netty之二次解码MessageToMessageDecoder
Posted better_hui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了netty之二次解码MessageToMessageDecoder相关的知识,希望对你有一定的参考价值。
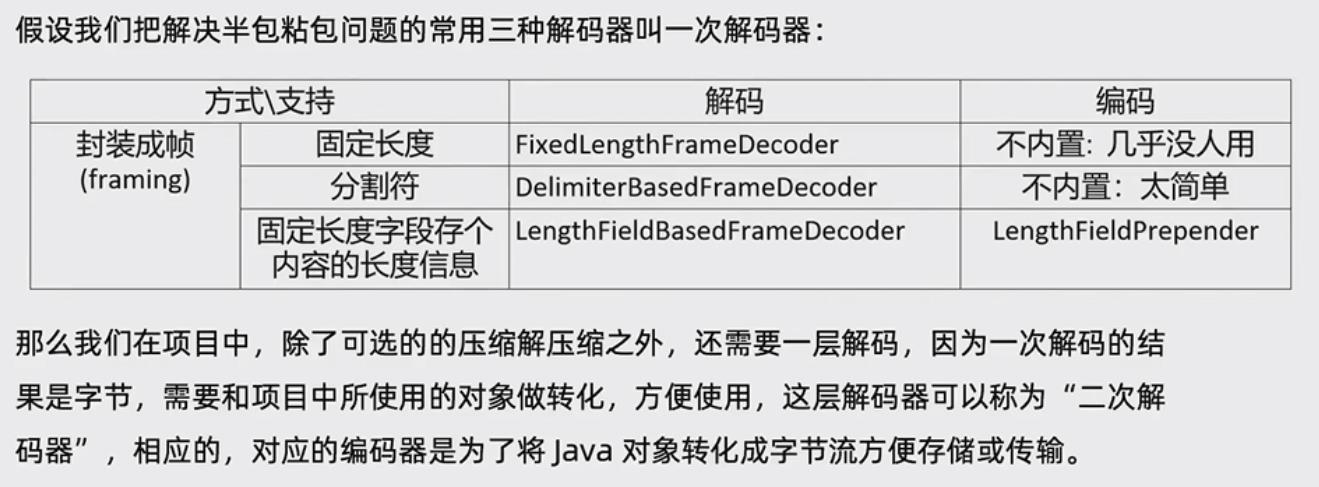
目录
1、ProtobufVarint32FrameDecoder
3、ProtobufVarint32LengthFieldPrepender
二次解码
我们将数据帧 转为正确的byte数组 我们称之为一次解码
将byte数据流转换为java对象 , 我们称之为二次解码
