印刷字符识别基于matlab OCR印刷字母+数字识别含Matlab源码 287期
Posted 紫极神光
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了印刷字符识别基于matlab OCR印刷字母+数字识别含Matlab源码 287期相关的知识,希望对你有一定的参考价值。
一、OCR简介
OCR技术是光学字符识别的缩写, 是通过扫描等光学输入方式将各种票据、报刊、书籍、文稿及其它印刷品的文字转化为图像信息, 再利用文字识别技术将图像信息转化为可以使用的计算机输入技术。由于其应用前景广泛, 在应用领域有着重要的意义。
1 预处理部分
本部分可进一步细分为要素定位、二值化、切割、文字归整几个部分。由清分机或者高速扫描仪扫入的原始票据经过本部分的处理, 其识别要素如金额、日期按照单个汉字分别被存储为汉字点阵, 其中手写体大写汉字、印刷体大写汉字以及印刷体小写数字, 被存储为6464的点阵, 而手写的小写数字被存储为9680的点阵, 然后对此汉字点阵进行字符识别处理。由于某些种类的票据中, 即便为同一张票据, 其各要素的背景噪声都不相同, 所以对各不同要素区域采用了不同的二值化方法。在切割完成之后, 各要素已经成为单独的字符点阵, 文字归整则是针对单个字符点阵进行。票据上的金额、日期、帐号等都分别要经过上面的流程处理。
2 文字识别部分
按照识别系统所要识别的字符种类来分, 本系统需识别的文字有:印刷体汉字、印刷体数字、手写体汉字、手写体数字。按照识别要素, 系统包含日期识别、金额识别、帐号识别、磁码识别几个不同模块。
本系统对汉字识别采用了模板匹配方法, 对数字识别采用了人工神经网络方法。
模板匹配的基本原理是抽取未知文字的特征与事先存储好的标准的文字特征进行匹配, 在一定的距离或相似度测度下, 找出与未知文字的特征匹配得最好的标准特征, 将该标准特征所代表的文字作为未知文字的识别结果。
3 特征训练
训练是识别的基础, 标准特征的好坏直接影响到识别结果, 选取具有代表性的样本作为训练样本。训练前先将样本按一定的顺序存放起来, 训练样本也是64*64的点阵。与识别部分的特征抽取相对应, 训练部分的特征抽取也是在对文字图像进行规整和分割基础之上进行的。抽取的标准特征是每个汉字不同的样本的特征值的平均值, 还抽取了每个汉字的标准方差, 方差记录了每个字的离散度。标准特征和标准方差在识别过程中都有很重要的作用。
4 印刷体数字和英文字母识别算法开发
首先, 改进汉字识别算法, 必须充分考虑即将要开发的识别算法所要面对的识别对象与原有算法所面对的识别对象之间的区别。原算法是面对变形较大、笔划比较稠密的手写汉字, 而所开发的算法面对的是字形比较固定、笔划比较稀疏的小写数字, 相对来讲, 识别对象简单了很多。而且识别字符集也小了不少, 由原来的3755个汉字变为简单的十个数字, 1, 2, 3, 4, 5, 6, 7, 8, 9, 0, 不过其中相似字仍然存在, 如5和6, 3和8; 其次是识别要求上的变化, 识别率由原来的手写汉字的识别率要求基本达到100%。
二、部分源代码
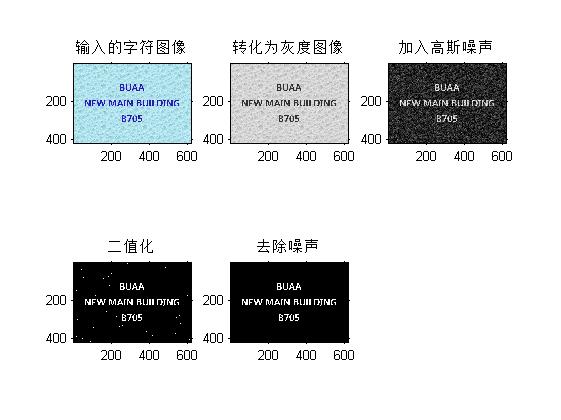
% OCR (Optical Character Recognition).
%关闭警告
warning off
% 清楚内存以及窗口
clc, close all, clear all
%读取字符图像
imagen=imread('buaa.jpg');
% 显示字符图像
subplot(2,3,1);
imshow(imagen);
title('输入的字符图像')
%判断是否为RGB真彩色图像,如果是,将RGB图像转换为灰度图像
if size(imagen,3)==3
imagen=rgb2gray(imagen);
end
subplot(2,3,2);
imshow(imagen);
title('转化为灰度图像');
%对图像进行归一化处理
J=double(imagen);
Maxvalue=max(max(J)');
f = 1 - J/Maxvalue;
%对灰度图像加入高斯噪声
imagen=imnoise(f,'gaussian',0,0.01);
subplot(2,3,3);
imshow(imagen);
title('加入高斯噪声');
% 利用graythresh函数获取一个阈值
threshold = graythresh(imagen);
%将灰度图像转换为二值图像
imagen =im2bw(imagen,threshold);
subplot(2,3,4);
imshow(imagen);
title('二值化');
% 删除二值图像中面积小于30个像素的对象
imagen =bwareaopen(imagen,30);
%去除噪声
subplot(2,3,5);
imshow(imagen);
title('去除噪声');
%定义一个矩阵word
word=[ ];
%将图像矩阵数据赋给re
re=imagen;
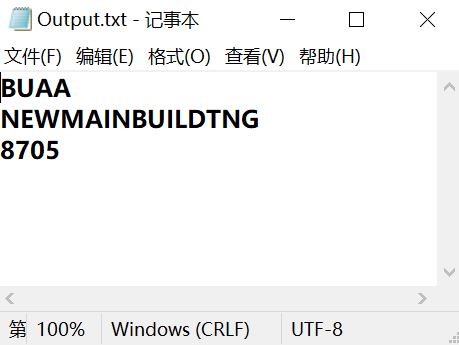
%打开'Output.txt'文件作为输出写入文件
fid = fopen('Output.txt', 'wt');
%加载字符模板
load templates
global templates
%计算模板文件中字符的数目
num_letras=size(templates,2);
while 1
%通过lines函数分割字符
[fl re]=lines(re);
imgn=fl;
% 通过bwlabel函数标记并计算连通区域的个数
[L Ne] = bwlabel(imgn);
for n=1:Ne
[r,c] = find(L==n);
% 提取字符
end
%将字符写入'Output.txt'文件中
fprintf(fid,'%s\\n',word);
% 清空word矩阵
word=[ ];
%当字符串识别完成后,跳出while循环
if isempty(re)
break
end
end
fclose(fid);
%打开'Output.txt'文件
winopen('Output.txt')
clear all
三、运行结果
四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1] 蔡利梅.MATLAB图像处理——理论、算法与实例分析[M].清华大学出版社,2020.
[2]杨丹,赵海滨,龙哲.MATLAB图像处理实例详解[M].清华大学出版社,2013.
[3]周品.MATLAB图像处理与图形用户界面设计[M].清华大学出版社,2013.
[4]刘成龙.精通MATLAB图像处理[M].清华大学出版社,2015.
[5]张殿东,包常新,温尚卓.OCR技术在银行票据识别系统中的应用[J]. 山东科学. 2005,(02)
以上是关于印刷字符识别基于matlab OCR印刷字母+数字识别含Matlab源码 287期的主要内容,如果未能解决你的问题,请参考以下文章