《异常检测——从经典算法到深度学习》13 MAD: 基于GANs的时间序列数据多元异常检测
Posted smile-yan
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《异常检测——从经典算法到深度学习》13 MAD: 基于GANs的时间序列数据多元异常检测相关的知识,希望对你有一定的参考价值。
《异常检测——从经典算法到深度学习》
- 0 概论
- 1 基于隔离森林的异常检测算法
- 2 基于LOF的异常检测算法
- 3 基于One-Class SVM的异常检测算法
- 4 基于高斯概率密度异常检测算法
- 5 Opprentice——异常检测经典算法最终篇
- 6 基于重构概率的 VAE 异常检测
- 7 基于条件VAE异常检测
- 8 Donut: 基于 VAE 的 Web 应用周期性 KPI 无监督异常检测
- 9 异常检测资料汇总(持续更新&抛砖引玉)
- 10 Bagel: 基于条件 VAE 的鲁棒无监督KPI异常检测
- 11 ADS: 针对大量出现的KPI流快速部署异常检测模型
- 12 Buzz: 对复杂 KPI 基于VAE对抗训练的非监督异常检测
- 13 MAD: 基于GANs的时间序列数据多元异常检测
相关:
重要说明
感谢小伙伴的提醒,从这一篇开始为了突出重点,将翻译部分全部移到自己的 个人博客 中( 5 M 带宽并且配置了 CDN 的服务器应该不会太慢,就是有点伤钱)。
所以接下来的内容将是简单明了的部分,一般而言会提到几个大家都关心的问题:
- 这是什么论文?值得看吗?一般而言节选的论文不一定是很厉害的会议或者期刊上的,而是一些相对基础一些的,容易理解的,甚至比较简单的。因为个人认为读那种非常复杂高深的论文参考意义不一定很大。
- 论文算法开源吗?很抱歉大多数论文不开源,但是我会尽量找一些开源的论文。
- 论文用到的是什么数据集?数据集这个问题非常难以解决,但是论文提到的也会在下面记下。
- 论文最最最主要在讲什么?一般论文有个总体思路,算法有个最主要的模型等等。这里希望自己能够概括一下这部分内容。有必要的话,我也会制作成 PPT 的形式和大家交流。
- 论文的优缺点。
13. MAD: 基于GANs的时间序列数据多元异常检测
2018 Anomaly Detection with Generative AdversarialNetworks for Multivariate Time Series
论文下载以及源码地址:MAD-GANs 翻译
期刊:Lecture Notes in Computer Science(普刊)
引用索引 bib
