数据仓库期末复习
Posted 陈希瑞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据仓库期末复习相关的知识,希望对你有一定的参考价值。
1、什么是“数据仓库”?
数据仓库是用于存储海量数据以及供分析决策的工具。
补充:特点:面向主题的、集成的、非易失的、随时间变化的
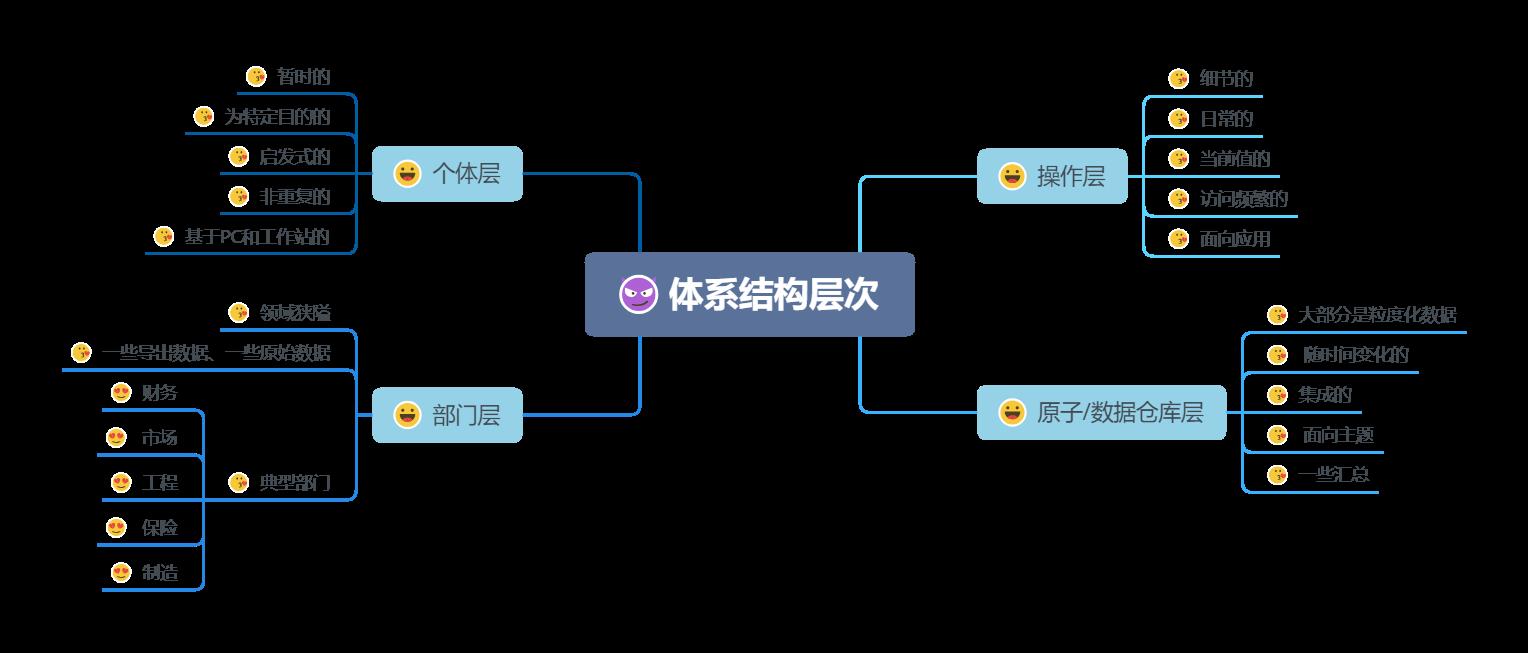
2、由于原始数据和导出数据的差异而引发数据分离的自然扩展过程形成的体系化环境的层次。
3、数据仓库中的数据组织形式。
- 简单堆积:以逐个记录为基础堆积的数据
- 轮转综合数据存储:比如每天的数据综合放到一个日槽中,七天后将七个日槽加到一起,放入周槽,月底将周槽相加放入月槽等。
- 简单直接文件:操作型数据间隔一定时间的一个快照。
- 连续文件:依据两个或更多的简单直接文件生成一种连续文件。[简单文件也可追加到连续文件]
4、数据仓库的数据集成。
概念:把不同类型的数据转换成同一种类型
- 当数据从操作型环境转向数据仓库环境时,需要对数据进行集成。
- 抽取、转换、加载(ETL)可以使复杂的未经集成的操作型数据处理自动进行。
- 操作型数据通常面向应用,是非集成的,而数据仓库中必须是集成的数据。
- 数据集成过程只需进行一次。
5、数据库与数据仓库的区别。
| 数据库 | 数据仓库 |
|---|---|
| 面向事务 | 面向主题 |
| 在线交易数据 | 历史数据 |
| 尽量避免冗余,采用符合范式的规则来设计 | 有意引入冗余,采用反范式的方式设计 |
| 读/写操作 | 一般为读操作 |
6、数据抽取的过程。
数据抽取过程:搜索整个文件或数据库(不会损害文件或数据库),使用某些标准选择合乎要求的数据,并把这些数据传送到其他文件或数据库中去。
