基于MinIO/Deleta Lake/Dremio和Superset或Metabase搭建简单的数据湖
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于MinIO/Deleta Lake/Dremio和Superset或Metabase搭建简单的数据湖相关的知识,希望对你有一定的参考价值。

数据湖架构
大多数公司都有大量的业务数据,这些数据通常孤立在各种存储系统中,包括数据库和数据仓库。为了充分利用这些数据资产,您应该将数据集中并整合到统一的数据存储中,以增强分析能力。
通过数据湖架构,组织可以更大规模地简化跨职能企业分析。查询数据湖和收获丰富洞察的能力带来了巨大的商业价值。当正确的建立和部署,数据湖给你的能力:
集中、整合和编目业务数据,从而消除与数据孤岛相关的问题
以无缝方式集成广泛的数据源和格式
助力数据科学并利用机器学习
通过向多个用户提供自助服务工具来实现企业数据的大众化。
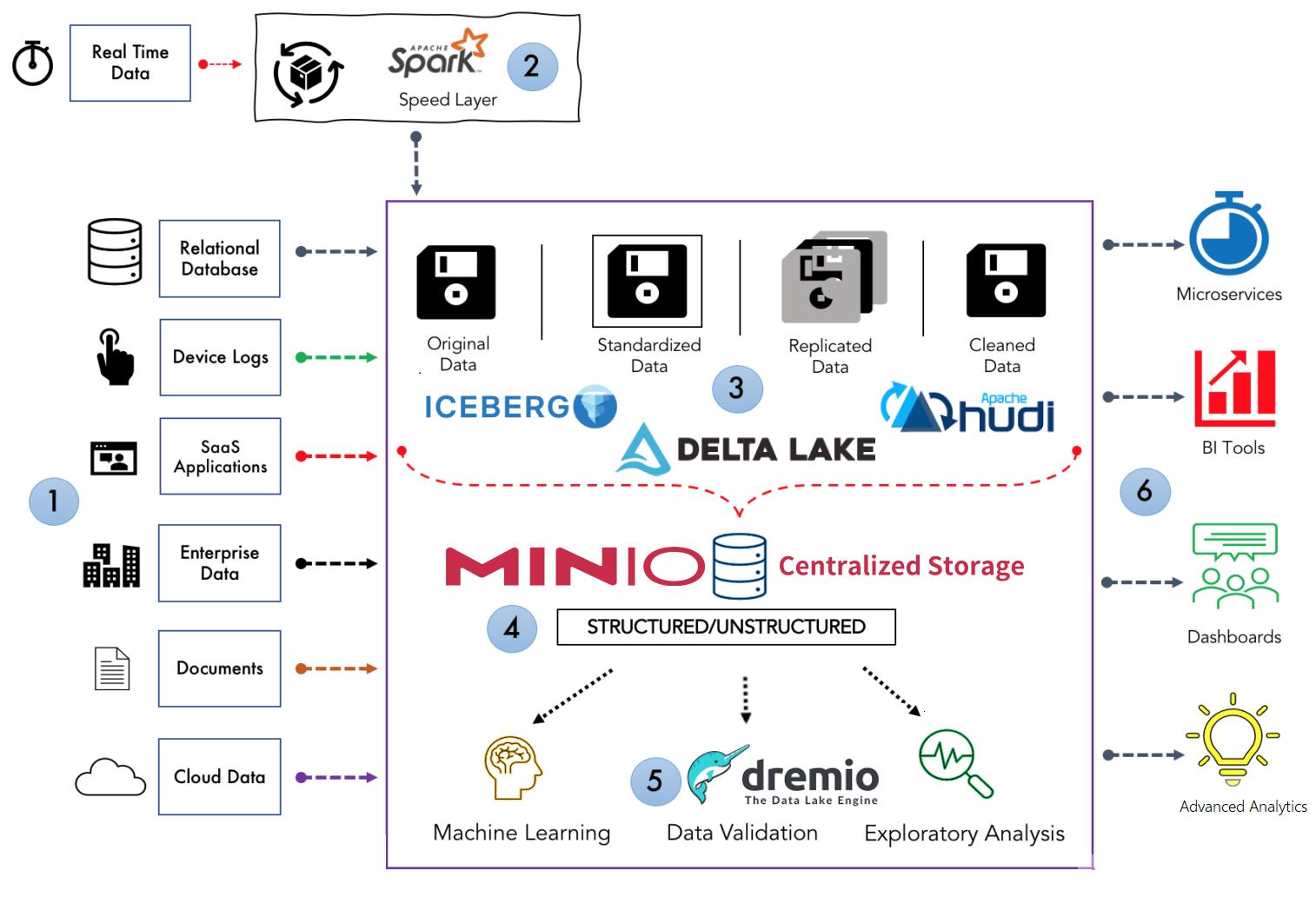
-
数据源:包括大量结构化和非结构化数据源输入数据湖。其中包括关系数据库、设备日志、企业数据、SaaS 数据、文档、云数据等等。
-
数据处理: 数据湖包含所有类型的数据资产,其中大部分不是实时产生的。因此,加载到数据湖中的大多数数据都以批处理格式存储。在将数据放入湖中之前,使用lambda 架构或Kafka Streams等实时数据框架(如: Spark)进行流处理。
-
数据转化:虽然数据湖是用于保存数据的统一中央存储库,但这些数据不会未经任何清理或处理就加载到数据湖中,并可以将其处于更好的结构或格式(如:DELTA LAKE/ICEBERG/HUDI)中以便于分析。
-
数据存储:这里是存储不同类型数据的地方。MinIO等工具用于存储目的。
-
数据分析: 数据湖允许企业中的各个团队使用他们选择的分析工具和框架(如: Dremio)访问数据。分析师可以利用这些数据,而无需将其移动到单独的存储中进行处理、分析、提炼或转换。
-
报告: 数据湖连接到现代商业智能工具,如 Apache Superset、Metabase 或 Tableau,用于准备数据以进行分析和构建报告。
对于想要存储多种类型的数据并从其数据资产中获得巨大价值的企业来说,数据湖非常强大。
基础环境
Docker
