IO流在C++中的应用
Posted 燕麦冲冲冲
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IO流在C++中的应用相关的知识,希望对你有一定的参考价值。
IO流

一、基本概念
在C++中,IO流是用来处理输入输出的工具。它将输入和输出数据的流看做是一个序列,并使用流的操作符来进行读写。
C++的IO流库分为两种类型:标准库流和文件流。标准库流分为输入流和输出流,文件流分为文件输入流和文件输出流。
1.1 标准库流

标准库输入流(cin)和输出流(cout)用于控制台输入和输出,它们是定义在iostream头文件中的对象。cin和cout都是全局对象,不需要创建,直接使用即可。它们可以通过操作符>>和<<来进行输入和输出。
标准库流日常中使用很多,就不举例子赘述了。
让我们来实现一个日期类,并重载>>和<<运算符。这里我们假设日期类的年月日分别用整数表示。
#include <iostream>
class Date
public:
int year, month, day;
Date(int y, int m, int d) : year(y), month(m), day(d)
friend std::ostream& operator<<(std::ostream& os, const Date& d)
os << d.year << "-" << d.month << "-" << d.day;
return os;
friend std::istream& operator>>(std::istream& is, Date& d)
char sep1, sep2;
is >> d.year >> sep1 >> d.month >> sep2 >> d.day;
if (sep1 != '-' || sep2 != '-')
is.setstate(std::ios_base::failbit);
return is;
;
在上面的代码中,我们定义了一个Date类,包含三个整型成员变量year、month、day,表示年、月、日。我们重载了<<和>>运算符,以便在流中输入输出Date类型的对象。
在<<运算符重载函数中,我们将年月日三个成员变量以“年-月-日”的格式输出到流中。
在>>运算符重载函数中,我们首先从输入流中读取年月日三个整数,然后检查年月日之间的分隔符是否为“-”。如果分隔符不是“-”,则将流的状态设置为失败状态。最后,返回输入流对象。
在上述示例中,我们将operator<<和operator>>函数声明为Date类的友元函数(friend function),并没有将它们定义为Date类的成员函数。这是因为这两个函数需要直接访问Date对象的私有成员变量,而不需要通过对象的公有接口来访问。因此,我们需要将它们声明为友元函数,以便它们可以访问Date对象的私有成员变量。
在C++中,友元函数既可以在类内部声明并在类外部定义,也可以在类外部声明并在类外部定义。当我们在类中声明一个函数为友元函数时,这个函数就被授权可以访问类的私有成员。需要注意的是,友元函数并不是类的成员函数,它们没有this指针,因此不能直接访问类的非静态成员函数。非静态成员函数只能通过类的实例进行访问。
以下是在类外定义友元函数的示例:
class Date
public:
Date(int year, int month, int day) : year_(year), month_(month), day_(day)
// 声明友元函数
friend std::ostream& operator<<(std::ostream& os, const Date& date);
friend std::istream& operator>>(std::istream& is, Date& date);
private:
int year_;
int month_;
int day_;
;
// 在类外部定义友元函数
std::ostream& operator<<(std::ostream& os, const Date& date)
os << date.year_ << "-" << date.month_ << "-" << date.day_;
return os;
std::istream& operator>>(std::istream& is, Date& date)
is >> date.year_ >> date.month_ >> date.day_;
return is;
1.2 文件流

文件输入流和文件输出流用于读取和写入文件。文件输入流对象(ifstream)和文件输出流对象(ofstream)定义在fstream头文件中。它们需要使用文件名创建,并且可以使用操作符>>和<<来进行读写。
例如,下面的代码将打开一个名为“input.txt”的文件,从文件中读取一个整数并将其写入名为“output.txt”的文件中:
#include <fstream>
#include <iostream>
int main()
std::ifstream input_file("input.txt");
std::ofstream output_file("output.txt");
int num;
input_file >> num;
output_file << "The number you entered is: " << num << std::endl;
input_file.close();