补充
(1)对抽取数据做分析有性能优势,用户从控制变成拥有数据。
(2)失控的抽取模式——自然演化式体系结构
(3)自然演化式体系结构的问题:数据可信性 生产率问题 无法把数据转化为有效信息
7、粒度与分区。
粒度
- 概念:指数据仓库中数据单元的细节程度或综合程度的级别;
- 说明:粒度越大细节程度越低;粒度越小细节程度越高;
分区
- 概念:指把数据分散大可独立处理的分离物理单元中去。
- 好处:数据装载更简单、建立索引更顺畅、数据归档更容易等。
8、在数据仓库中原始数据和导出数据的区别。
| 原始数据/操作型数据 | 导出数据/DSS(决策支持系统)数据 |
|---|---|
| 面向应用;详细的;在访问瞬间是准确的 | 面向主题;概要的/精化的;代表过去的的数据,快照 |
| 为日常工作服务;可更新;重复运行 | 为管理者服务;不更新;启发式运行 |
| 处理需求预先可知 | 处理需求预不知道 |
| 生命周期符合SDLC;事务处理驱动 | 完全不同的生命周期;分析处理驱动 |
| 对性能要求高;一次访问一个单元 | 对性能要求宽松;一次访问一个集合 |
| 就操作型数据更新责任来说更新控制是一个主要关心的问题 | 无更新控制问题 |
| 高可用性;非冗余性 | 以子集管理;总是存在冗余 |
| 静态结构,可变的内容;一次处理数据量小 | 结构灵活;一次处理数据量大 |
| 支持日常操作;访问频繁 | 支持管理需求;访问很少或不多 |
注:sdlc(系统生命周期,系统生存周期)
9、Facebook与 Hive与Apache三者的关系。
hive由Facebook组织设计,用于解决海量结构化日志的数据统计,后交予Apache开源。
10、什么是Hive?
