详细讲解MySQL的字符集与排序规则/校对规则(charactercollate)
Posted 董哥的黑板报
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了详细讲解MySQL的字符集与排序规则/校对规则(charactercollate)相关的知识,希望对你有一定的参考价值。
一、字符集和排序规则
- 数据库表被用来存储和检索数据。不同的语言和字符集需要以不同的方式存储和检索。因此,mysql需要适应不同的字符集(不同的字母和字符),适应不同的排序和检索数据的方法
- 在MySQL的正常数据库活动(select、insert等)中,不需要操心太多的东西。使用何种字符集和校对的决定在服务器、数据库和表级进行
几个重要术语
- 字符集:为字母和符号的集合
- 编码:为某个字符集成员的内部表示
- 排序规则:为规定字符如何比较的指令。(排序规则也称为"校对顺序")
为什么校对这么重要
- 排序英文其实没有想象的那么简单。考虑APE、apex和Apple,它们处于正确的排列顺序吗?这依赖于你是否想区分大小写。使用区分大小写的校对顺序,这些词有一种排序方式,使用不区分大小写的校对顺序。这不仅影响排序(如用order by排序数据),还影响搜索(例如,寻找apple的where子句是否能找到APPLE)
- 在使用诸如发文或德文这样的特殊字符时,情况更复杂,在使用不基于拉丁文的字符集(日文、希伯来文、俄文等)时,情况更复杂
二、MySQL的字符集支持
- MySQL支持多种字符集(character set),而且允许在服务器、数据库、表、列和字符串常量等不同层次单独指定字符集。例如,你想让某个表的列默认使用latin1字符集,但同时还想包含一个支持希伯来语(Hebrew)的列和一个支持希腊语(Greek)的列,这都是允许的。
- 此外,你还可以显式地指定排序规则。可以找出MySQL具体都支持哪些字符集和排序规则,也可以将数据从一种字符集转换为另一种。
- MySQL提供了以下这些字符集特性:
- MySQL服务器允许同时使用多种字符集。
- 一个给定地字符集可以有一种或多种排序规则。你可以为自己地应用挑选一种最适用地排序规则。
