SegNet论文笔记及其创新点代码解析
Posted cuihaoren01
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SegNet论文笔记及其创新点代码解析相关的知识,希望对你有一定的参考价值。
论文名称:SegNet: A Deep Convolutional Encoder-Decoder Architecture for Image
Segmentation
论文链接:SegNet
项目地址:SegNet caffe版本
Motivation
1、深度学习需提取图像的高阶语义特征,需要连续的下采样,连续的下采样会导致图像边界信息损失,如何尽可能保留高阶语义特征的边界信息,更好地做到高阶语义特征与原始输入分辨率的图片的映射关系是本文主要探讨的内容。
2、如何设计分割模型,做到端到端的,且模型需要兼顾内存和计算量的问题呢?本文主要借鉴了FCN,有做出了不少的创新。
Contributions
- 提出了一种高效的用于语义分割的深度卷积神经网络
- 与当前主流的分割网络FCN、Deeplab进行了比较。
Methods
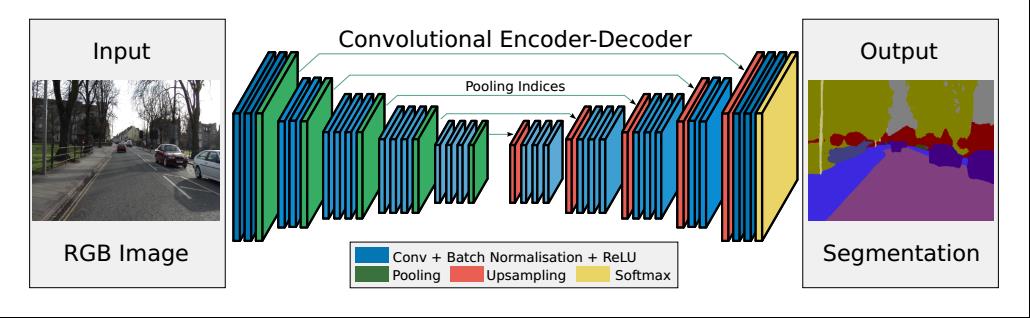
1. Encoder编码器:
SegNet就是使用了VGGNet16的前13个卷积层,去除了对应的全连接层,和我们现在的主干网络类似,卷积层+BN层+ReLU层,Encoder就是获取图像的高阶语义特征,这里需要注意的是SegNet会保留每一次max pooling的位置(即2x2的区域->1x1的区域,所对应的位置)
2. Decoder编码器
上采样当中存在着一个不确定性,即一个1x1的特征点经过上采样将会变成一个2x2特征区域,这个区域中的某个1x1区域将会被原来的1x1特征点取代,其他的三个区域为空。但是哪个1x1区域会被原特征点取代呢?一个做法就是随机将这个特征点分配到任意的一个位置,或者干脆给它分配到一个固定的位置。但是这样做无疑会引入一些误差,并且这些误差会传递给下一层。层数越深,误差影响的范围也就越大。所以把1x1特征点放到正确的位置至关重要。
SegNet通过一个叫Pooling Indices方式来保存池化点的来源信息。在Encoder的池化层处理中,会记录每一个池化后的1x1特征点来源于之前的2x2的哪个区域,在这个信息在论文中被称为Pooling Indices。Pooling Indices会在Decoder中使用。既然SegNet是一个对称网络,那么在Decoder中需要对特征图进行上采样的时候,我们就可以利用它对应的池化层的Pooling Indices来确定某个1x1特征点应该放到上采样后的2x2区域中的哪个位置。此过程的如下图所示。
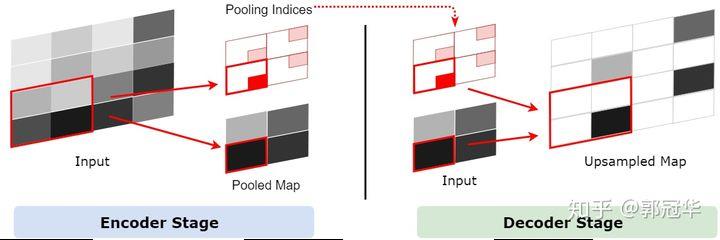
在这里说明下和UNet和Deconv的区别:
-
与U-Net的区别:
U-Net没有利用池化位置索引信息,而是将编码阶段的整个特征图传输到相应的解码器(以牺牲更多内存为代价),并将其连接,再进行上采样(通过反卷积),从而得到解码器特征图。 -
与Deconv的区别:
Deconvnet具有更多的参数,需要更多的计算资源,并且很难进行端到端训练,主要是因为使用了全连接层。
这里通过代码进行再说明可能会更浅显易懂一些。结合代码把上面的内容串起来就基本搞定这篇论文了。
import numpy as np
a = [[1,2,1,2], [3,4,3,4],[1,2,1,2],[3,4,3,4]]
b = torch.Tensor(a) # 初始化tensor
print(b)
--------------------------------------------------------------------------
Output:
tensor([[1., 2., 1., 2.],
[3., 4., 3., 4.],
[1., 2., 1., 2.],
[3., 4., 3., 4.]])
---------------------------------------------------------------------------
import torch.nn as nn
pool_test = nn.MaxPool2d(2, 2, return_indices=True, ceil_mode=True)
b = b.reshape(1, 1, 4, 4)
c, inx = pool_test(b) # 对tensor进行max_pooling
print(c)
print(inx)
---------------------------------------------------------------------------
Output:
c: tensor([[[[4., 4.],
[4., 4.]]]])
inx : tensor([[[[ 5, 7],
[13, 15]]]])
---------------------------------------------------------------------------
unpool_test = nn.MaxUnpool2d(2, 2)
shape_b = b.size()[2:]
up = unpool_test(c, inx, shape_b)
print(up)
print(b + up)
---------------------------------------------------------------------------
Output:
up : tensor([[[[0., 0., 0., 0.],
[0., 4., 0., 4.],
[0., 0., 0., 0.],
[0., 4., 0., 4.]]]])
up + b : tensor([[[[1., 2., 1., 2.],
[3., 8., 3., 8.],
[1., 2., 1., 2.],
[3., 8., 3., 8.]]]])
上面的就是SegNet 最重要的Decoder的思想,unpooling。当前很多的网络都是使用双线性插值来做upsample的,感兴趣的话可以试试两种方式对结果的影响~
以上是关于SegNet论文笔记及其创新点代码解析的主要内容,如果未能解决你的问题,请参考以下文章