output_file.close();
return 0;
笔者觉得这里和Linux中的重定向很类似。
注意,文件输入流和文件输出流需要手动关闭,以确保在程序退出时所有资源都被释放。
二、性能问题
2.1 cout和printf性能上的差距

一般来说,cout输出的速度比printf慢一些,因为cout进行了更多的类型检查和格式转换。cout在输出时会根据不同的类型自动选择适当的格式化方式,而printf需要手动指定格式。这意味着cout可以进行更多的类型检查,确保输出的数据类型正确,但是也会导致一些额外的开销。
另外,cout和printf所输出的内容也会影响性能。如果输出的内容比较简单,如输出整数或字符串等,那么cout和printf之间的性能差别可能不会很大。但是如果需要输出复杂的数据类型,如对象、容器等,cout的性能优势可能会更加明显,因为cout可以自动处理这些类型,而printf需要手动指定格式。
综合来说,cout和printf之间的性能差距并不是绝对的,具体取决于输出内容和实际情况。在实际应用中,应该根据具体情况选择最合适的输出方式。
2.2 介绍sync_with_stdio
sync_with_stdio是iostream库中的一个函数,其作用是将iostream库和C标准库中的输入输出流同步,以提高输入输出的效率。默认情况下,iostream库中的输入输出流和C标准库中的输入输出流是独立的,这意味着在进行输入输出时,需要进行缓冲区的切换,会导致一些额外的开销。
当调用sync_with_stdio函数时,iostream库中的输入输出流和C标准库中的输入输出流将同步。这意味着在进行输入输出时,不需要进行缓冲区的切换,可以提高输入输出的效率。但是需要注意的是,使用该函数会使输入输出变得不安全,因为C标准库中的输入输出函数不是线程安全的。
使用sync_with_stdio函数的方式如下:
std::ios::sync_with_stdio(false); // 关闭同步
调用该函数时,需要将其参数设置为false,表示关闭同步。如果将参数设置为true,则表示打开同步,但这并不是一个好的做法,因为会降低输入输出的效率。通常情况下,如果不需要进行C标准库中的输入输出操作,建议将同步关闭。
三、多组输入的终止条件

在一些OJ题中,测试用例是多组,比如测试多个string类型的变量,这时候需要采用while(cin>>str)来多次读取,终止条件是什么?理论上>>的返回值是istream,为什么能作为判断条件?
3.1 终止条件
在使用while(cin>>str)来读取多个string类型变量时,需要考虑如何终止读取。一种常见的做法是在输入文件中使用某个特殊字符或字符串作为输入结束的标志,当读取到该标志时,停止读取。例如,可以在每个测试用例之间加入一个空行,当读取到空行时,表示当前测试用例输入结束。
另外,还可以使用Ctrl+Z或Ctrl+D组合键来结束输入,这取决于操作系统的不同。在Windows系统中,可以使用Ctrl+Z来结束输入,在Unix/Linux系统中,可以使用Ctrl+D来结束输入。
3.2 判断条件
在C++中,输入运算符>>返回的类型是输入流对象istream的引用,它的返回值可以被用作条件表达式。
当输入运算符>>执行成功时,输入流对象的状态标志会被设置为“正常”,因此输入流对象在条件判断时会被转换成bool类型,如果流状态正常,则被转换为true,否则被转换为false。这样,当输入运算符执行成功时,循环条件就成立,可以继续读取下一个输入;当输入运算符执行失败时,循环条件不成立,输入结束。
因此,我们可以使用输入运算符>>的返回值作为循环条件,实现多次读取输入的操作。例如,在循环读取输入时,可以这样写:
string str;
while (cin >> str)
// 处理读取到的输入
在上述代码中,当输入运算符>>成功读取输入时,循环条件成立,继续读取下一个输入,直到输入结束。
其原理是:C++11中,重载了bool类型,可以将ios及其子类的对象隐式转为bool类型,那么这样就可以使用这些类型的对象作为条件判断了。
我们可以通过重载 bool 运算符来实现隐式类型转换。以下是一个示例:
#include <iostream>
class MyClass
public:
// 重载 bool 运算符
operator bool() const
return is_valid_;
// 一些成员函数
void do_something()
std::cout << "doing something..." << std::endl;
void set_valid(bool valid)
is_valid_ = valid;
private:
bool is_valid_ = false;
;
int main()
MyClass obj;
obj.set_valid(true);
// 隐式类型转换
if (obj)
obj.do_something();
在这个例子中,我们定义了一个名为 MyClass 的类,并重载了 bool 运算符。在 main 函数中,我们创建了一个 MyClass 类型的对象 obj,并将它设置为有效。然后我们使用 if (obj) 来判断 obj 是否有效,由于 MyClass 类型重载了 bool 运算符,因此 obj 可以隐式转换为 bool 类型,且如果 obj 为有效,则条件成立,执行 obj.do_something()。
那么为什么重载了bool,类对象就可以隐式类型转换为bool?
