计算着色器(Compute Shaders)
Posted 大哥大嫂过年好啊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了计算着色器(Compute Shaders)相关的知识,希望对你有一定的参考价值。
原文 : https://catlikecoding.com/unity/tutorials/basics/compute-shaders/
1 将工作转移到GPU(Moving Work to the GPU)
我们图形的分辨率越高,CPU和GPU需要做的工作就越多,即计算位置和渲染方块。点的数量等于分辨率的平方,所以双倍的分辨率会显著的增加工作负载。我们也许在分辨率100的时候能达到60FPS,但是我们又能推进多远?并且如果我们抵达了一个瓶颈我们能否使用不同的方法越过瓶颈?
1.1 分辨率200(Resolution 200)
让我们从将Graph 的最大分辨率从100提升到200开始,并且看一下我们能得到什么样的性能。
[SerializeField, Range(10, 200)]
int resolution = 10;

Graph with resolution set to 200.
我们现在渲染了40 000 个点。我这里的平均分辨率,DRP降到了10FPS,URP降到了15FPS。


Profiling a build at resolution 200, without VSync, DRP and URP.
1.2 GPU 图像(GPU Graph)
排序、批处理,然后将40 000个点的变换矩阵发送给GPU消耗很多时间。单个矩阵包含16个float 数字,每个是4 字节,一个矩阵就是总共64 字节。40 000 个点就是2.56 百万字节--差不多2.44M--每次花这些点时都要复制给GPU。这些事URP每帧要做两次,一次是阴影,一次是常规几何图形。DRP至少要做三次,因为它的额外的深度通道,除此之外,除了主平行光之外的每盏灯都要再加一次。
通常情况下,最好将CPU和GPU间的通信和数据量降到最低。由于我们只需要点的位置来显示他们,最好是这些数据只存在于GPU。这会消除许多数据转换。但是CPU将不再计算位置,转而交由CPU计算。幸运的是它很适合这个任务。
让CPU计算位置需要一个不同的方法。我们将创建一个新的图像,并保留目前的图像作为对比。复制Graph 脚本并重命名为GPUGraph。移除pointPrefab 和 points 字段,并移除 Awake, UpdateFunction, and UpdateFunctionTransition 方法。
using UnityEngine;
public class GPUGraph : MonoBehaviour
//[SerializeField]
//Transform pointPrefab;
[SerializeField, Range(10, 200)]
int resolution = 10;
[SerializeField]
FunctionLibrary.FunctionName function;
public enum TransitionMode Cycle, Random
[SerializeField]
TransitionMode transitionMode = TransitionMode.Cycle;
[SerializeField, Min(0f)]
float functionDuration = 1f, transitionDuration = 1f;
//Transform[] points;
float duration;
bool transitioning;
FunctionLibrary.FunctionName transitionFunction;
//void Awake () …
void Update () …
void PickNextFunction () …
//void UpdateFunction () …
//void UpdateFunctionTransition () …
然后在Update 中移除这些函数的调用
void Update ()
…
//if (transitioning)
// UpdateFunctionTransition();
//
//else
// UpdateFunction();
//
我们的GPUGraph 组件与Graph 内部不同,但有着相同的配置选项,除了预制件。它包含了功能之间转换的逻辑,但除此之外不做任何事。创建一个游戏对象并添加此组件,resolution为200,Transition Mode 为 Cycle。
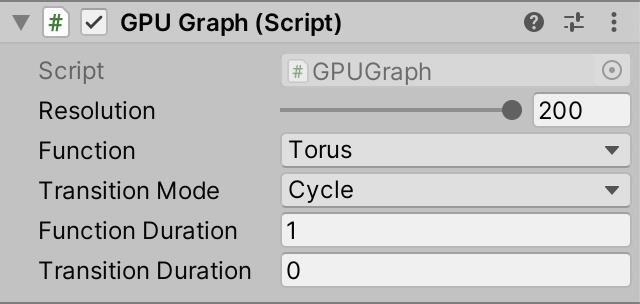
GPU graph component, set to instantaneous transitions.
1.3 计算缓冲区(Compute Buffer)
为了保存GPU上的位置,我们需要为他们申请空间。为此我们创建一个ComputeBuffer 对象。在GPUGraph 中添加一个位置缓冲区字段,并在Awake 函数中通过调用new ComputeBuffer()创建对象。
ComputeBuffer positionsBuffer;
void Awake ()
positionsBuffer = new ComputeBuffer();
我们需要传递给缓冲区元素的数量作为参数,也就是分辨率的平方,就像Graph.的位置数组一样。
positionsBuffer = new ComputeBuffer(resolution * resolution);compute buffer 包含任意无类型数据。通过第二个参数,我们需要指定每个元素精确的尺寸。我们需要存储3D位置向量,即包含3个float 数字,所以每个元素是3倍的4 bytes。
positionsBuffer = new ComputeBuffer(resolution * resolution, 3 * 4);现在我们得到了一个compute buffer,但是这些对象不会再热重载时生存(not survive hot reloads),也就是说如果我们在play模式下修改代码它就会消失。我们可以将其从Awake 函数替换到 OnEnable 函数,每次组件被激活时它都会被调用。
void OnEnable ()
positionsBuffer = new ComputeBuffer(resolution * resolution, 3 * 4);
除此之外我们还需要添加 OnDisable 函数,当组件禁用时会被调用,同时在被销毁和热重载之前被调用。通过在其中调用Release 函数来释放缓冲区。这样声明的GPU内存可以被立即释放。
void OnDisable ()
positionsBuffer.Release();
由于这之后我们不在使用这个对象实例,最好将这个字段设为null 。这使得Unity的垃圾回收机制下次运行时可以回收这个对象,如果我们的图像在play模式时被禁用或销毁。
void OnDisable ()
positionsBuffer.Release();
positionsBuffer = null;
1.4 计算着色器(Compute Shader)
为了在GPU上计算位置,我们必须为其写一个脚本,也就是一个计算着色器,通过 Assets / Create / Shader / Compute Shader 创建。它将成为我们FunctionLibrary 类的GPU等价物,所以也将其命名为FunctionLibrary 。虽然它是作为一个着色器并使用HLSL 语法,但它作为通用程序运行,而不是常规的用作渲染东西的着色器。因此我将其放置在Scripts 文件夹。

