Flinkflink zookeeper HA 实现分析
Posted 九师兄
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flinkflink zookeeper HA 实现分析相关的知识,希望对你有一定的参考价值。

1.概述
转载:flink zookeeper HA 实现分析
仅仅是自己学习。
2.Zookeeper HA相关配置
## 使用zk做HA
high-availability: zookeeper
## zk地址
high-availability.zookeeper.quorum: node1:2181,node2:2181,node3:2181
## flink在zk下的工作路径
high-availability.zookeeper.path.root: /flink
## 任务所在的HA路径
high-availability.cluster-id: /default
## 保存元数据到文件系统
high-availability.storageDir: hdfs:///flink/recovery
## --任务运行在YARN上的配置--
## applicationMaster重试的次数,默认为1,当application master失败的时候,该任务不会重启。
## 设置一个比较大的值的话,yarn会尝试重启applicationMaster。
yarn.application-attempts: 10
## flink是否应该重新分配失败的taskmanager容器。默认是true。
yarn.reallocate-failed:true
## applicationMaster可以接受的容器最大失败次数,达到这个参数,就会认为yarn job失败。
## 默认这个次数和初始化请求的taskmanager数量相等(-n 参数指定的)。
yarn.maximum-failed-containers:1
flink使用Zookeeper做HA
flink的ResourceManager、Dispatcher、JobManager、WebServer组件都需要高可用保证,同时flink高可用还需要持久化checkpoint的元数据信息,保留最近一次已经完成的checkpoint等工作,其中最重要的就是组件的leader选举、leader状态跟踪。本次抽取出Flink使用zk实现leader选举、leader状态跟踪代码,学习下flink是如何使用curator的。类之间的关系如下:
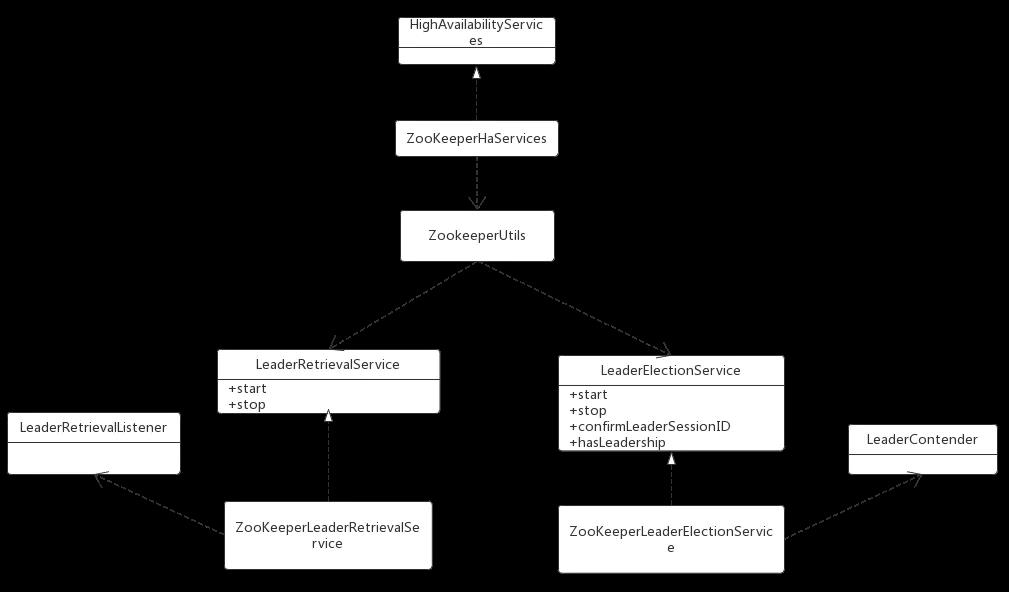
ZooKeeperHaServices是HighAvailabilityServices基于zookeeper的实现,通过使用ZooKeeperUtils类来创建组件的LeaderRetrievalService以及LeaderElectionService。
LeaderRetrievalService用来跟踪leader的变化,当发现leader地址变化时,要通知依赖它的组件去依赖新的leader。比如getResourceManagerLeaderRetriever方法,flink会监听zk的/leader/resource_manager_lock节点内容变化,内容是rm的leader地址和leaderUUID,而taskmanger调用该服务的start方法传递了一个LeaderRetrievalListener。如果节点内容发生变化,意味着rm的leader地址发生变化,那么的LeaderRetrievalListener的notifyLeaderAddress就会通知taskmanger去新的ResourceManager地址进行注册。zk实现该功能使用的是curator的NodeCache并重写了nodeChanged方法。
LeaderElectionService用来进行leader选举工作,当节点成为leader后会调用LeaderContender的grantLeadership方法。以ResourceManagerLeaderElection为例,flink会在zk的/leaderlatch/resource_manager_lock路径下创建临时节点,创建成功的rm节点成为leader触发rm的grantLeadership,最终将当前地址和UUID写入/leader/resource_manager_lock中,这样就触发了LeaderRetrievalService服务。zk实现leader选举使用的是curator的LeaderLatch并重写了isLeader和notLeader方法。同时使用NodeCache监听/leader/resource_manager_lock内容变化,确保新leader地址和UUID成功写入节点。
LeaderRetrievalListener对LeaderRetrievalService的leader地址变化做出响应,通过notifyLeaderAddress传递新leader地址。
LeaderContender对LeaderElectionService的节点角色发生变化做出响应,通过grantLeadership和revokeLeadership进行leader的授权和撤销工作。
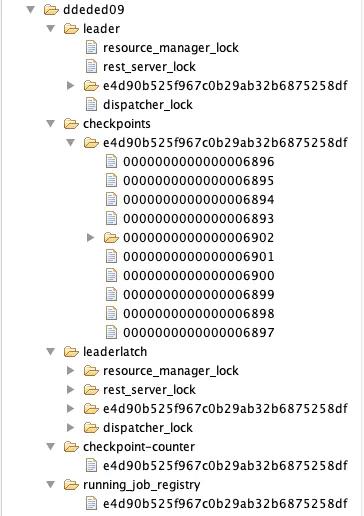
3.zk结构
一个集群目录下的zk结构如下图所示:
4.flink相关源码
简单的走一下流程,看看集群启动时是如何创建ZooKeeperHaServices的。
集群启动入口ClusterEntrypoint
根据集群的部署模式session or perjob由对应的子类调用ClusterEntrypoint的startCluster方法启动集群,接着会先调用initializeServices方法,启动集群相关的组件信息。这里只看启动haServices部分。
public void startCluster() throws ClusterEntrypointException
SecurityContext securityContext = installSecurityContext(configuration);
securityContext.runSecured((Callable<Void>) () ->
runCluster(configuration);
return null;
);
protected void initializeServices(Configuration configuration)
ioExecutor = Executors.newFixedThreadPool(
Hardware.getNumberCPUCores(),
new ExecutorThreadFactory("cluster-io"));
haServices = createHaServices(configuration, ioExecutor);