一次解码是将数据正确的拆分或者拼合 , 二次解码是将数据正确的序列化或者反序列化 。
这里用到了分层的思想 , 一边后续协议变更时,高耦合度代码修改量大的问题

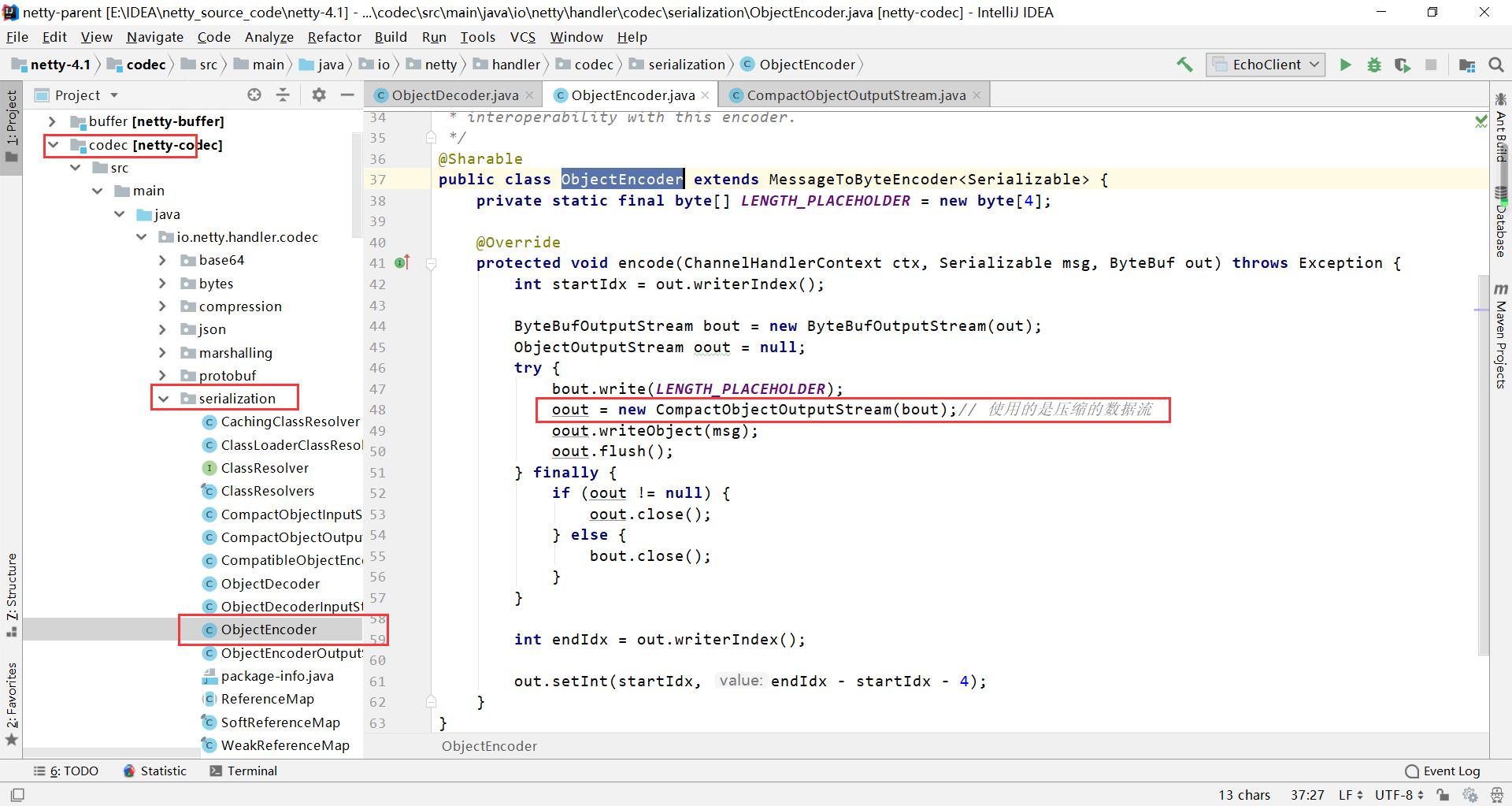
ObjectEncoder 如何实现编码
进入源码如图所示的包路径,第48行就是编码的核心方式,看得出来使用的是CompactObjectOutputStream的方式,也就是压缩了数据
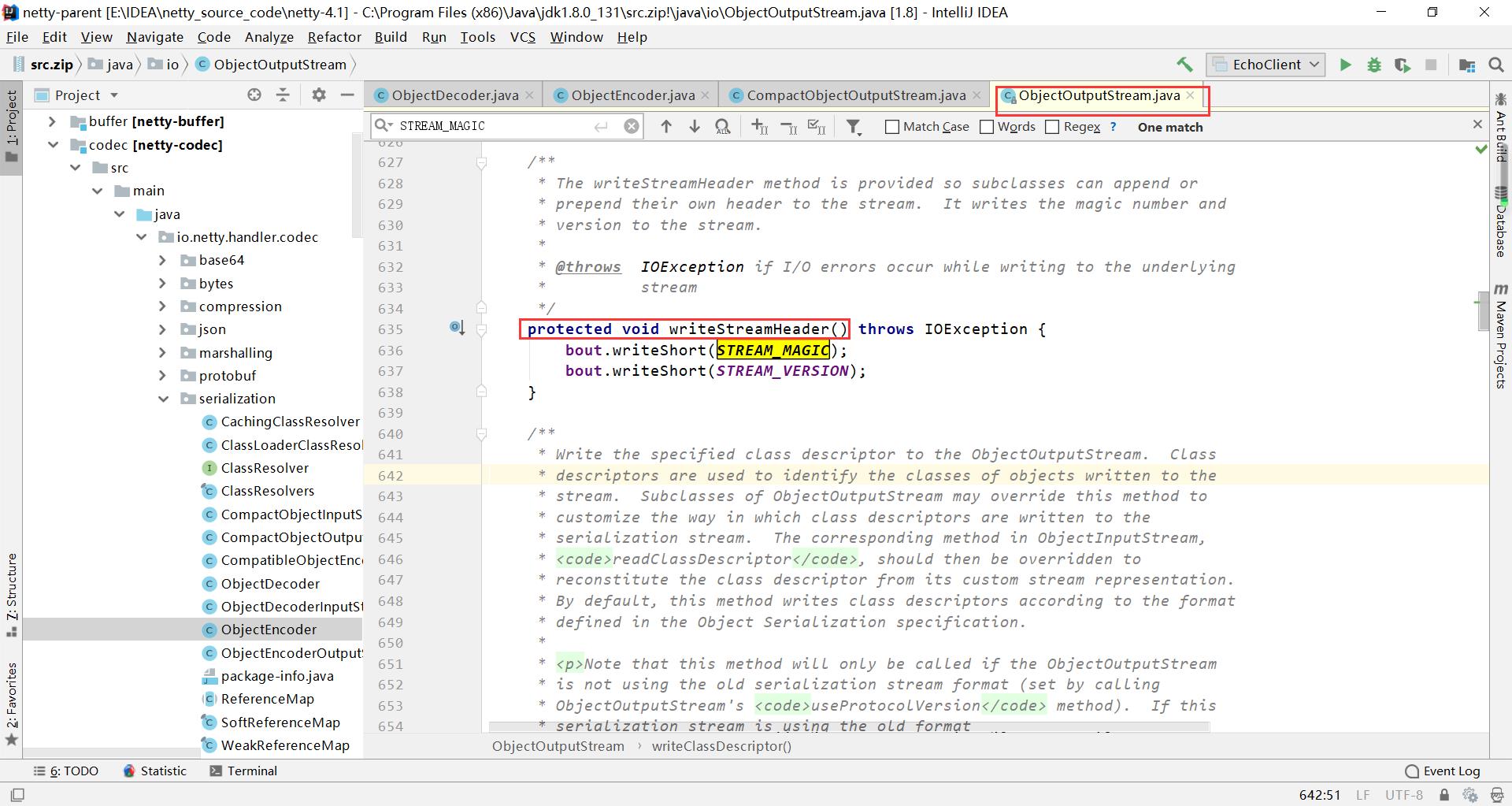
1、 writeStreamHeader
writeStreamHeader简化了STREAM_MAGIC字段