Docker版本: 20.10.10
访问地址
Portainer
地址:http://10.0.0.198:9999/#!/home
用户名/密码 admin/ admin123
MinIO
地址: http://10.0.0.198:9009/dashboard
用户名/密码 minio/minio123
Spark
地址: http://10.0.0.198
Dremio
地址: http://10.0.0.198:9047
用户名/密码 dremio/ dremio123
Metabase
地址: http://10.0.0.198:3000
用户名/密码 test123@sina.com / test123@sina.com
在 Linux 系统上安装 Compose
在 Linux 上,你可以从GitHub 上的Compose 存储库发布页面下载 Docker Compose 二进制文件 。按照链接中的说明进行操作,其中包括curl在终端中运行命令以下载二进制文件。这些分步说明也包含在下面。
对于
alpine,需要以下依赖包:py-pip,python3-dev,libffi-dev,openssl-dev,gcc,libc-dev,rust,cargo和make。
下载 Docker Compose 的当前稳定版本:
sudo curl -L "https://github.com/docker/compose/releases/download/1.29.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose
要安装不同版本的 Compose,请替换
1.29.2为你要使用的 Compose 版本。
对二进制文件应用可执行权限:
sudo chmod +x /usr/local/bin/docker-compose
注意:如果
docker-compose安装后命令失败,请检查你的路径。你还可以/usr/bin在路径中创建指向或任何其他目录的符号链接。
例如:
sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
bash 补全命令
在当前的 Linux 操作系统上(在非最小安装中),bash 完成应该可用。
将完成脚本放在/etc/bash_completion.d/.
