知识点 —— Python进阶-3
Posted 海绵小青年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了知识点 —— Python进阶-3相关的知识,希望对你有一定的参考价值。
Python进阶–3
单例模式
常用开发模式之一
用途
确保某一个类只有一个实例存在。当你希望在整个系统中,某个类只能出现一个实例时
比如,某个服务器程序的配置信息存放在一个文件中,客户端通过一个 AppConfig 的类来读取配置文件的信息。如果在程序运行期间,有很多地方都需要使用配置文件的内容,也就是说,很多地方都需要创建 AppConfig 对象的实例,这就导致系统中存在多个 AppConfig 的实例对象,而这样会严重浪费内存资源,尤其是在配置文件内容很多的情况下。事实上,类似 AppConfig 这样的类,我们希望在程序运行期间只存在一个实例对象。
实现
用到再说
模块–基础
什么是模块?
具有类似功能的函数或类的集合,将这些放在一个文件中,通过调用文件来使用这些功能
- 特点
不同模块内相同名字的函数不影响
模块调用
- import 模块名
- form 模块名 import 变量|函数|类|
- form 模块名 import *
__all__ = [使用*号可以访问的内容]
可以通过上述语句,限制*可以访问的模块内容
只针对此种导入方式有效
- 注意:
# 被调用的模块
# 函数定义
# 类定义
# 变量
# ......
if __name__ == "__main__": # 里面包含某些函数调用语句
test()
通过这样写,调用模块:from 模块 import * 的时候,就不会执行这些调用语句,只是加载了这个模块的函数|类等信息
包的调用
- 简化调用的目的吧,用到了再说
模块的循环导入
- 有时会因为相互之间的调用,出错
- 解决办法
改用包的形式
在函数内部导入,而不是在全局导入(比较常用)
代码重构
模块–系统模块
sys模块
time模块
import time
# 得到一个时间戳
a = time.time()
print(a)
# 将时间戳输出为字符串形式
b = time.ctime(a)
print(b)
# 将时间戳输出为元组形式
c = time.localtime(a)
print(c)
# 将元组格式的时间转换为时间戳
d = time.mktime(c)
print(d)
# 将元组的时间转为字符串
e = time.strftime("%Y-%m-%d %H:%M:%S")
print(e)
# 将字符串转换为元组的方式
s = time.strptime("2021/06/21", "%Y/%m/%d")
1629283055.1991527
Wed Aug 18 18:37:35 2021
time.struct_time(tm_year=2021, tm_mon=8, tm_mday=18, tm_hour=18, tm_min=37, tm_sec=35, tm_wday=2, tm_yday=230, tm_isdst=0)
1629283055.0
2021-08-18 18:37:35
datatime模块
# 时间有关模块
random模块
# 随机值模块
hashlib模块
# 加密模块
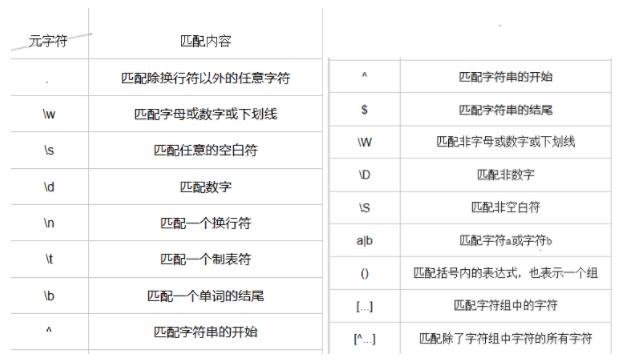
正则表达式
常用函数
- group()|groups()|start()|end()|span()
对匹配的结果的处理
import re
line = "This is the last one"
res = re.match( r'(.*) is (.*?) .*', line, re.M|re.I)
if res:
print("res.group() : ", res.group())
print("res.group(1) : ", res.group(1))
print("res.group(2) : ", res.group(2))
print("res.groups() : ", res.groups())
print("res.start() : ", res.start())
print("res.end() : ", res.end())
print("res.span() : ", res.span())
else:
print("No match!!")