jdk自带的writeStreamHeader()方法中带有STREAM_MAGIC来标志当前协议类型,CompactObjectOutputStream类没有,用于节省空间
下图是java的jdk源码:
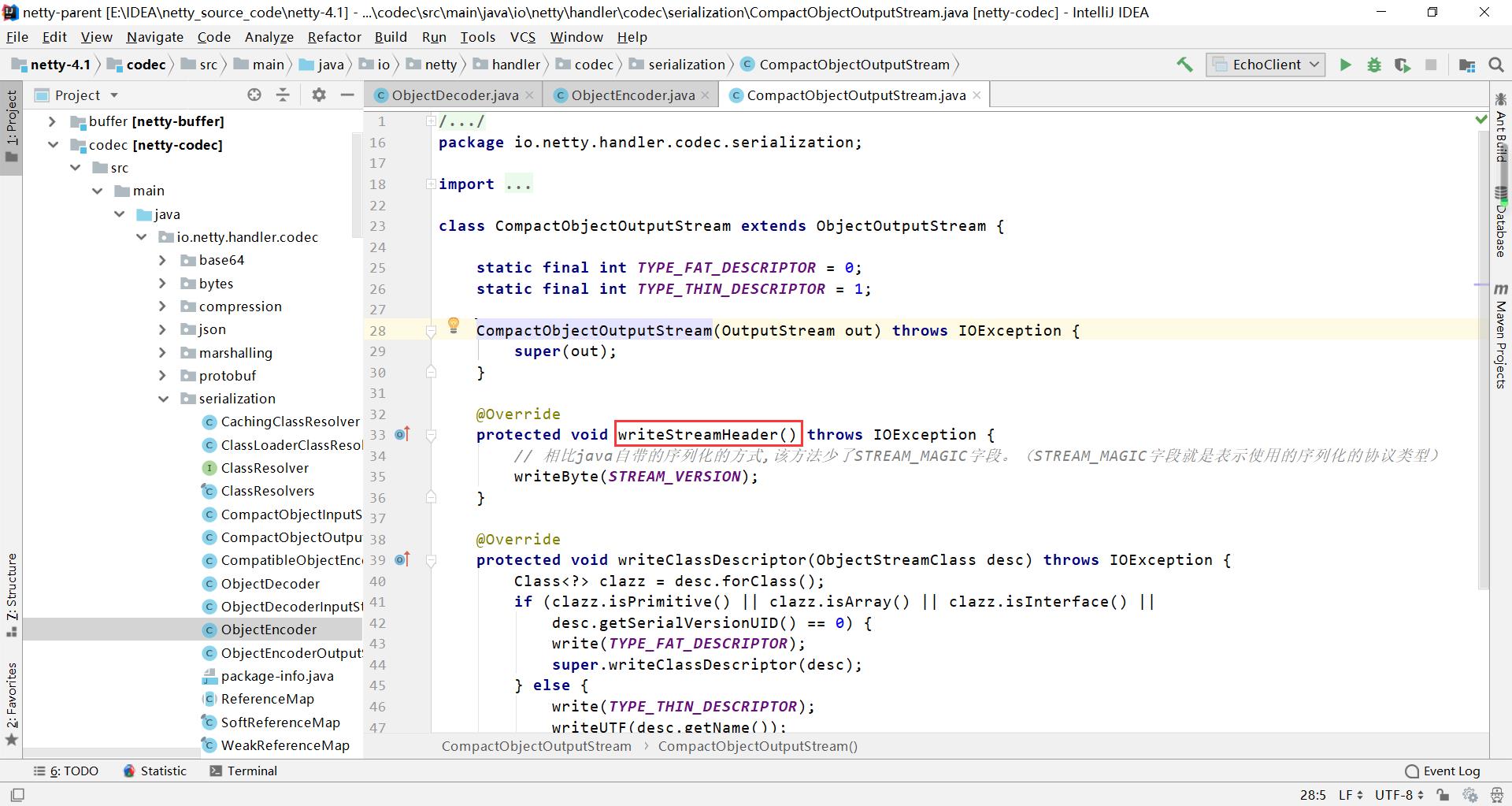
2、writeClassDescriptor
CompactObjectOutputStream对非原始数据类型,写入类的描述信息只有两行代码
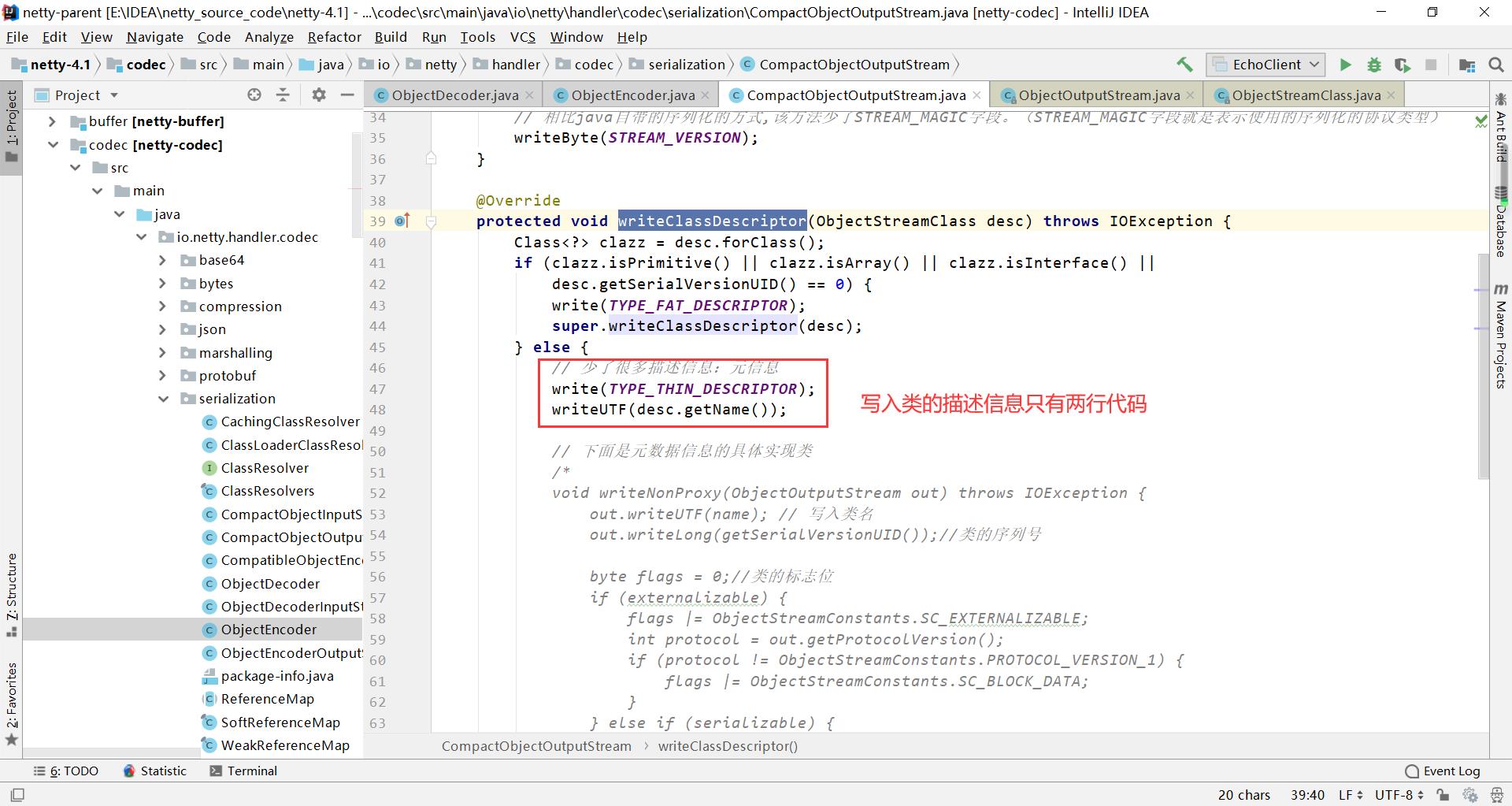
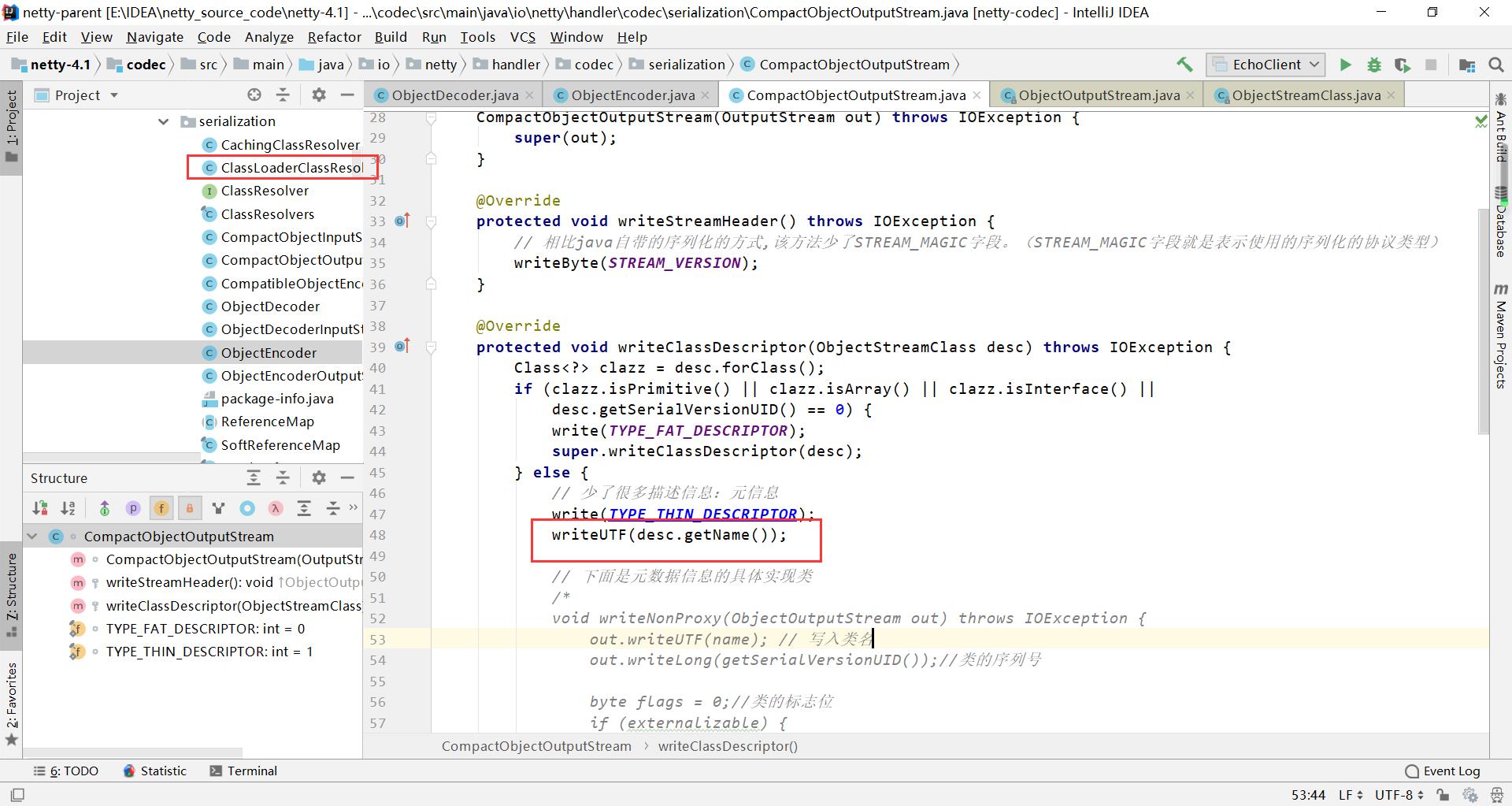