sudo curl \\
-L https://raw.githubusercontent.com/docker/compose/1.29.2/contrib/completion/bash/docker-compose \\
-o /etc/bash_completion.d/docker-compose
重新加载你的终端。你可以关闭然后打开一个新终端,或者source ~/.bashrc在当前终端中使用命令重新加载你的设置。
测试安装。
docker-compose --version
docker-compose version 1.29.2, build 1110ad01
MinIO
在Docker Compose上部署分布式MinIO,请下载docker-compose.yaml到你的当前工作目录。Docker Compose会pull MinIO Docker Image,所以你不需要手动去下载MinIO binary。然后运行下面的命令
安装
# 配置信息
#################### MINIO #####################
x-minio-image: &minio-image minio/minio:RELEASE.2021-07-30T00-02-00Z
x-minio-data-dir: &minio-data-dir
# 映射文件路径
- /mydata/minio/data:/data
#用于部署运行所依赖的基础环境组件
version: '3.9'
services:
# 1.MinIO服务器
minio:
image: *minio-image
container_name: minio
ports:
- "9000:9000"
- "9009:9009"
restart: always
deploy:
resources:
limits:
cpus: '0.50'
memory: 512M
reservations:
cpus: '0.25'
memory: 256M
command: server /data --console-address ":9009"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123 #大于等于8位
logging:
options:
max-size: "2048M" # 最大文件上传限制
max-file: "10"
driver: json-file
volumes: *minio-data-dir
healthcheck:
test: ["CMD", "curl", "-f", "http://10.0.0.198:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
参考链接:
https://www.jianshu.com/p/aaa797181c2d
Spark3(包含Deleta Lake)
# 2.spark3(包含Deleta Lake)
# 2.1 spark-master
spark:
image: datamechanics/spark:jvm-only-3.1-latest
hostname: spark
command: /opt/spark/sbin/start-master.sh
environment:
- "SPARK_MASTER_HOST=spark"
ports:
- "8080:8080"
- "7077:7077"
# 2.2 spark-worker
worker:
image: datamechanics/spark:jvm-only-3.1-latest
hostname: worker
command: /opt/spark/sbin/start-worker.sh
environment:
- "SPARK_MASTER_HOST=spark"
ports:
- "8080:8080"
- "7077:7077"
spark 集成delta lake 以及minio s3
-
运行命令
# 1. 进入根目录 cd # 2. spark 集成delta lake 以及minio s3 ./bin/spark-shell \\ --packages io.delta:delta-core_2.12:1.0.0,org.apache.hadoop:hadoop-aws:3.2.0 \\ --conf "spark.hadoop.fs.s3a.access.key=minio" \\ --conf "spark.hadoop.fs.s3a.secret.key=minio123" \\ --conf "spark.hadoop.fs.s3a.endpoint=http://10.0.0.198:9000" \\ --conf "spark.databricks.delta.retentionDurationCheck.enabled=false" \\ --conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \\ --conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog" # 3. 创建delta lake table--先在minio中创建名为delta-lake的bucket,然后生成随机数保存都firstdemo中 spark.range(50000000).write.format("delta").save("s3a://delta-lake/firstdemo") -
运行示例
185@spark:~/work-dir$ cd
185@spark:~$ ./bin/spark-shell \\
--packages io.delta:delta-core_2.12:1.0.0,org.apache.hadoop:hadoop-aws:3.2.0 \\
--conf "spark.hadoop.fs.s3a.access.key=minio" \\
--conf "spark.hadoop.fs.s3a.secret.key=minio123" \\
--conf "spark.hadoop.fs.s3a.endpoint=http://10.0.0.198:9000" \\
--conf "spark.databricks.delta.retentionDurationCheck.enabled=false" \\
--conf "spark.sql.extensions=io.delta.sql.DeltaSparkSessionExtension" \\
--conf "spark.sql.catalog.spark_catalog=org.apache.spark.sql.delta.catalog.DeltaCatalog"
:: loading settings :: url = jar:file:/opt/spark/jars/ivy-2.4.0.jar!/org/apache/ivy/core/settings/ivysettings.xml