res.group() : This is the last one
res.group(1) : This
res.group(2) : the
res.groups() : (‘This’, ‘the’)
res.start() : 0
res.end() : 20
res.span() : (0, 20)
- re.match()
尝试从字符串开头匹配一个模式
成功:返回成功匹配的对象
失败:返回None
import re
msg = '4534北京欢迎你9809i、'
a = re.match('北京欢迎你', msg)
print(a)
a = re.match('4534', msg)
print(a.span(), a.group())
None
(0, 4) 4534
- re.search()
扫描整个字符串,并返回第一次匹配成功的对象
失败则返回None
import re
result = re.search(r'[abc]\\*\\d2','12a*23Gb*12ad')
print(result.group())
# 只返回第一次匹配成功的对象,b*12也满足,但是没有匹配
a*23
- re.sub()
替换特定的字符串,并返回替换后的结果
替换可以是固定的格式,也可以是一种处理规则
import re
result = re.sub('#.*$', 'qqq', 'num = 0 #a number')
print(result)
def func(temp):
new = temp.group()
return str(int(new) + 1)
result = re.sub('\\d', func, 'num = 0 #a number')
print(result)
num = 0 qqq
num = 1 #a number
- re.split()
分割字符,返回列表信息
import re
s='abc, abc, defg, dds'
result = re.split('\\W+',s)
print(result)
[‘abc’, ‘abc’, ‘defg’, ‘dds’]
- re.findall()
匹配所有满足要求的字符串,列表形式返回
import re
result = re.findall(r'\\w*oo\\w*', 'woo this foo is too')
print(result)
[‘woo’, ‘foo’, ‘too’]
- re.finditer()
功能同于re.findall()
只是返回的类型是一个迭代器,而不是列表,更节省空间
import re
for i in re.finditer(r'\\d+','one12two34three56four') :
print(i.group())
12
34
56
- re.compile()
将正则表达式编译成一个语句
这样就可以将常用的正则表达式写的简单一点,方便调用
import re
s = "this is a python test"
p = re.compile('\\w+') #编译正则表达式,获得其对象
res = p.findall(s)#用正则表达式对象去匹配内容
print(res)
[‘this’, ‘is’, ‘a’, ‘python’, ‘test’]
正则匹配规则
- 字符串匹配规则
提供一个满足匹配要求的字符串序列
待匹配的字符存在于序列内,就算匹配成功
import re
# 匹配一个对象,是0-7的任一个数字
print(re.findall(r'[0-7]', '123qweAV4v'))
# 判断思路就是:1是不是0-7,是,下一个
# 2是不是0-7,是,下一个
# 3是不是0-7,是,下一个
# q是不是0-7,不是,下一个
# ......
# 匹配一个对象,是小写a-m的任一个字母
print(re.findall(r'[a-m]', '123qweAV4v'))
# 匹配一个对象,是大写A-K的任一个字母
print(re.findall(r'[A-K]', '123qweAV4v'))
# 匹配一个对象,是数字或字母
print(re.findall(r'[0-9a-zA-Z]', '123qweAV4v'))
[‘1’, ‘2’, ‘3’, ‘4’]
[‘e’]
[‘A’]
[‘1’, ‘2’, ‘3’, ‘q’, ‘w’, ‘e’, ‘A’, ‘V’, ‘4’, ‘v’]
- 字符匹配规则
匹配单个字符
import re
# 匹配数字+字母这样格式的两位字符,例如:1B、2c、4D
print(re.findall(r'\\d\\w', '123 qw eA V4v'))
# 匹配两个连在一次的数字,且第二个数字再结尾,即后边是空格或什么的
print(re.findall(r'\\d\\d\\b', '123 qw eA V4v'))
# 匹配 V数字v 这种格式的字符串,并返回这个数字
print(re.findall(r'[V](\\d)[v]', '123 qw eA V4vv4v'))
[‘12’, ‘4v’]
[‘23’]
[‘4’]
- 数量匹配规则
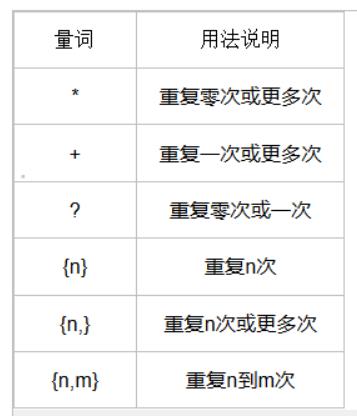
import re
# 匹配数字+字母这样格式的两位字符,例如:1B、2c、4D
result = re.findall(r'(.2) is .*?', 'xxx is qqq, ooo is bbb')
print(result)
[‘xx’, ‘oo’]
标志位
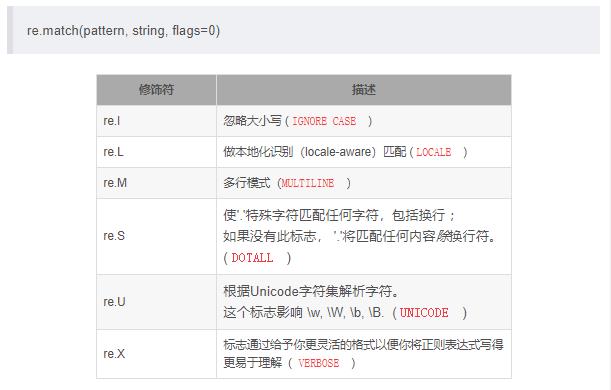
重复表达式的调用
import re
strs = '<html><h1>你好啊<h1><html>'
result = re.match(r'(<\\w+>)(<\\w\\d>)(.+)\\2\\1', strs)
print(result.group())
print(result.group(1))
print(result.group(2))
print(result.group(3))
result = re.match(r'(?P<name1><\\w+>)(?P<name2><\\w\\d>)(.+)(?P=name2)(?P=name1)', strs)
print(result.group())