重载了类型转换运算符的类对象,可以像内置类型一样进行隐式类型转换,这是因为C++标准规定,在条件判断语句或者逻辑运算中,如果操作数不是bool类型,那么会自动进行类型转换。具体地,如果操作数是类类型,则会调用该类的bool类型转换运算符函数,将该对象转换为bool类型的值。
所以在重载了bool类型转换运算符的类中,将该类对象隐式转换为bool类型,就相当于调用该类的bool类型转换运算符函数。这样做的好处是可以使得代码更加简洁易懂,使得类对象可以更自然地在条件判断或逻辑运算中使用。
3.3 getline与cin
getline() 和 cin 都可以用于输入,但它们有一些不同点:
- 输入方式不同:
getline()可以一次读取一行完整的字符串,而cin是通过空格、制表符或换行符来划分不同的输入单元。因此,如果想要输入含有空格的字符串,应该使用getline()。 - 参数不同:
getline()函数有两个参数,第一个参数为输入流对象,第二个参数为要读取的字符串对象;而cin通常只需要一个输入运算符(>>)。 - 错误处理方式不同:
getline()函数在读取输入时,会保留输入中的换行符,而cin不会。如果输入错误,getline()会将错误信息存储在输入流对象中,而cin则会设置一个错误标志,需要调用cin.clear()函数进行清除。
总的来说,getline() 更适合读取一行完整的字符串,而 cin 更适合读取由空格、制表符或换行符分隔的单词或数字。
四、文件流详解
4.1 二进制文件和文本文件

二进制文件和文本文件都是文件的存储格式。
二进制文件是以二进制形式编码的文件,其中的数据可以是任意的,包括非文本数据,例如图像、音频、视频、程序等等。它们通常被用于存储和传输需要高效处理的数据,如图像处理、音频处理、网络数据传输等等。二进制文件不容易被人类读取,需要特定的程序才能处理。
文本文件则是以字符形式编码的文件,其中的数据只能是文本字符,例如字母、数字、标点符号等等。文本文件通常用于存储和传输人类可读的数据,如文本编辑器中的文本、网页、代码等等。文本文件可以被人类直接读取和编辑。
在C++中,文件读写函数通常使用二进制模式和文本模式来打开文件,使用二进制模式可以读写任意类型的数据,使用文本模式则只能读写文本数据。可以使用以下方式来打开文件:
// 以二进制模式打开文件
fstream file("filename", ios::binary | ios::in | ios::out);
// 以文本模式打开文件
fstream file("filename", ios::in | ios::out);
4.2 文件流的输入输出
文件流和标准流在输入输出上是因为对象不同而不同的。
在标准流中,输入是由用户输入并传递给程序,输出是由程序输出到用户的控制台。因此,在标准流中,输入操作符 “>>” 用于将用户输入的数据读取到程序中,输出操作符 “<<” 用于将程序的输出发送到用户的控制台中。
而在文件流中,输入是由程序从文件中读取数据,输出是由程序将数据写入文件中。因此,在文件流中,输出操作符 “<<” 用于将程序的数据写入文件中,输入操作符 “>>” 用于从文件中读取数据到程序中。
因此,在输入输出流与文件流中,输入和输出是不同的概念,因此在使用操作符 “<<” 和 “>>” 时,它们的行为会根据上下文而有所不同,这也是它们在输入输出流和文件流中表现不同的原因。
以下是一个示例程序,演示如何通过文件流读写二进制文件和文本文件:
#include <iostream>
#include <fstream>
using namespace std;
struct Person
char name[20];
int age;
;
int main()
// 写入文本文件
ofstream fout("person.txt");
if (!fout)
cerr << "Error opening file!" << endl;
return 1;
Person p = "John", 25;
fout << p.name << " " << p.age << endl;
fout.close();
// 读取文本文件
ifstream fin("person.txt");
if (!fin)
cerr << "Error opening file!" << endl;
return 1;
Person q;
fin >> q.name >> q.age;
cout << "Name: " << q.name << endl;
cout << "Age: " << q.age << endl;
fin.close();
// 写入二进制文件
ofstream foutb("person.bin", ios::binary);
if (!foutb)
cerr << "Error opening file!" << endl;
return 1;
foutb.write(reinterpret_cast<const char*>(&p), sizeof(p));
foutb.close();
// 读取二进制文件
ifstream finb("person.bin", ios::binary);
if (!finb)
cerr << "Error opening file!" << endl;
return 1;
Person r;
finb.read(reinterpret_cast<char*>(&r), sizeof(r));
cout << "Name: " << r.name << endl;
cout << "Age: " << r.age << endl;
finb.close();
return 0;
该程序先写入两个人的信息到二进制文件中,然后读取该二进制文件并输出每个学生的信息。接着将人的信息写入到文本文件中,并读取该文本文件并输出每个人的信息。
注意在打开二进制文件时需要添加 ios::binary 标志,以便正确地读取二进制数据。而在写入文本文件时则不需要添加该标志。