hive是基于hadoop的数据仓库工具,可以将结构化数据文件映射为一张表,并提供类SQL查询语句,能将HQL转换为MapReduce任务执行。
11、Hive的特点。
特点:采用类SQL语法、上手容易;学习成本低;延迟高,适合处理大数据,进行数据分析;支持自定义函数
换个问法:hive的优缺点
优点:采用类SQL语法上手容易;避免去写MapReduce,学习成本低;执行延迟高,适合处理大数据;支持自定义函数;
缺点:HQL表达能力有限,迭代式算法无法表达,数据挖掘方面不擅长;hive自动生成的MapReduce任务不够智能化;hive调优困难;
12、启动与停止hadoop,hive,mysql等的命令。
| 启动 | 停止 | |
|---|---|---|
| hadoop | start-dfs.sh/start-all.sh | stop-dfs.sh/stop-all.sh |
| hive | hive | quit; |
| mysql | service mysqld start | service mysqld stop |
补充:进入mysql交互界面:mysql -uroot -p
13、Hive的工作流程。
- 提交HQL查询需求
- 通过编译器对HQL语句进行解析编译
- 解析HQL后,发送元数据请求到元数据库
- 解析后重新将请求发送给驱动器
- 驱动器发送执行计划到执行器
- 完成MR任务
- 执行器接收到结果将结果反馈给驱动器,驱动器将最终执行结果返回给用户
14、Hive中的内部表和外部表。
-
内部表:创建时,会将数据移动到数据仓库指向的路径;删除时,内部表的元数据和原始数据会被一起删除。
-
外部表:创建时,仅记录数据所在路径,不改变数据的位置;删除时,外部表只删除元数据,不删除原始数据。
15、Hive与传统数据库的区别。
| hive | 传统数据库 | |
|---|---|---|
| 查询语言 | HQL | SQL |
| 数据存储位置 | HDFS | 块设备或本地文件系统 |
| 数据更新 | 读多写少 | 写入较多 |
| 索引 | 无索引,暴力扫描整个数据 | 有索引,效率高 |
| 执行 | HQL转MapReduce任务执行 | 有自己的执行引擎 |
| 执行延迟 | 高 | 低 |
| 可扩展性 | 高 | 低 |
| 数据规模 | 大 | 小 |
16、Hive中数据在HDFS上的存储形式。
- TEXTFILE
- SEQUENCEFILE
- RCFILE
- 自定义格式
17、Hive的系统架构的核心模块。
-
用户接口模块
-
驱动模块
-
元数据存储模块
18、Hive支持的数据类型。
Hive支持原始数据类型和复杂类型,原始类型包括数值型,Boolean,字符串,时间戳。复杂类型包括array,map,struct,union
19、在hive中,有哪些将数据装载和插入至数据表中的方法?
--Hadoop导入
hadoop fs -mkdir 'HDFS路径'
hadoop fs -put '本地路径' 'HDFS目标路径'
--load导入
load data loacl inpath '本地路径' into table db.table
load data inpath 'HDFS路径' into table db.table
--insert导入
insert into table table_name_01 select * from table_name_02;
20、Hive基本的DDL和DML语言操作命令(重点!)。
-- 创建数据库
create database test;
create database if not exists test;
create database test_01 location 'HDFS路径';
-- 查询数据库
--显示数据库
show databases;
--过滤显示的数据库
show databases like 'test*';
--显示数据库信息
desc database test;
--显示数据库详细信息(extended)
desc database extended test;
--切换数据库
use test;
-- 删除数据库
--删除空数据库
drop database if exists test;
--删除非空数据库
drop database test cascade;
-- 创建表
create table if not exists demo;
--创建外部表[external]
create external table if not exists demo;
--案例
create external table demo(
id int,
name string
)
row format delimited
fields terminated by ',';
--查看表类型
desc formated table_name;
--查看创建的表
show tables;
--查询表中数据
select * from table_name;
--创建分区表(案例)
create table t_all_hero_part(
id int,
name string,
hp_max int,
mp_max int,
attack_max int,
defense_max int,
attack_range string,
role_main string,
role_assist string
) partitioned by (role string)
row format delimited
fields terminated by '\\t';
--加载数据到分区表[静态加载]
load data local inpath '路径' into table t_all_hero_part partition(role='sheshou');
--增加分区
alter table t_all_hero_part add partition(role='tanke');
--删除分区
alter table t_all_hero_part drop partition(role='tanke');
--查看分区个数
show partitions t_all_hero_part;
-- 修改表
--重命名表
alter table old_table_name rename to new_table_name;
--修改列名
alter table emp_hr3 change employee_id employee_ids string;
--添加列
alter table table_name add columns(sex int);
--替换列
alter table table_name replace columns(
id int,
name string
);
-- 删除表
drop table table_name;
-- 清除表数据
truncate table table_name;

注:记住单词如何写
format、delimited、terminated、partitioned、external、truncate、fields、collection
left join
right join
full join
order by
group by
21、自然式演化的问题
- 数据可信性
- 生产率问题
- 无法将数据转化为有用信息
22、数据缺乏可信性
-
数据无时间基准
-
数据算法上的差异
-
抽取的多层次问题
-
外部数据问题
-
无公共起始数据源
以上是关于数据仓库期末复习的主要内容,如果未能解决你的问题,请参考以下文章