print(result.group(1))
print(result.group(2))
print(result.group(3))
r’(<\\w+>)(<\\w\\d>)(.+)\\2\\1’
\\2 = (<\\w\\d>)
\\1=<\\w+>)
r’(?P<\\w+>)(?P<\\w\\d>)(.+)(?P=name2)(?P=name1)’
(?P<\\w+>) 表示名字为name1的正则表达式,其表达式为(<\\w+>)
(?P=name2) 表示调用名字为name2的正则表达式

贪婪匹配
默认贪婪匹配,尽可能匹配多的字符串
在量词,即数量匹配后面加个?号,就变成非贪婪匹配
import re
strs = 'abc123bdb'
result = re.match(r'abc(\\d+)', strs)
print(result.group())
result = re.match(r'abc(\\d+?)', strs)
print(result.group())
abc123
abc1
进程
基本概念
- 多任务
单核CPU:操作系统轮流让各个任务交替执行
例:QQ执行2us,微信执行2us…
切换速度很快,以至于人们以为是在一起执行
多核CPU:可以真正实现多任务执行
每个任务都分配到一个核心上执行,真正实现多任务
但是任务数>>核心数,轮流调度执行还是会存在
- 并发和并行
并发(Concurrent):多个线程,且只有一个CPU
一次只能执行一个线程,其他线程处于挂起状态,然后轮流来执行
并行(Parallel):系统有多个CPU
可能实现非并发,即一个线程有一个CPU来做,另外一个线程有另外的CPU来做
- 多任务实现模式
基本模式
多进程模式
多线程模式
协程
关系
进程 > 线程 > 协程
一个进程可以有多个线程
一个线程可以有多个协程
- 进程创建
from multiprocessing import Process
process = Process(target= 函数,name=进程的名字,args=(给函数传递的参数))
对象调用方法:
process.start() 启动进程并执行任务
process.run() 只是执行了任务但是没有启动进程
terminate() 终止
# 进程创建
import os
from multiprocessing import Process
from time import sleep
def task1(s, name):
while True:
sleep(s)
print('这是任务1.。。。。。。。。。。', os.getpid(), '------', os.getppid(), name) # 进程ID,父进程ID
def task2(s, name):
while True:
sleep(s)
print('这是任务2.。。。。。。。。。。', os.getpid(), '------', os.getppid(), name)
number = 1
if __name__ == '__main__':
print(os.getpid())
# 子进程
p = Process(target=task1, name='任务1', args=(1, 'aa')) # 进程传参
p.start()
print(p.name)
p1 = Process(target=task2, name='任务2', args=(2, 'bb'))
p1.start()
print(p1.name)
while True:
number += 1
sleep(0.2)
if number == 100:
p.terminate()
p1.terminate()
break
else:
print('---------------->number:',number)
print('--------------')
print('*****************')
主进程:即整个程序的加载
子进程:程序加载后,运行到P和P1子进程的创建
进程创建之后,不能保证进程间的执行顺序,是随机的
- 进程间的全局变量问题
# 进程创建
'''
多进程对于全局变量访问,在每一个全局变量里面都放一个m变量,
保证每个进程访问变量互不干扰。
m = 1 # 不可变类型
list1 = [] # 可变类型
主进程启动子进程,启动之后无法控制是谁先谁后
'''
import os
from multiprocessing import Process
from time import sleep
m = 1 # 不可变类型
list1 = [] # 可变类型
def task1(s, name):
global m
while True:
sleep(s)
m += 1
list1.append(str(m) + 'task1')
print('这是任务1.。。。。。。。。。。', m, list1)
def task2(s, name):
global m
while True:
sleep(s)
m += 1
list1.append(str(m) + 'task2')
print('这是任务2.。。。。。。。。。。', m, list1)
if __name__ == '__main__':
# 子进程
p = Process(target=task1, name='任务1', args=(1, 'aa'))
p.start()
p1 = Process(target=task2, name='任务2', args=(2, 'bb'))
p1.start()
while True:
sleep(1)
m += 1
print('--------->main:', m)
- 进程间通信
# 进程间通信
from multiprocessing import Queue
q = Queue(5)
q.put('A')
q.put('B')
q.put('C')
q.put('D')
q.put('E')
print(q.qsize())
if not q.full(): # 判断队列是否满 q.empty() 判断队列是否是空的
q.put('F', timeout=3) # put() 如果queue满了则只能等待,除非有‘空地’则添加成功
else:
print('队列已满!')
