Flinkflink highavailabilityservices 源码解析
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flinkflink highavailabilityservices 源码解析相关的知识,希望对你有一定的参考价值。

1.概述
转载:https://www.freesion.com/article/5743743878/
写在前面:源码查看入口
runtime ---> Entrypoint
不同模式对应不同入口,比如 :
StandaloneSessionClusterEntrypoint,ClusterEntrypoint
在Entrypoint中初始化 haservier。之后传递到 -->
Dispatcher ----> jobmaster -----> jobmanager
Flink内部有一些服务是JobMaster和TaskExecutor共用的。如HighAvailabilityServices, RpcService, ActorSystem(MetricQueryService), HeartbeatServices, MetricRegistryImpl, BlobCacheService.
2.HIGHAVAILABILITYSERVICES 的作用
- 提供 Leader 获取服务(ResourceManager, Dispatcher, JobManager, WebMonitor)
- 提供 Leader 选举服务(同上)
- 提供Checkpoint恢复工厂类(获取已完成的Checkpoint的元信息,以及Checkpoint计数器)
- 提供SubmittedJobGraphStore,用来保存和恢复JobGraph
- 提供大文件(Blob)的高可用存储
- 提供(RunningJobsRegistry),任务状态信息的保存与获取
3.HIGHAVAILABILITYSERVICES 的使用者
ClusterEntrypoint
TaskManagerRunner
ClusterClient
4.创建
HighAvailabilityServices 的创建是通过HighAvailabilityServicesUtils这个工具类,这个工具类提供了两个重要的静态方法来生成HighAvailabilityServices 。
-
第一个是 createAvailableOrEmbeddedServices(Configuration config, Executor executor),主要用于创建MiniCluster,服务于测试和本地运行。
-
第二个是 createHighAvailabilityServices(Configuration configuration, Executor executor, AddressResolution addressResolution),相比于第一个方法,它的参数还需要AddressResolution 。
/**
* Enum specifying whether address resolution should be tried or not when creating the
* @link HighAvailabilityServices.
*/
public enum AddressResolution
TRY_ADDRESS_RESOLUTION,
NO_ADDRESS_RESOLUTION
- TRY_ADDRESS_RESOLUTION和NO_ADDRESS_RESOLUTION,分别代表是否需要解析地址。用于在非HA环境下的直接解析地址,如果hostname不存在则快速失败。在ClusterEntrypoint中由于是本地,不需要解析,而在TaskManagerRunner与ClusterClient中使用了TRY_ADDRESS_RESOLUTION,因为一个是负责执行具体任务,另一个则是用户的客户端。
- 这个方法首先获取高可用模式(HighAvailabilityMode),分别是无高可用,基于Zookeeper的高可用,以及自己定制的高可用模式。
public enum HighAvailabilityMode
NONE(false),
ZOOKEEPER(true),
FACTORY_CLASS(true);
-
其中None模式JobManager地址是固定的,所以直接从Configuration中获取地址并生成一个StandaloneHaServices。
-
Zookeeper模式会先创建BlobStorService,就是一个高可用的大文件持久化服务,这个服务将文件保存在high-availability.storageDir配置的位置,并在Zookeeper上保存元信息。
case ZOOKEEPER:
BlobStoreService blobStoreService = BlobUtils.createBlobStoreFromConfig(configuration);
return new ZooKeeperHaServices(
ZooKeeperUtils.startCuratorFramework(configuration),
executor,
configuration,
blobStoreService);
- Custom模式需要用户自己实现HighAvailabilityServicesFactory
5.leaderEectionService & leaderRetrievalService
LeaderElectionService和LeaderRetrievalService分别提供了某个组件参加Leader选举和获取其他组件Leader的功能。(组件包括ResourceManager, Dispatcher, JobManager, WebMonitor)。
5.1 leaderEectionService
接口如下所示, start方法就是将当前的组件加入Leader选举,上述四个组件都是现了LeaderContender接口。
当某个组件被选举为leader时,会回调该组件实现的grantLeadership方法(第一次被选举为leader),当某个组件不再是leader时,会回调该组件实现的revokeLeadership方法。
public interface LeaderElectionService
void start(LeaderContender contender) throws Exception;
void stop() throws Exception;