那么,既然这么多的描述信息都被删除了,那怎么实现反序列化呢? 关键就在于48行,写入了一个类的名称。同时看到下图左上角,包内有一个ClassLoader,它是利用反射去实现反序列化的。
总结
ObjectEncoder简化了魔术和元信息来减少数据的传输,使用反射的方式实现对原来的对象的反序列化。
protobuf的编码解码过程
WorldClockClientInitializer是netty中提供一个整合protobuf例子,提供了四个编码解码器
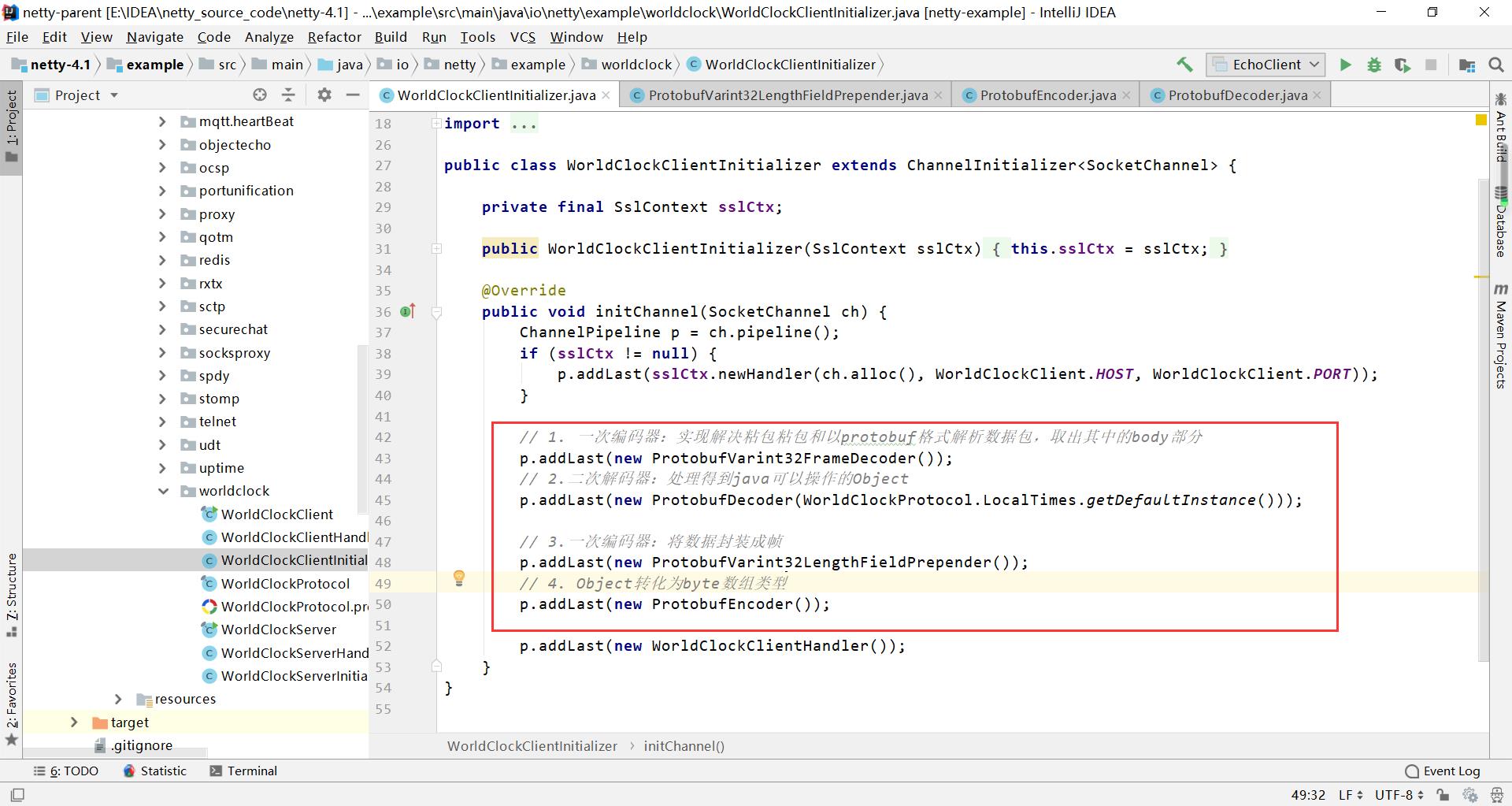
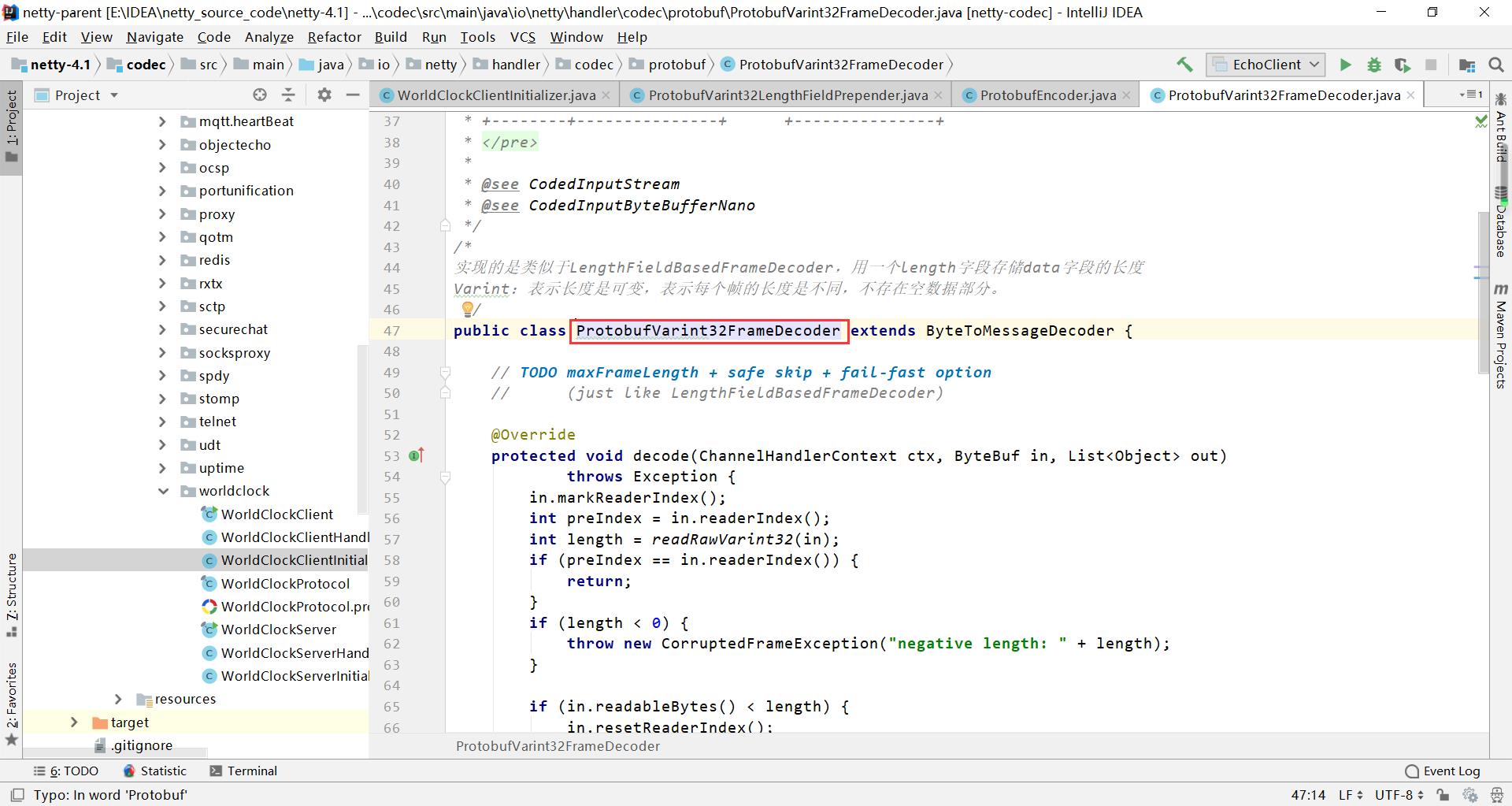
1、ProtobufVarint32FrameDecoder
ProtobufVarint32FrameDecoder是一个类似于LengthFieldBasedFrameDecoder,用一个字段存储length,然后data字段存储数据。 它做出的改进是,会根据根据数据的长度使用readRawVarint32方法去按照varint32的方式去读取头部的length长度。里面的int字段可变长度的就是他做出的改进。
2、ProtobufDecoder
ProtobufDecoder核心步骤: 1.类初始化的时候,判断是否含所有getParserForType方法,如果有HAS_PARSER为true 2.decode方法中,如果带有extension则按照扩展的解析方式解析,如果没有根据HAS_PARSER字段判断是mergeFrom()还是parseFrom()解析
@Sharable
public class ProtobufDecoder extends MessageToMessageDecoder<ByteBuf>
// HAS_PARSER是版本大于2.5.0才有的方法,旧版本的protobuf没有该方法
// HAS_PARSER用于标志protobuf中是否有getParserForType方法
private static final boolean HAS_PARSER;
static
boolean hasParser = false;
try
// MessageLite.getParserForType() is not available until protobuf 2.5.0.
