CCS 2021 | 自动化网络流量分析新方向
Posted WellShark
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了CCS 2021 | 自动化网络流量分析新方向相关的知识,希望对你有一定的参考价值。
CCS 2021 | 自动化网络流量分析新方向
| 论文名称 | New Directions in Automated Traffic Analysis |
|---|---|
| 录用信息 | CCS 2021(CCF-A) |
| 作者 | Jordan Holland, Paul Schmitt, Nick Feamster, Prateek Mittal |
| 团队 | 普林斯顿大学信息技术政策中心 芝加哥大学网络运营和互联网安全实验室 |
| 源码 | https://github.com/nprint/nprint |
| 数据集 | https://drive.google.com/drive/folders/158Lwb9TwopIJ0lGPuFik5744qPiqrg9F |
一、摘要
机器学习技术被广泛的应用在入侵检测、应用程序识别等网络流量分析任务中。然而在使用机器学习方法时,特征表示、模型选择和参数调整等过程仍然需要大量的人力成本和专业知识。此外,流量模式会不断的发生变化,使得模型和人工提取的特征过时。因此,本文提出一种自动化流量分析方法(nPrintML),使机器学习技术更容易应用于更广泛的流量分析任务。nPrintML 包含 nPrint 流量表示和 AutoML 两部分,首先 nPrint 通过对 IP 数据包头进行对齐和拼接形成统一的数据表征,然后使用 AutoGluon-Tabular 框架进行自动化的进行特征提取、模型搜索和超参数优化。作者在 8 个不同的流量分析任务上对 nPrintML 进行评估,都取得了很好的效果。