void confirmLeaderSessionID(UUID leaderSessionID);
boolean hasLeadership(@Nonnull UUID leaderSessionId);
public interface LeaderContender
void grantLeadership(UUID leaderSessionID);
void revokeLeadership();
String getAddress();
void handleError(Exception exception);
5.2 leaderRetrievalService
LeaderRetrievalService 非常简洁,提供了start和stop方法,并且start方法只能被调用一次,在ZK模式中因为它只会监听一条ZK上的路径(即一个组件的变化)。
在启动LeaderRetrievalService的方法中需要接收参数LeaderRetrievalListener,将实现这个接口的类的实例作为参数传入这个方法,在相应组件leader发生变化时会回调notifyLeaderAddress方法,在LeaderRetrievalService抛出异常的时候会调用handleError方法。
public interface LeaderRetrievalService
void start(LeaderRetrievalListener listener) throws Exception;
void stop() throws Exception;
public interface LeaderRetrievalListener
void notifyLeaderAddress(@Nullable String leaderAddress, @Nullable UUID leaderSessionID);
void handleError(Exception exception);
6.HA 的典型实现 zookeeperHaServices
ZooKeeperHaServices的Constructor需要接受四个参数,分别为CuratorFramework, Executor, Configuration, BlobStoreService
在HighAvailabilityServices创建中,已经介绍了BlobStoreService的作用,此处要再介绍一下是创建CuratorFramework的方法ZooKeeperUtils.startCuratorFramework(configuration)
6.1 创建CuratorFramework
下图是如何通过Builder创建CuratorFramework,详情可以阅读Zookeeper客户端Curator使用详解一文,这里会介绍这些参数是如何配置的
CuratorFramework cf = CuratorFrameworkFactory.builder()
.connectString(zkQuorum)
.sessionTimeoutMs(sessionTimeout)
.connectionTimeoutMs(connectionTimeout)
.retryPolicy(new ExponentialBackoffRetry(retryWait, maxRetryAttempts))
// Curator prepends a '/' manually and throws an Exception if the
// namespace starts with a '/'.
.namespace(rootWithNamespace.startsWith("/") ? rootWithNamespace.substring(1) : rootWithNamespace)
.aclProvider(aclProvider)
.build();
-
zkQuorum对应配置中的high-availability.zookeeper.quorum,即Zookeeper的地址 -
sessionTimeout对应配置中的high-availability.zookeeper.client.session-timeout,单位为毫秒,默认60000即一分钟,ZK会话的超时时间 -
connectionTimeout对应配置中的high-availability.zookeeper.client.connection-timeout,单位为毫秒,默认15000即15秒,ZK的连接超时时间 -
重试策略为
ExponentialBackoffRetry,从概率上来讲随着重试次数越来越多,重试间隔呈指数级增长retryWait对应配置中的high-availability.zookeeper.client.retry-wait,即基础的间隔时间maxRetryAttempts对应配置中的high-availability.zookeeper.client.max-retry-attempts,即最大重试次数
-
rootWithNamespace由root和namespace(clusterId)拼成,root对应配置中的high-availability.zookeeper.path.root,默认为/flink, namespace对应配置中的high-availability.cluster-id, 在Yarn模式下也就是applicationId -
aclProvider默认使用DefaultACLProvider,相关的配置有zookeeper.sasl.disable(默人false)和high-availability.zookeeper.client.acl(默认open)
Executor是用来执行ZooKeeperCompletedCheckpointStore移除CompletedCheckpoints的任务的。
在介绍LeaderElectionService和LeaderRetrievalService的ZK实现之前,先看一个flink cluster在zookeeper中的目录结构,如下图
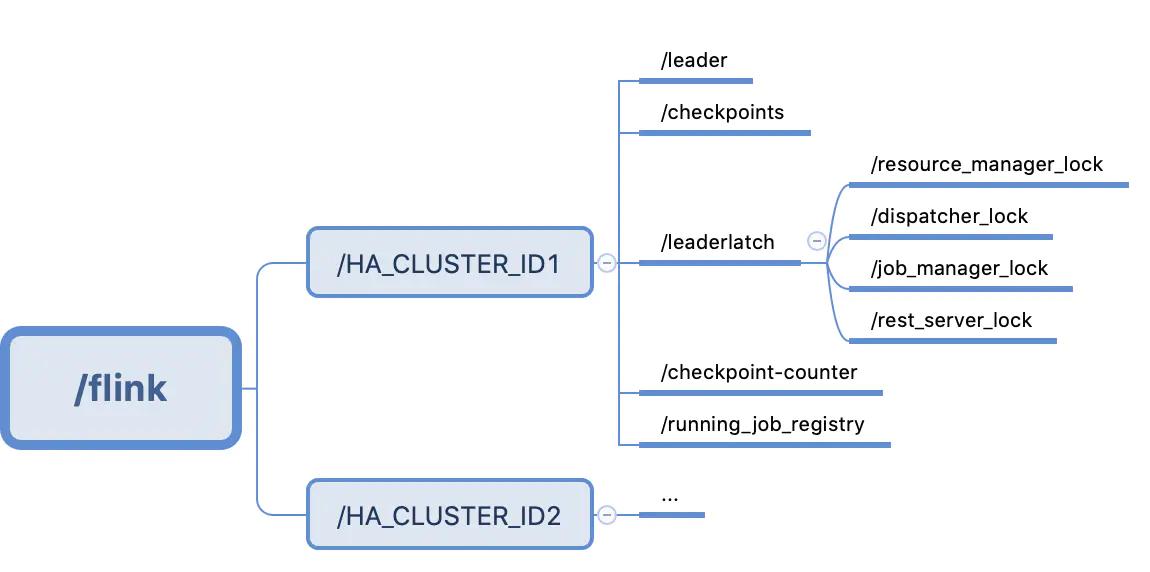
6.2 ZookeeperLeaderElectionService
ZooKeeperLeaderElectionService除了实现LeaderElectionService以外,还实现了LeaderLatchListener,NodeCacheListener,UnhandledErrorListener三个属于curator的接口。
LeaderLatchListener需要实现类实现两个回调方法,如下