blobServer = new BlobServer(configuration, haServices.createBlobStore());
blobServer.start();
根据high-availability配置创建ZooKeeperHaServices,默认情况下为NONE。
protected HighAvailabilityServices createHaServices(
Configuration configuration,
Executor executor) throws Exception
//创建HA服务时不需要地址解析
return HighAvailabilityServicesUtils.createHighAvailabilityServices(
configuration,
executor,
HighAvailabilityServicesUtils.AddressResolution.NO_ADDRESS_RESOLUTION);
//根据传递的high-availability配置,选择创建哪种HA服务,默认为NONE
public static HighAvailabilityServices createHighAvailabilityServices(
Configuration configuration,
Executor executor,
AddressResolution addressResolution) throws Exception
//获取high-availability配置 如:zookeeper
HighAvailabilityMode highAvailabilityMode = LeaderRetrievalUtils.getRecoveryMode(configuration);
switch (highAvailabilityMode)
case NONE:
final Tuple2<String, Integer> hostnamePort = getJobManagerAddress(configuration);
final String jobManagerRpcUrl = AkkaRpcServiceUtils.getRpcUrl(
hostnamePort.f0,
hostnamePort.f1,
JobMaster.JOB_MANAGER_NAME,
addressResolution,
configuration);
final String resourceManagerRpcUrl = AkkaRpcServiceUtils.getRpcUrl(
hostnamePort.f0,
hostnamePort.f1,
ResourceManager.RESOURCE_MANAGER_NAME,
addressResolution,
configuration);
final String dispatcherRpcUrl = AkkaRpcServiceUtils.getRpcUrl(
hostnamePort.f0,
hostnamePort.f1,
Dispatcher.DISPATCHER_NAME,
addressResolution,
configuration);
final String address = checkNotNull(configuration.getString(RestOptions.ADDRESS),
"%s must be set",
RestOptions.ADDRESS.key());
final int port = configuration.getInteger(RestOptions.PORT);
final boolean enableSSL = SSLUtils.isRestSSLEnabled(configuration);
final String protocol = enableSSL ? "https://" : "http://";
return new StandaloneHaServices(
resourceManagerRpcUrl,
dispatcherRpcUrl,
jobManagerRpcUrl,
String.format("%s%s:%s", protocol, address, port));
case ZOOKEEPER:
//元数据存储服务 我们通常使用FileSystemBlobStore 路径就是 high-availability.storageDir: hdfs:///flink/recovery
BlobStoreService blobStoreService = BlobUtils.createBlobStoreFromConfig(configuration);
// 使用 ZooKeeper做HA服务
return new ZooKeeperHaServices(
ZooKeeperUtils.startCuratorFramework(configuration),
executor,
configuration,
blobStoreService);
case FACTORY_CLASS:
return createCustomHAServices(configuration, executor);
default:
throw new Exception("Recovery mode " + highAvailabilityMode + " is not supported.");
ZooKeeperHaServices主要提供了创建LeaderRetrievalService和LeaderElectionService方法,并给出了各个服务组件使用的ZK节点名称。别看是以_lock结尾,这个节点名称既在leaderlatcher做leader选举的分布式锁产生的路径,又在leader目录下用来存放leader的地址信息。
private static final String RESOURCE_MANAGER_LEADER_PATH = "/resource_manager_lock";
private static final String DISPATCHER_LEADER_PATH = "/dispatcher_lock";
private static final String JOB_MANAGER_LEADER_PATH = "/job_manager_lock";
// web展示服务
private static final String REST_SERVER_LEADER_PATH = "/rest_server_lock";
// 创建ResourceManagerLeaderRetriever,对RM的leader地址变化进行跟踪
public LeaderRetrievalService getResourceManagerLeaderRetriever()