二、nPrint
在应用机器学习方法时,对数据进行编码是非常重要的一环。为了实现上述提出的目标,数据编码需要满足以下要求:
- 完整性(Complete):我们的目的是找到一种统一的数据编码,而不依赖于专家知识,所以该编码方式需要包含数据包的所有信息。
- 不变性(Constant size per problem):机器学习模型要求输入的数据保持同样大小。因此,对于不同的数据包,也应该有相同的数据表征。
- 归一性(Inherently normalized):归一化可以减少模型的训练时间并提高模型的稳定性,因此数据表征应该是经过归一化的。
- 一致性(Aligned):不同数据包头的同一部分在编码后应该位于同样的位置。
首先来看传统的流量数据包头:
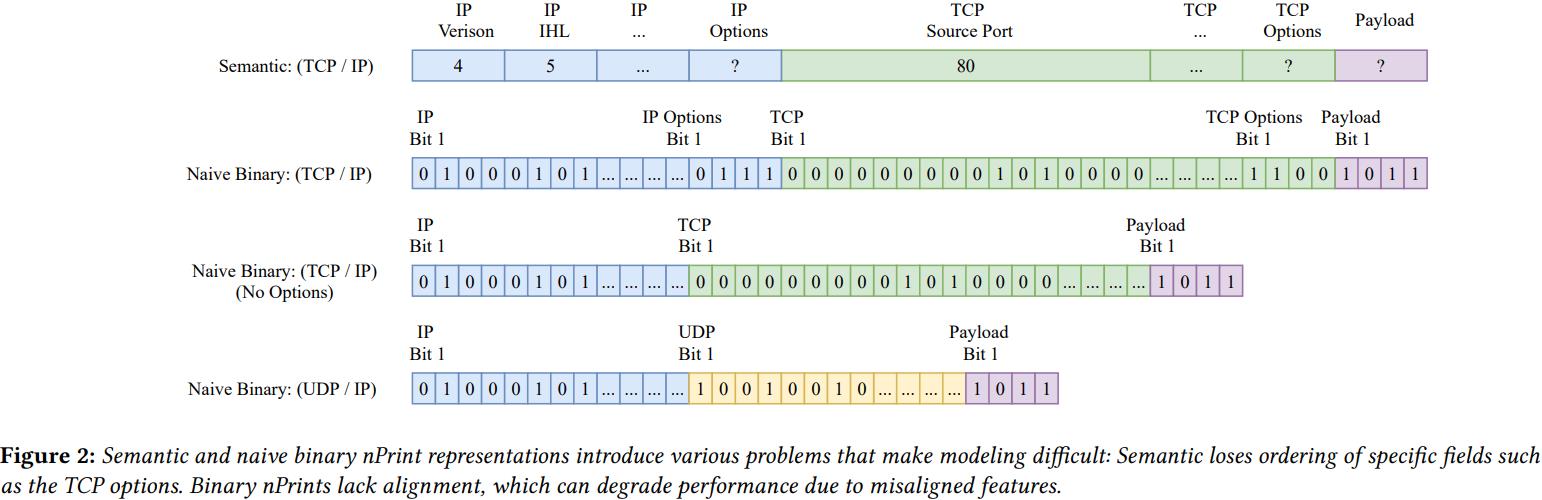
从图 2 可以看出,不同的网络协议(如 TCP 和 UDP)有着不同的数据表示方案,甚至相同的网络协议(如 IP)也不相同(是否包含 Options 选项),这显然无法满足上述需求。因此,作者提出了一个标准化的数据包表征方法:nPrint(图 3)。

nPrint 使用每种协议允许的最大包头长度来表示该协议,同时将不同协议头部拼接组合成固定长度的包头。因此,nPrint 符合了上述几个性质:完整性(理论上可以包含所有协议)、不变性(数据表征可以是一个确定的长度)、归一性(数据被表示为 1/0/-1)、一致性(不同数据包头的同一选项在同一位置)。
三、nPrintML
作者将 nPrint 与 AutoGluon-Tabular 框架相结合,提出 nPrintML,实现了机器学习自动化的流程(图 1)。
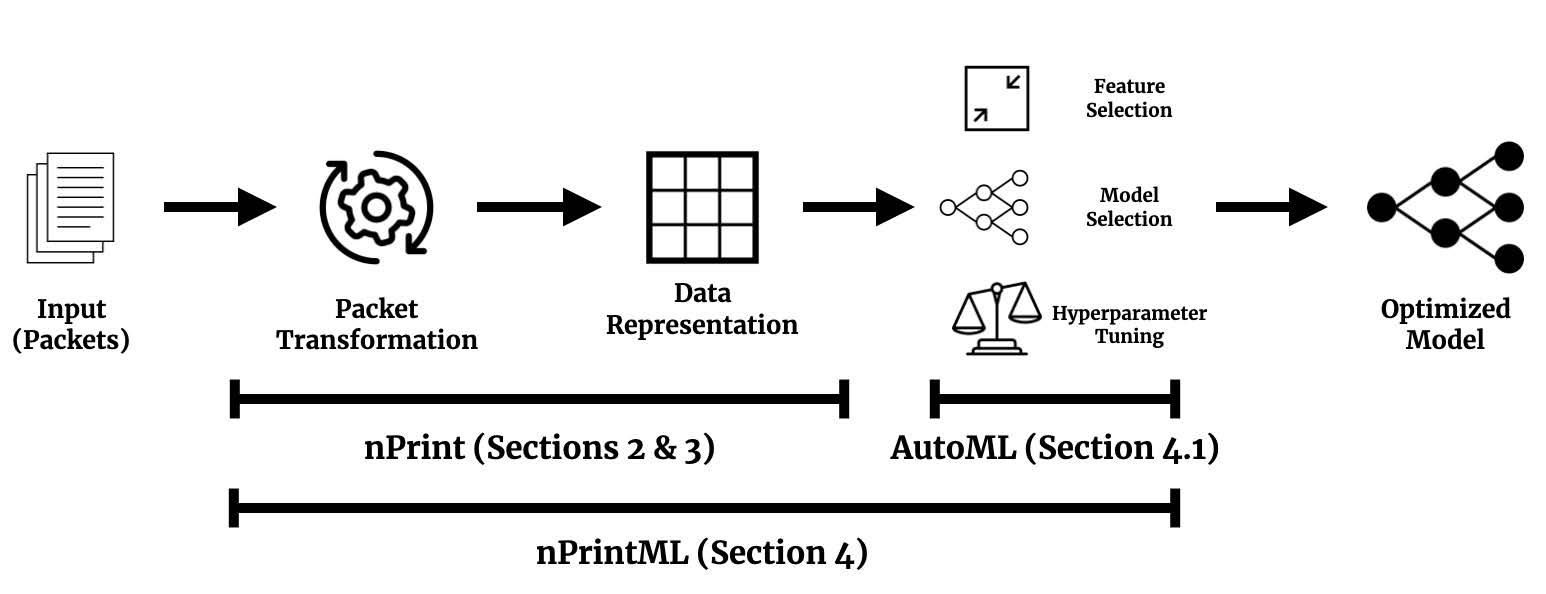