13.1 简要概述论文内容
13.1.1 核心思想与方法
论文提出了一种新的基于无监督GAN的异常检测 (GAN- AD) 方法,该方法通过建模多个时间序列之间的非线性关联,并基于训练好的 GAN 模型检测异常。
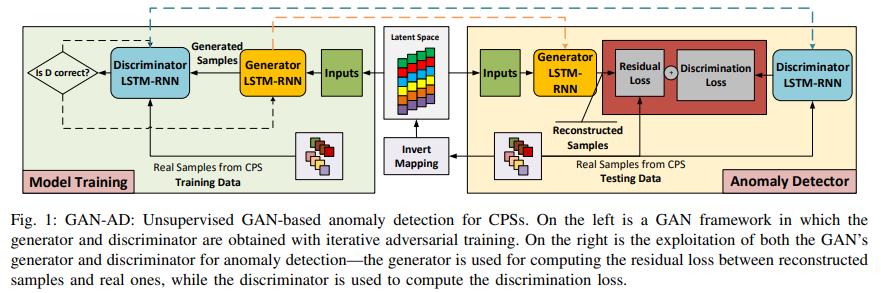
上图分为训练和检测两部分,这两部分之间的联系就是隐变量。这个与 VAE 异常检测类似,把数据特征存储在隐变量中,检测的时候隐变量则会派上用场。因为生成模型本身是不能直接输出与异常有线性关系的结果的。
继续看上图左边部分,这个是典型的 GAN 模型,GAN 模型的判别器与生成器 “相爱相杀”,生成器想方设法欺骗判别器而判别器又不断提高自己的识别能力。论文在 GAN 标准模型上添加了 LSTM 与 RNN。
继续看上图右边部分,异常检测部分首先从测试数据开始,将样本数据与隐变量空间建立映射关系,然后再把映射结果作为输入交给 GAN 的生成器,注意看上面的虚线,是指这个生成器是训练得到的。使用生成器对隐变量输入进行重构,然后与测试数据进行计算得到 Residual Loss ,同样将测试数据直接交给判别器进行计算得到 Discrimination Loss ,最后将这两个损失结合,得到最终的检测结果。
13.1.2 主要贡献
- 提出了一种基于 GAN 的无监督异常检测方法,用于检测具有网络传感器和执行器的复杂多进程网络物理系统的异常(网络攻击)。
- 使用多个时间序列对GAN模型进行训练,采用LSTM-RNN (Long - Short - Term-Recurrent Neural Networks, LSTM-RNN) 捕获时间相关性,从图像生成域自适应生成GAN进行时间序列生成。
- 均匀使用高维的正规序列训练GAN模型区分真伪,同时从特定的潜在空间重构测试序列;
- 将训练好的鉴别器计算的鉴别损失与重构序列与真实测试序列之间的残差损失(训练好的鉴别器与生成器同时使用)结合起来检测高维时间序列中的异常点,在具有六级的复杂安全水处理(SWaT)系统中,该方法在检测网络攻击导致的异常方面优于现有方法。
13.1.3 论文算法
论文算法:LSTM-RNN-GAN-based Anomaly Dection Strategy。

训练时
- 对于第 k 个批次训练数据:
- 从隐变量空间中生成样本 Z = z i , i = 1 , 2 , . . . , m ⇒ G R N N ( Z ) Z=\\z_i, i=1,2,...,m\\ \\Rightarrow G_RNN(Z) Z=zi,i=1,2,...,m⇒GRNN(Z)
