/80496594
https://www.zhihu.com/question/19787937
以上是关于一文读懂国产分布式数据库TiDB&Ocean Base原理的主要内容,如果未能解决你的问题,请参考以下文章