AutoGluon-Tabular:一个 Aws 开源的 AutoML 框架,仅需要几行代码即可在未预处理的表格型数据(如 csv)上训练高精度的机器学习模型。(AutoGluon 也支持处理非结构化数据)
关于 AutoGluon 的详细介绍见 [5],[6],[7]。


四、实验
4.1 Overview
作者在 8 个不同的网络流量分析任务上进行实验分析,结果表明(表 1):nPrintML 可以应用于不同场景,相较于对比方法能够取得更好的性能:

4.2 主动设备指纹识别(Active Device Fingerprinting)
Nmap 通过发送一些探针到目标主机进而判断其设备指纹,作者修改 Nmap 使其输出每个探针的原始响应内容,nPrintML 使用 Nmap 产生的原始响应为每个设备构建一个 nPrint。
Comparison method:Nmap
Input:21 个 packets 组成的 nPrint,即探针的响应数据
Dataset:Holland et al. 2020 + 使用 Shodan 标注的 4 种 IoT 设备
Packet Transformation and Data Representation:
nPrint 配置为使用 IPv4、TCP 和 ICMP 头((60+60+8) Bytes = 1024 bit = 1024 个特征)。nPrintML聚合来自每个设备的所有响应,为每个设备创建一个包含 21 个数据包的 nPrint(为什么是 21 个数据包?)。
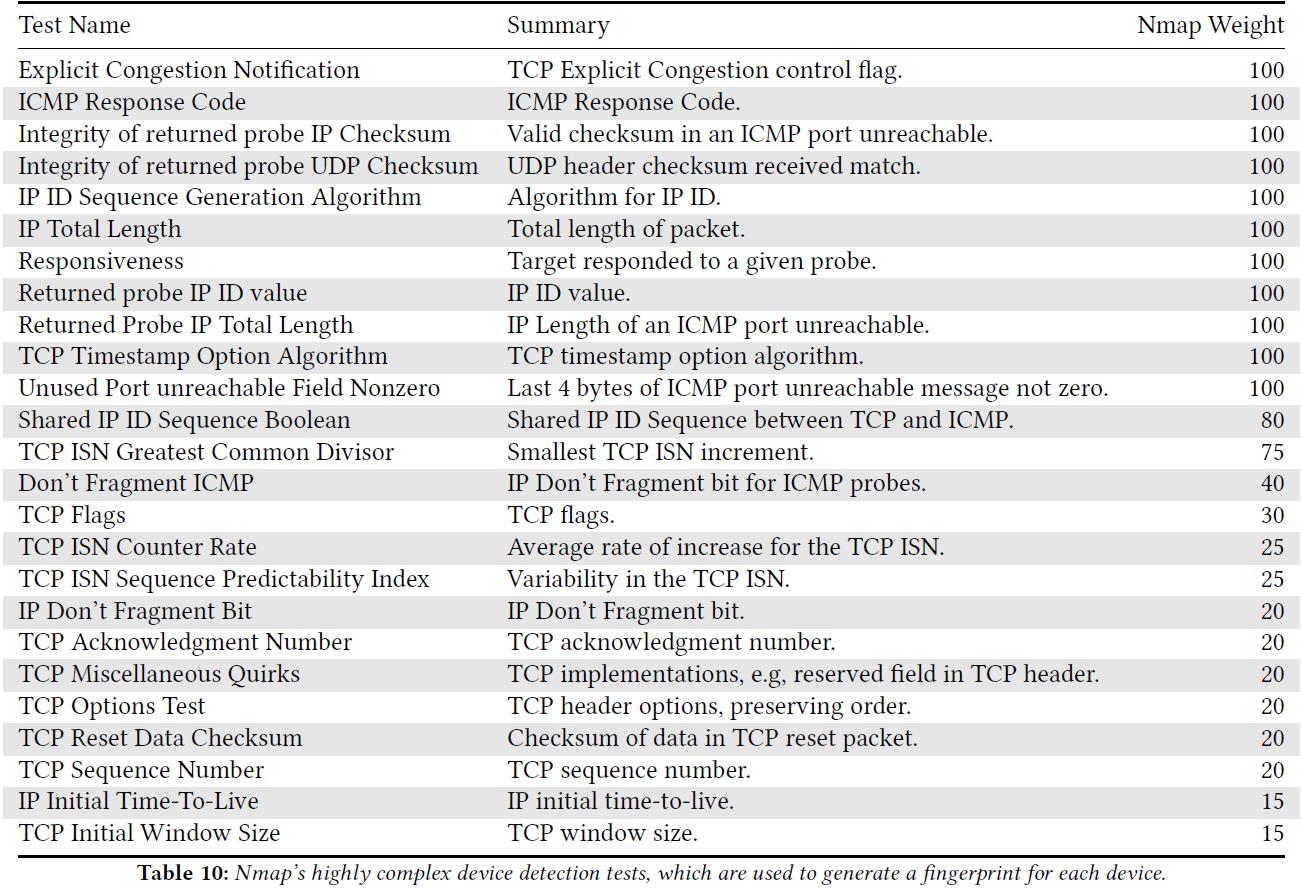
Nmap 开发了一系列复杂的测试(表 10),将每个探针的响应转换为指纹。本文使用两种方式来使用这种指纹进行评估:
- Nmap 将生成的指纹与其数据库进行比较,对远程设备进行分类(Nmap Direct/Nmap Aggressive)。