- 进行判别操作 X = x i , i = 1 , 2 , . . . , m ⇒ D R N N ( X ) X=\\x_i,i=1,2,...,m\\ \\Rightarrow D_RNN(X) X=xi,i=1,2,...,m⇒DRNN(X)
- G R N N ( Z ) ⇒ D R N N ( G R N N ( Z ) ) G_RNN(Z)\\Rightarrow D_RNN(G_RNN(Z)) GRNN(Z)⇒DRNN(GRNN(Z)) 即进行对抗训练
- 通过梯度下降来最小化 D l o s s D_loss Dloss 更新判别器的参数: min 1 m ∑ i = 1 m ( − log D R N N ( x i ) − log ( 1 − D R N N ( z i ) ) ) \\min \\frac1m\\sum_i=1^m(-\\log D_RNN(x_i)-\\log(1-D_RNN(z_i))) minm1∑i=1m(−logDRNN(xi)−log(1−DRNN(zi)))
- 通过梯度下降来最小化 G l o s s G_loss Gloss 更新判别器的参数: min ∑ i = 1 m log ( − D R N N ( G R N N ( z i ) ) ) \\min \\sum_i=1^m \\log (-D_RNN(G_RNN(z_i))) min∑i=1mlog(−DRNN(GRNN(zi)))。(注: 这个地方应该是指更新生成器的参数。应该是论文书写错误。 )
- 记录当前迭代中生成器与判别器的参数。
- 本次循环建立测试数据与隐变量之间的映射关系
- 计算残差(residuals): R e s = ∣ X t e s − G R N N ( Z k ) ∣ Res = |X^tes-G_RNN(Z^k)| Res=∣Xtes−GRNN(Zk)∣
- 计算判别结果: P r o = D R N N ( X t e s ) Pro=D_RNN(X^tes) Pro=DRNN(Xtes)
- 计算异常分数: S = R e s + P r o S=Res+Pro S=Res+Pro
13.1.4 其他部分
算法这一块儿的内容大致如上,其他部分内容比如 Anomaly Detection Framework 中提到的使用 PCA 建立映射关系比较简单,而其他部分比如根据阈值进行异常打标实在是有凑公式凑字数的嫌疑。
13.2 实验数据与结果
实验使用的是 SWaT 数据集,可以前去 https://itrust.sutd.edu.sg/ 进行申请,一般填写学生邮箱就能申请成功,但是给的是谷歌云盘的资源地址,并且数据集非常大,一般是几个 G 起。