- 支持Unicode的字符集有:
- utf8和ucs2字符集,它们包括基本多文种平面(Basic Multilingual Plane,BMP,也称为"零号平面(Plane 0)",它是Unicode中地一个编码区段,编码范围包括U+000到U+FFFF)字符。
- 以及utf16、utf32和utf8mb4字符集,它们包括BMP字符和补充字符。
- MySQL 5.6.1增加了utf16le。该字符集与utf16很像,主要差异在于其适用地编码是低字节优先(little-endian),而非高字节优先(big-endian)。
- 你可以分别在服务器、数据库、表、列和字符串常量等这些层次指定字符集:
- MySQL服务器有一个默认字符集。
- 可以适用CREATE DATABSES语句来设置数据库的字符集;适用ALTER DATABASES语句来修改。
- CREATE TABLE和ALTER TABLE有专门的子句,用于设定表和列的字符集。
- 字符串常亮的字符集既可以通过上下文指定,也可以显式指定。
- 还有几个函数和运算符可用来将一些单独的值从一种字符集转换为另一种。CHARSET()函数可返回某个给定值的字符集。类似地,COLLATE运算符可以更改某个字符串的排序规则,而COLLATE()函数能返回某个给定字符串的排序规则。
- SHOW语句和INFORMATION_SCHEMA库里的数据库能提供与可用字符集和可用排序规则相关的信息。
- 当更改某个索引过的字符列时,MySQL服务器会自动对索引进行重新排序。
- 在一个字符串内部不能混用不同的字符集,也不能为某个给定列的不同行适用不同的字符集。不过,可以使用Unicode字符集(可以用一种编码表示多种语言的字符)来实现多语言支持。
三、查看支持的字符集和排序规则
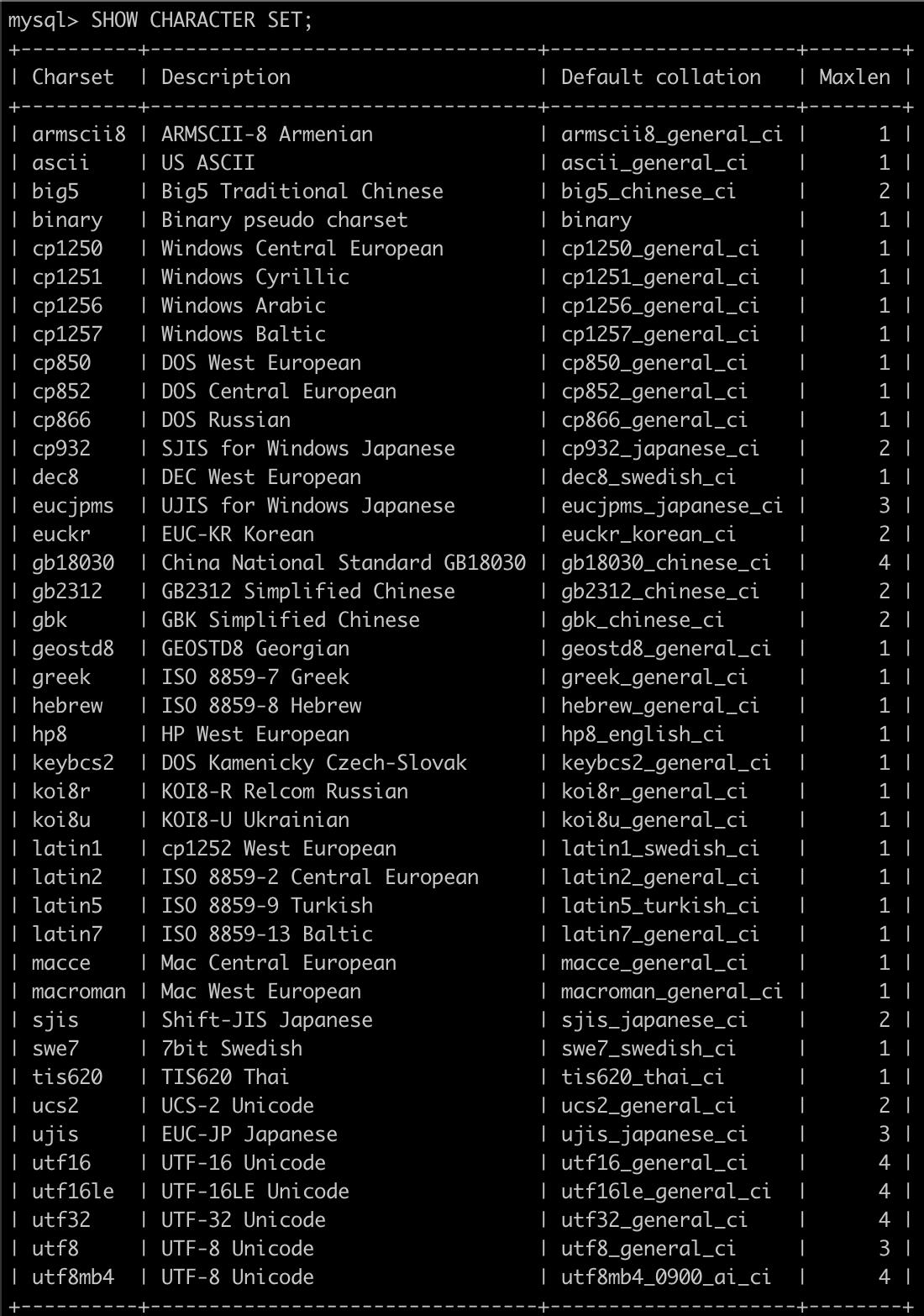
查看所支持的字符集
SHOW CHARACTER SET;
- MySQL支持众多的字符集。该语句可以所有可用的字符集以及每个字符集的描述和默认校对规则。如下所示:
查看所支持的校对列表
SHOW COLLATION;
