redis源码学习跳跃表
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了redis源码学习跳跃表相关的知识,希望对你有一定的参考价值。

之前手写过跳表,所以概念性的东西就不多提,直接上链接:数据结构(9)-- 跳表
在redis中跳表主要应用于有序集合的底层实现。
这个别人怎么讲都意义不大,自己动手去写一下才知道其中的妙处与不容易。没有看起来那么好写。
然后,来学习一下redis中是如何实现跳表的,看看自己跟大师的天差地别。
跳表整体概览
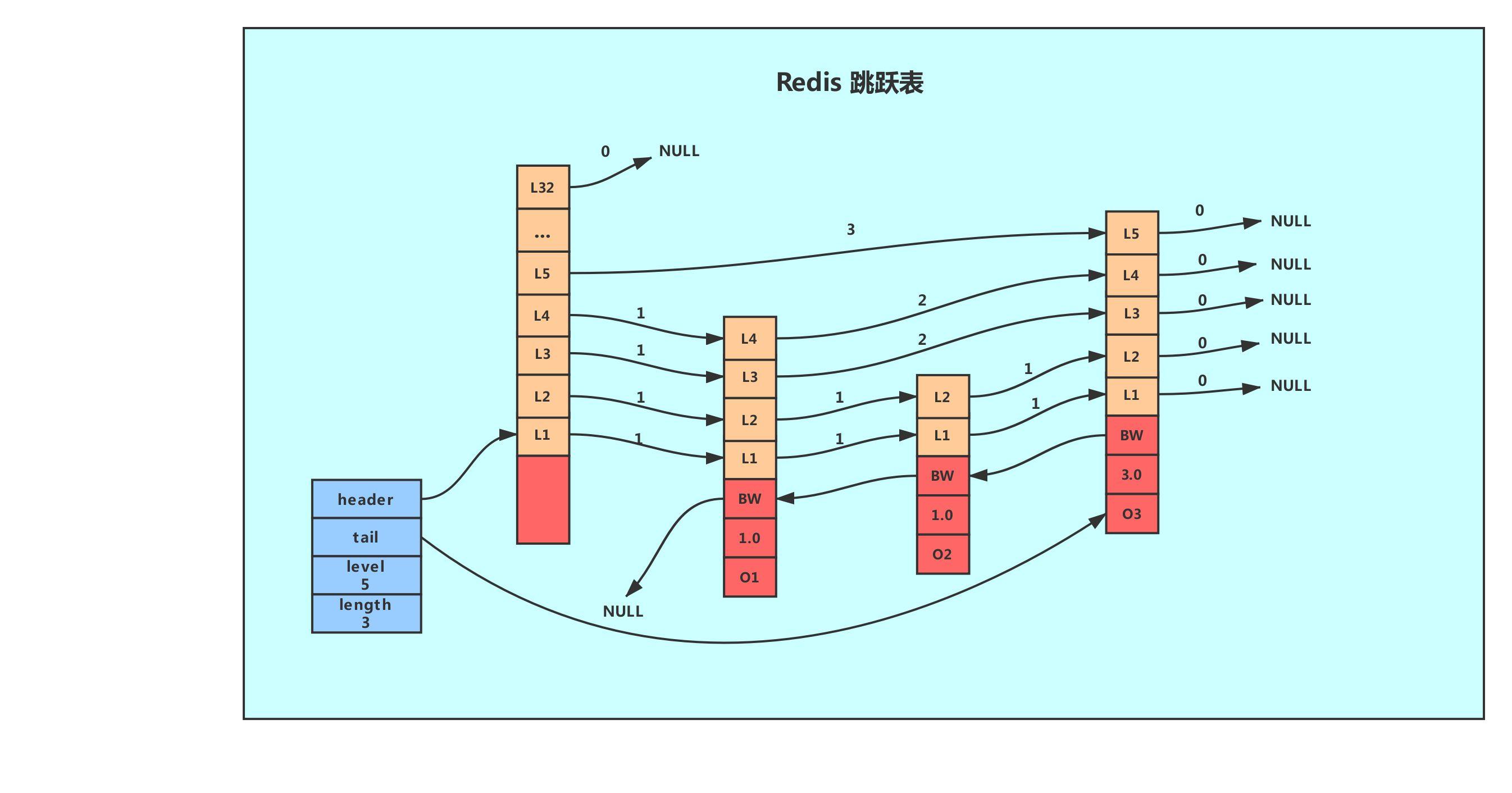
1、由多层构成。
2、有一个头节点,指向一个64层结构。还有个尾结点。
3、除头结点外,层次最高的层数记录在 level 中。
4、length记录了最底层链表的长度。
5、红色部分有往回指的。下面来看这个红色部分。
跳跃表节点
/* ZSETs use a specialized version of Skiplists */
typedef struct zskiplistNode
sds ele; //每个节点的 ele 存储有序集合的成员member值
double score; //score存储成员分值。所有节点的分值都是从小到大排序的,遇到分值相同的则按ele的字典序排序。
struct zskiplistNode *backward; //后退指针,上面红色部分最顶层
//下面是粉红色部分
struct zskiplistLevel
struct zskiplistNode *forward; //指向本层后一个节点
unsigned long span; //两个节点之间跳过了多少个节点
level[]; //那这个就是存一层一层的节点咯。生成每一层的管理员节点(意会一下)时,随机生成一个1~64的值。值越大出现的概率越低。
zskiplistNode;
跳跃表结构
链表都是有结构 + 节点 组成的,跳跃表出自链表,自然也有结构。
//图中蓝色部分
typedef struct zskiplist
struct zskiplistNode *header, *tail;
unsigned long length;
int level;
zskiplist;
局势已经有点明朗了吧。
创建跳跃表
随机数获取
略微抽象哈。
/* Returns a random level for the new skiplist node we are going to create.
