ConcurrentSkipListMap以及跳表的原理
Posted 爪洼ing
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ConcurrentSkipListMap以及跳表的原理相关的知识,希望对你有一定的参考价值。
ConcurrentSkipListMap
底层实现是”跳跃表“ ,Redis当中Zset同样采用的是该数据结构
跳跃表的结构图:
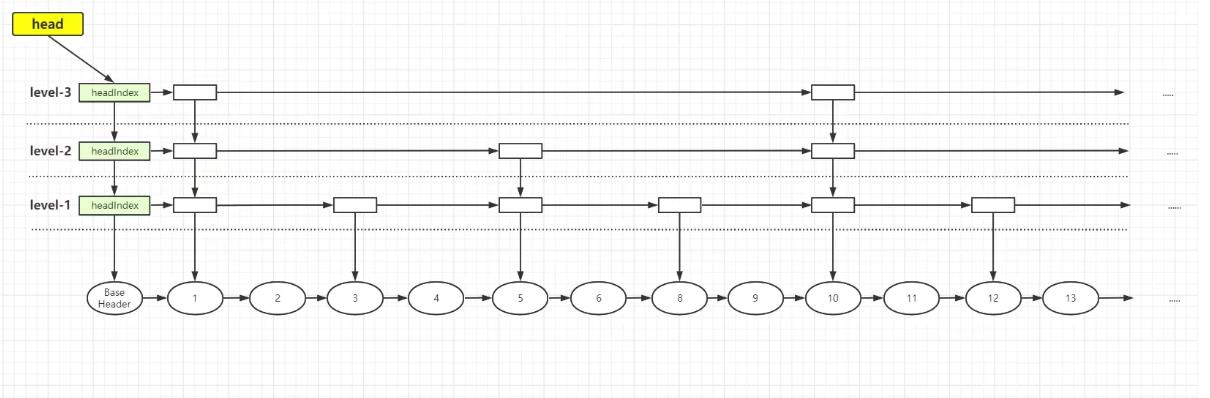
特点:
- 其根本思想是 二分查找 的思想。
- 跳表的前提条件是 针对 有序的单链表 ,实现高效地查找,插入,删除。
- Redis中的 有序集合 sorted set 就是用跳表实现的。
1、跳表的原理
种基于单链表的高级数据结构, 跳表 将单链表先进行排序,然后针对 有序链表 为了实现高效的查找,可以使用跳表这种数据结构。
对于单链表,即使是 存储的有序数据(即 有序链表),想在其中查找某个数据,也只能从头到尾遍历,查找效率低,时间复杂度是O(n),如下图所示:

怎么才能提高查找效率呢?
为了提高查找效率,使用二分查找的思想,对有序链表建立一级“索引”。 每两个节点提取一个节点到索引层。 索引层中的每个节点 都包
含两个指针,一个指向下一个节点,一个down指针,指向下一级节点

首先在一级索引层遍历,当遍历到14这个节点的时候,发现其下一个节点是23,则要查找的18就在14和23之间。 然后,通过14节点的
down 指针,下降到原始链表这一层,继续在原始链表中遍历。 此时,只需要在原始链表中,遍历两个节点,14和18,就找到18这个节点
了。 查找18这个节点,在原始链表需要遍历10个节点,现在只需要遍历7个节点(一级索引层遍历5个节点,原始链表遍历2个节点)。
如果再增加一级索引,那么效率会不会更高呢?
建立二级索引

现在如果要查找18节点,只需要遍历6个节点(二级索引层遍历3个节点,一级索引层1个节点,原始链表2个节点)。
通过建立索引的方式,对于数据量越大的有序链表,通过建立多级索引,查找效率提升会非常明显。
这种链表加多级索引的结构 就是 跳表。
2、跳表中查询一个节点
通过Key去查询,从Head节点开始进入,由最高层索引开始查询,主键向下层索引缩小范围,知道找到我们BaseHeader这一层后会将Node节点进行逐个equals比较
3、跳表中插入一个节点
跳表作为一个动态数据结构,不仅支持查找操作,还支持数据的插入和删除操作,并且 插入和删除的操作的时间复杂度都是O(logn).
我们先去查询我们这个节点在我们的调表中是否存在,也就是通过key执行上述的查询的过程,如果发现节点存在,那么就会覆盖我们的已存在的节点,如果不存在则新建一个Node节点进行插入操作,但是我们插入之后就会出现一个新的问题,就是我们的节点变了那么对应的索引也应该做相应的修改,那么为新插入的Node节点创建的索引步骤如下 :
1、首先是生成一个随机数
int rnd = ThreadLocalRandom.nextSecondarySeed();
2、然后通过让我们的随机数与0x80000001进行一个&操作,去判断是否满足建立索引的条件
if ((rnd & 0x80000001) == 0) // 0x80000001这个16进制转换为2进制则是 10000000 00000000 00000000 00000001
// rnd这个随机数,最高位和最低为同时为0的时候条件成立,概率是1/4
3、当满足建立索引的条件后,我们还需要通过对这个随机数进行计算得出我们建立的索引层数level
//首先rnd满足索引建立条件初始为1,之后检查从第二位到第31位间1的个数,相加即为索引层数
rnd = 00000000 00000000 00000000 00011110 ===> 得出level为4 + 1 = 5 ;
rnd = 00000000 00000000 00010100 01011110 ===> 得出level为8 + 1 = 9 ;
4、我们讲理论上应该建立的索引层数再次进行判断,得到我们的实索引际高度!
//拿到步骤3得出的理论索引层数,与我们当前调表中的索引层数比较,例:上图跳表的层数是3,我们为新插入的节点建立索引的理论高度是9,那么我们就会得出我们实际的索引高度是3 + 1 = 4 ; 也就是超过实际索引高度,我们为新插入节点建立的索引高度就是我们实际的高度 + 1
5、创建层次索引,完结!
4、调表删除节点
删除原链表中的节点,如果节点存在于索引中,也要删除索引中的节点。 因为单链表中的删除需要用到 要删除节点 的 前驱动节点。 可以像插入操作一样,通过索引逐层向下遍历到原始链表中,要删除的节点,并记录其 前驱节点,从而实现删除操作。
5、面试题
为什么Redis中的有序集合用跳表而非红黑树来实现呢?
- 对于插入,删除,查找 以及 输出有序序列 这几个操作,红黑树也可以完成,时间复杂度 与 用跳表实现是相同的。 但是,对于按照区间查找数据这个操作(比如 [20,300]),红黑树的效率没有跳表高,跳表可以做到 O(logn)的时间复杂度定位区间的起点,然后在原始链表中顺序向后遍历输出,直到遇到值大于区间终点的节点为止。
- 跳表更加灵活,它可以通过改变节点的抽取间隔,灵活地平衡空间复杂度和时间复杂度
- 相比红黑树,跳表更容易实现,代码更简单
以上是关于ConcurrentSkipListMap以及跳表的原理的主要内容,如果未能解决你的问题,请参考以下文章