MessageLite.class.getDeclaredMethod("getParserForType");// 反射获取getParserForType方法
hasParser = true;
catch (Throwable t)
// Ignore
HAS_PARSER = hasParser;
private final MessageLite prototype;
private final ExtensionRegistryLite extensionRegistry;
/**
* Creates a new instance.
*/
public ProtobufDecoder(MessageLite prototype)
this(prototype, null);
public ProtobufDecoder(MessageLite prototype, ExtensionRegistry extensionRegistry)
this(prototype, (ExtensionRegistryLite) extensionRegistry);
public ProtobufDecoder(MessageLite prototype, ExtensionRegistryLite extensionRegistry)
this.prototype = ObjectUtil.checkNotNull(prototype, "prototype").getDefaultInstanceForType();
this.extensionRegistry = extensionRegistry;
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf msg, List<Object> out)
throws Exception
final byte[] array;
final int offset;
final int length = msg.readableBytes();
if (msg.hasArray())
array = msg.array();
offset = msg.arrayOffset() + msg.readerIndex();
else
array = ByteBufUtil.getBytes(msg, msg.readerIndex(), length, false);
offset = 0;
// 带有extension字段则按照扩展的规则进行解析
if (extensionRegistry == null)
// HAS_PARSER表示是否含有getParserForType方法
if (HAS_PARSER)
// 使用parseFrom方法解析
out.add(prototype.getParserForType().parseFrom(array, offset, length));
else
// 使用mergeFrom方法解析
out.add(prototype.newBuilderForType().mergeFrom(array, offset, length).build());
else
if (HAS_PARSER)
out.add(prototype.getParserForType().parseFrom(
array, offset, length, extensionRegistry));
else
out.add(prototype.newBuilderForType().mergeFrom(
array, offset, length, extensionRegistry).build());
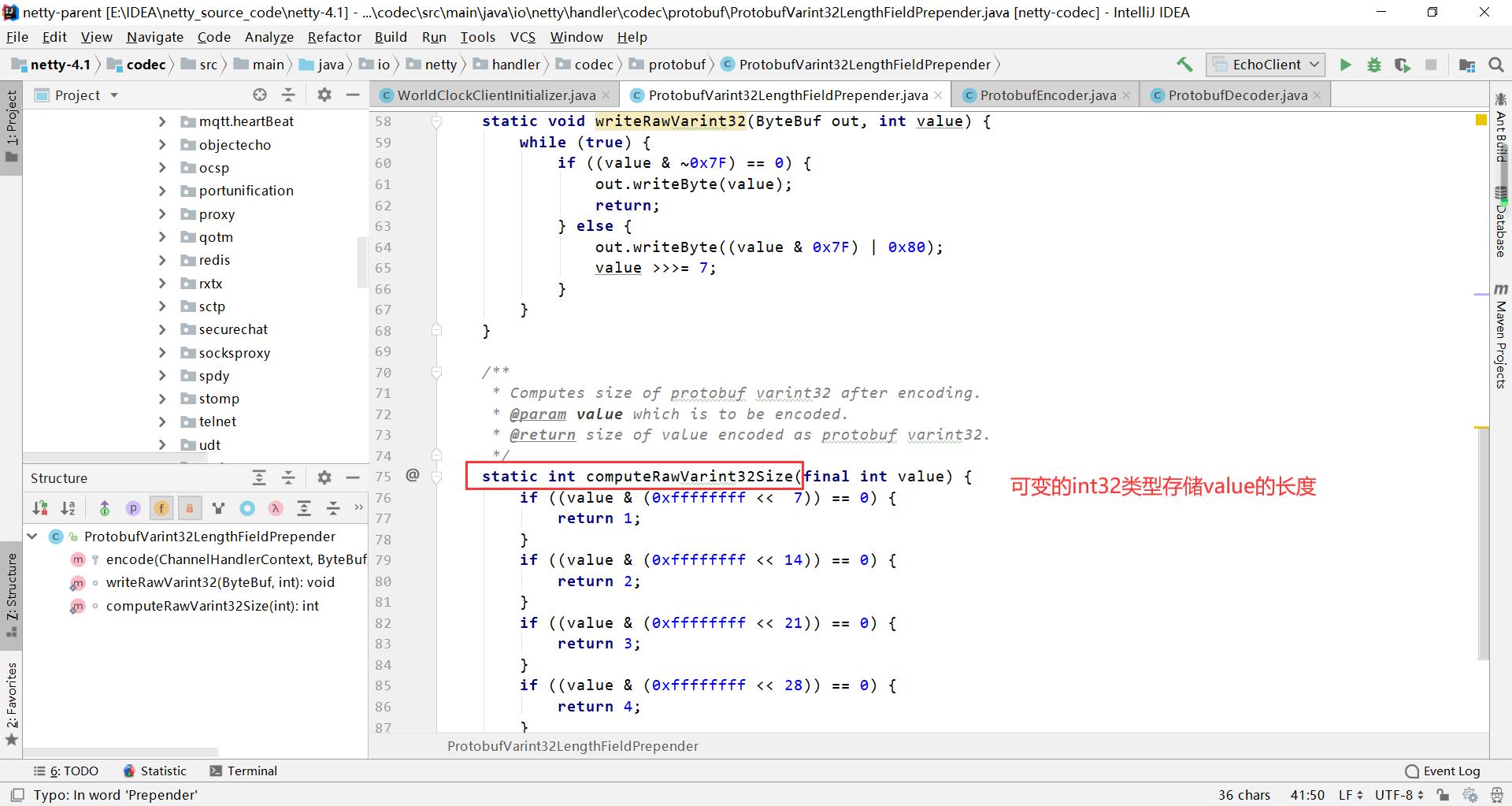
3、ProtobufVarint32LengthFieldPrepender
通过可变数据类型的规则解析body的数据长度
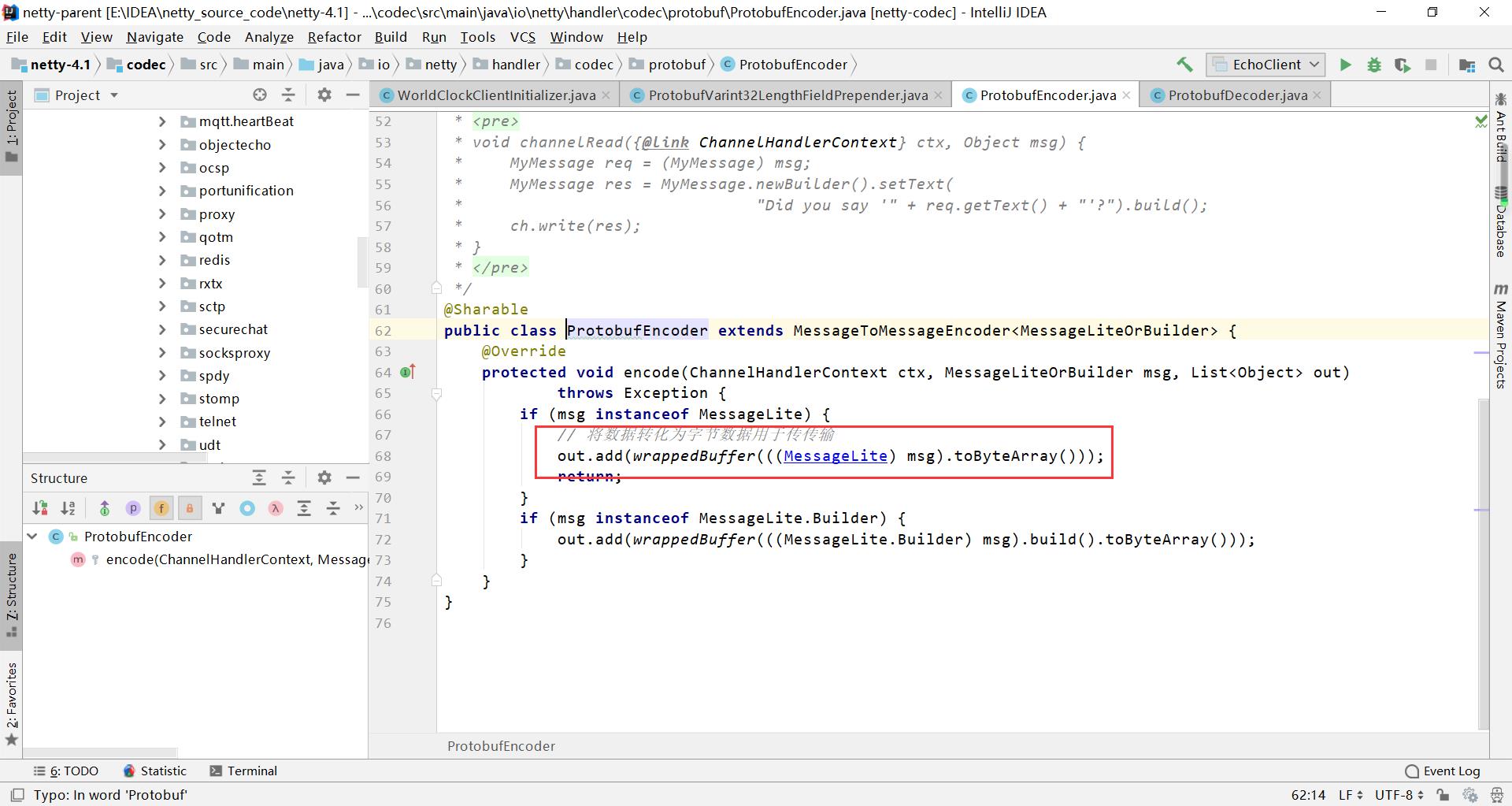
4、ProtobufEncoder
将数据转化为字节数据用于传传输
总结
protobuf对数据长度处理使用可变数据类型,减少数据的传输压力。
以上是关于netty之二次解码MessageToMessageDecoder的主要内容,如果未能解决你的问题,请参考以下文章