public interface LeaderLatchListener
void isLeader();
void notLeader();
当被监听的对象(此处即为该ZookeeperLeaderElectionService实例)被选为leader时,isLeader实现的逻辑会被调用,当失去leader位置时,notLeader会被调用
NodeCacheListener只有一个方法,如下
public interface NodeCacheListener
void nodeChanged() throws Exception;
当监测的节点状态发生变化时,nodeChanged会被调用,在此处是保存了LeaderContender地址和LeaderSessionID的节点
UnhandledErrorListener接口需要实现一个方法,如下
public interface UnhandledErrorListener
void unhandledError(String var1, Throwable var2);
当后台操作发生异常时触发unhandledError方法,在flink各个组件的实现中也把这当做fatal error来处理
6.2.1 创建
ZookeeperLeaderElectionService的创建通过工具类ZookeeperUtils的createLeaderElectionService方法,如下。
public static ZooKeeperLeaderElectionService createLeaderElectionService(
final CuratorFramework client,
final Configuration configuration,
final String pathSuffix)
final String latchPath = configuration.getString(
HighAvailabilityOptions.HA_ZOOKEEPER_LATCH_PATH) + pathSuffix;
final String leaderPath = configuration.getString(
HighAvailabilityOptions.HA_ZOOKEEPER_LEADER_PATH) + pathSuffix;
return new ZooKeeperLeaderElectionService(client, latchPath, leaderPath);
该方法接受的参数其中client(CuratorFramework)的创建上一个小节介绍了。还有pathSuffix则对应的是各个组件,分别如下, 与leader和leaderlatch目录下一一对应
private static final String RESOURCE_MANAGER_LEADER_PATH = "/resource_manager_lock";
private static final String DISPATCHER_LEADER_PATH = "/dispatcher_lock";
private static final String JOB_MANAGER_LEADER_PATH = "/job_manager_lock";
private static final String REST_SERVER_LEADER_PATH = "/rest_server_lock";
方法体中的HA_ZOOKEEPER_LATCH_PATH对应flink配置中的high-availability.zookeeper.path.latch,默认值为/leaderlatch,
HA_ZOOKEEPER_LEADER_PATH对应flink配置中的high-availability.zookeeper.path.leader,默认为/leader。
此处latchpath与leaderpath就与上图中flink集群在zk下的目录一一对应了起来。
在ZookeeperLeaderElectionService的构造方法如下
public ZooKeeperLeaderElectionService(CuratorFramework client, String latchPath, String leaderPath)
this.client = Preconditions.checkNotNull(client, "CuratorFramework client");
this.leaderPath = Preconditions.checkNotNull(leaderPath, "leaderPath");
leaderLatch = new LeaderLatch(client, latchPath);
cache = new NodeCache(client, leaderPath);
issuedLeaderSessionID = null;
confirmedLeaderSessionID = null;
leaderContender = null;
running = false;
其中LeaderLatch是Curator的针对某一条zk路径的leader选举实现,NodeCache是Curator监控某一条zk路径的变化的实现,在此处只是分别根据latchpath和leaderpath初始化了对象,还没有启动监听。
有两个重要的类型为UUID的成员变量被初始化为null,分别是issuedLeaderSessionID和confirmedLeaderSessionID。这两个变量在leader选举过程中起到非常重要的作用。
6.3 启动
在启动LeaderElectionService时,会将实现LeaderContender(参与选举)的实例传入,基于zk的方法实现如下
public void start(LeaderContender contender) throws Exception
Preconditions.checkNotNull(contender, "Contender must not be null.");
Preconditions.checkState(leaderContender == null, "Contender was already set.");
LOG.info("Starting ZooKeeperLeaderElectionService .", this);
synchronized (lock)
client.getUnhandledErrorListenable().addListener(this);