Function library compute shader asset.
打开这个文件并移除它默认的内容。一个计算着色器需要包含一个主函数作为核心,通过#pragma kernel 指令后面跟着一个名字来指定,就像我们表面着色器的#pragma surface。这条指令作为第一行也是当前唯一一行,使用名字FunctionKernel
#pragma kernel FunctionKernel在指令下面来定义函数。
#pragma kernel FunctionKernel
void FunctionKernel () 1.5 计算线程(Compute Threads)
当GPU被安排执行计算着色器时,它将它的任务划分为多个组然后独立的或平行的调度他们。每个组由若干线程组成,这些线程执行相同的计算但是有不同的输入。通过为我们的核心函数添加numthreads 属性,我们必须详细说明每个组有多少个线程。最简单的选项是所有三个参数都使用1,这使每个组只运行一个线程。
[numthreads(1, 1, 1)]
void FunctionKernel () GPU 硬件包含始终执行特定数量的lockstep里的线程的计算单元。它们被称为warps 或 wavefronts。如果一个组的线程数比warp 大小要小,一些线程就会空运转,浪费时间。如果线程数量超出了,CPU会给每个组使用更多warps。通常,默认使用64个线程比较好,因为这和ADM GPU的warp大小匹配,如果是NVidia GPU则是32,所以后者每个组将使用两个warp。在现实中硬件会更复杂并且会对线程组做更多,但是这和我们简单的图形无关。
numthreads 的三个参数可以被用来组织线程是1、 2 还是3维度的。例如,(64, 1, 1)是一维的,而(8, 8, 1) 数量相同但是提供了一个2D 的8X8 方格。由于我们基于2D uv坐标定义我们的点,我们使用后者。
[numthreads(8, 8, 1)]这里的线程是包含三个无符号整型的向量,我们可以通过给我们的函数添加uint3 参数来实现。
void FunctionKernel (uint3 id) 我们必须明确的指明这个参数是作为线程标识。为此我们在参数名字后面添加SV_DispatchThreadID 关键字。
void FunctionKernel (uint3 id: SV_DispatchThreadID) 1.6 UV坐标(UV Coordinates)
如果我们知道图像的步长,我们可以将线程标识转换为坐标。给计算着色器添加一个属性命名为_Step ,就像我们给我们的表面着色器添加_Smoothness
float _Step;
[numthreads(8, 8, 1)]
void FunctionKernel (uint3 id: SV_DispatchThreadID) 然后创建一个GetUV 函数,将线程标识作为它的参数并返回float2型的UV坐标。我们可以使用Graph 中循环点时同样的逻辑。
float _Step;
float2 GetUV (uint3 id)
return (id.xy + 0.5) * _Step - 1.0;
1.7 设置位置(Setting Positions)
为了存储位置我们需要访问位置缓冲区。在HLSL 中,一个计算缓冲区被看作是一个结构体缓冲区。因为我们需要对其进行读写,所以添加一个RWStructuredBuffer. 字段,命名为_Positions
RWStructuredBuffer _Positions;
float _Step;在这个例子中我们需要列出缓冲区元素的类型。位置是float3 值,我们直接写在RWStructuredBuffer 后面,并用尖括号括起来。
RWStructuredBuffer<float3> _Positions;为了存储点的位置,我们需要基于线程标识为其分配一个索引。我们需要知道图像的分辨率。所以添加一个_Resolution 属性,类型是uint 以匹配标识的类型。
RWStructuredBuffer<float3> _Positions;
uint _Resolution;
float _Step;然后创建一个SetPosition 函数以设置点,传递它一个标识和要设置的点。我们将使用标识的x 部分加上y部分乘以分辨率作为索引。这样我们就将2D数据按顺序存储到了1D数组中。
float2 GetUV (uint3 id)
return (id.xy + 0.5) * _Step - 1.0;
void SetPosition (uint3 id, float3 position)
_Positions[id.x + id.y * _Resolution] = position;