- 以下语句可以查看所支持的所有校对(图片过长,截取部分)
- 例如,latin1对不同的欧洲语言有几种校对,而且许多校对出现两次,一次区分大小写(由_cs表示),一次不区分大小写(由_ci表示)


- SHOW语句支持LIKE子句,因此可以查询特定的字符集或排序规则。例如:
SHOW CHARACTER SET LIKE 'latin%';
SHOW COLLATION LIKE 'utf8%';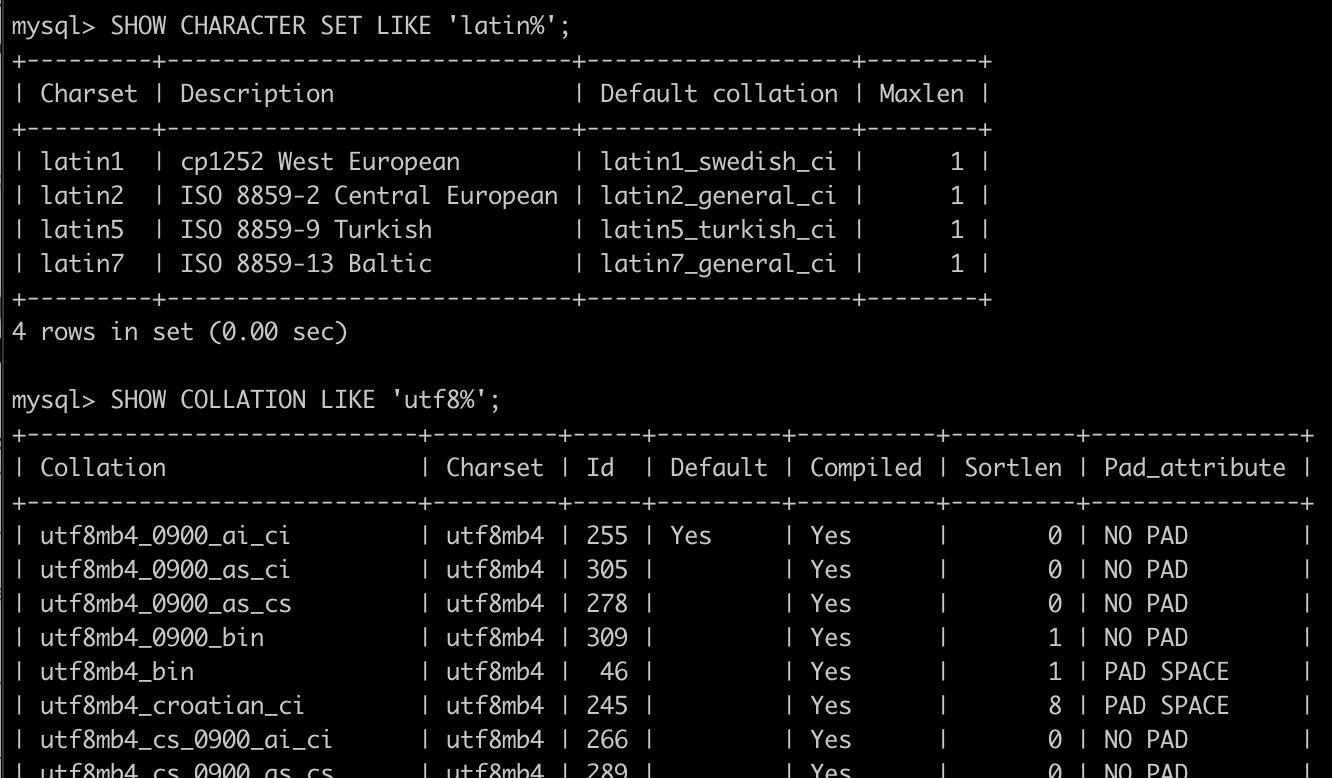
- 与可用字符集和排序规则有关的信息,还可以从INFORMATION_SCHEMA库的CHARACHTER_SETS表和COLLATIONS表里获得
四、查看当前的字符集和校对
- 数据库在安装时有一个默认的字符集和校对。此外,也可以在创建数据库时指定默认的字符集和校对
- 事实上,字符集很少是服务器范围(甚至数据库范围)的设置。不同的表,甚至不同的列都可能需要不同的字符集,而且两者可以在创建表时指定
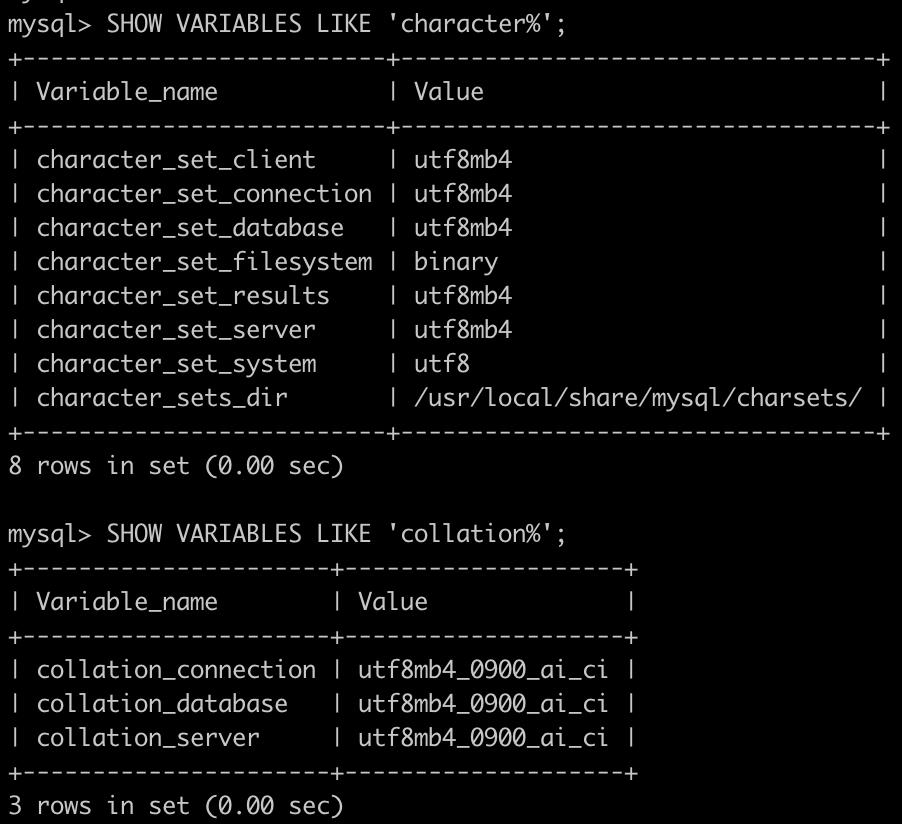
查看当前的字符集和校对
SHOW VARIABLES LIKE 'character%'; SHOW VARIABLES LIKE 'collation%';
- SHOW VARIABLES语句可以显示服务器当前的字符集和排序规则。例如:
五、指定字符集
- 字符集和排序规则可以在多个层次(从MySQL服务器所使用的默认字符集,一直到单个字符串所使用的字符集)进行设定。
- 服务器的默认字符集和排序规则是在编译时构建好的。但你可以在服务器启动或运行时,通过设置系统变量character-set-server和collation-server来改写它们。
- 如果只是指定字符集,那么其默认排序规则将会成为服务器的默认排序规则。如果指定了排序规则,那么它必须与字符集兼容。如果某种排序规则的名字是以某个字符集的名字作为开头,那么它们就是兼容的。例如,排序规则utf8_danish_ci与字符集utf8相兼容,但与字符集latin1不兼容。
语法格式
- 下面两个子句可以用来指定数据库/表/列的字符集和排序规则:
CHARACTER SET charset COLLATE collation
- 相关注意事项:
- CHARACTER SET可用CHARSET来代替。
- charset是服务器支持的某个字符集的名字,而collation是该字符集的某种排序规则的名字。
- 这两个子句可以同时使用,也可以分开使用。如果同时适用,必须保证排序规则的名字与字符集相兼容。
- 如果只给出了CHARACTER SET子句,则表示适用默认排序规则。
- 如果只给出了COLLATE子句,则使用由给定排序规则的名字的开头部分所确定的那个字符集。
创建数据库时指定规则
- 创建数据库时指定字符集和排序规则的语法如下:
CREATE DATABASE db_name CHARACTER SET charset COLLATE collation;创建表时指定规则
- 创建表时指定字符集和排序规则的语法如下:
CREATE TABLE tbl_name(...) CHARACTER SET charset COLLATE collation;给列指定规则
- 为表中的列指定字符集和排序规则的语法如下:这些属性适用于CHAR、VARCHAR、TEXT、ENUM、SET等数据类型
CREATE TABLE tbl_name( col_name CHAR(10) CHARACTER SET charset COLLATE collation );
六、在查询时指定校对规则
- 例如下面select语句使用collate指定一个备用的校对顺序(在这个例子中,为区分大小写的校对),这将会影响到结果排列的次序
SELECT * FROM customer ORDER BY cust_name COLLATE latin1_general_cs;临时区分大小写
- 上面的select语句演示了在通常不分区大小写的表上进行区分大小写搜索的一种技术。当然,反过来也是可以的
select的其它collate子句
- 除了上面看到的在order by子句中使用以下,collate还可以用于group by、having、聚集函数、别名等
- 最后,需要注意的是,如果绝对需要,串可以在字符集之间进行转换。为此,使用cast()或convert()函数