- 使用指纹和对每个测试编码的类别特征(categorical feature)创建一个特征向量,用于 AutoML 训练和验证(ML-Enhanced Nmap)。
先前研究[3]表明 Nmap 首先扫描设备上 1000 个最常见的开放端口以找到一个开放端口。然后向设备发送 16 个探针,其中 10 个用来探测开放端口,6 个(3 TCP + 1 UDP + 2 ICMP)用来探测关闭的端口。
Conclusion:
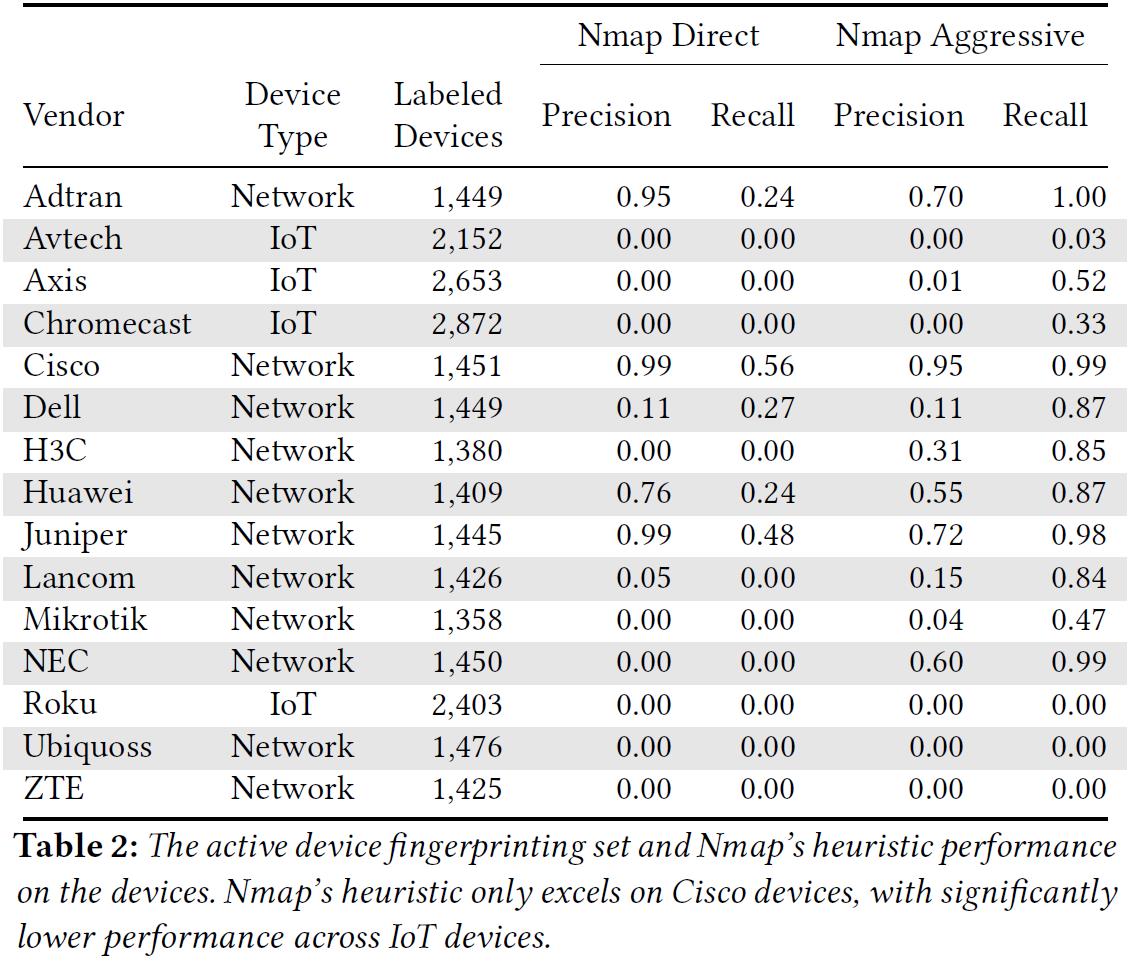
1) Nmap’s heuristics perform poorly for some devices.
表 2 显示了 Nmap 直接输出设备猜测结果(Nmap Direct)和多种探针加权聚合结果(Namp Aggressive)两种方法的对比情况。结果表明:Nmap 在 Cisco、Juniper 和 Adtran 设备分类上具有较高的精度和相对较低的召回率,此外,Nmap 在整个数据集上的其他设备分类上效果都很差。
2) nPrintML outperforms an AutoML-enhanced Nmap.
为了更好的比较 nPrint 和 Nmap 长期积累的特征提取技术,作者在每个经过 one-hot 的 Nmap 指纹上使用 AutoML 进行指纹识别,替代了原有的结果生成方案(heuristic)。同时,在每个设备产生的 nPrint 表征上运行 nPrintML。表 3 显示了 Nmap 和 nPrintML 的最高性能分类器的平均精度。结果表明,在 nPrint 表征方法上训练的模型不需要手动的特征工程就可以区分设备,而且 nPrintML 的性能优于 Nmap。
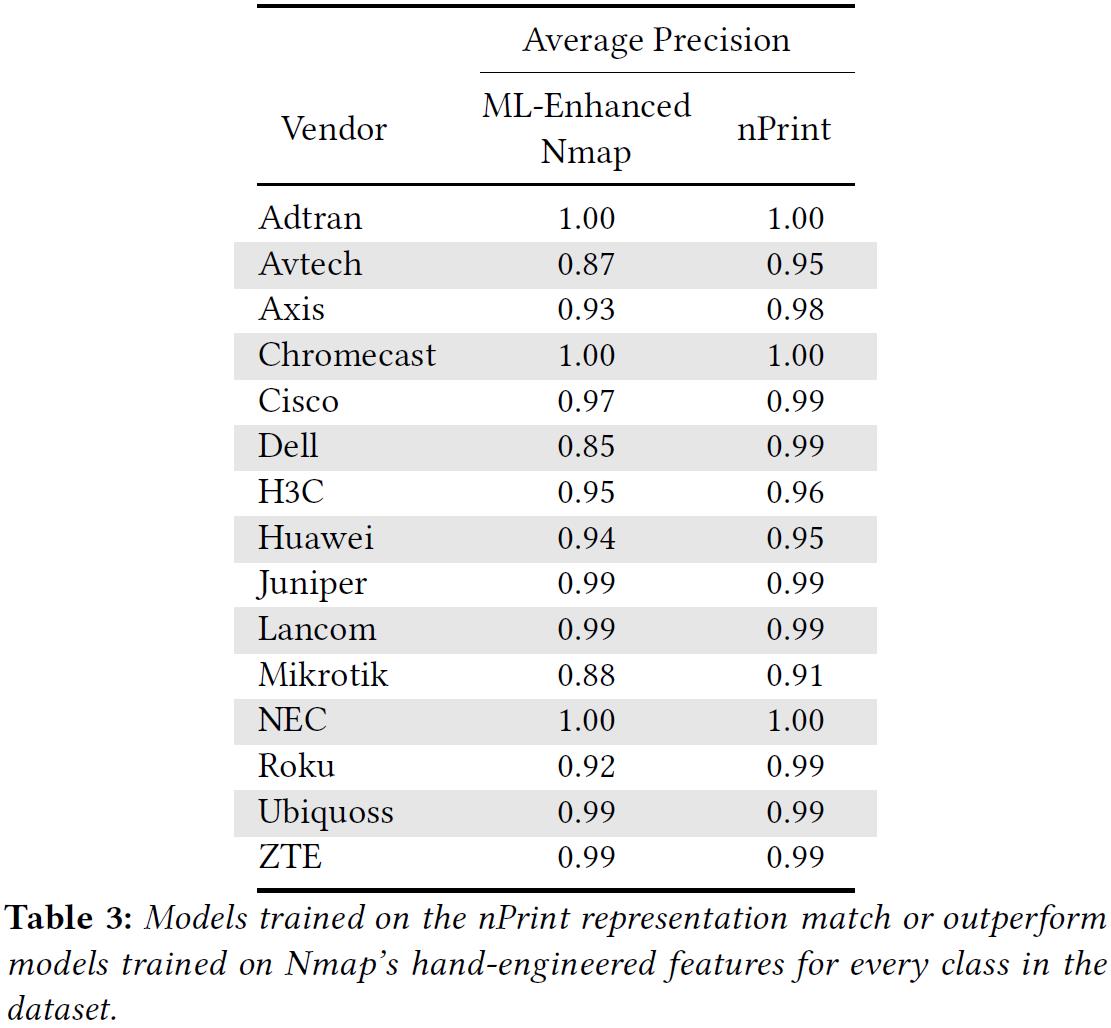
表 4 显示了 Nmap 和 nPrintML 的最佳模型性能,可以发现 nPrintML 在每个指标上都优于 Nmap 长期积累的特征。