Position indices for 3×3 grid.
需要注意的是我们组的每个计算都是8*8个点的网格。如果图形的分辨率不是8的倍数,我们最后将得到一行和一列的一些点的计算是越界的。这表明那些点会在缓冲区之外或与有效的索引冲突,而这会破坏我们的数据。
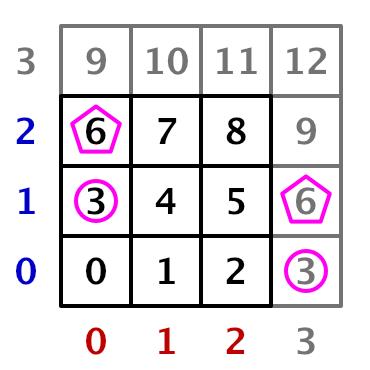
Going out of bounds.
可以通过限制标识的X 和 Y 小于分辨率来避免非法的位置
void SetPosition (uint3 id, float3 position)
if (id.x < _Resolution && id.y < _Resolution)
_Positions[id.x + id.y * _Resolution] = position;
1.8 Wave 功能(Wave Function)
我们现在可以通过FunctionKernel 获得UV坐标,并通过我们创建的函数设置位置。先从设置位置为0开始
[numthreads(8, 8, 1)]
void FunctionKernel (uint3 id: SV_DispatchThreadID)
float2 uv = GetUV(id);
SetPosition(id, 0.0);
我们首先只支持Wave 功能,也就是我们库里最简单的功能。为了让其动起来我们需要知道时间,所以添加一个_Time 属性。
float _Step, _Time;然后从FunctionLibrary 类复制 Wave 函数,将其插到FunctionKernel 之上。为了将其转换为 HLSL 函数,移除public static 修饰符,用float3 替换Vector3 ,用sin. 替换 Sin。
float3 Wave (float u, float v, float t)
float3 p;
p.x = u;
p.y = sin(PI * (u + v + t));
p.z = v;
return p;
最后还缺少定义是PI。我们将添加一个宏来定义它。添加#define PI 然后在其后面加上数字,我们使用3.14159265358979323846. 这比一个float 值要精确很多。
#define PI 3.14159265358979323846
float3 Wave (float u, float v, float t) … 现在我们用 Wave 函数来计算位置。
void FunctionKernel (uint3 id: SV_DispatchThreadID)
float2 uv = GetUV(id);
SetPosition(id, Wave(uv.x, uv.y, _Time));
1.9 分发一个计算着色器核心(Dispatching a Compute Shader Kernel)
我们现在有一个计算并存储我们图形点位置的核心函数,下一步将其在GPU上运行。为此GPUGraph 需要访问计算着色器,添加一个序列化字段ComputeShader 然后和我们的资源关联起来
[SerializeField]
ComputeShader computeShader;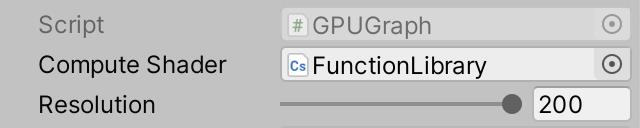
Compute shader assigned.
我们需要设置一些计算着色器的属性。为此我们需要知道他们在Unity中的标识。它们都是整型,可以通过调用Shader.PropertyToID 并传入一个字符串获得。这些标识是按需声明的,并在app或编辑器运行时保持不变,所以我们可以直接用静态字段存储它们。先从_Positions 属性开始。
static int positionsId = Shader.PropertyToID("_Positions");我们永不会修改这些字段,所以我们可以为其添加readonly 修饰符。
static readonly int positionsId = Shader.PropertyToID("_Positions");存储 _Resolution, _Step, 和_Time 的标识符
static readonly int
positionsId = Shader.PropertyToID("_Positions"),
resolutionId = Shader.PropertyToID("_Resolution"),
stepId = Shader.PropertyToID("_Step"),
timeId = Shader.PropertyToID("_Time");接下来,创建一个UpdateFunctionOnGPU 函数计算步长并设置分辨率、步长和时间属性。通过调用SetInt 和 SetFloat 来实现。
void UpdateFunctionOnGPU ()
float step = 2f / resolution;
computeShader.SetInt(resolutionId, resolution);
computeShader.SetFloat(stepId, step);
computeShader.SetFloat(timeId, Time.time);
我们还需要设置位置缓冲区,它并不复制任何数据而是将缓冲区链接到核心(kernel)。通过调用 SetBuffer实现,它和其他函数很像只是多了一个参数。它的第一个参数是核心函数的索引,因为一个计算着色器可以包含多个核心,缓冲区可以被链接到特定的一个。我们可以通过调用计算着色器上的FindKernel 来获得核心索引,但我们只有一个核心,它的索引会总是0,所以我们可以直接使用这个值。
computeShader.SetFloat(timeId, Time.time);
computeShader.SetBuffer(0, positionsId, positionsBuffer);设置完缓冲区后我们可以运行我们的核心,调用计算着色器上的有四个参数的Dispatch 函数。第一个是核心的索引,另外三个是运行的组的数量。所有维度都使用1,意思就是只有第一个有8x8位置的组被计算。
computeShader.SetBuffer(0, positionsId, positionsBuffer);
computeShader.Dispatch(0, 1, 1, 1);因为我们的组是8X8的尺寸,我们需要X和Y等于分辨率除以8,向上取整。
int groups = Mathf.CeilToInt(resolution / 8f);
computeShader.Dispatch(0, groups, groups, 1);最后在Update中调用UpdateFunctionOnGPU 来运行我们的核心。
void Update ()
…
UpdateFunctionOnGPU();
现在,在play模式下,我们已经每帧在计算所有图像的位置,即使我们没有注意到这点并且没有对数据做任何事。
2 程序化绘制(Procedural Drawing)
下一步是绘制这些点,且不必从CPU传递任何变换矩阵到GPU。因此着色器需要从缓冲区获得正确的位置而不是标准矩阵。
2.1 绘制许多网格(Drawing Many Meshes)
因为那些点已经在GPU上存在,我们不需要在CPU端记录它们。我们甚至不需要为他们建游戏对象。相反,我们需要通过一个命令通知GPU用特定的材质绘制特定的网格。为了能配置绘制些什么,在GPUGraph. 中添加序列化字段 Material 和 Mesh 。我们先用我们已有的Point Surface 材质来绘制DRP点。网格我们用默认的方块。
[SerializeField]
Material material;
[SerializeField]
Mesh mesh;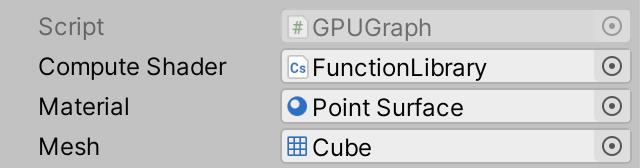
Material and mesh configured.
我们通过调用 Graphics.DrawMeshInstancedProcedural 来实现程序化绘制,并传入网格,子网格索引和材质作为参数。子网格索引是为一个网格包含多个部分时准备的,我们例子没有这种情况所以为0,。
void UpdateFunctionOnGPU ()
…
Graphics.DrawMeshInstancedProcedural(mesh, 0, material);
由于这种方式不使用游戏对象,Unity不知道在场景中哪里绘制。我们需要添加一个参数指定边界。这是一个轴对其框,只是我们正在绘制内容的边界。Unity使用这个来决定是否跳过这个绘制,因为它可能在摄像机视域之外。这被称为视锥剔除。现在是评估一次整个图形边界而不是单个点。这对我们的图形没有影响,因为我们想要完整的看到它。
