利用 MediaPipe 和 TensorFlow.js 检测 3D 手部姿态
Posted 谷歌开发者
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了利用 MediaPipe 和 TensorFlow.js 检测 3D 手部姿态相关的知识,希望对你有一定的参考价值。


发布人:来自 Google 的 Valentin Bazarevsky、 Ivan Grishchenko、Eduard Gabriel Bazavan、Andrei Zanfir、Mihai Zanfir、Jiuqiang Tang、 Jason Mayes、Ahmed Sabie
今天跟大家分享新版本的手部姿态检测模型,该模型具有更高的 2D 准确率,并新增了对 3D 的支持,以及同时预测双手关键点的能力。
手部姿态检测
https://github.com/tensorflow/tfjs-models/tree/master/hand-pose-detection
之前版本的手部姿态检测模型能够预测 21 个关键点,但每次只能检测一只手,新版本对此进行了改进。支持追踪多个手部目标,是开发者社区最普遍的需求之一,我们很高兴能够在此版本中实现该支持。
本文,我们将对新模型进行介绍,帮助您着手使用。您可以点击下方链接尝试一下新模型的实时演示版。

新的手部姿态检测模型实际操作
试用实时演示版
https://storage.googleapis.com/tfjs-models/demos/hand-pose-detection/index.html?model=mediapipe_hands
操作说明
1. 第一步是导入库。您可以在 html 文件中使用 <script> 标签或者使用 NPM:
通过脚本标签:
<script src=<span data-raw-text="" "="" data-textnode-index-1640661109348="16" data-index-1640661109348="616" class="character">"https://cdn.jsdelivr.net/npm/@tensorflow-models/hand-pose-detection<span data-raw-text="" "="" data-textnode-index-1640661109348="16" data-index-1640661109348="684" class="character">">>/script>
<!-- Optional: Include below scripts if you want to use MediaPipe runtime. -->
<script src=<span data-raw-text="" "="" data-textnode-index-1640661109348="18" data-index-1640661109348="785" class="character">"https://cdn.jsdelivr.net/npm/@mediapipe/hands<span data-raw-text="" "="" data-textnode-index-1640661109348="18" data-index-1640661109348="831" class="character">"> </script >通过 NPM:
yarn add @tensorflow-models/hand-pose-detection
# Run below commands if you want to use TF.js runtime.
yarn add @tensorflow/tfjs-core @tensorflow/tfjs-converter
yarn add @tensorflow/tfjs-backend-webgl
# Run below commands if you want to use MediaPipe runtime.yarn add @mediapipe/hands如果是通过 NPM 安装的,您需要先导入库:
import * as handPoseDetection from '@tensorflow-models/hand-pose-detection';接下来创建一个检测器的实例:
const model = handPoseDetection.SupportedModels.MediaPipeHands;
const detectorConfig =
runtime: 'mediapipe', // or 'tfjs'
modelType: 'full'
;
detector = await handPoseDetection.createDetector(model, detectorConfig);选择一个适合您应用需求的 modelType,有两个选项供您选择:lite 和 full。从 lite 到 full,准确率提高,而推断速度下降。
2. 有了检测器后,您就可以传入视频串流或静态图像以检测姿态:
const video = document.getElementById('video');
const hands = await detector.estimateHands(video);输出格式如下:hands 代表图像帧中检测到的 hand 预测数组。对于每只手而言,该结构包含左右手的预测,以及该预测的可信度。还会返回一个 2D 关键点数组,其中每个关键点都包含 x、y 坐标,以及名称。x、y 表示手部关键点在图像像素空间中的水平和垂直位置,而名称表示关节标签。除了 2D 关键点之外,我们还以指标尺度返回 3D 关键点(x、y、z 值),食指、中指、无名指和小指的第一个指关节之间的平均值作为辅助关键点的原点。
[
score: 0.8,
Handedness: 'Right',
keypoints: [
x: 105, y: 107, name: <span data-raw-text="" "="" data-textnode-index-1640661109348="57" data-index-1640661109348="1967" class="character">"wrist<span data-raw-text="" "="" data-textnode-index-1640661109348="57" data-index-1640661109348="1973" class="character">",
x: 108, y: 160, name: <span data-raw-text="" "="" data-textnode-index-1640661109348="58" data-index-1640661109348="2005" class="character">"pinky_finger_tip<span data-raw-text="" "="" data-textnode-index-1640661109348="58" data-index-1640661109348="2022" class="character">",
...
]
keypoints3D: [
x: 0.00388, y: -0.0205, z: 0.0217, name: <span data-raw-text="" "="" data-textnode-index-1640661109348="62" data-index-1640661109348="2105" class="character">"wrist<span data-raw-text="" "="" data-textnode-index-1640661109348="62" data-index-1640661109348="2111" class="character">",
x: -0.025138, y: -0.0255, z: -0.0051, name: <span data-raw-text="" "="" data-textnode-index-1640661109348="63" data-index-1640661109348="2165" class="character">"pinky_finger_tip<span data-raw-text="" "="" data-textnode-index-1640661109348="63" data-index-1640661109348="2182" class="character">",
...
]
]您可以参阅我们的 README,了解更多有关 API 的详情。
README
https://github.com/tensorflow/tfjs-models/tree/master/hand-pose-detection
深入探索模型
手部姿态检测 API 的更新版本改善了 2D 关键点预测、左右手识别(分类输出是左手还是右手)的质量,并将误报检测的次数降到最低。我们近期的论文介绍了更多关于更新模型的细节:“设备端实时手部姿势识别 (On-device Real-time Hand Gesture Recognition)”。
设备端实时手部姿势识别
https://arxiv.org/abs/2111.00038
继我们近期在 TensorFlow.js 中发布 BlazePose GHUM 3D 之后,我们还在这个版本中为手部姿态检测增加了指标尺度的 3D 关键点预测,食指、中指、无名指和小指第一指节的平均值作为辅助关键点,表示原点。我们的 3D 真实值基于一个名为 GHUM 的统计学 3D 人体模型,该模型的构建利用了人体形状和运动的大型语料库。
GHUM
https://openaccess.thecvf.com/content_CVPR_2020/papers/Xu_GHUM__GHUML_Generative_3D_Human_Shape_and_Articulated_Pose_CVPR_2020_paper.pdf
为了获取手部姿态的真实值,我们将 GHUM 手部模型与现有的 2D 手部数据集进行拟合,还恢复了现实世界的 3D 关键点坐标。GHUM 手部模型的形状和手部姿态变量经过优化,让重建的模型与图像证据保持一致。其中包括 2D 关键点对齐、形状和姿态正则化条款,以及人体测量学的关节角度限制和模型自我接触惩罚。

