Python爬虫之正则表达式
Posted Harris-H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python爬虫之正则表达式相关的知识,希望对你有一定的参考价值。
Python爬虫之正则表达式
0.介绍
爬虫的分类:网络爬虫可分为 通用爬虫 和 聚焦爬虫 两种
- 通用爬虫:通用网络爬虫 是 捜索引擎抓取系统(Baidu、Google、Yahoo等)的重要组成部分。主要目的是将互联网上的网页下载到本地,形成一个互联网内容的镜像备份。
- 聚焦爬虫:聚焦爬虫,是"面向特定主题需求"的一种网络爬虫程序,它与通用搜索引擎爬虫的区别在于:聚焦爬虫在实施网页抓取时会对内容进行处理筛选,尽量保证只抓取与需求相关的网页信息。
1.操作符

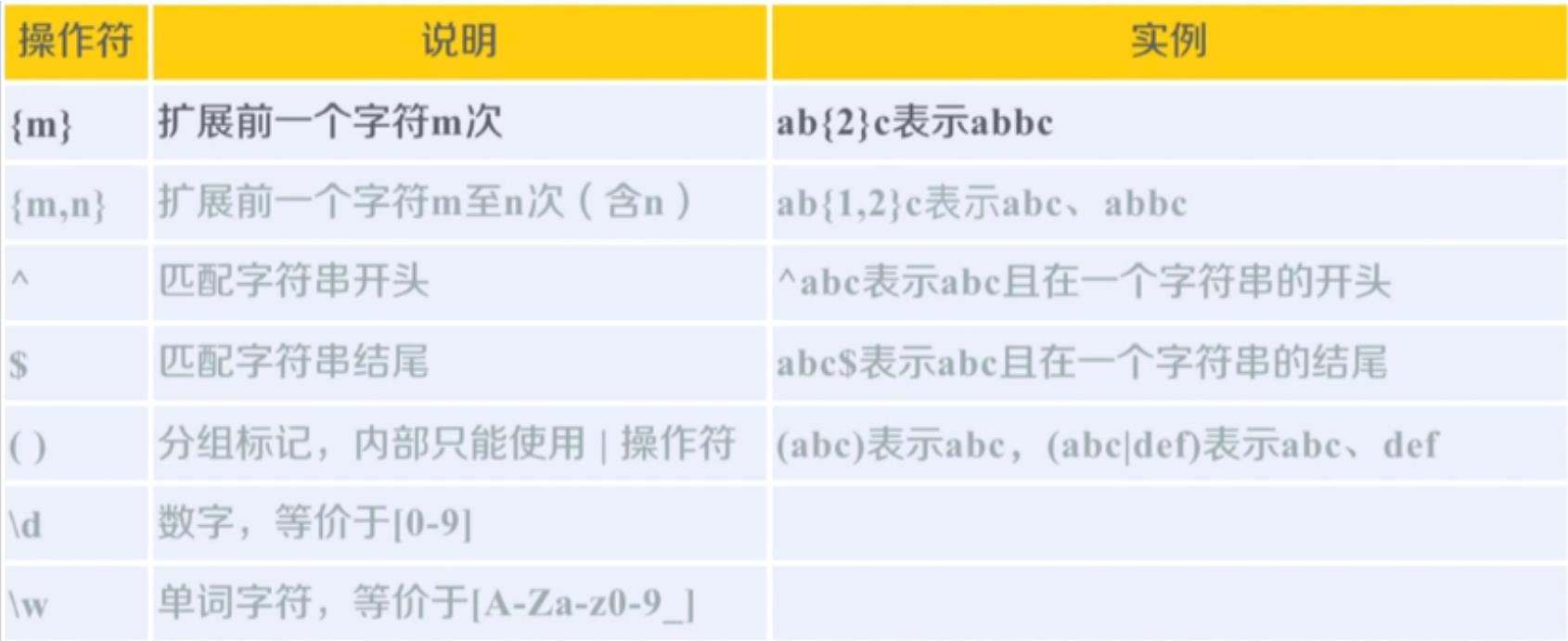
-
\\S:与\\s相反 -
\\w: -
- 对于 str 类型,匹配任何 单词字符,包括 [a-zA-Z0-9_] 以及其它单词字符
- 对于 str 类型开启 re.ASCII 标志或者 bytes 类型,只匹配 [a-zA-Z0-9_]
-
\\W:与\\w相反 -
[ ]:匹配 括号内所包含的任意一个字符 -
- 若连字符 (-) 出现在字符串中间则表示范围,出现在首位则作普通字符;
- 若脱字符 (^) 出现在字符串首位则表示排除,出现在中间则作普通字符
-
\\s: -
- 对于 str 类型,匹配任何 空白字符,包括 [\\t\\n\\r\\f\\v] 以及其它空白字符
- 对于 str 类型开启 re.ASCII 标志或者 bytes 类型,只匹配 [\\t\\n\\r\\f\\v]
-
.:匹配除换行符之外的 所有字符 -
^:匹配字符串的 开始位置 -
$:匹配字符串的 结束位置 -
*:匹配字符串 零次或多次,在后面加上 ? 表示启用非贪婪模式匹配(默认为贪婪模式) -
+:匹配字符串 一次或多次,在后面加上 ? 表示启用非贪婪模式匹配(默认为贪婪模式) -
?:匹配字符串 零次或一次,在后面加上 ? 表示启用非贪婪模式匹配(默认为贪婪模式) -
-
M, N表示匹配字符串 M~N 次M,表示匹配字符串至少 M 次,N表示匹配字符串至多 N 次N表示匹配字符串 N 次
经典例子:

IP地址:



2…常用方法

1re.search()
返回match对象
re.search函数会在字符串内查找模式匹配,只要找到第一个匹配然后返回,如果字符串没有匹配,则返回None。


2.re.match()
当匹配的第一个字符不符合,则返回空,返回match对象
*注:match和search一旦匹配成功,就是一个match object对象,而match object对象有以下方法:
- group() 返回被 RE 匹配的字符串
- start() 返回匹配开始的位置
- end() 返回匹配结束的位置
- span() 返回一个元组包含匹配 (开始,结束) 的位置
- group() 返回re整体匹配的字符串,可以一次输入多个组号,对应组号匹配的字符串。
a. group()返回re整体匹配的字符串,
b. group (n,m) 返回组号为n,m所匹配的字符串,如果组号不存在,则返回indexError异常
c.groups()groups() 方法返回一个包含正则表达式中所有小组字符串的元组,从 1 到所含的小组号,通常groups()不需要参数,返回一个元组,元组中的元就是正则表达式中定义的组
import re
a = "123abc456"
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(0)) #123abc456,返回整体
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(1)) #123
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(2)) #abc
print(re.search("([0-9]*)([a-z]*)([0-9]*)",a).group(3)) #456
###group(1) 列出第一个括号匹配部分,group(2) 列出第二个括号匹配部分,group(3) 列出第三个括号匹配部分。###
import re
line = "This is my blog"
#匹配含有is的字符串
matchObj = re.match( r'(.*) is (.*?) .*', line, re.M|re.I)
#使用了组输出:当group不带参数是将整个匹配成功的输出
#当带参数为1时匹配的是最外层左边包括的第一个括号,一次类推;
if matchObj:
print ("matchObj.group() : ", matchObj.group())#匹配整个
print ("matchObj.group(1) : ", matchObj.group(1))#匹配的第一个括号
print ("matchObj.group(2) : ", matchObj.group(2))#匹配的第二个括号
else:
print ("No match!!")
#输出:
matchObj.group() : This is my blog
matchObj.group(1) : This
matchObj.group(2) : my

3.re.findall()