我们的图形坐落于远点,它的点仍应该在2以内。我们可以用Vector3.zero 和 Vector3.one乘以2来调用Bounds 构造函数以创建一个边界值。
var bounds = new Bounds(Vector3.zero, Vector3.one * 2f);
Graphics.DrawMeshInstancedProcedural(mesh, 0, material, bounds);但是点也有尺寸,它的一半会在边界之外。所以我们同样需要增加边界。
var bounds = new Bounds(Vector3.zero, Vector3.one * (2f + 2f / resolution));最后一个要传递给DrawMeshInstancedProcedural 的参数是要绘制多少实例。这需要和位置缓冲区的元素个数匹配,我们可以通过它的count 属性获得。
Graphics.DrawMeshInstancedProcedural(
mesh, 0, material, bounds, positionsBuffer.count
);
Overlapping unit cubes.
进入play模式后,我们可以看到一个彩色的单位方块坐落于原点。每个点渲染一次相同的方块,但都具有单位变换矩阵,所以他们会重叠。现在性能比之前好很多,因为几乎没有数据要被拷贝到GPU,并且所有的点只用一个draw call 绘制。Unity也不需做任何裁剪。也不必根据它们的视空间深度来为他们排序,通常离摄像机最近的点最先被绘制。深度排序对不透明物体的渲染非常有效,因为这可以避免overdraw,但是我们的程序化绘制命令仅仅一个接一个的绘制那些点。然而,消除的CPU工作和数据传输,加上GPU全速渲染所有立方体的能力足以弥补这一点。
2.2 获取位置(Retrieving the Positions)
为了获取我们存在GPU的点的位置,我们需要创建一个新着色器,先重DRP开始。复制Point Surface 着色器并重命名为Point Surface GPU。同样修改其菜单标签。由于我们现在基于一个由计算着色器填充的结构缓冲区,提升着色器的目标级别为4.5。
Shader "Graph/Point Surface GPU"
Properties
_Smoothness ("Smoothness", Range(0,1)) = 0.5
SubShader
CGPROGRAM
#pragma surface ConfigureSurface Standard fullforwardshadows
#pragma target 4.5
…
ENDCG
FallBack "Diffuse"
程序化渲染的工作类似于GPU instancing,但是我们需要通过#pragma instancing_options 指令指定一个额外的选项。
#pragma surface ConfigureSurface Standard fullforwardshadows
#pragma instancing_options procedural:ConfigureProcedural这表明表面着色器需要为每个点调用ConfigureProcedural 函数。它是一个没有任何参数,返回空的函数。
void ConfigureProcedural ()
void ConfigureSurface (Input input, inout SurfaceOutputStandard surface)
surface.Albedo = saturate(input.worldPos * 0.5 + 0.5);
surface.Smoothness = _Smoothness;
默认情况下,只有常规绘制通道(regular draw pass)会调用这个函数。为了在渲染阴影时也调用,我们需要指定一个阴影通道,通过在#pragma surface 指令后添加addshadow
#pragma surface ConfigureSurface Standard fullforwardshadows addshadow现在添加一个和计算着色器一样的位置缓冲区。因为这次我们只需要读取它所以用StructuredBuffer替换RWStructuredBuffer
StructuredBuffer<float3> _Positions;
void ConfigureProcedural () 但是我们应该只对为程序化绘制专门编译的着色器变体执行此操作。这是定义了UNITY_PROCEDURAL_INSTANCING_ENABLED 宏时的情况。我们可以通过#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)检查是否定义。这是一个预处理指令,它使编译器只在标签被定义时才包含后面的代码,直到遇到#endif 指令。
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
StructuredBuffer<float3> _Positions;
#endif我们还要为ConfigureProcedural 做同样的事。
void ConfigureProcedural ()
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
#endif
现在我们可以通过位置缓冲区的索引,也就是当前正在被绘制的实例的标识符,来得到点的位置。我们通过unity_InstanceID 得到标识符,他可以被全局访问。
void ConfigureProcedural ()
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
float3 position = _Positions[unity_InstanceID];
#endif
2.3 创建变换矩阵(Creating a Transformation Matrix)
我们有了位置之后,下一步就是创建一个object-to-world 变换矩阵。为简单起见,我们将图形放在世界坐标原点,没有旋转和缩放。调整GPU Graph 游戏对象的Transform 不会有任何效果,所以我们不会对他做任何操作。
我们只操作点的位置和缩放。位置被存储在4 x 4 变换矩阵的最后一列,缩放存储在矩阵的对角线。矩阵的最后一位是1,其他都是0。
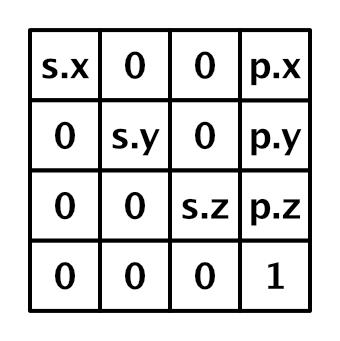
Transformation matrix with position and scale.
变换矩阵是为了将顶点从对象空间转换到世界空间。它由unity_ObjectToWorld 提供。因为我们是程序化绘制,它是一个单位矩阵,所以我们需要重置他。先把它设为0
float3 position = _Positions[unity_InstanceID];
unity_ObjectToWorld = 0.0;我们可以通过float4(position, 1.0). 构建一个列向量。我们可以通过unity_ObjectToWorld._m03_m13_m23_m33.将其设为矩阵的第四列。
unity_ObjectToWorld = 0.0;
unity_ObjectToWorld._m03_m13_m23_m33 = float4(position, 1.0);然后添加一个float _Step 属性并将其赋值给unity_ObjectToWorld._m00_m11_m22. 这是用来缩放的。
float _Step;
void ConfigureProcedural ()
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
float3 position = _Positions[unity_InstanceID];
unity_ObjectToWorld = 0.0;
unity_ObjectToWorld._m03_m13_m23_m33 = float4(position, 1.0);
unity_ObjectToWorld._m00_m11_m22 = _Step;
#endif
还有一个unity_WorldToObject 矩阵,用来变换法线向量。它是用来矫正方向向量的转换,但是我们不需要所以我们可以忽略它。我们通过添加assumeuniformscaling 来通知我们的着色器。
#pragma instancing_options assumeuniformscaling procedural:ConfigureProcedural现在为我们的着色器创建一个材质,勾选GPU instancing,并赋值给我们的GPU graph