return ZooKeeperUtils.createLeaderRetrievalService(client, configuration, RESOURCE_MANAGER_LEADER_PATH);
// 创建ResourceManagerLeaderElectionService,对RMleader挂掉后重新进行选举
public LeaderElectionService getResourceManagerLeaderElectionService()
return ZooKeeperUtils.createLeaderElectionService(client, configuration, RESOURCE_MANAGER_LEADER_PATH);
ZooKeeperUtils创建LeaderRetrievalService流程。
- 接收curator客户端以及服务在zk下的节点路径,创建出
ZooKeeperLeaderRetrievalService(ZKLRS)对象。 - ZKLRS这个对象就是对zk节点的内容进行了监听,当内容发生变化时,通知给通过start方法传递过来的
LeaderRetrievalListener。
public void start(LeaderRetrievalListener listener) throws Exception
synchronized (lock)
//leader发生变化时,通知对应的LeaderRetrievalListener
leaderListener = listener;
// 异常时调用当前对象的unhandledError方法
client.getUnhandledErrorListenable().addListener(this);
// 使用NodeCache监听节点内容变化
cache.getListenable().addListener(this);
cache.start();
// 对会话连接状态进行跟踪
client.getConnectionStateListenable().addListener(connectionStateListener);
running = true;
通过重写nodeChanged方法,来获取Leader变更后的地址,并传递新的地址
public void nodeChanged() throws Exception
synchronized (lock)
if (running)
try
LOG.debug("Leader node has changed.");
ChildData childData = cache.getCurrentData();
String leaderAddress;
UUID leaderSessionID;
if (childData == null)
leaderAddress = null;
leaderSessionID = null;
else
byte[] data = childData.getData();
if (data == null || data.length == 0)
leaderAddress = null;
leaderSessionID = null;
else
ByteArrayInputStream bais = new ByteArrayInputStream(data);
ObjectInputStream ois = new ObjectInputStream(bais);
// leader 地址
leaderAddress = ois.readUTF();
// leader uuid
leaderSessionID = (UUID) ois.readObject();
// leader 地址发生变化
if (!(Objects.equals(leaderAddress, lastLeaderAddress) &&
Objects.equals(leaderSessionID, lastLeaderSessionID)))
lastLeaderAddress = leaderAddress;
lastLeaderSessionID = leaderSessionID;
// 传递新的leaderAddress和leaderSessionID
leaderListener.notifyLeaderAddress(leaderAddress, leaderSessionID);
catch (Exception e)
leaderListener.handleError(new Exception("Could not handle node changed event.", e));
throw e;
else
LOG.debug("Ignoring node change notification since the service has already been stopped.");
ZooKeeperUtils创建ZooKeeperLeaderElectionService流程。
传递leader所在的zk路径、选举时临时节点创建的zk路径。之所以要传递leader节点是要在新leader产生时,将新leader的地址和uuid写入。
public static ZooKeeperLeaderElectionService createLeaderElectionService(
final CuratorFramework client,
final Configuration configuration,
final String pathSuffix)
// 在leaderlatch节点下进行选举
final String latchPath = configuration.getString(
HighAvailabilityOptions.HA_ZOOKEEPER_LATCH_PATH) + pathSuffix;
// leader节点
final String leaderPath = configuration.getString(
HighAvailabilityOptions.HA_ZOOKEEPER_LEADER_PATH) + pathSuffix;
return new ZooKeeperLeaderElectionService(client, latchPath, leaderPath);
通过调用start方法传递LeaderContender,并开启leader选举。
public void start(LeaderContender contender) throws Exception
synchronized (lock)
// 绑定异常处理监听器
client.getUnhandledErrorListenable().addListener(this);
// 传递Contender竞争者
leaderContender = contender;
//开启leader选举服务,成为leader的节点会触发isleader