叠加了 2D 关键点注释的手部图像 GHUM 手部拟合样本。利用这些数据来训练并测试各种姿态,能够更好地检测更多极端姿态
模型质量
在新版本中,我们大幅提高了模型的质量,并在美国手语 (ASL) 手势数据集的基础上对模型进行了评估。我们采用了 COCO 关键点挑战方法所建议的平均精度 (mAP) 作为 2D 屏幕坐标的评估指标。
COCO 关键点挑战方法
https://cocodataset.org/#keypoints-eval
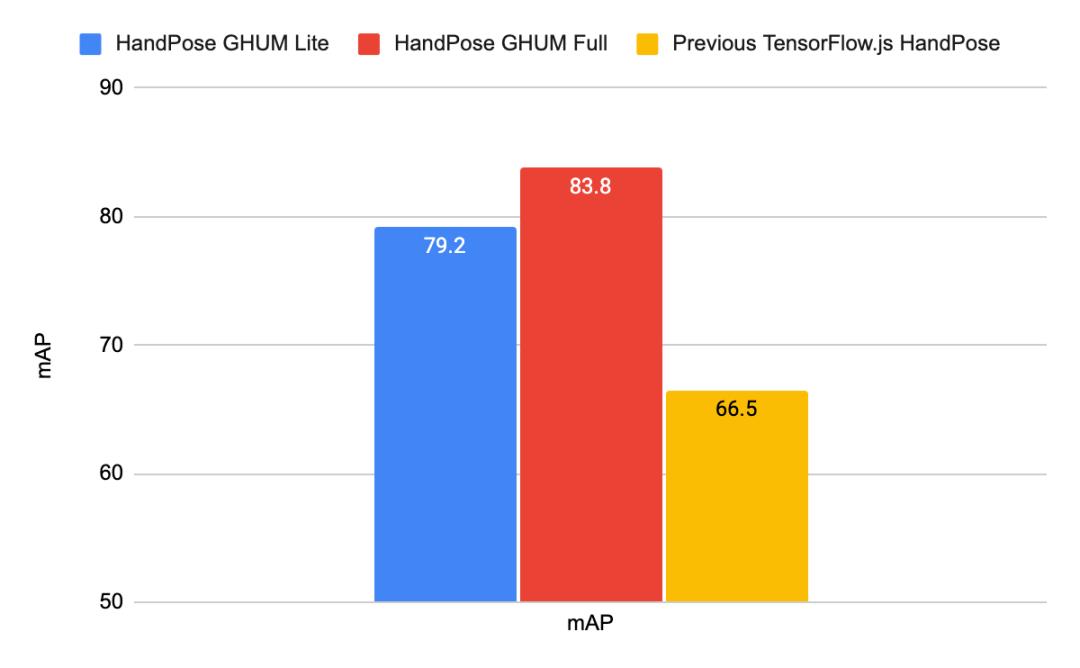
美国手语数据集基础上的手部模型评估
在 3D 评估中,我们采用了欧几里得 3D 指标空间的平均绝对误差,平均误差以厘米为单位。