Using GPU material.
我们还需要设置一下材质的属性,就像我们之前设置计算着色器一样。在UpdateFunctionOnGPU 中,绘制之前调用材质的SetBuffer 和 SetFloat 函数。此时我们不需要提供核心的索引。
material.SetBuffer(positionsId, positionsBuffer);
material.SetFloat(stepId, step);
var bounds = new Bounds(Vector3.zero, new Vector3(2f + 2f / resolution));
Graphics.DrawMeshInstancedProcedural(
mesh, 0, material, bounds, positionsBuffer.count
);
40,000 shadowed cubes, drawn with DRP.
我们进入play模式时,我们再次看见了我们的图像,但是现在有40 000个点被渲染并保持60FPS。如果我关闭VSync 它可以达到245FPS。
Profiling a DRP build with VSync.
2.4 百万(Going for a Million)
既然40 000个点表现的这么好,我们看一下是否可以处理百万个点。但在这之前我们需要知道异步着色器编译。这是Unity 编辑器的特色,而非构建(builds)的。编辑器只在需要时编译着色器,这可以节省很多编译时间,但也意味着着色器并不总是立即有效。当这种情发生时,会临时使用一个统一的蓝绿色着色器直到着色器被编译完成。这通常还好,但是这个临时着色器不支持程序化绘制。这会显著的减缓绘制过程,如果要渲染百万个点很可能会使Unity崩溃,甚至整个机器也可能崩溃。
我们可以通过设置关闭异步着色器编译,但只有我们的Point Surface GPU 才有这个问题。幸运的人是我们可以通过添加#pragma editor_sync_compilation 指令通知Unity为某个着色器使用同步编译。
#pragma surface ConfigureSurface Standard fullforwardshadows addshadow
#pragma instancing_options assumeuniformscaling procedural:ConfigureProcedural
#pragma editor_sync_compilation
#pragma target 4.5现在我们可以将分辨率限制增加到1000了
[SerializeField, Range(10, 1000)]
int resolution = 10;