fout等变量是文件句柄,它是一个与文件相关联的对象,用于进行文件的输入输出操作。在C++中,文件句柄是通过fstream类的对象来表示的。具体来说,fstream类是iostream类的一个派生类,用于实现对文件的读写操作。在使用fstream类时,需要创建一个fstream对象,并使用其成员函数来进行文件的打开、读取、写入等操作。
在计算机科学中,句柄(Handle)是一个指向资源的引用,这个资源可能是内存块、文件、网络连接、图形设备等。通常,句柄是一个整数,而不是一个指针。句柄可以被传递给各种系统调用和API函数,以表示要访问的资源。通过传递句柄,操作系统可以确保资源在不同的进程间共享和重用,同时还能对资源进行跟踪和管理。在不同的操作系统和编程语言中,句柄的具体实现方式可能不同。
如果上面例子中的成员变量name使用string类型,会出现异常崩溃。
使用string作为成员变量在二进制文件中的读写是不安全的,因为string的内部表示方式可能会因不同的编译器或操作系统而不同,而且string类型的大小也不固定,这可能会导致二进制读写崩溃或数据损坏。
当我们使用string类型时,实际上这个类型内部存储了一个指向字符数组的指针,字符数组存储实际的字符串内容。而在进行二进制读写时,我们只能将内存中的数据直接写入文件,然后再从文件读取回来,如果直接将string类型的对象进行读写,那么实际上只有指针地址被写入了文件,而指针指向的字符数组并没有被写入文件,当读取时,程序会试图将文件中的指针地址重新转换为指针,这个指针实际上是无效的,因为这个指针指向的内存空间已经不存在了,程序因此可能会崩溃。
因此,如果要在二进制文件中存储字符串,可以将其存储为字符数组,而不是string类型。
深浅拷贝的问题也可能导致二进制文件读写出现问题。
在使用字符串时,如果采用的是浅拷贝,那么在拷贝时只是将指针复制一份,指向的内存地址并没有复制,所以在进行二进制文件读写时,指针所指向的内存地址不一定是有效的,导致程序崩溃。
而采用深拷贝,即对字符串进行复制时,除了将指针复制一份外,还会将指针所指向的内存地址中的数据复制一份,这样就可以避免上述问题。
总之,无论是采用深拷贝还是浅拷贝,都需要在进行二进制文件读写时,特别注意指针所指向的内存地址是否有效,以免出现程序崩溃的情况。
对于上述例子中的问题,不同进程之间进行通信时,读写string类型的数据会导致野指针的问题。而在同一进程中进行读写,不会出现野指针的问题,但会出现悬垂指针的问题,因为两个Student对象共享了同一块内存空间。
那文本读写为什么不会出现上述错误?
文本读写通常采用的是字符流,即读入和输出的是以字符为单位的数据,例如字符串、字符数组等。这种方式下,读入的数据是以字符数组的形式存储在内存中,不存在指针类型的数据,因此也不存在深浅拷贝和指针转换的问题。
五、通过流序列化和反序列化
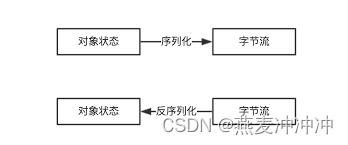
网络聊天中的消息传递通常是通过网络传输的,因此需要将消息序列化为二进制流来进行传输。C++的流可以很方便地进行序列化和反序列化操作。
以下是一个简单的例子,演示如何使用C++流进行消息序列化和反序列化:
#include <iostream>
#include <sstream>
class Message
public:
std::string sender;
std::string content;
// 将消息序列化为二进制流
std::string serialize() const
std::ostringstream oss;
oss << sender.size() << sender << content.size() << content;
return oss.str();
// 从二进制流中反序列化消息
void deserialize(const std::string& data)
std::istringstream iss(data);
int sender_len, content_len;
iss >> sender_len;
sender.resize(sender_len);
iss.read(&sender[0], sender_len);
iss >> content_len;
content.resize(content_len);
iss.read(&content[0], content_len);
;
int main()
Message msg;
msg.sender = "Alice";
msg.content = "Hello, Bob!";
// 将消息序列化为二进制流
std::string data = msg.serialize();
// 从二进制流中反序列化消息
Message new_msg;
new_msg.deserialize(data);
std::cout << "Sender: " << new_msg.sender << std::endl;
std::cout << "Content: " << new_msg.content << std::endl;
return 0;
这里我们定义了一个 Message 类,其中包含了一个 sender 和一个 content 字符串。我们在类中定义了 serialize 和 deserialize 两个方法,用于将 Message 对象序列化到输出流中,或者从输入流中反序列化出一个 Message 对象。
在序列化方法中,我们将 sender 和 content 字符串的长度以及内容按照一定的格式输出到输出流中。在反序列化方法中,我们首先读取出 sender 和 content 字符串的长度,然后分别使用 resize 方法调整字符串的大小,接着使用 read 方法从输入流中读取出字符串的内容。
在主函数中,我们首先将一个 Message 对象序列化到 std::stringstream 对象中,接着再从这个对象中反序列化出一个新的 Message 对象,并打印出其中的信息。
以上是关于IO流在C++中的应用的主要内容,如果未能解决你的问题,请参考以下文章