数据结构与算法之--高级排序:shell排序和快速排序未完待续
Posted tlz888
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据结构与算法之--高级排序:shell排序和快速排序未完待续相关的知识,希望对你有一定的参考价值。
高级排序比简单排序要快的多,简单排序的时间复杂度是O(N^2),希尔(shell)排序大约是O(N*(logN)^2),而快速排序是O(N*logN)。
说明:下面以int数组的从小到大排序为例。
希尔(shell)排序
希尔排序是基于插入排序的,首先回顾一下插入排序,假设插入是从左向右执行的,待插入元素的左边是有序的,且假如待插入元素比左边的都小,就需要挪动左边的所有元素,如下图所示:
 ==>
==>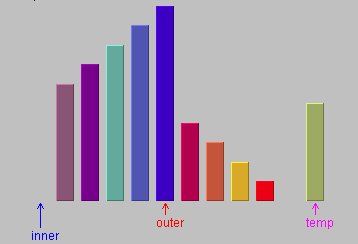
图1和图2:插入右边的temp柱需要outer标记位左边的五个柱子都向右挪动
如图3所示,相比插入排序,希尔排序是这样做的:对固定间隔的元素做插入排序,然后减小间隔,重复做插入排序,直到间隔减小为1。
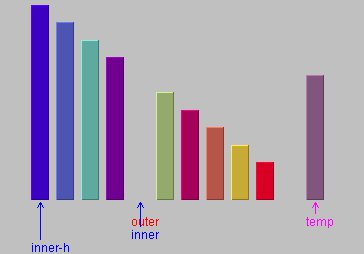 ==>
==> 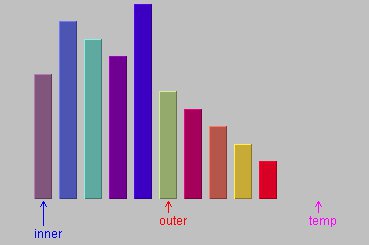
图3和图4: outer位置和inner-h位置的柱子做插入排序
数据量大的图形看这个过程更容易形象地把握算法特点,如图5和6,总元素数量等于100:
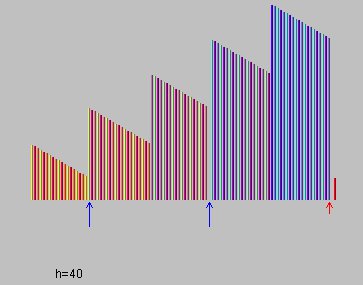
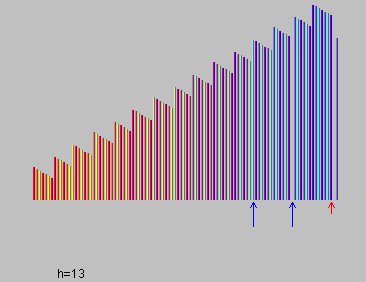
图5和图6:间隔分别为40和13执行完插入排序后的效果
相比简单插入排序,大间隔地做插入排序有两个好处:
一、大间隔直接导致需要挪动的数据稀少,且数据挪动的效率高,图5中一次挪动可以跨越40个位置;
二、经过前一步大间隔的插入排序后,整个数组从整体上粗略地看已经有了明显的顺序,后一步小间隔的插入排序时,一部分操作是不需要挪动数据的,再次减少了挪动数据的次数。
间隔的序列:间隔的常用序列,通过递归表示:h=3*h+1。(1,4,13,40,121 ...)