Resolution set to 1,000.
在小窗口中它看起来并不漂亮,因为点太小会出现摩尔纹,但它确实运行了。我这里渲染百万个点是24FPS。在编辑器和构建中性能是一样的。此时编辑器开支是无关紧要的,GPU才是瓶颈。并且,是否打开VSync 也并没有明显的不同。

Profiling a build rendering a million points, no VSync.
当VSync 被关闭时,可以看出多数player loop时间花费在等待GPU完工。
注意我们现在是渲染一百万个有阴影的点,对于DPR需要每帧渲染他们三次。关闭阴影和VSync 后帧率会上升到65FPS。
2.5 URP
为了看下URP的表现,我们需要复制我们的 Point URP shader graph,重命名为Point URP GPU 。Shader graph 并不直接支持程序化绘制,但我们可以一些自定义代码使其支持。为了简单化和重用性我们创建一个HLSL文件资源。Unity没有这个选项,所以复制一个表面着色器然后重命名为PointGPU。然后修改扩展名为hlsl.

PointGPU HLSL script asset.
清空文件内容,让后复制一下内容
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
StructuredBuffer<float3> _Positions;
#endif
float _Step;
void ConfigureProcedural ()
#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
float3 position = _Positions[unity_InstanceID];
unity_ObjectToWorld = 0.0;
unity_ObjectToWorld._m03_m13_m23_m33 = float4(position, 1.0);
unity_ObjectToWorld._m00_m11_m22 = _Step;
#endif
我们现在可以通过 #include "PointGPU.hlsl" 指令在Point Surface GPU 着色器中包含这个文件,原来的代码可以被移除。
#include "PointGPU.hlsl"
struct Input
float3 worldPos;
;
float _Smoothness;
//#if defined(UNITY_PROCEDURAL_INSTANCING_ENABLED)
// StructuredBuffer<float3> _Positions;
//#endif
//float2 _Scale;
//void ConfigureProcedural () …
void ConfigureSurface (Input input, inout SurfaceOutputStandard surface) … 我们将在shader graph 中使用一个Custom Function 节点来包含HLSL文件。那个节点会调用一个文件里的函数。我们给PointGPU 添加一个简单的函数,仅仅传入一个float3 值并将其返回。
给PointGPU 添加一个有两个float3 参数的void ShaderGraphFunction_float 函数,仅仅将输入赋值给输出。
void ShaderGraphFunction_float (float3 In, float3 Out)
Out = In;
这里假定了Out 参数是一个输出参数,我们需要在其前面添加 out
void ShaderGraphFunction_float (float3 In, out float3 Out)
Out = In;
函数名后面的_float 后缀是必要的的,因为它指定了函数的精度。Shader graph 提供了两种精度,float 和 half. 后者是前者的一半。节点的精度可以被明确的选择或设为继承,继承也是默认值。为了支持两种精度,使用half 添加一个变体函数。
void ShaderGraphFunction_float (float3 In, out float3 Out)
Out = In;
void ShaderGraphFunction_half (half3 In, out half3 Out)
Out = In;
现在给Point URP GPU 添加一个Custom Function 节点。它的Type 默认是File 。将PointGPU 赋值给它的Source 属性。Name 设为ShaderGraphFunction ,不要后缀。然后在Inputs 中添加 In ,Outputs 中添加Out ,都是Vector3. 类型