Ivy Default Cache set to: /opt/spark/.ivy2/cache
The jars for the packages stored in: /opt/spark/.ivy2/jars
io.delta#delta-core_2.12 added as a dependency
org.apache.hadoop#hadoop-aws added as a dependency
:: resolving dependencies :: org.apache.spark#spark-submit-parent-b3b3485b-6bb5-42b7-a4fc-5a6ceee32dbe;1.0
confs: [default]
found io.delta#delta-core_2.12;1.0.0 in central
found org.antlr#antlr4;4.7 in central
found org.antlr#antlr4-runtime;4.7 in central
found org.antlr#antlr-runtime;3.5.2 in central
found org.antlr#ST4;4.0.8 in central
found org.abego.treelayout#org.abego.treelayout.core;1.0.3 in central
found org.glassfish#javax.json;1.0.4 in central
found com.ibm.icu#icu4j;58.2 in central
found org.apache.hadoop#hadoop-aws;3.2.0 in central
found com.amazonaws#aws-java-sdk-bundle;1.11.375 in central
:: resolution report :: resolve 350ms :: artifacts dl 9ms
:: modules in use:
com.amazonaws#aws-java-sdk-bundle;1.11.375 from central in [default]
com.ibm.icu#icu4j;58.2 from central in [default]
io.delta#delta-core_2.12;1.0.0 from central in [default]
org.abego.treelayout#org.abego.treelayout.core;1.0.3 from central in [default]
org.antlr#ST4;4.0.8 from central in [default]
org.antlr#antlr-runtime;3.5.2 from central in [default]
org.antlr#antlr4;4.7 from central in [default]
org.antlr#antlr4-runtime;4.7 from central in [default]
org.apache.hadoop#hadoop-aws;3.2.0 from central in [default]
org.glassfish#javax.json;1.0.4 from central in [default]
---------------------------------------------------------------------
| | modules || artifacts |
| conf | number| search|dwnlded|evicted|| number|dwnlded|
---------------------------------------------------------------------
| default | 10 | 0 | 0 | 0 || 10 | 0 |
---------------------------------------------------------------------
:: retrieving :: org.apache.spark#spark-submit-parent-b3b3485b-6bb5-42b7-a4fc-5a6ceee32dbe
confs: [default]
0 artifacts copied, 10 already retrieved (0kB/9ms)
21/11/04 05:10:33 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
21/11/04 05:10:41 WARN Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
Spark context Web UI available at http://localhost:4041
Spark context available as 'sc' (master = local[*], app id = local-1636002641781).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\\ \\/ _ \\/ _ `/ __/ '_/
/___/ .__/\\_,_/_/ /_/\\_\\ version 3.1.1
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 1.8.0_312)
Type in expressions to have them evaluated.
Type :help for more information.
scala> spark.range(50000000).write.format("delta").save("s3a://delta-lake/firstdemo")
21/11/04 05:12:09 WARN MemoryManager: Total allocation exceeds 95.00% (906,992,014 bytes) of heap memory
Scaling row group sizes to 96.54% for 7 writers
21/11/04 05:12:09 WARN MemoryManager: Total allocation exceeds 95.00% (906,992,014 bytes) of heap memory
Scaling row group sizes to 84.47% for 8 writers
21/11/04 05:12:14 WARN MemoryManager: Total allocation exceeds 95.00% (906,992,014 bytes) of heap memory
Scaling row group sizes to 96.54% for 7 writers
参考链接:
http://spark.apache.org/docs/latest/running-on-kubernetes.html