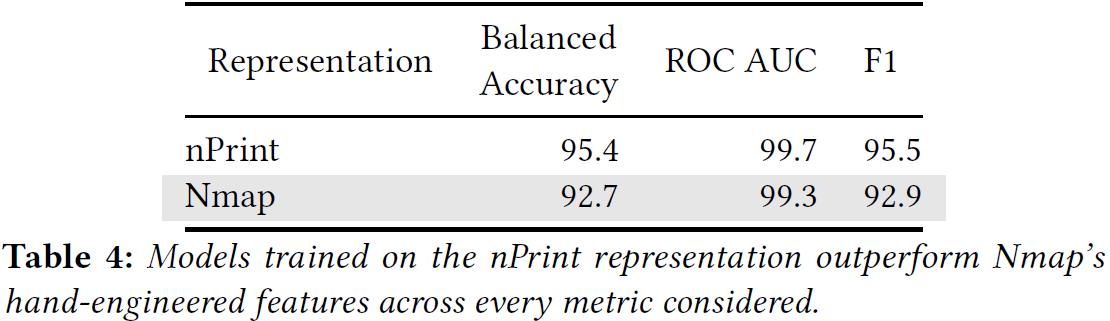
表 5 显示了 Nmap 和 nPrintML 两个性能最高的模型的训练和推理时间。

图 4 显示了从使用 nPrintML 训练的随机森林模型中收集的特征重要性热力图。可以发现,探针响应数据包的 TCP 源端口是对设备供应商进行分类的最重要的特征之一。此外,我们还看到 IP TTL 和 TCP 窗口大小有助于识别设备。

4.3 被动操作系统指纹识别(Passive OS Fingerprinting)
Comparison method:p0f
Input:1/10/100 个数据包组成的 nPrint(表示不同识别难度)
Dataset:CIC-IDS 2017(13 种可用的操作系统流量)
Packet Transformation and Data Representation:使用每种设备的前 100,000 个数据包,将它们划分为 1、10、100 数据包的样本集(即 100,000 个包含 1 个数据包的 Pcap,10,000 个包含 10 个数据包的 Pcap 和 1000 个包含 100 个数据包的 Pcap),也就产生了 3 个独立的分类问题。同时,为这些流量样本生成仅含有 IP 和 TCP 头部的 nPrint 表征,删除其中的 IP 源地址、IP 目标地址、IP 标识、TCP 源和目标端口以及 TCP 序列号和确认号,避免模型记住这些字段而不是学会区分。
p0f 从每个数据包中提取一些字段,并将提取的值与指纹数据库进行比较,为提取的字段找到匹配的操作系统。
Conclusion:
1) nPrintML can perform OS classification with high recall and few packets.