* The return value of this function is between 1 and ZSKIPLIST_MAXLEVEL
* (both inclusive), with a powerlaw-alike distribution where higher
* levels are less likely to be returned. */
int zslRandomLevel(void)
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF)) //ZSKIPLIST_P = 0.25,0xFFFF = 1111 1111 1111 1111
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL; //ZSKIPLIST_MAXLEVEL = 64
所以这个循环的意思就是,取一个随机数random,取这个值的低16位(共32位)作为x,当x小于0.25倍的0xFFFF(十进制为65535)时,level 加一。
如果我没猜错,这个每次成功加一的概率为 0.25,可以口算,但是笔算我就不会写了。
节点 n 层高的概率为 (1-p)*p^(n-1),所以节点的期望层高为 1/(1-p) = 1.33。
好低啊。。。
创建跳跃表结构
就是那个蓝色部分:
/* Create a new skiplist. */
zskiplist *zslCreate(void)
int j;
zskiplist *zsl;
zsl = zmalloc(sizeof(*zsl));
zsl->level = 1;
zsl->length = 0;
zsl->header = zslCreateNode(ZSKIPLIST_MAXLEVEL,0,NULL);
for (j = 0; j < ZSKIPLIST_MAXLEVEL; j++)
zsl->header->level[j].forward = NULL;
zsl->header->level[j].span = 0;
zsl->header->backward = NULL;
zsl->tail = NULL;
return zsl;
不难理解吧,跟链表创建头结点一样的。
创建跳跃表节点
初始化操作总是那么的平平无奇哈。后面的增删改查才是重头戏!!!
/* Create a skiplist node with the specified number of levels.
* The SDS string 'ele' is referenced by the node after the call. */
zskiplistNode *zslCreateNode(int level, double score, sds ele)
zskiplistNode *zn =
zmalloc(sizeof(*zn)+level*sizeof(struct zskiplistLevel));
zn->score = score;
zn->ele = ele;
return zn;
插入节点
插入节点的步骤如下:
1、寻找插入位置
2、调增跳跃表高度
3、插入节点
4、调整backward
看似不难,谁写谁知道。
/* Insert a new node in the skiplist. Assumes the element does not already
* exist (up to the caller to enforce that). The skiplist takes ownership
* of the passed SDS string 'ele'. */
zskiplistNode *zslInsert(zskiplist *zsl, double score, sds ele)
//update:保存被插入节点每层的前一个节点,直接看很难明白为什么要这个东西,自己写过一遍就知道这是个好东西了
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
//rank:记录当前层从header到update[i]所需步长,更新span的时候需要用到
unsigned int rank[ZSKIPLIST_MAXLEVEL];
int i, level;
serverAssert(!isnan(score));
x = zsl->header;
//看下面示例
for (i = zsl->level-1; i >= 0; i--)
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
rank[i] += x->level[i].span;
x = x->level[i].forward;
update[i] = x;
/* we assume the element is not already inside, since we allow duplicated
* scores, reinserting the same element should never happen since the
* caller of zslInsert() should test in the hash table if the element is
* already inside or not. */
level = zslRandomLevel();
if (level > zsl->level)
for (i = zsl->level; i < level; i++)
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
zsl->level = level;
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++)
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++)
update[i]->level[i].span++;
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
我们用这个示例来看这个跳跃表的插入循环:

找这么张图不容易哈。
我们现在往里面插入 score=27,level=3 的数据。
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--)
/* store rank that is crossed to reach the insert position */
rank[i] = i == (zsl->level-1) ? 0 : rank[i+1];
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
rank[i] += x->level[i].span;
x = x->level[i].forward;
update[i] = x;
第一次进入for循环:
1)x为头,i=1;
2)rank[1] = 0;
3)进入while循环;
4)rank[1] = 1;x成为第一个节点(也就是update(1)那边)
5)由于第一个节点的L1层后继无人,所以被迫终止循环。update[i]=x;