SWaT 数据是一个高维数据(共有51个维度),光从谷歌云下载下来就需要花费大量的时间。因此,不建议使用这个数据集。但是如果环境允许可以申请一下,了解一下。
论文源码https://github.com/LiDan456/MAD-GANs 提到可以考虑跑一下 KDD CUP 数据,数据集附加在源码文件夹中,解压即可用。并且已经是进行一些处理后的,比如不考虑异常的类型,只要是异常就把标签设置为 1 等。
具体步骤:
环境说明:
- tensorflow 1.x
- keras:1.x
克隆项目
git clone https://github.com/LiDan456/MAD-GANs.git
解压文件夹
需要注意解压后的是这样的,不要添加额外的路径:

直接运行
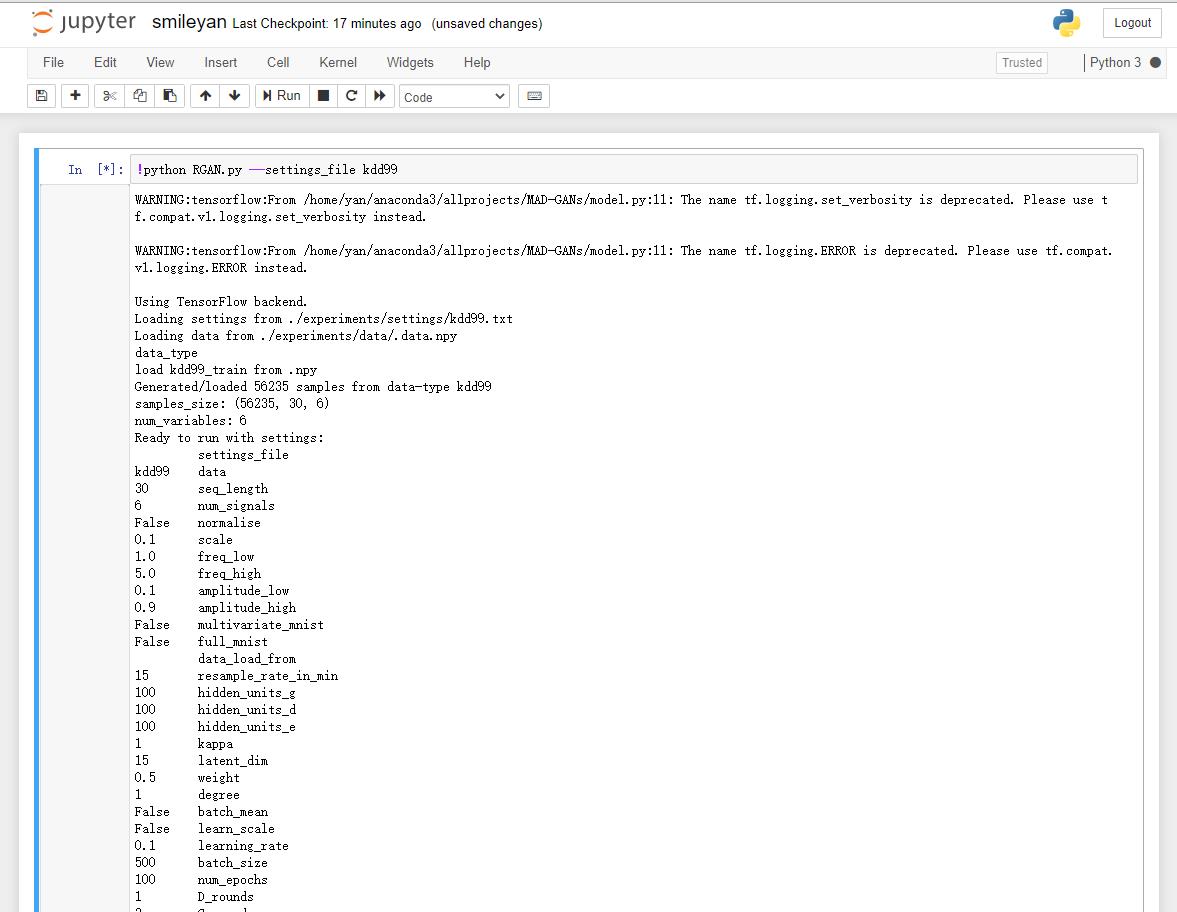
python RGAN.py --settings_file kdd99
如果是使用 notebook 的话前面添加感叹号即可,具体效果如下:
对测试数据进行异常检测
python AD.py --settings_file kdd99_test
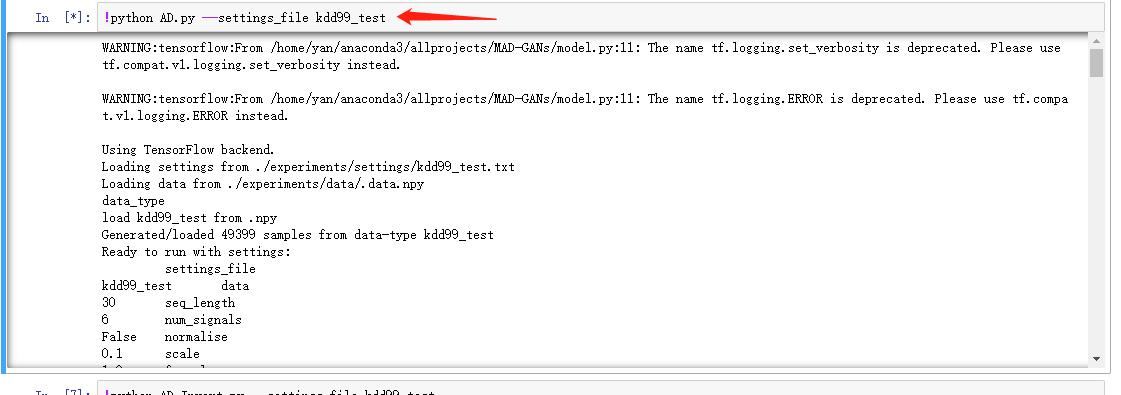
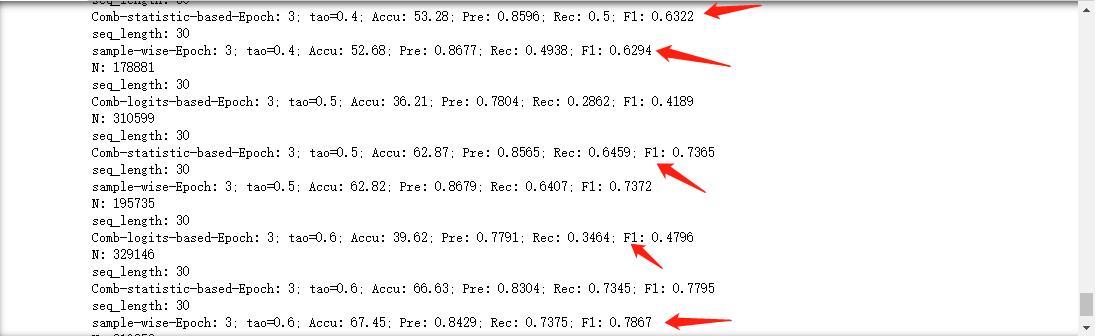
同样需要一些时间,输出的结果大致包括:
常见问题
一般情况下肯定都会出问题,莫方莫烦,逐个解决即可。
首先确保tensorflow版本
一般情况下 1.x 即可。我自己的环境是 1.15.4

其次是 keras 的版本
一般也是 1.x 即可,我的环境是 1.1.2

scipy报错
运行训练的时候报错。具体的报错内容是 ModuleNotFoundError: No module named 'scipy.misc.pilutil'
查了一下官网,这个库是旧版本的,所以方法就是降低版本或者不使用这个库,我们选择不使用这个库,所以前去源码指定位置进行一波注释即可。
具体的文件地址是 data_utils.py ,其中的第14行,from scipy.misc.pilutil import imresize 根本后面就没用到,所以直接注释掉就好了。
numpy报错
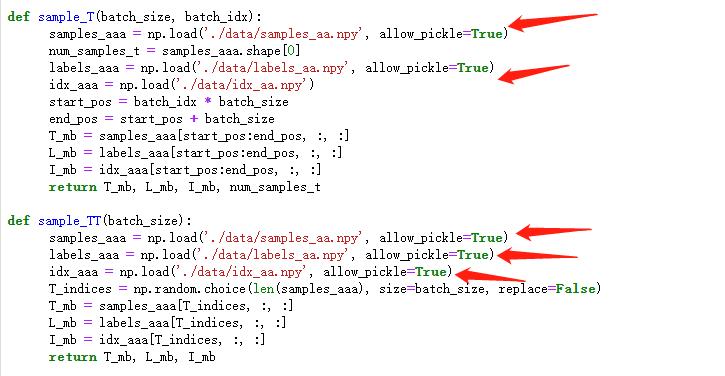
在进行测试的时候,看到的报错。具体报错内容是 ValueError: Object arrays cannot be loaded when allow_pickle=False