新发布的 HandPose GHUM 模型与之前发布的 TensorFlow.js HandPose 模型在 2D 和 3D 预测方面的质量指标
浏览器性能
我们在多个设备上对该模型进行了基准测试。所有的基准测试中都包括双手。

HandPose 在不同设备和运行时条件下的推理速度。每个单元中的第一个数字是精简模型,第二个数字是完整模型
如要在您的设备上查看模型的 FPS,请试用我们的演示版。您可以在演示版界面上实时切换模型类型和运行时,以查看最适合您设备的模型。
跨平台可用性
除了 javascript 手部姿态检测 API 外,这些更新的手部模型还可在 MediaPipe Hands 中作为即用型 android Solution API 和 Python Solution API 使用,还分别在 Android Maven Repository 和 Python PyPI 中预置了软件包。
MediaPipe Hands
https://solutions.mediapipe.dev/hands
Android Solution API
https://google.github.io/mediapipe/solutions/hands#android-solution-api
Python Solution API
https://google.github.io/mediapipe/solutions/hands#python-solution-api
Android Maven Repository
https://maven.google.com/web/index.html#com.google.mediapipe:hands
Python PyPI
https://pypi.org/project/mediapipe/
例如,对于 Android 开发者来说,只要在项目的 Gradle 依赖项中添加以下内容,就能轻松将 Maven 软件包集成到 Android Studio 项目中:
dependencies
implementation 'com.google.mediapipe:solution-core:latest.release'
implementation 'com.google.mediapipe:hands:latest.release'
MediaPipe Android 解决方案旨在处理不同的使用场景,例如处理摄像机的实时画面、视频文件以及静态图像。它还配备了一些实用程序,以便将输出标记点叠加到 CPU 图像(使用 Canvas)或 GPU(使用 OpenGL)上。例如,以下代码片段演示了如何使用该解决方案来处理摄像机的实时画面并在屏幕上实时渲染输出:
// Creates MediaPipe Hands.
HandsOptions handsOptions =
HandsOptions.builder()
.setModelComplexity(1)
.setMaxNumHands(2)
.setRunOnGpu(true)
.build();
Hands hands = new Hands(activity, handsOptions);
// Connects MediaPipe Hands to camera.
CameraInput cameraInput = new CameraInput(activity);
cameraInput.setNewFrameListener(textureFrame -> hands.send(textureFrame));
// Registers a result listener.
hands.setResultListener(
handsResult ->
handsView.setRenderData(handsResult);
handsView.requestRender();
)
// Starts the camera to feed data to MediaPipe Hands.
handsView.post(this::startCamera);若要进一步了解 MediaPipe Android 解决方案,请参阅我们的文档,并通过 Android Studio 项目示例进行尝试。欢迎访问 MediaPipe 解决方案,了解更多跨平台解决方案。
文档
https://google.github.io/mediapipe/getting_started/android_solutions.html
Android Studio 项目
https://github.com/google/mediapipe/tree/master/mediapipe/examples/android/solutions
MediaPipe 解决方案
https://google.github.io/mediapipe/solutions/solutions.html
致谢
感谢参与或赞助创建 HandPose GHUM 3D 以及构建 API 的同事:Cristian Sminchisescu、Michael Hays、Na Li、Ping Yu、George Sung、Jonathan Baccash、Esha Uboweja、David Tian、Kanstantsin Sokal、Gregory Karpiak、Tyler Mullen、Chuo-Ling Chang、Matthias Grundmann。
 点击屏末 | 阅读原文 | 访问 TensorFlow 官网
点击屏末 | 阅读原文 | 访问 TensorFlow 官网



以上是关于利用 MediaPipe 和 TensorFlow.js 检测 3D 手部姿态的主要内容,如果未能解决你的问题,请参考以下文章
使用 MediaPipe 和 TensorFlow.js 进行人体分割
基于Unity引擎利用OpenCV和MediaPipe的面部表情和人体运动捕捉系统
利用 MediaPipe 的手部追踪来控制您的 Mirru 机械手
利用机器学习(mediapipe)进行人脸468点的3D坐标检测--视频实时检测