4.re.split()
按照能够匹配的子串将string分割后返回列表。
可以使用re.split来分割字符串,如:re.split(r’\\s+’, text);将字符串按空格分割成一个单词列表。
格式:
re.split(pattern, string[, maxsplit])
maxsplit用于指定最大分割次数,不指定将全部分割。
print(re.split('\\d+','one1two2three3four4five5'))
执行结果如下:
['one', 'two', 'three', 'four', 'five', '']

print(re.split('a','1A1a2A3',re.I))
输出结果并未能区分大小写
这是因为re.split(pattern,string,maxsplit,flags)默认是四个参数,当我们传入的三个参数的时候,系统会默认re.I是第三个参数,所以就没起作用。如果想让这里的re.I起作用,写成flags=re.I即可。
5.re.finditer()
返回match对象

6.e.sub()

import re
text = "JGood is a handsome boy, he is cool, clever, and so on..."
print(re.sub(r'\\s+', '-', text))
执行结果如下:
JGood-is-a-handsome-boy,-he-is-cool,-clever,-and-so-on...
其中第二个函数是替换后的字符串;本例中为'-'
第四个参数指替换个数。默认为0,表示每个匹配项都替换。
7.re.compile()
编译正则表达式模式,返回一个对象的模式。(可以把那些常用的正则表达式编译成正则表达式对象,这样可以提高一点效率。)
格式:
re.compile(pattern,flags=0)
pattern: 编译时用的表达式字符串。
flags 编译标志位,用于修改正则表达式的匹配方式,如:是否区分大小写,多行匹配等。常用的flags有:
| 标志 | 含义 |
|---|---|
| re.S(DOTALL) | 使.匹配包括换行在内的所有字符 |
| re.I(IGNORECASE) | 使匹配对大小写不敏感 |
| re.L(LOCALE) | 做本地化识别(locale-aware)匹配,法语等 |
| re.M(MULTILINE) | 多行匹配,影响^和$ |
| re.X(VERBOSE) | 该标志通过给予更灵活的格式以便将正则表达式写得更易于理解 |
| re.U | 根据Unicode字符集解析字符,这个标志影响\\w,\\W,\\b,\\B |
8.subn()
返回替换次数
格式:
subn(pattern, repl, string, count=0, flags=0)
print(re.subn('[1-2]','A','123456abcdef'))
print(re.sub("g.t","have",'I get A, I got B ,I gut C'))
print(re.subn("g.t","have",'I get A, I got B ,I gut C'))
执行结果如下:
('AA3456abcdef', 2)
I have A, I have B ,I have C
('I have A, I have B ,I have C', 3)

8,两种使用re对象的方法的方式:使用面向对象方式时,将正则表达式写入compile()方法中,re对象的方法中就不用正则表达式参数了;


一些区别
1、re.match与re.search与re.findall的区别:
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
a = re.search(r'[\\d]', "abc33").group()
print(a)
p = re.match(r'[\\d]', "abc33")
print(p)
b = re.findall(r'[\\d]', "abc33")
print(b)
执行结果:
3
None
['3', '3']
4.Match对象
1,match对象的属性:

2,match方法:

5.正则表达式的匹配
1.贪婪匹配

2.最小匹配

贪婪匹配实例
import re
rE=re.compile(r"[A-Z].*[A-Z]")
ls=rE.search("adaAdssdDsdsFdsdsdM")
print(ls.group(0))

最小匹配实例
import re
rE=re.compile(r"[A-Z].*?[A-Z]")
ls=rE.search("adaAdssdDsdsFdsdsdM")
print(ls.group(0))

6.参考文章
https://www.cnblogs.com/lq13035130506/p/12250588.html
https://www.cnblogs.com/tina-python/p/5508402.html
https://zhuanlan.zhihu.com/p/78502318
在线RE测试:https://tool.oschina.net/regex
以上是关于Python爬虫之正则表达式的主要内容,如果未能解决你的问题,请参考以下文章