分布式系统的唯一ID如何生成
Posted 小志的博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系统的唯一ID如何生成相关的知识,希望对你有一定的参考价值。
一、雪花算法的提前
-
针对业务数据来说,通常都是需要唯一id的,比如学生的学号、订单的订单号,支付流水的流水号等等。
-
采用最简单的方式,就是插入时候设置主键auto increment的自增方式。那么插入表中的数据都是唯一的,不过方案虽然简单,但是弊端确实很多。
(1)、比如通过这种自增的方式,用户很容易就会通过遍历id的方式,获得库中的业务数据,并且如果采用了分库分表的方式,那么就无法通过主键自增的方式来控制业务数据唯一性。 -
如果采取MD5的方式呢,却失去了业务含义,并且不利于在分库分表的场景下,通过id快速确定数据在哪个库或哪张表上。
-
针对这种情况,我们可以采用雪花算法来解决。
二、雪花算法的概述
- 雪花算法(snowflake)是Twitter开源的分布式ID生成算法,它会返回一个long类型的唯一ID。
- 这种方案大致来说是一种以划分命名空间来生成ID的一种算法,这种方案把32或64-bit分别划分成多段,分开来标示机器、时间等。



三、雪花算法的代码实现
1、雪花算法代码
package com.xz.springboottest.day6;
/**
* @description: snowflake算法
* @author: xz
*/
public class SnowFlake
/**
* 起始的时间戳
*/
private final static long START_STAMP = 1480166465631L;
/**
* 每一部分占用的位数
*/
private final static long SEQUENCE_BIT = 12; //序列号占用的位数
private final static long MACHINE_BIT = 5; //机器标识占用的位数
private final static long DATA_CENTER_BIT = 5;//数据中心占用的位数
/**
* 每一部分的最大值
*/
private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT); //序列号最大值
private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT);//机器标识最大值
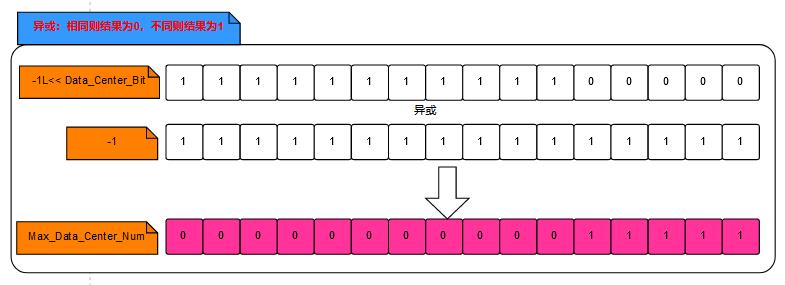
private final static long MAX_DATA_CENTER_NUM = -1L ^ (-1L << DATA_CENTER_BIT);//数据中心最大值
/**
* 每一部分向左的位移
*/
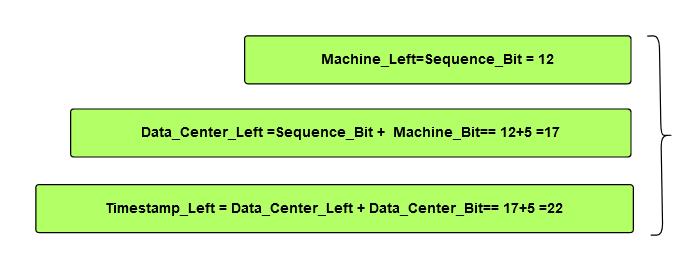
private final static long MACHINE_LEFT = SEQUENCE_BIT;
private final static long DATA_CENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT;
private final static long TIMESTAMP_LEFT = DATA_CENTER_LEFT + DATA_CENTER_BIT;
/**
* 定义参数
* */
private long dataCenterId; //数据中心
private long machineId; //机器标识
private long sequence = 0L; //序列号
private long lastStamp = -1L;//上一次时间戳
/**
* 带参数的构造函数
* */
public SnowFlake(long dataCenterId, long machineId)
if (dataCenterId > MAX_DATA_CENTER_NUM || dataCenterId < 0)
throw new IllegalArgumentException("dataCenterId can't be greater than MAX_DATA_CENTER_NUM or less than 0");
if (machineId > MAX_MACHINE_NUM || machineId < 0)
throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0");
this.dataCenterId = dataCenterId;
this.machineId = machineId;
/**
* 产生下一个ID
*
* @return
*/
public synchronized long nextId()
long currStamp = getNewStamp();
if (currStamp < lastStamp)
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
if (currStamp == lastStamp)
//相同毫秒内,序列号自增
sequence = (sequence + 1) & MAX_SEQUENCE;
//同一毫秒的序列数已经达到最大
if (sequence == 0L)
currStamp = getNextMill();
else
//不同毫秒内,序列号置为0
sequence = 0L;
lastStamp = currStamp;
return (currStamp - START_STAMP) << TIMESTAMP_LEFT //时间戳部分
| dataCenterId << DATA_CENTER_LEFT //数据中心部分
| machineId << MACHINE_LEFT //机器标识部分
| sequence; //序列号部分
private long getNextMill()
long mill = getNewStamp();
while (mill <= lastStamp)
mill = getNewStamp();
return mill;
private long getNewStamp()
return System.currentTimeMillis();
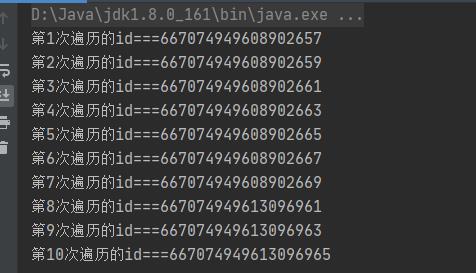
2、测试代码

以上是关于分布式系统的唯一ID如何生成的主要内容,如果未能解决你的问题,请参考以下文章