表 6 显示了 3 个实验的精度和召回率。 结果表明 p0f 生成的设备信息粒度较粗(如 p0f 将所有 Ubuntu 设备和 Web Server 分类为“Linux 3.11 及更高版本”,将所有 Windows 设备分类为“Windows 7 或 8”)。此外,随着 p0f 访问的数据包数增多,其性能通常会不断提高,但其召回率整体都很低。nPrintML 相比而言,精度和召回都很高(使用 p0f label),即使只有 1 个数据包。
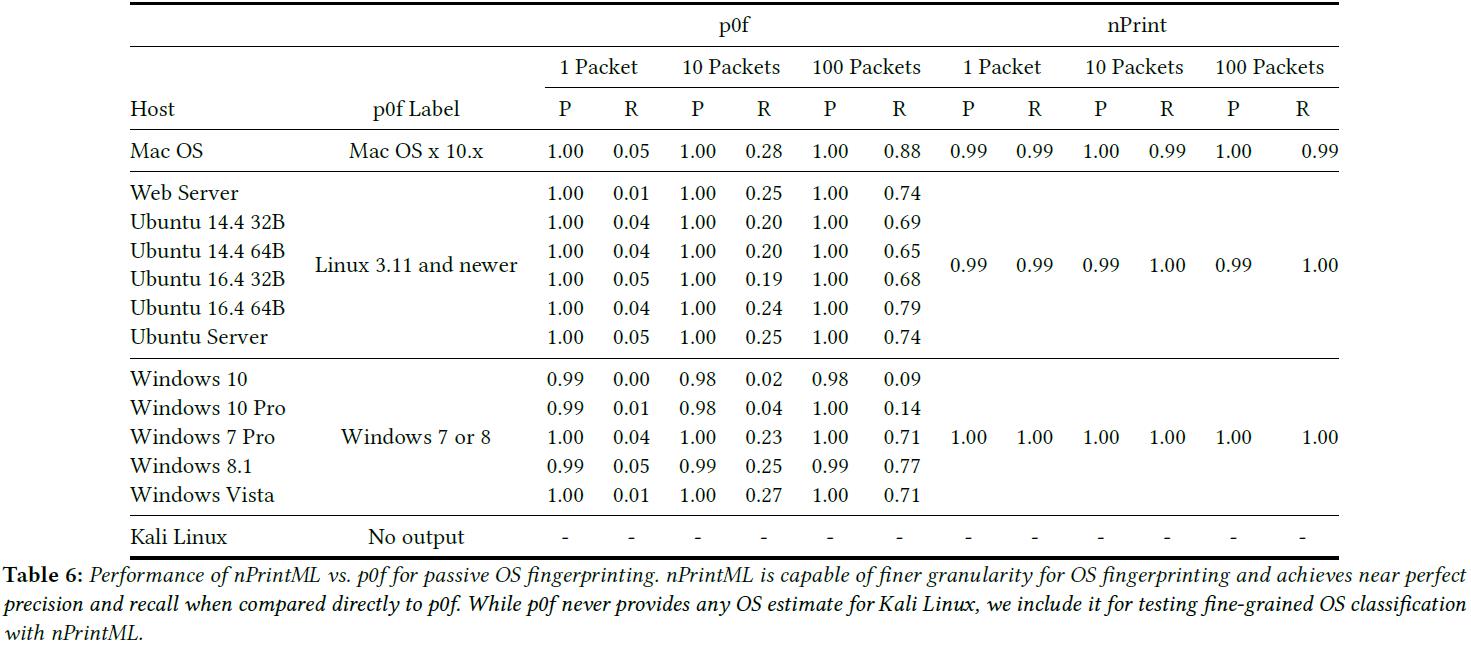
图 5 显示了从使用 nPrintML 训练的性能最高的随机森林模型中收集的特征重要性热力图。对于 IPv4 包头,最重要的特性是 TTL 字段,其次是 ID 字段。这些结果证实了过去的一些经验,即 TTL 和 ID 可用于操作系统检测,因为不同的操作系统对这些字段使用不同的默认值。在 TCP 报头中,窗口大小字段是最重要的特征。此外还可以观察到,TCP 选项中的某些位有助于确定操作系统,因为某些操作系统默认包括特定选项,如最大段大小(maximum segment size)、窗口缩放(window scale)或 SACK(selective acknowledgement permitted)。

2) nPrintML can reveal fine-grained differences in OSes.
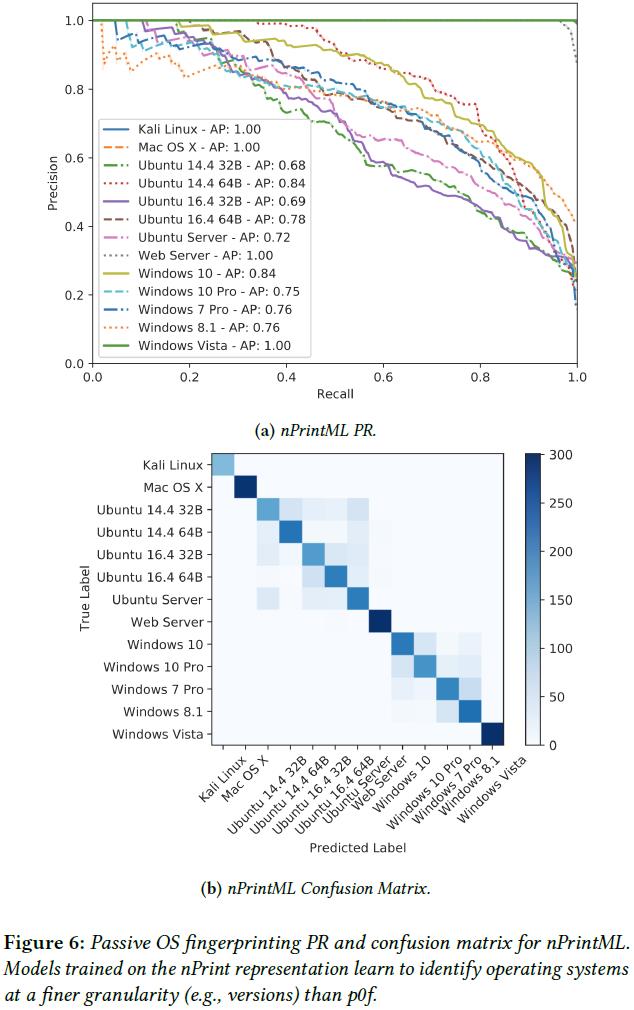
接下来,作者使用了相同的 100-packet 样本来验证在 nPrint 表征上训练的模型是否能够在更细粒度的级别上实现自动化被动操作系统检测(13 个类别的分类任务)。图 6a 显示了最高性能模型的 PR 曲线。 图 6b 更详细地展示了模型分类结果的混淆矩阵。尽管细粒度分类的精度不如粗粒度,但几乎所有的错误都出现在同一个操作系统大类中(合理)。
3) nPrintML differentiates OSes, not simply devices.