https://cloud.tencent.com/developer/article/1156852
https://www.cnblogs.com/rongfengliang/p/14928505.html
https://community.dremio.com/t/error-restore-backup/6114/19
Dremio
version: “3.2”
services:
mssql:
container_name: mssql
image: microsoft/mssql-server-linux:2017-latest
ports:
- “1433:1433”
environment:
SA_PASSWORD: “A_P@ssw0rd”
ACCEPT_EULA: “Y”
dremio_coordinator:
container_name: dremio
image: dremio/dremio-oss
volumes:
- C:\\MYSHARE:/MNT/MYSHARE
environment:
CONF: “is_coordinator”
EXECTUORS : "dremio_executor_1,dremio_executor_2"
ports:
- “9047:9047”
- “31010:31010”
- “32010:32010”
- “45678:45678”
links:
- mssql
dremio_executor_1:
container_name: dremio
image: dremio/dremio-oss
volumes:
- C:\\MYSHARE:/MNT/MYSHARE
environment:
CONF: “is_executor"
ID "1"
ports:
- “9047:9047”
- “31010:31010”
- “32010:32010”
- “45678:45678”
links:
- dremio_coordinator
dremio_executor_2:
container_name: dremio
image: dremio/dremio-oss
volumes:
- C:\\MYSHARE:/MNT/MYSHARE
environment:
CONF: “is_executor"
ID: "2"
ports:
- “9047:9047”
- “31010:31010”
- “32010:32010”
- “45678:45678”
links:
- dremio_coordinator
Dremio: 将 Minio 配置为分布式存储
https://glory.blog.csdn.net/article/details/120747823
Dremio的基本使用
参考链接:
https://github.com/dremio/dremio-cloud-tools/tree/master/charts/dremio_v2
https://github.com/dremio/dremio-cloud-tools
https://github.com/big-data-europe/docker-spark
https://www.dremio.com/tutorials/getting-oriented-to-dremio/
Superset
安装
1. Clone Superset 的 Github 仓库
使用以下命令在终端中克隆 Superset 的 repo:
$ git clone https://github.com/apache/superset.git
一旦该命令成功完成,你应该会superset在当前目录中看到一个新文件夹。
2.通过Docker Compose启动Superset
导航到你在步骤 1 中创建的文件夹:
$ cd superset
然后,运行以下命令:
$ docker-compose -f docker-compose-non-dev.yml up
**注意:**这将在非开发模式下启动Superset,不会反映对代码库的更改。如果你想在开发模式下运行 superset 来测试本地更改,只需将之前的命令替换为:docker-compose up,然后等待superset_node容器完成资产构建。
配置 Docker Compose
你可以分别使用docker/.env和为开发和非开发模式配置 Docker Compose 设置docker/.env-non-dev。这些环境文件为 Docker Compose 设置中的大多数容器设置环境,一些变量影响多个容器,而其他变量只影响单个容器。
一个重要的变量是SUPERSET_LOAD_EXAMPLES决定superset_init容器是否将示例数据和可视化加载到数据库和 Superset 中。这些示例对大多数人很有帮助,但对于有经验的用户来说可能没有必要。加载过程有时可能需要几分钟和大量 CPU,因此你可能希望在资源受限的设备上禁用它。
**注意:**用户通常希望从 Superset 连接到其他数据库。目前,最简单的方法是修改docker-compose-non-dev.yml文件并将你的数据库添加为其他服务所依赖的服务(通过x-superset-depends-on)。其他人尝试network_mode: host在 Superset 服务上进行设置,但这些通常会破坏安装,因为配置需要使用 Docker Compose DNS 解析器来获取服务名称。如果你对此有好的解决方案,请告诉我们!
4. 登录Superset
你的本地 Superset 实例还包括一个 Postgres 服务器来存储你的数据,并且已经预加载了一些 Superset 附带的示例数据集。你现在可以通过 Web 浏览器访问 Superset 访问http://localhost:8088。
使用默认用户名和密码登录:
username: admin
password: admin
在Superset中添加Dremio 驱动程序
Superset 需要为要连接的每种其他类型的数据库安装 Python 数据库驱动程序。通过 本地设置 Superset 时docker-compose, 将自动安装requirements.txt和 requirements-dev.txt 中包含的驱动程序和包 。
在本节中,我们将介绍如何安装 mysql 连接器库。所有附加库的连接器库安装过程都是相同的,我们将在本节结束时为每个数据库推荐连接器库。
1. 确定你需要的驱动程序
弄清楚如何安装你选择的数据库驱动程序。
在示例中,我们将逐步介绍在 Superset 中安装 dremio驱动程序的过程。
2.安装Dremio驱动
由于我们目前通过 运行在 Docker 容器内docker compose,因此我们不能简单地pip install mysqlclient在本地 shell 上运行 并期望将驱动程序安装在 Docker 容器中以进行Superset。
为了解决这个问题,Supersetdocker compose设置附带了一种机制,供你在本地安装包,Git 将忽略本地开发的目的。请按照以下步骤操作:
创建 requirements-local.txt
# From the repo root...
touch ./docker/requirements-local.txt
添加在上述步骤中选择的驱动程序:
echo "sqlalchemy_dremio" >> ./docker/requirements-local.txt
使用内置的新驱动程序重建本地映像:
docker-compose build --force-rm
Docker 镜像的重建完成后(这需要几分钟),你可以使用以下命令重新启动:
docker-compose up
另一种选择是通过 Docker Compose 启动 Superset 使用 中的配方docker-compose-non-dev.yml,这将使用预先构建的前端资产并跳过前端资产的构建:
docker-compose -f docker-compose-non-dev.yml up
3.连接到Dremio
现在你已经在本地安装了 Dremio驱动程序,你应该可以对其进行测试。
我们现在可以在 Superset 中创建一个可用于连接到 Dremio实例的数据源。假设你的 MySQL 实例在本地运行并且可以通过 localhost 访问,请在“SQL Alchemy URI”中使用以下连接字符串,通过转到 Superset 中的 Sources > Databases > + 图标(添加新数据源)。
对于Dremio推荐的连接器库是 sqlalchemy_dremio。
ODBC 的预期连接字符串(默认端口为 31010)格式如下:
dremio://username:password@host:port/database_name/dremio?SSL=1
Arrow Flight (Dremio 4.9.1+. 默认端口为 32010) 的预期连接字符串格式如下:
dremio+flight://username:password@host:port/dremio
单击“测试连接”,它应该会给你一个“OK”消息。如果没有,请查看你的终端以获取错误消息,并寻求帮助。
你可以为你希望Superset能够连接到的每个数据库重复此过程。
Dremio 的这篇博文提供了一些关于将 Superset 连接到 Dremio 的额外有用说明。
参考链接:
使用 Docker Compose 在本地安装 Superset
https://www.dremio.com/tutorials/dremio-apache-superset/
https://pypi.org/project/sqlalchemy-dremio/
Metabase
安装
添加外部依赖项或插件
要添加外部依赖 JAR 文件,例如 Oracle 或 Vertica JDBC 驱动程序或第 3 方 Metabase 驱动程序,你需要在主机系统中创建一个目录plugins并将其绑定,以便/plugins使用--mount或-v/将其作为路径供 Metabase使用--volume。
例如,如果你在主机系统上命名了一个目录/path/to/plugins,则可以使用以下--mount选项将其内容提供给 Metabase :
docker run -d -p 3000:3000 \\
--mount type=bind,source=/usr/local/jt/deploy-datalake/datalake/metabase/plugins,destination=/plugins \\
--name metabase metabase/metabase
请注意,Metabase 将使用此目录提取与默认 Metabase 发行版捆绑在一起的插件(例如 SQLite 等各种数据库的驱动程序),因此它必须是 Docker 可读和可写的。插件要具备可执行权限。
注意
- 新建文件夹
/mydata/minio/data- 新建文件夹
/usr/local/jt/deploy-datalake/datalake/metabase/plugins, 并存放dremio.metabase-driver.jar插件, 赋予可读可写可执行权限- spark整理使用了host模式, 修改启动命令中
command: /opt/spark/sbin/start-worker.sh spark://10.0.0.198:7077的主机地址
Metabase基本使用
参考链接:
https://github.com/Baoqi/metabase-dremio-driver
https://www.metabase.com/docs/latest/operations-guide/running-metabase-on-docker.html
https://registry.hub.docker.com/r/metabase/metabase
https://www.metabase.com/docs/latest/developers-guide-drivers.html
https://github.com/metabase/metabase/wiki/Writing-a-Driver
https://github.com/metabase/metabase/pull/9087?w=1
https://community.dremio.com/t/fyi-just-build-a-dremio-connector-for-metabase-open-source-bi/7487
完整部署文件
datalake-app.yml
部署数据湖相关组件
# 配置信息
#################### MinIO #####################
x-minio-image: &minio-image minio/minio:RELEASE.2021-07-30T00-02-00Z
x-minio-data-dir: &minio-data-dir
# 映射文件路径
- /mydata/minio/data:/data
#################### Metabase #####################
x-metabase-data-dir: &metabase-data-dir
# 映射文件路径
- /dev/urandom:/dev/random:ro
- /usr/local/jt/deploy-datalake/detailListake/plugins/metabase:/plugins
#################### Spark #####################
x-spark-data-dir: &spark-data-dir
# 映射文件路径
- /usr/local/jt/deploy-datalake/datalake/plugins/spark:/opt/spark/.ivy2
#################### Postgres #####################
x-postgres-data-dir: &postgres-data-dir
# 映射文件路径
- /mydata/postgres/data:/var/lib/postgresql/data
#用于部署运行所依赖的基础环境组件
version: '3.9'
services:
# 1.MinIO服务器
minio:
image: *minio-image
container_name: minio
ports:
- "9000:9000"
- "9009:9009"