七、Unicode支持
- 之所以会有这么多种字符集,原因之一就是人们为不同的语言制定了不同的字符编码方案。从而会 导致好些问题。例如,如果某个给定字符存在于好几种语言里,它在不同的编码方案里就有可能被用不同的数字表示。还有,不同的语言往往要求使用数目不同的字节去表示一个字符。latinl字符集很小,每个字符只使用一个字节来表示即可。但对于某些语言,如日语和汉语,由于包含了非常多的字符,它们的每个字符都需要使用多个字节来表示。
- Unicode的目标是提供一种统 一的字符编码系统,让所有语言的字符集都能以一种统一的方式进行表示。
- utf8与ucs2这两种类型的Unicode字符集,都只包括了BMP里定义的字符,即最多只有65536个字符。它们都不支持BMP之外的那些补充字符。
- ucs2字符集与Unicode的UCS-2编码方案相对应。它使用2个字节来表示1个字符,并且最高有效字节(mostsignificantbyte)优先。UCS是通用字符集(Universal Character Set)的缩 写 。
- utf8字符集采用了一种长度可变的格式,使用1到3个字节来表示一个字符。它与UTF-8编码方案相对应。UTF是统一编码转换格式(Unicode Transformation Format) 的缩写。
- 从MySQL 5.5.3版本开 始,其他的Unicode字符集都包括了BMP之外的那些补充字符。
- 字符集utf16和utf32类似于ucs2,只是它们增加了对补充字符的支持。对于utf16,那些BMP字符仍然占2个 字节 (与 usc2—样 ),补充字符占4个字节 。对于utf32,所有字符都占4个字节。
- utf8mb4字符集包含了所有的utf8字符(其中,每个字符占1到3个字节),另外也包含了补充字符,其中,每个字条占4个字节 。
-
MySQL 5.6.1增加了对utf16le的支持。该字符集与utf16很像,主要差异在于它使用的是低字节优 先,而非高字节优先。
以上是关于详细讲解MySQL的字符集与排序规则/校对规则(charactercollate)的主要内容,如果未能解决你的问题,请参考以下文章