为了验证 nPrintML 是否能够检测操作系统,而不是学习识别网络上的特定设备,作者构建了一个实验,使用数据集中的五台 Ubuntu 主机和五台 Windows 主机设置一个二分类任务,并且迭代地从两个列表中选择对来训练模型,并针对列表中的其余主机进行测试。结果表明无论使用哪一对设备进行训练,nPrintML 都能以完美的准确率、ROC AUC 和 F1-Score 区分 Ubuntu 和 Windows 机器。这是由于模型学习到了两个操作系统设置的初始 IP TTL 不同。
不同类型的操作系统,默认的起始 TTL 值是不同的[8]:
- windows:128(65-128)
- linux/unix:64(1-64)
- 某些 Unix:255
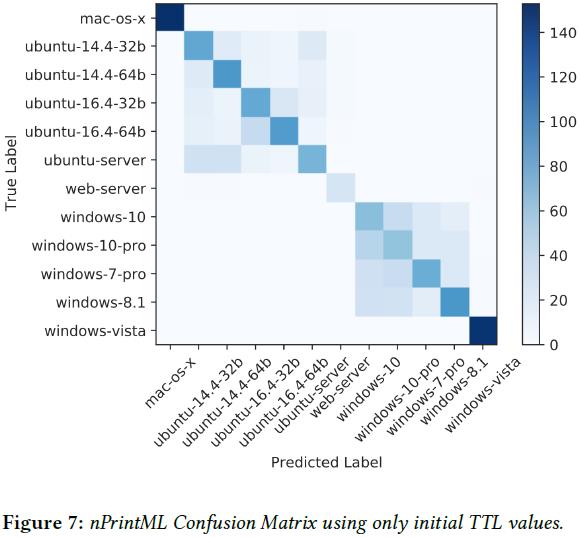
最后,为了确保 nPrint 不会通过设备的 TTL 值来记住主机在网络中的位置,作者将 TTL 统一设置为初始值进行了实验,结果(图 7)表明错误仍然发生在操作系统大类的内部。
p0f 使用沿路径的位置作为特征。p0f 尝试通过 64、128 或 255 三种值来猜测初始 TTL,然后使用递减的 TTL 计算距离初始 TTL 的“距离”
4.4 DTLS 应用识别(DTLS Application Identification)
Input:DTLS 握手包组成的 nPrint
Dataset:Kyle MacMillan et al. 2020(来自 Firefox 和 Chrome 的 4 种约 7000 次的 DTLS 握手包:Facebook Messenger、Discord、Google Hangouts 和 Snowflake)本文设计为 7 分类任务。

Comparison method:Kyle MacMillan et al. 2020(作者参与的另一项工作,人工提取特征)
Packet Transformation and Data Representation:将握手包转换为 nPrint 表征,同时在多种配置(表 1)下测试 nPrintML。
Conclusion:
1) nPrintML can automatically detect features in a noisy environment.
在 nPrint 表征上训练的加权集成分类器获得了完美的 ROC AUC 分数、99.8% 的准确率和 99.8% 的 F1-Score。nPrintML 几乎可以完美地识别生成每次握手的<浏览器,应用程序>对。虽然在以前的工作中,手动设计的特征可以达到相同的精度,但 nPrintML 完全避免了模型选择和特征设计。此外,表 1 还显示,在 nPrint 表征上训练的模型可以仅使用每个数据包中的 UDP 报头以高精度执行此任务。

2) nPrintML performs well across models and trains quickly.
表 8 显示了每个经过训练的非集成分类器和总体性能最高的加权集成分类器在测试数据集上的 F1-Score、训练时间和总推断时间。nPrint 表征可跨模型工作,推理和训练时间与模型相关。

3) nPrintML can be used to understand semantic feature importance.
图 8 显示了从 nPrint 表征上训练的性能最高的随机森林模型中收集的特征重要性热力图。在该场景下,头部的长度信息和 DTLS 有效载荷中的信息在很大程度上决定了 nPrintML 的性能。

4.5 其他实验(Additional Case Studies)
4.5.1 netML 挑战赛(netML Challenge Examples)
使用 netML 流量分析挑战赛数据集,包含三个场景:入侵检测、物联网设备恶意软件检测和流量识别。实验结果见表 1,在每项任务中,除了 IoT 恶意流量分析的一个场景外,nPrintML 的性能都优于 netML排行榜上性能最高的模型(不公平的比较:netML 挑战赛只给出了统计特征,但作者使用了原始的数据包)。作者还提供了复现的具体命令:
# Intrusion Detection
$ nprintml -L labels.txt -a pcap --pcap-dir traffic_flows/ -4 -t -u -c 5 -x "ipv4_src.*|ipv4_dst.*"
# Malware Detection
$ nprintml -L labels.txt -a pcap --pcap-dir traffic_flows/ -4 -t -u -c 10 -x "ipv4_src.*|ipv4_dst.*"
# Traffic Identification(No Payload bytes)
$ nprintml -L labels.txt -a pcap --pcap-dir traffic_flows/ -4 -t -u -c 5 -x "ipv4_src.*|ipv4_dst.*"
# Traffic Identification(10 Payload bytes)
$ nprintml -L labels.txt -a pcap --pcap-dir traffic_flows/ -4 -t -u -p 10 -c 5 -x "ipv4_src.*|ipv4_dst.*"
作者此处没有给出使用 Payload 和不使用 Payload 的性能对比
4.5.2 移动应用来源分类(Mobile Country of Origin)
使用 Cross Platform 数据集[4]确定移动应用程序流量来源国家(中国、美国、印度)。nPrintML 可以使用每个数据包的 IPv4、TCP 和 UDP 报头以 96% 以上的准确率执行此任务。
$ nprintml -L labels.txt -a pcap --pcap-dir application_traces/ -4 -t -u -p 50 -c 25 -x " ipv4_src.*|ipv4_dst.*"
4.5.3 流媒体视频提供商识别(Streaming Video Providers)
仅使用 SYN 数据包能够以 98% 的准确率识别流媒体服务提供商(Netflix、YouTube、Amazon 和 Twitch)。数据集来自本文第三作者先前参与的工作。
$ nprintml -L labels.txt -a pcap --pcap-dir video_traces -4 -t -u -R -c 25 -f "tcp[13] == 2"
五、总结
Contributions:
- 为自动化流量提供了一种新的方向。提出一种统一的网络数据包表征方法 nPrint;
- 将 nPrint 与自动化机器学习工具 AutoGluon 相结合,提出 nPrintML,实现了自动化流量分析;
- 在 8 个不同流量分析场景进行了实验评估,结果表明 nPrintML 可以更好地获取网络流量的特征信息,nPrintML 获取的机器学习模型在性能上比传统特征工程得到的机器学习模型更加优越。
Deficiencies:
- 面对流量的加密化趋势,越来越多的工作转向使用流级别的序列信息或统计信息进行流量分析,nPrint 表征方法对流级别的序列信息提取几乎没有帮助;