leaderContender = contender;
leaderLatch.addListener(this);
leaderLatch.start();
cache.getListenable().addListener(this);
cache.start();
client.getConnectionStateListenable().addListener(listener);
running = true;
在启动方法中,将当前LeaderElection的对象作为Listener加入LeaderLatch,NodeCache和CuratorFramework的UnhandleError中,并启动前两个服务,并将Running置为true。
6.4 过程
过程主要包含了被选举为leader,不再是leader和Cache节点改变
-
被选举为leader,如接口小节所述,
isLeader方法会被调用,此时会生成一个UUID作为issuedLeaderSessionID,并作为调用LeaderContender(参与选举的组件)的grantLeadership方法的参数。而LeaderContender则会通过confirmedLeaderSessionID来进行确认,只有与issuedLeaderSessionID相同,confirmedLeaderSessionID才会更新,并将leader信息写入对应的leaderPath的节点中。 -
不再是leader,如接口小节所述,notLeader方法会被调用,此时会将issuedLeaderSessionID和confirmLeaderSessionID置为null,并调用LeaderContender的revokeLeadership方法通知该组件已经失去leader位置。 -
Cache节点改变时,nodeChanged方法会被调用,首先判断是否为leader,如果是的话则判断confirmedLeaderSessionID是否为空,如果不为空则将其连同LeaderContender的地址写入leaderpath下的zk临时节点。
6.5 停止
在停止方法中LeaderContender将退出选举。具体实现是将启动方法中添加的listener移除并关闭LeaderLatch和NodeCache,并将成员变量的引用置null。
6.6 ZookeeperLeaderretrievalService
6.6.1 接口
接口,ZooKeeperLeaderRetrievalService实现了LeaderRetrievalService,NodeCacheListener和UnhandledErrorListener接口,这三个接口在上文都已经介绍过。
6.6.2 创建
因为LeaderRetrievalService功能相对比较简单,只需要在leader切换时获取相关组件的Leader的地址和leaderSessionID,所以只创建了NodeCache来监测retrievalPath的变化(此处retrievalPath与参与选举的组件的leaderPath)相同,并缓存了lastLeaderAddress和lastLeaderSessionID,防止在leader并没有改变的情况下触发listener的notifyLeaderAddress。
6.6.3 启动
启动方法将Listener加入UnhandledError和NodeCache的监听并启动NodeCache,在CuratorFramework出错或者监测的retrievalPath节点发生变化或能收到回调。
6.6.4 过程
当监测的retrievalPath发生变化时,nodeChanged会被调用,在该方法体中,会从这个NodeCache(zk节点)中获取数据,与lastLeaderAddress和lastLeaderSessionID进行比对,如果发生变化会更新这两个变量并调用Listner的notifyLeaderAddress,通知新的leader地址与leaderSessionID.
6.6.5 停止
在停止方法中中止监听,具体实现是将listener移除,并关闭NodeCache。
7.CheckpointreCoveryFactory
CheckpointRecoveryJob
- 一是提供了根据JobID和
maxNumberOfCheckpointsToRetain(也就是保存的历史checpkpoint文件的个数)来生成CompletedCheckpointStore的方法, - 二是提供了根据JobID生成
CheckpointIDCounter的方法。在本文中不会多做介绍,后续如果写到失败恢复的文章的话会详细介绍。CompletedCheckpointStore本质上主要是提供获取高可用存储下备份的JobGraph进行任务恢复的方法。
ZookeeperCheckpointRecoveryJob的提供CompletedCheckpointStore的实现中具体存储方式是将在高可用文件系统(如HDFS)上保存的Checkpoint文件的地址存储在/flink/cluster_id/checkpoints/路径下。其中ZK的路径由配置中的high-availability.zookeeper.path.checkpoints参数来制定,文件系统上存储的路径由配置中的high-availability.storageDir指定。
ZooKeeperCheckpointRecoveryFactory中提供CheckpointIDCounter是通过Curator的SharedCount来实现的,是一个高可用的计数器,路径由配置中high-availability.zookeeper.path.checkpoint-counter来指定,默认是/checkpoint-counter
8.SubmittedJobGraphStore
SubmittedJobGraphStore提供了将JobGraph高可用文件系统上的保存和移除功能,以及根据 JobID获取所要恢复的任务的JobGraph功能。但是在zk的目录和hdfs上的目录下我都没有找到相应的文件,这边先略过,有机会补上。
9.RunningJobsRegistry
ZK实现RunningJobsRegistry负责在ZK节点上登记所有集群中运行的Job的状态,三种状态分别为RUNNING,PENDING和FINISHED。ZK上的路径可以通过high-availability.zookeeper.path.running-registry来指定。
以上是关于Flinkflink highavailabilityservices 源码解析的主要内容,如果未能解决你的问题,请参考以下文章