leaderLatch.addListener(this);
leaderLatch.start();
//监听leader节点内容变化
cache.getListenable().addListener(this);
cache.start();
client.getConnectionStateListenable().addListener(listener);
running = true;
当某一Contender成为leader后,会触发grantLeadership传递新leader的uuid进行授权,并调用LeaderElectionService的confirmLeaderSessionID,将新leader地址写入leader节点。
public void confirmLeaderSessionID(UUID leaderSessionID)
// 是Leader
if (leaderLatch.hasLeadership())
// check if this is an old confirmation call
synchronized (lock)
if (running)
if (leaderSessionID.equals(this.issuedLeaderSessionID))
confirmedLeaderSessionID = leaderSessionID;
// 将confirmLeaderSessionID写到 leader目录下
writeLeaderInformation(confirmedLeaderSessionID);
写入时会触发当前对象的nodeChanged方法,该方法用来确保新leader地址和uuid成功写入。
public void nodeChanged() throws Exception
try
// leaderSessionID is null if the leader contender has not yet confirmed the session ID
if (leaderLatch.hasLeadership()) // leader
synchronized (lock)
if (running)
// 当选为leader 已经被确认
if (confirmedLeaderSessionID != null)
ChildData childData = cache.getCurrentData();
// 没写进去,再写一次
if (childData == null)
if (LOG.isDebugEnabled())
LOG.debug(
"Writing leader information into empty node by .",
leaderContender.getAddress());
writeLeaderInformation(confirmedLeaderSessionID);
else
byte[] data = childData.getData();
if (data == null || data.length == 0)
// the data field seems to be empty, rewrite information
writeLeaderInformation(confirmedLeaderSessionID);
else
ByteArrayInputStream bais = new ByteArrayInputStream(data);
ObjectInputStream ois = new ObjectInputStream(bais);
String leaderAddress = ois.readUTF();
UUID leaderSessionID = (UUID) ois.readObject();
if (!leaderAddress.equals(this.leaderContender.getAddress()) ||
(leaderSessionID == null || !leaderSessionID.equals(confirmedLeaderSessionID)))
writeLeaderInformation(confirmedLeaderSessionID);
else
// leader未确认confirmedLeaderSessionID
LOG.debug("Ignoring node change notification since the service has already been stopped.");
catch (Exception e)
...
writeLeaderInformation用来写入leader地址和uuid,写入时先判断leader节点是否由当前leader会话创建的,如果不是则删除后重写创建。
protected void writeLeaderInformation(UUID leaderSessionID)
try
ByteArrayOutputStream baos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(baos);
// leader 地址
oos.writeUTF(leaderContender.getAddress());
// leader的 UUID
oos.writeObject(leaderSessionID);
oos.close();
boolean dataWritten = false;
while (!dataWritten && leaderLatch.hasLeadership())
Stat stat = client.checkExists().forPath(leaderPath);
if (stat != null)
long owner = stat.getEphemeralOwner();
long sessionID = client.getZookeeperClient().getZooKeeper().getSessionId();
//节点由当前会话创建
if (owner == sessionID)
try
client.setData().forPath(leaderPath, baos.toByteArray());
dataWritten = true;
catch (KeeperException.NoNodeException noNode)
// node was deleted in the meantime
else
try
// 不是当前节点创建则先删除
client.delete().forPath(leaderPath);
catch (KeeperException.NoNodeException noNode)
// node was del以上是关于Flinkflink zookeeper HA 实现分析的主要内容,如果未能解决你的问题,请参考以下文章