- 作者的分类问题设计的普遍比较简单,缺少和最先进的流量分析方法(基于机器学习技术)的比较,而且使用加密后的 Payload 进行分类也很难解释;
- AutoML 技术当前存在的一些缺点也会影响到流量分析任务,如何自动化构建更复杂的模型、如何基于数据构建更复杂的关系(跨流捕获时间关系)等都是未来需要改进的方向。
附录:
1. nPrint 配置选项
-4, --ipv4 include ipv4 headers
-6, --ipv6 include ipv6 headers
-A, --absolute_timestamps include absolute timestmap field
-c, --count=INTEGER number of packets to parse ( if not all )
-C, --csv_file=FILE csv (hex packets) infile
-d, --device=STRING device to capture from if live capture
-e, --eth include eth headers
-f, --filter=STRING filter for libpcap
-F, --fill_int=INT8_T integer to fill missing bits with
-h, --nprint_filter_help print regex possibilities
-i, --icmp include icmp headers
-N, --nPrint_file=FILE nPrint infile
-O, --write_index=INTEGER Output file Index (first column) Options :
0: source IP (default)
1: destination IP
2: source port
3: destination port
4: flow (5-tuple)
-p, --payload=PAYLOAD_SIZE include n bytes of payload
-P, --pcap_file=FILE pcap infile
-R, --relative_timestamps include relative timestamp field
-S, --stats print stats about packets processed when finished
-t, --tcp include tcp headers
-u, --udp include udp headers
-V, --verbose print human readable packets with nPrints
-W, --write_file=FILE file for output , else stdout
-x, --nprint_filter=STRING regex to filter bits out of nPrint . nprint -h for details
-?, --help Give this help list
--usage Give a short usage message
--version Print program version
2. nPrintML 示例
作者提供了一个从头开始复现 4.4 节中结果的示例。
1)克隆存储库以获取数据
$ git clone repo_name
2)解压缩流量数据
$ tar -xvf dataset.tar.gz
3)编写一个脚本来生成标签
# Generate Labels, not necessary if labels exist
import sys
import pathlib
# Example file name: dataset/facebook/windows_chrome_facebook_1383.pcap
# Get file paths
paths = list(pathlib.Path(sys.argv[1]).rglob('*.pcap'))
for path in paths :
# Build label
tokens = str(path.stem).split('_')
label = '0_1'.format(tokens[0], tokens[1])
print('0,1'.format(path, label))
4)运行标签生成脚本
$ python gen_labels.py dataset/ > labels.txt
5)运行 nPrintML 执行流量分析
# IPv4, UDP, first 10 payload bytes of each packet:
$ nprintML -L labels.txt -a pcap --pcap_dir dataset/ -4 -u -p 10
# First 100 payload bytes of each packet:
$ nprintML -L labels.txt -a pcap --pcap_dir dataset/ -p 100
# UDP headers only:
$ nprintML -L labels.txt -a pcap --pcap_dir dataset/ -u
参考资料:
- Holland J, Schmitt P, Feamster N, et al. New directions in automated traffic analysis[C]//Proceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security. 2021: 3366-3383.
- Erickson N, Mueller J, Shirkov A, et al. Autogluon-tabular: Robust and accurate automl for structured data[J]. arXiv preprint arXiv:2003.06505, 2020.
- Holland J, Teixeira R, Schmitt P, et al. Classifying Network Vendors at Internet Scale[J]. arXiv preprint arXiv:2006.13086, 2020.
- Ren J, Dubois D J, Choffnes D. An International View of Privacy Risks for Mobile Apps[J]. 2019.
- https://mp.weixin.qq.com/s/QCTGWcL01DZ3sQYh4wQxGw
- https://www.freesion.com/article/4292383268/
- https://www.bilibili.com/video/BV1F84y1F7Ps/
- https://mp.weixin.qq.com/s/nCkqGmmVmUcGV1pxhLnFjg
- https://blog.csdn.net/weixin_43876557/article/details/106351768
以上是关于CCS 2021 | 自动化网络流量分析新方向的主要内容,如果未能解决你的问题,请参考以下文章