restart: always
deploy:
resources:
limits:
cpus: '0.50'
memory: 512M
reservations:
cpus: '0.25'
memory: 256M
command: server /data --console-address ":9009"
environment:
MINIO_ROOT_USER: minio
MINIO_ROOT_PASSWORD: minio123 #大于等于8位
logging:
options:
max-size: "2048M" # 最大文件上传限制
max-file: "10"
driver: json-file
volumes: *minio-data-dir
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:9000/minio/health/live"]
interval: 30s
timeout: 20s
retries: 3
# 2.spark3(包含Deleta Lake)
# 2.1 spark-master
spark-master:
image: datamechanics/spark:jvm-only-3.1-latest
hostname: spark-master
container_name: spark-master
network_mode: host
command: /opt/spark/sbin/start-master.sh
volumes: *spark-data-dir
environment:
- "SPARK_MASTER_HOST=spark"
- "SPARK_NO_DAEMONIZE=true"
# ports:
# - "8080:8080"
# - "7077:7077"
# 2.2 spark-worker
spark-worker :
image: datamechanics/spark:jvm-only-3.1-latest
hostname: spark-worker
container_name: spark-worker
command: /opt/spark/sbin/start-worker.sh spark://10.0.0.198:7077
environment:
- "SPARK_NO_DAEMONIZE=true"
ports:
- "8888:8080"
- "7777:7077"
# 3. dremio
dremio:
image: dremio/dremio-oss:15.0.0
container_name: dremio
command: -H unix:///var/run/docker.sock
restart: always
# deploy:
# resources:
# limits:
# cpus: '1.0'
# memory: 2048M
# reservations:
# cpus: '0.5'
# memory: 1024M
# environment:
# # 中文查询乱码问题解决
# - DREMIO_JAVA_SERVER_EXTRA_OPTS=-Dsaffron.default.charset=UTF-16LE -Dsaffron.default.nationalcharset=UTF-16LE -Dsaffron.default.collation.name=UTF-16LE\\$en_US
ports:
- "9047:9047"
- "31010:31010"
- "45678:45678"
volumes:
- /var/run/docker.sock:/var/run/docker.sock #数据文件挂载
- /etc/localtime:/etc/localtime:ro
- dremio-data:/opt/dremio/data
- dremio-data:/var/lib/dremio
# 4. metabase
metabase:
image: metabase/metabase:v0.39.5
container_name: metabase
hostname: metabase
volumes: *metabase-data-dir
ports:
- 3000:3000
environment:
MB_DB_TYPE: postgres
MB_DB_DBNAME: metabase
MB_DB_PORT: 5432
MB_DB_USER: metabase
MB_DB_PASS: metabase123
MB_DB_HOST: postgres-secrets
depends_on:
- postgres-secrets
# 4. metabase依赖的数据库
postgres-secrets:
image: postgres:14.0
container_name: postgres-secrets
hostname: postgres-secrets
environment:
POSTGRES_USER: metabase
POSTGRES_DB: metabase
POSTGRES_PASSWORD: metabase123
volumes: *postgres-data-dir
# 5.nginx服务器
# nginx:
# image: nginx:$NGINX_VERSION
# container_name: nginx
# restart: always
# ports:
# - "80:8080"
# - "7930:7930"
# - "9001:9001"
# - "9002:9002"
# #定义挂载点
# volumes:
# - $NGINX_CONF_FILE:/etc/nginx/nginx.conf
# - $NGINX_CONF_DIR:/etc/nginx/conf.d
# - $NGINX_LOG_DIR:/var/log/nginx
# - $NGINX_HTML_DIR:/etc/nginx/html
# 持久存储
volumes:
dremio-data:
datalake-base.yml
部署容器的UI界面
#用于部署运行所依赖的服务
version: '3.9'
services:
# 基础环境组件
# 1.Portainer
portainer:
image: portainer/portainer-ce
container_name: portainer
command: -H unix:///var/run/docker.sock
restart: always
deploy:
resources:
limits:
cpus: '0.50'
memory: 800M
reservations:
cpus: '0.1'
memory: 256M
ports:
- "9999:9000"
- "8000:8000"
environment:
TZ: Asia/Shanghai
volumes:
- /var/run/docker.sock:/var/run/docker.sock #数据文件挂载
- portainer_data:/data portainer/portainer-ce #配置文件挂载
# 存储卷
volumes:
portainer_data:以上是关于基于MinIO/Deleta Lake/Dremio和Superset或Metabase搭建简单的数据湖的主要内容,如果未能解决你的问题,请参考以下文章