Custom function via file.
添加一个Position 节点,设为对象空间,并将其与我们的自定义节点的输入链接起来。

Object-space vertex position passed through our function.
现在对象空间的顶点位置就传入了我们的函数,并且我们的代码也被包含进了着色器。但是为了程序化渲染,我们还需要包含#pragma instancing_options 和#pragma editor_sync_compilation 。它们必须被直接注入生成的着色器源代码,不能通过文件引用。所以添加一个 Custom Function 节点,输入和输出与之前一样,但是Type 设为String. 。Name 设一个适当的值,比如InjectPragmas,然后将指令写入Body 文本框。body就像一个函数代码块一样,所以这里我们还需要将输入赋值给输出。
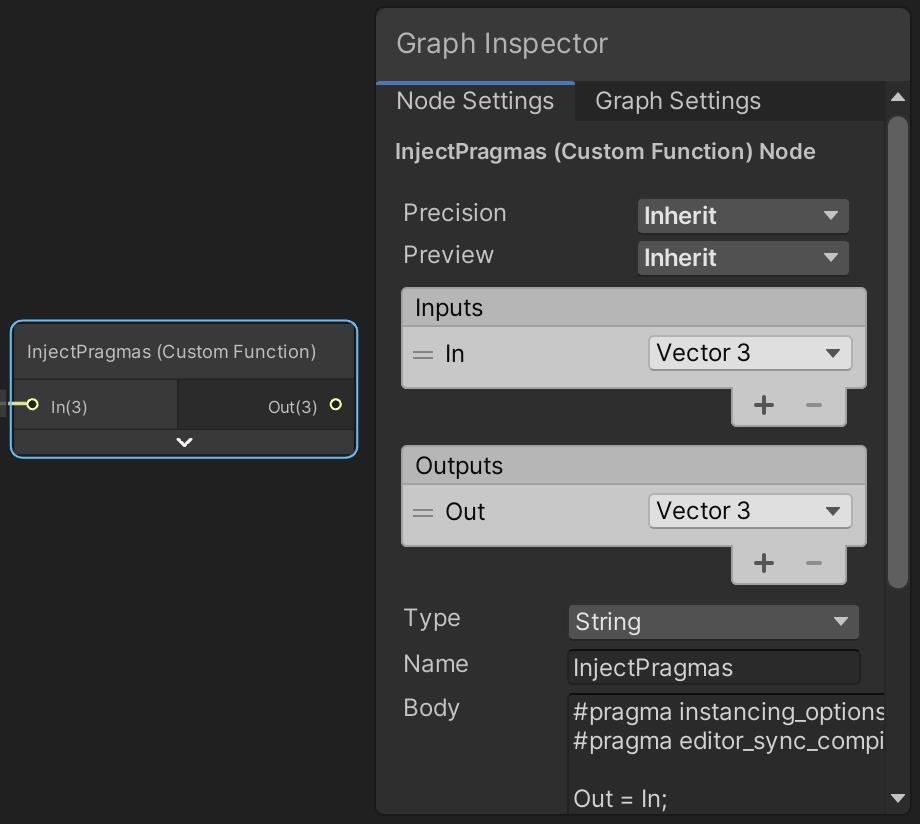
Custom function via string injecting pragmas.
为了看得更清晰,下面是body的代码
#pragma instancing_options assumeuniformscaling procedural:ConfigureProcedural
#pragma editor_sync_compilation
Out = In;将顶点位置传递给这个节点。

Shader graph with pragmas
创建一个材质,启用instancing,使用Point URP GPU 着色器,将其赋值给我们的graph,然后进入play模式。我这里达到了36FPS,在开启阴影的情况下,比DRP快了50%

Profiling URP build.
2.6 可变的分辨率(Variable Resolution)
因为我们总是为缓冲区的每个位置绘制点,降低分辨率会使一些点固定在那里。这是因为计算着色器值更新符合图形的点。