# 获取队列的值
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
print(q.get(timeout=2))
# q.put_nowait()
# q.get_nowait()
# 进程间通信
from multiprocessing import Process, Queue
from time import sleep
def download(q):
images = ['girl.jpg', 'boy.jpg', 'man.jpg']
for image in images:
print('正在下载:', image)
sleep(0.5)
q.put(image)
def getfile(q):
while True:
try:
file = q.get(timeout=5)
print('保存成功!'.format(file))
except:
print('全部保存完毕!')
break
if __name__ == '__main__':
q = Queue(5)
p1 = Process(target=download, args=(q,))
p2 = Process(target=getfile, args=(q,))
p1.start()
# p1.join()
p2.start()
# p2.join() # 阻塞一下
print('00000000000')
自定义进程
# 进程:自定义
from multiprocessing import Process
class MyProcess(Process):
def __init__(self, name, num):
super(MyProcess, self).__init__()
self.name = name
self.num = num
# 重写run方法
def run(self):
n = 1
while True:
# print('进程名字:' + self.name)
print('--------->自定义进程,n:'.format(n, self.name))
n += 1
if __name__ == '__main__':
p = MyProcess('小明', 10)
p.start()
p1 = MyProcess('小红')
p1.start()
进程池
- 基本概念
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态成生多个进程,
但如果是上百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的Pool方法。
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,
那么就会创建一个新的进程用来执行该请求;但如果池中的进程数已经达到指定的最大值,那么该请求就会等待,
直到池中有进程结束,才会创建新的进程来执行。
- 非阻塞式进程
import os
from multiprocessing import Pool
import time
# 非阻塞式进程
from random import random
def task(task_name):
print('开始做任务啦!', task_name)
start = time.time()
# 使用sleep
time.sleep(random() * 2)
end = time.time()
# print()
# return '完成任务:!用时:,进程id:'.format(task_name, (end - start), os.getpid())
print('完成任务:!用时:,进程id:'.format(task_name, (end - start), os.getpid()))
container = []
# 回调函数
def callback_func(n):
container.append(n)
if __name__ == '__main__':
pool = Pool(5)
tasks = ['听音乐', '吃饭', '洗衣服', '打游戏', '散步', '看孩子', '做饭']
for task1 in tasks:
pool.apply_async(task, args=(task1,), callback=callback_func)
pool.close() # 添加任务结束
pool.join() #
for c in container:
print(c)
print('over!!!!!')
- 阻塞式进程
# 阻塞式
import os
import time
from multiprocessing import Pool
from random import random
'''
特点:
添加一个执行一个任务,如果一个任务不结束另一个任务就进不来。
进程池:
pool = Pool(max) 创建进程池对象
pool.apply() 阻塞的
pool.apply_async() 非阻塞的
pool.close()
pool.join() 让主进程让步
'''
def task(task_name):
print('开始做任务啦!', task_name)
start = time.time()
# 使用sleep
time.sleep(random() * 2)
end = time.time()
print('完成任务:!用时:,进程id:'.format(task_name, (end - start), os.getpid以上是关于知识点 —— Python进阶-3的主要内容,如果未能解决你的问题,请参考以下文章