方法也非常简答,把 model.py 中所有 np.load 都添加一个参数以及值为 True。如图所示:

linux解压7z文件
如果和我一样使用的是云服务器跑代码的话,或者本身自己用的就是linux系统的话,希望通过命令行解压也非常简单。安装方法与解压请 参考。
p7zip x data.7z
需要多长时间执行完
跟自己的机器性能有关,一般情况下……很久。叫上你的小伙先去吃顿饭吧。
运行时间太长
模型的训练需要很长时间(约半个小时),而模型的测试却需要更长的时间,简直可怕,我居然非常有耐心让它跑完了(睡觉第二天出结果)。
约 4.5 小时。所以如果希望早点结束运行的话,需要修改源码文件夹中的配置文件。experiments/settings/kdd99_test.txt 找到这个文件中的 num_epochs ,默认是 100 修改为 10 或者更小即可。
其他错误
我没有遇到其他问题,如果有遇到其他问题请在后面留言。
13.3 论文的优缺点
个人认为最大的优点就是开源,让大家可以跑一下玩一下了解一下,说不定也写到自己的论文的 REFERENCE 中。
其次论文相对而言比较简单,没有高深的数学理论和复杂的推导公式。
还有很不错的地方在于提供数据集让大家解压即可使用,这一点必须给作者以及作者团队点赞。
缺点就是凑字数的嫌疑太大了,比如 f1-score 的计算公式也写到论文中而且还算是5个公式是不是有点不太好,而且在算法中更新判别器和生成器的时候那个地方应该是存在错误的,两个地方都是更新判别器参数是非常不科学的。
但总体而言虽然这只是一个普刊上的论文,但是还是值得读一下,跑一下代码,了解一下的。如果觉得作者写得可以的话也请前去 github 点星星吧。自己的论文也可以考虑引用一下。作为对比实验之类的。
13.4 致谢
不知不觉这方面的博客写了这么长时间了,存在很多很多问题,也有不少小伙伴留言与私信交流这方面的内容,对我也有一些帮助,感谢!
如果有这方面的疑问欢迎留言讨论!
感谢 您的 阅读、点赞、收藏 和 评论 ,别忘了 还可以 关注 一下哈,感谢 您的支持!
Smileyan
2021.8.5 17:02
以上是关于《异常检测——从经典算法到深度学习》13 MAD: 基于GANs的时间序列数据多元异常检测的主要内容,如果未能解决你的问题,请参考以下文章
异常检测——从经典算法到深度学习》14 对于流数据基于 RRCF 的异常检测
《异常检测——从经典算法到深度学习》16 基于VAE和LOF的无监督KPI异常检测算法
异常检测——从经典算法到深度学习》14 对于流数据基于 RRCF 的异常检测
异常检测——从经典算法到深度学习》14 对于流数据基于 RRCF 的异常检测