希尔排序的效率:“没有理论上分析希尔排序的效率的结论,各种基于实验的评估,估计它的时间级从O(N^(3/2))到O(N^(7/6))”--[1]。
参考代码:
1 /** 2 * Shell排序可以说是插入排序的升级版,相比较插入排序, 3 * Shell排序首先使用大间隔、少元素的插入排序,使得每次移动的数据少,但是移动的跨度大; 4 * 然后再使用小间隔,略多数量元素的插入排序,经过上一步插入排序,很多数据已经距离排序位置不远了, 5 * 这样第二次插入排序时,需要移动的数据的数量就会减少, 6 * 间隔最终减小到1. 7 */ 8 public static int[] shellSort(int[] input) { 9 int length = input.length; 10 int inner, outer; 11 int temp; 12 13 int h = 1; 14 while (h <= length / 3) { 15 h = h * 3 + 1; 16 } 17 18 while (h > 0) { 19 for (outer = h; outer < length; outer++) { 20 temp = input[outer]; 21 inner = outer; 22 23 while (inner > h - 1 && input[inner - h] >= temp) { 24 input[inner] = input[inner - h]; 25 inner -= h; 26 } 27 input[inner] = temp; 28 } 29 h = (h - 1) / 3; 30 } 31 32 return input; 33 }
快速排序
快速排序算法的策略是这样的:首先把数组用某个值分为两个子数组,且称这个值为分组值,一个子数组中的元素均小于分组值,另一子数组则均大于等于分组值,这里的子组内并不排序;然后,再分别对两个子组进行再分组,重复递归这个过程,直到最后每两个元素作为一组进行再分组,整个数组就排好序了。
分组过程具体如下:同时从左往右和从右往左扫描数组,记扫描标记位为LP和RP。在LP一边,若发现元素小于分组值则跳过(即向右移动一位检查下一个元素),否则等待RP的扫描;RP若发现元素大于等于分组值跳过,直到找到小于分组值的元素,然后LP和RP位置的元素交换,重复这个过程,直到LP和RP相遇。
如图7,8所示,以11号元素为分组值,LP停在0号位置,RP跳过10号,停在图7中的9号位置(粉色柱),然后0号和9号交换,后续重复这个过程。
 =>
=> 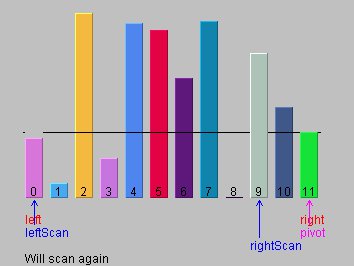
图7和图8:以11号柱作为分组值,0号和9号柱子将交换
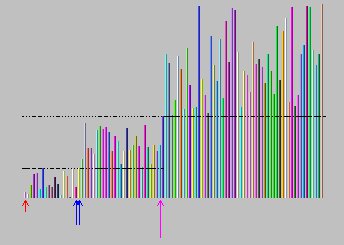
图9:100个元素的数组经过两次分组后的效果
分组值的选择,可以想见,理想的分组值应该是待分组元素的中值,这样分组后子组在数量少几乎是一半对一半,不过找中值无疑增加了算法的工作量。图7中采用了更简单的方式,直接选数组最右边的元素为分组值,分组结束后,再把这个值交换到LP和RP相遇的位置,假如初始数组是从大到小排序的,这种情况下,选择最右边的元素作为分组值,其区分度就很差了。更好用的方法是所谓的取首尾中三项数据的中值或者平均值。
通过对算法过程的描述可知,其时间复杂度应该为:O(N*logN),比简单排序和希尔排序都要快。
参考程序如下:
1 /** 2 * Time Complexity: O(N*logN) 3 */ 4 public static void quickSort(int[] input, final int left, final int right) { 5 if (left < right) { 6 int partition = partition(input, left, right); 7 quickSort(input, left, partition - 1); 8 quickSort(input, partition, right); 9 } 10 } 11 12 13 public static int median(int i1, int i2, int i3) { 14 int[] arrTmp = {i1, i2, i3}; 15 int min = arrTmp[0]; 16 int max = arrTmp[0]; 17 for (int i = 1; i < arrTmp.length; i++) { 18 min = min < arrTmp[i] ? min : arrTmp[i]; 19 max = max > arrTmp[i] ? max : arrTmp[i]; 20 } 21 return (i1 + i2 + i3) - min - max; 22 } 23 24 public static int partition(int[] input, final int left, final int right) { 25 final int mid = (left + right) / 2; 26 int pivotValue = median(input[left], input[mid], input[right]); 27 28 int leftPtr = left; 29 int rightPtr = right; 30 while (leftPtr < rightPtr) { 31 if (input[leftPtr] < pivotValue) { 32 leftPtr++; 33 continue; 34 } 35 if (input[rightPtr] > pivotValue) { 36 rightPtr--; 37 continue; 38 } 39 int temp = input[leftPtr]; 40 input[leftPtr] = input[rightPtr]; 41 input[rightPtr] = temp; 42 leftPtr++; 43 rightPtr--; 44 } 45 46 // 找出大于pivotalValue的第一个值的位置。 47 if (input[rightPtr] > pivotValue) { 48 return rightPtr; 49 } else { 50 return rightPtr + 1; 51 } 52 }
参考文献
【1】Java数据结构与算法 Rober Lafore 2nd
说明: 文中的图片来自文献【1】附带的Java applet演示小程序。
以上是关于数据结构与算法之--高级排序:shell排序和快速排序未完待续的主要内容,如果未能解决你的问题,请参考以下文章