Stuck points after lowering resolution.
计算着色器不能调整大小。我们可以每次改变分辨率时创建一个新的,但简单的方法是总是申请一个最大分辨率的的缓冲区。这样天生的就可以改变分辨率。
我们将最大分辨率设为一个常量,然后在resolution 字段的 Range 属性里使用它
const int maxResolution = 1000;
…
[SerializeField, Range(10, maxResolution)]
int resolution = 10;接下来,使用最大分辨率创建缓冲区。
void OnEnable ()
positionsBuffer = new ComputeBuffer(maxResolution * maxResolution, 3 * 4);
最后,使用当前分辨率的平方替换缓冲区元素数
void UpdateFunctionOnGPU ()
…
Graphics.DrawMeshInstancedProcedural(
mesh, 0, material, bounds, resolution * resolution
);
3 GPU函数库(GPU Function Library)
现在我们基于GPU的方式是功能化的,让我们将我们整个函数库转到我们的计算着色器。
3.1 所有函数(ll Functions)
我们可以像拷贝修改Wave 一样拷贝其他函数。第二个是MultiWave。它与Wave唯一较大的不同是它包含了float 值。在HLSL中没有 f 后缀,所以将其全部移除。为了指明他们是浮点数,我给他们加了一个点,比如2f 变成了 2.0
float3 MultiWave (float u, float v, float t)
float3 p;
p.x = u;
p.y = sin(PI * (u + 0.5 * t));
p.y += 0.5 * sin(2.0 * PI * (v + t));
p.y += sin(PI * (u + v + 0.25 * t));
p.y *= 1.0 / 2.5;
p.z = v;
return p;
同样修改其他函数,Sqrt 改为sqrt ,Cos 改为cos.
float3 Ripple (float u, float v, float t)
float d = sqrt(u * u + v * v);
float3 p;
p.x = u;
p.y = sin(PI * (4.0 * d - t));
p.y /= 1.0 + 10.0 * d;
p.z = v;
return p;
float3 Sphere (float u, float v, float t)
float r = 0.9 + 0.1 * sin(PI * (6.0 * u + 4.0 * v + t));
float s = r * cos(0.5 * PI * v);
float3 p;
p.x = s * sin(PI * u);
p.y = r * sin(0.5 * PI * v);
p.z = s * cos(PI * u);
return p;
float3 Torus (float u, float v, float t)
float r1 = 0.7 + 0.1 * sin(PI * (6.0 * u + 0.5 * t));
float r2 = 0.15 + 0.05 * sin(PI * (8.0 * u + 4.0 * v + 2.0 * t));
float s = r2 * cos(PI * v) + r1;
float3 p;
p.x = s * sin(PI * u);
p.y = r2 * sin(PI * v);
p.z = s * cos(PI * u);
return p;
3.2 宏(Macros)
我们现在要为每个图形函数创建一个独立的核心函数,但那会有非常多的重复代码。我们可以通过创建一个宏避免这些。在FunctionKernel 函数上面写上#define KERNEL_FUNCTION
#define KERNEL_FUNCTION
[numthreads(8, 8, 1)]
void FunctionKernel (uint3 id: SV_DispatchThreadID) … 这些定义通常只适用于写在它后面的,同一行的东西,但是我们可以通过给除了最后一行之外的每一行后面添加 \\ 反斜杠来扩展到多行。
#define KERNEL_FUNCTION \\
[numthreads(8, 8, 1)] \\
void FunctionKernel (uint3 id: SV_DispatchThreadID) \\
float2 uv = GetUV(id); \\
SetPosition(id, Wave(uv.x, uv.y, _Time)); \\
现在,当我们写KERNEL_FUNCTION 时,编译器会用FunctionKernel函数代码将其替换。为了让其有函数功能,我们给宏添加一个参数。这就像函数的参数一样,但是没有类型并且圆括号紧跟着宏名字。给它一个 function 参数并用其代替Wave.
#define KERNEL_FUNCTION(function) \\
[numthreads(8, 8, 1)] \\
void FunctionKernel (uint3 id: SV_DispatchThreadID) \\
float2 uv = GetUV(id); \\
SetPosition(id, function(uv.x, uv.y, _Time)); \\
我们还需要修改核心函数的名字。我们使用function 作为前缀,后面跟着Kernel 。我们需要将function 标签分离出,否则它不能被识别为着色器参数。为此我们使用 ## 宏链接操作符将两个字组合起来。
void function##Kernel (uint3 id: SV_DispatchThreadID) \\现在所有五个函数都可以用KERNEL_FUNCTION 来定义了。
#define KERNEL_FUNCTION(function) \\
…
KERNEL_FUNCTION(Wave)
KERNEL_FUNCTION(MultiWave)
KERNEL_FUNCTION(Ripple)
KERNEL_FUNCTION(Sphere)
KERNEL_FUNCTION(Torus)我们还需要为每个函数替换我们的kernel指令
#pragma kernel WaveKernel
#pragma kernel MultiWaveKernel
#pragma kernel RippleKernel
#pragma kernel SphereKernel
#pragma kernel TorusKernel最后一步是在 GPUGraph.UpdateFunctionOnGPU 中使用当前函数作为kernel索引来替换之前的0
var kernelIndex = (int)function;
computeShader.SetBuffer(kernelIndex, positionsId, positionsBuffer);
int groups = Mathf.CeilToInt(resolution / 8f);
computeShader.Dispatch(kernelIndex, groups, groups, 1);
All functions at resolution 1,000, with plane to show shadows.
计算着色器非常快所以每个函数的帧率都差不多。
3.3 变形(Morphing Functions)
支持从一个函数变形到另一个函数有点复杂,因为每个变形都需要有一个单独的核心函数。先添加一个转换进程属性,后面的融合函数会用到。
float _Step, _Time, _TransitionProgress;复制那个核心宏,重命名为KERNEL_MOPH_FUNCTION, 给它添加两个参数:functionA 和functionB.将函数名改为 functionA##To##functionB##Kernel ,然后使用lerp 来对计算的点线性插值。
#define KERNEL_MOPH_FUNCTION(functionA, functionB) \\
[numthreads(8, 8, 1)] \\
void functionA##To##functionB##Kernel (uint3 id: SV_DispatchThreadID) \\
float2 uv = GetUV(id); \\
float3 position = lerp( \\
functionA(uv.x, uv.y, _Time), functionB(uv.x, uv.y, _Time), \\
_TransitionProgress \\
); \\
SetPosition(id, position); \\
每个函数都可以转换为其他,所以每个函数有四个转换。为他们添加核心函数
KERNEL_FUNCTION(Wave)
KERNEL_FUNCTION(MultiWave)
KERNEL_FUNCTION(Ripple)
KERNEL_FUNCTION(Sphere)
KERNEL_FUNCTION(Torus)
KERNEL_MOPH_FUNCTION(Wave, MultiWave);
KERNEL_MOPH_FUNCTION(Wave, Ripple);
KERNEL_MOPH_FUNCTION(Wave, Sphere);
KERNEL_MOPH_FUNCTION(Wave, Torus);
KERNEL_MOPH_FUNCTION(MultiWave, Wave);
KERNEL_MOPH_FUNCTION(MultiWave, Ripple);
KERNEL_MOPH_FUNCTION(MultiWave, Sphere);
KERNEL_MOPH_FUNCTION(MultiWave, Torus);
KERNEL_MOPH_FUNCTION(Ripple, Wave);
KERNEL_MOPH_FUNCTION(Ripple, MultiWave);
KERNEL_MOPH_FUNCTION(Ripple, Sphere);
KERNEL_MOPH_FUNCTION(Ripple, Torus);
KERNEL_MOPH_FUNCTION(Sphere, Wave);
KERNEL_MOPH_FUNCTION(Sphere, MultiWave);
KERNEL_MOPH_FUNCTION(Sphere, Ripple);
KERNEL_MOPH_FUNCTION(Sphere, Torus);
KERNEL_MOPH_FUNCTION(Torus, Wave);
KERNEL_MOPH_FUNCTION(Torus, MultiWave);
KERNEL_MOPH_FUNCTION(Torus, Ripple);
KERNEL_MOPH_FUNCTION(Torus, Sphere);我们添加核心以使他们的索引等于functionB + functionA * 5,
#pragma kernel WaveKernel
#pragma kernel WaveToMultiWaveKernel
#pragma kernel WaveToRippleKernel
#pragma kernel WaveToSphereKernel
#pragma kernel WaveToTorusKernel
#pragma kernel MultiWaveToWaveKernel
#pragma kernel MultiWaveKernel
#pragma kernel MultiWaveToRippleKernel
#pragma kernel MultiWaveToSphereKernel
#pragma kernel MultiWaveToTorusKernel
#pragma kernel RippleToWaveKernel
#pragma kernel RippleToMultiWaveKernel
#pragma kernel RippleKernel
#pragma kernel RippleToSphereKernel
#pragma kernel RippleToTorusKernel
#pragma kernel SphereToWaveKernel
#pragma kernel SphereToMultiWaveKernel
#pragma kernel SphereToRippleKernel
#pragma kernel SphereKernel
#pragma kernel SphereToTorusKernel
#pragma kernel TorusToWaveKernel
#pragma kernel TorusToMultiWaveKernel
#pragma kernel TorusToRippleKernel
#pragma kernel TorusToSphereKernel
#pragma kernel TorusKernel 回到GPUGraph, 添加转换进程属性的标识
static readonly int
…
timeId = Shader.PropertyToID("_Time"),
transitionProgressId = Shader.PropertyToID("_TransitionProgress");如果正在转换,在UpdateFunctionOnGPU 中使用它。
computeShader.SetFloat(timeId, Time.time);
if (transitioning)
computeShader.SetFloat(
transitionProgressId,
Mathf.SmoothStep(0f, 1f, duration / transitionDuration)
);
为了选择正确的索引,如果在转换增加 transition function 乘以5,否则增加自身乘以5
var kernelIndex =
(int)function + (int)(transitioning ? transitionFunction : function) * 5;
Continuous random morphing.
添加的转换对帧率没有影响。很明显渲染才是瓶颈,计算不是。
3.4 函数数量属性(Function Count Property)
为了计算核心索引,GPUGraph 需要知道有多少个函数。我们可以给FunctionLibrary 添加GetFunctionCount 函数来得到个数。这样做的好处是,如果我们添加或移除函数,只需要修改哪两个FunctionLibrary 文件。
public static int GetFunctionCount ()
return 5;
我们甚至可以移除常量,返回functions 数组的长度,更加减少了我们需要修改的代码。
public static int GetFunctionCount ()
return functions.Length;
将函数数量改为属性也是一个好方法。
public static int FunctionCount
get
return functions.Length;
这就定义了一个getter属性。由于它唯一要做的就是返回一个值,我们可以将其简化为 get => functions.Length;.
public static int FunctionCount
get => functions.Length;
因为没有set 块,我们可以将其更简化为省略get. 这样它就减为只有一行。
public static int FunctionCount => functions.Length; GetFunction 和 GetNextFunctionName.也使用这种方法
public static Function GetFunction (FunctionName name) => functions[(int)name];
public static FunctionName GetNextFunctionName (FunctionName name) =>
(int)name < functions.Length - 1 ? name + 1 : 0;在GPUGraph.UpdateFunctionOnGPU.中使用新属性替换常量
var kernelIndex =
(int)function +
(int)(transitioning ? transitionFunction : function) *
FunctionLibrary.FunctionCount;3.5 更多细节 (More Details)
由于分辨率的增加,我们的图像可以更加详细。比如,我们可以双倍Sphere.扭曲的频率。
float3 Sphere (float u, float v, float t)
float r = 0.9 + 0.1 * sin(PI * (12.0 * u + 8.0 * v + t));
…

More detailed sphere.
同样还有Torus. 的星星样式。
float3 Torus (float u, float v, float t)
float r1 = 0.7 + 0.1 * sin(PI * (8.0 * u + 0.5 * t));
float r2 = 0.15 + 0.05 * sin(PI * (16.0 * u + 8.0 * v + 3.0 * t));
…

More detailed torus.
以上是关于计算着色器(Compute Shaders)的主要内容,如果未能解决你的问题,请参考以下文章