第二次进入for循环(层级下降):
1)x为第一个节点,i=0;
2)rank[0]=rank[1]=1;
3)进入循环,这时已经下降一层了。
4)rank[0] = 2;
5)x继续往后,进入到第二个节点(也就是update[0]那边了)
6)由于插入score干不过后面那个,所以被迫退出循环,update[0]=x;
第三次进入for循环?nonono,莫得了、
接下来干嘛?调整最大高度。
level = zslRandomLevel();
if (level > zsl->level)
for (i = zsl->level; i < level; i++)
rank[i] = 0;
update[i] = zsl->header;
update[i]->level[i].span = zsl->length;
zsl->level = level;
rank用来记录头节点到update的span,不要忘了。
由于目标level=2,所以会进入分支。
1)rank[2]=0,因为update[2]是头结点。
2)update[2]是头结点。
3)先给level赋个值,后面会调整。
接下来干嘛?前戏都做完了,接下来插入节点。
x = zslCreateNode(level,score,ele);
for (i = 0; i < level; i++)
x->level[i].forward = update[i]->level[i].forward;
update[i]->level[i].forward = x;
/* update span covered by update[i] as x is inserted here */
x->level[i].span = update[i]->level[i].span - (rank[0] - rank[i]);
update[i]->level[i].span = (rank[0] - rank[i]) + 1;
如果新插入的列太矮,那比较高的那一部分就不用去转接,只需要span+1即可。
/* increment span for untouched levels */
for (i = level; i < zsl->level; i++)
update[i]->level[i].span++;
还剩最后一段,调整backword。
x->backward = (update[0] == zsl->header) ? NULL : update[0];
if (x->level[0].forward)
x->level[0].forward->backward = x;
else
zsl->tail = x;
zsl->length++;
return x;
真是庖丁解牛。我自己写的时候没有想这么清楚,就搞得有点乱。
查改就不说了吧,上面有查了,改就更不多说了吧,再看一下删。
删除节点
/* Internal function used by zslDelete, zslDeleteRangeByScore and
* zslDeleteRangeByRank. */
void zslDeleteNode(zskiplist *zsl, zskiplistNode *x, zskiplistNode **update)
int i;
for (i = 0; i < zsl->level; i++)
if (update[i]->level[i].forward == x)
update[i]->level[i].span += x->level[i].span - 1;
update[i]->level[i].forward = x->level[i].forward;
else
update[i]->level[i].span -= 1;
if (x->level[0].forward)
x->level[0].forward->backward = x->backward;
else
zsl->tail = x->backward;
while(zsl->level > 1 && zsl->header->level[zsl->level-1].forward == NULL)
zsl->level--;
zsl->length--;
看完增,删就是一个缩减版的逆操作,应该不难理解吧。
删除整表
这里的英文解释挺详尽的了,代码也很清晰。从第0层开始,通过forward向后遍历,一个一个回收内存。节点都回收完了,再回收表结构。
/* Delete an element with matching score/element from the skiplist.
* The function returns 1 if the node was found and deleted, otherwise
* 0 is returned.
*
* If 'node' is NULL the deleted node is freed by zslFreeNode(), otherwise
* it is not freed (but just unlinked) and *node is set to the node pointer,
* so that it is possible for the caller to reuse the node (including the
* referenced SDS string at node->ele). */
int zslDelete(zskiplist *zsl, double score, sds ele, zskiplistNode **node)
zskiplistNode *update[ZSKIPLIST_MAXLEVEL], *x;
int i;
x = zsl->header;
for (i = zsl->level-1; i >= 0; i--)
while (x->level[i].forward &&
(x->level[i].forward->score < score ||
(x->level[i].forward->score == score &&
sdscmp(x->level[i].forward->ele,ele) < 0)))
x = x->level[i].forward;
update[i] = x;
/* We may have multiple elements with the same score, what we need
* is to find the element with both the right score and object. */
x = x->level[0].forward;
if (x && score == x->score && sdscmp(x->ele,ele) == 0)
zslDeleteNode(zsl, x, update);
if (!node)
zslFreeNode(x);
else
*node = x;
return 1;
return 0; /* not found */
今天先到这里吧。大家都是按部就班的,字符串,压缩表,哈希表。。。。我反而觉得压缩表不如跳跃表来的有意思哈哈。
以上是关于redis源码学习跳跃表的主要内容,如果未能解决你的问题,请参考以下文章